啥玩意都有 新看的知识
后端面试进阶指南目录 https://xiaozhuanlan.com/topic/2167809435
小林coding:https://www.cnblogs.com/xiaolincoding/ 强烈推荐
C++浅拷贝与深拷贝
- 系统默认是浅拷贝,当数据成员没有指针时,其实就是没有内存资源时,浅拷贝是可行的;但有指针时,用浅拷贝会使两个类中的两个指针指向同一个地址,当对象快结束时,会调用两次析构函数,使指针悬空。
- 深拷贝时会把开辟新内存把指针指向的对象也拷贝出来。
A(const A& _A) : size(_A.size){
data = new int[size];
} // 深拷贝
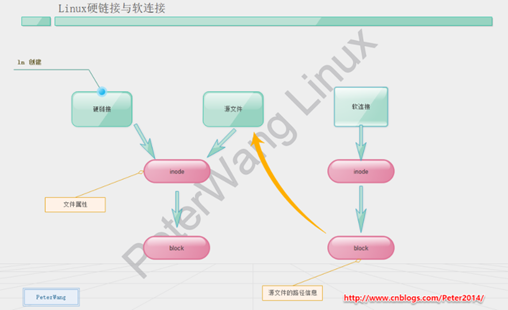
软连接与硬链接
- 硬链接:硬链接与源文件都指向同一个inode,是文件的不同入口,想要删除文件需要把所有硬链接和源文件都删除。对目录不能创建硬链接。
- 软连接:windows的快捷方式就是软连接,软连接是创建个新的inode,存着一个block,block存着源文件路径名,是和源文件不同的文件,文件类型也不同。如果源文件没了,软连接依然存在,只是无法访问源文件。
用nullptr不用NULL
- null在c++中就是无类型的0,而nullptr不是整型类别,也不是指针类型,但能转换成任意指针类型。
从键盘按下字符到它出现在显示器的过程详解 (存疑)
- 键盘被按下后,产生了硬件中断信号。
- 计算机高级中断控制器(IOAPIC)选择CPU处理核心以及软件中断编号,并发送给中断描述符表(IDT)处理。
- 计算机根据IDT选择中断处理函数。
- 处理函数处理并通知端口驱动获取按键的信息。
- 端口驱动将数据封装,以IRP(I/O request package)形式传递给上层处理程序。
- 等待输入的进程获得数据,处理并交给目标进程。
- 目标进程显示输入。
另个解释:https://blog.csdn.net/bingjing12345/article/details/7830710
TCP 和 HTTP 中的 KeepAlive 机制总结:
https://xie.infoq.cn/article/398b82c2b4300f928108ac605
一个是用来保活,提高可靠性,一个是提高复用性。
epoll原理解析
https://blog.csdn.net/armlinuxww/article/details/92803381
如果 SYN 半连接队列已满,只能丢弃连接吗?
https://www.cnblogs.com/xiaolincoding/p/12995358.html
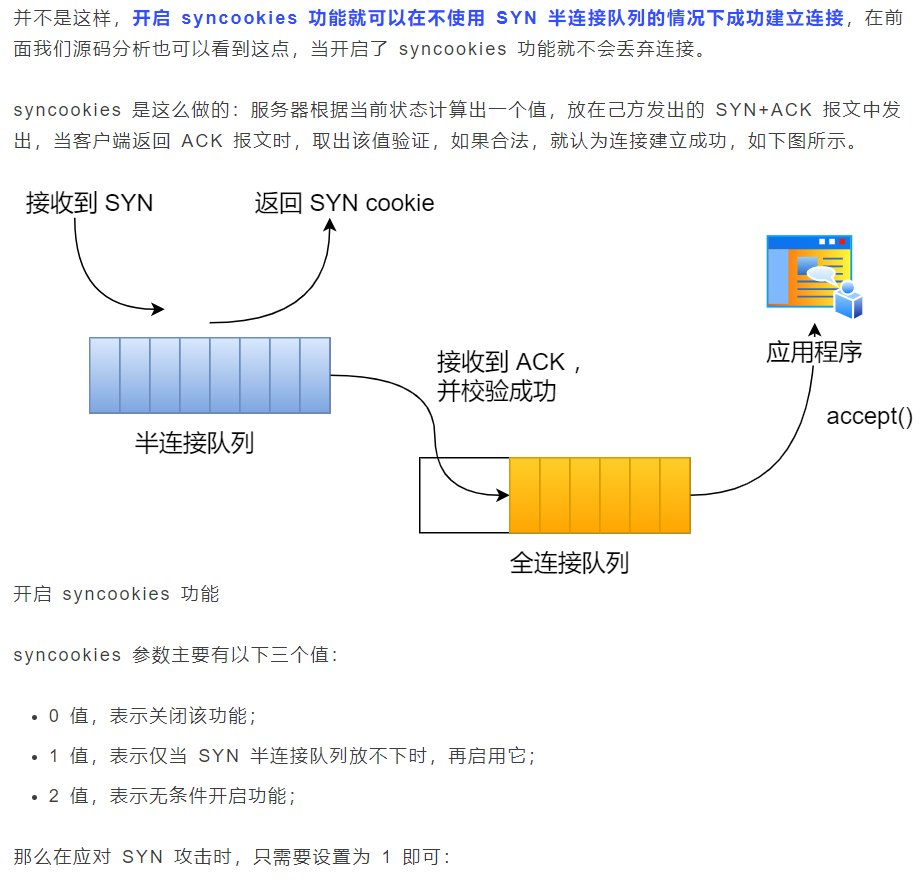
这里给出几种防御 SYN 攻击的方法:
- 增大半连接队列;
- 开启 tcp_syncookies 功能
- 减少 SYN+ACK 重传次数:加快处于 SYN_REVC 状态的 TCP 连接断开。
InnoDB与MyISAM有哪些区别呢?
https://www.cnblogs.com/dalianpai/p/14165216.html
如何用通俗易懂的话来解释非对称加密?
联合索引
https://segmentfault.com/a/1190000015416513
Utf8编码

话说进程和线程
https://www.bilibili.com/video/BV1H541187UH?from=search&seid=692598712846930104
https://www.bilibili.com/video/BV1KD4y1U7Rr?from=search&seid=7668303275125709327
进程:进程控制块pcb pcb有个指针,存储当前进程页目录的物理地址,页目录里存着指针,指向页表,页表存储着物理内存页的起始地址。两级页表可以寻址1024*1024*4KB = 4GB 内存空间大小。线性地址32位,10位是在页目录中选择一个页表,10位在页表中选择一个物理内存页,12位是物理内存页的偏移量。
进程先向操作系统申请内存地址,linux中通过进程对应的task_struct找到记录内存分配的链表,每个链表记录该进程已经分配的一段连续内存地址空间。但真正进行映射要到进程访问这段内存时才会进行。Cup中的内存管理单元(MMU)负责线性地址到物理地址转换,该进程页目录的物理地址会保存到特定的寄存器,cup会把已经转换的地址关系存放在TLB中,需要转换地址时先去tlb查找,找不到去查页表写入tlb。切换进程时,页目录地址会改变,之前的TLB缓存会失效需要重新查询页表,这也是进程切换代价比较高的一个重要原因。
而线程共享进程的虚拟地址空间,tlb缓存不会失效。
进程拥有的资源包括:内存空间中的代码、数据等;I/O 资源;文件;处理机等。
线程资源:线程控制块tcb
为何引入进程:为了程序的并发执行
四个范式

Mysql的MyISAM与innoDB
- Innodb是数据和索引不分离的,myisam是索引存放的是数据的地址。
- Innodb要有主键,sam可以没有。
- Innodb有行级锁,支持事务,支持外键
- Myisam优点是存储空间更大,支持全文索引。
面向报文(udp)面向字节流(TCP)
- 面向报文的传输方式是应用层交给UDP多长的报文,UDP就照样发送,即一次发送一个报文。因此,应用程序必须选择合适大小的报文。若报文太长,则IP层需要分片,降低效率。若太短,会是IP太小。UDP对应用层交下来的报文,既不合并,也不拆分,而是保留这些报文的边界。这也就是说,应用层交给UDP多长的报文,UDP就照样发送,即一次发送一个报文。 DNS 视频面试
- 面向字节流的话,虽然应用程序和TCP的交互是一次一个数据块(大小不等),但TCP把应用程序看成是一连串的无结构的字节流。TCP有一个缓冲,当应用程序传送的数据块太长,TCP就可以把它划分短一些再传送。如果应用程序一次只发送一个字节,TCP也可以等待积累有足够多的字节后再构成报文段发送出去。 文件传输
Redo log的机制
https://www.jianshu.com/p/336e4995b9b8
分布式储存的哈希一致性:
https://segmentfault.com/a/1190000021199728
分布式存储的一致性 两段提交:
https://segmentfault.com/a/1190000012534071
一篇文章讲透分布式存储
https://zhuanlan.zhihu.com/p/55964292
什么时候使用指针?什么时候使用引用?什么时候应该按值传递?
https://blog.csdn.net/hbtj_1216/article/details/56843014
通过虚函数表调用虚函数与通过虚函数表(绕过访问权限控制)
https://blog.csdn.net/iicy266/article/details/11906807
堆栈的区别
1、内存分配方面:
堆:一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS回收 。注意它与数据结构中的堆是两回事,分配方式是类似于链表。可能用到的关键字如下:new、malloc、delete、free等等。
栈:由编译器(Compiler)自动分配释放,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈。
2、申请方式方面:
堆:需要程序员自己申请,并指明大小。在c中malloc函数如p1 = (char *)malloc(10);在C++中用new运算符,但是注意p1、p2本身是在栈中的。因为他们还是可以认为是局部变量。
栈:由系统自动分配。 例如,声明在函数中一个局部变量 int b;系统自动在栈中为b开辟空间。
3、系统响应方面:
堆:操作系统有一个记录空闲内存地址的链表,当系统收到程序的申请时,会遍历该链表,寻找第一个空间大于所申请空间的堆结点,然后将该结点从空闲结点链表中删除,并将该结点的空间分配给程序,另外,对于大多数系统,会在这块内存空间中的首地址处记录本次分配的大小,这样代码中的delete语句才能正确的释放本内存空间。另外由于找到的堆结点的大小不一定正好等于申请的大小,系统会自动的将多余的那部分重新放入空闲链表中。
栈:只要栈的剩余空间大于所申请空间,系统将为程序提供内存,否则将报异常提示栈溢出。
4、大小限制方面:
堆:是向高地址扩展的数据结构,是不连续的内存区域。这是由于系统是用链表来存储的空闲内存地址的,自然是不连续的,而链表的遍历方向是由低地址向高地址。堆的大小受限于计算机系统中有效的虚拟内存。由此可见,堆获得的空间比较灵活,也比较大。
栈:在Windows下, 栈是向低地址扩展的数据结构,是一块连续的内存的区域。这句话的意思是栈顶的地址和栈的最大容量是系统预先规定好的,在WINDOWS下,栈的大小是固定的(是一个编译时就确定的常数),如果申请的空间超过栈的剩余空间时,将提示overflow。因此,能从栈获得的空间较小。
5、效率方面:
堆:是由new分配的内存,一般速度比较慢,而且容易产生内存碎片,不过用起来最方便,另外,在WINDOWS下,最好的方式是用VirtualAlloc分配内存,他不是在堆,也不是在栈是直接在进程的地址空间中保留一快内存,虽然用起来最不方便。但是速度快,也最灵活。
栈:由系统自动分配,速度较快。但程序员是无法控制的。
6、存放内容方面:
堆:一般是在堆的头部用一个字节存放堆的大小。堆中的具体内容有程序员安排。
栈:在函数调用时第一个进栈的是主函数中后的下一条指令(函数调用语句的下一条可执行语句)的地址然后是函数的各个参数,在大多数的C编译器中,参数是由右往左入栈,然后是函数中的局部变量。 注意: 静态变量是不入栈的。当本次函数调用结束后,局部变量先出栈,然后是参数,最后栈顶指针指向最开始存的地址,也就是主函数中的下一条指令,程序由该点继续运行。
7、存取效率方面:
堆:char *s1 = "Hellow Word";是在编译时就确定的;
栈:char s1[] = "Hellow Word"; 是在运行时赋值的;用数组比用指针速度要快一些,因为指针在底层汇编中需要用edx寄存器中转一下,而数组在栈上直接读取。
单例的安全性
懒汉不安全,饿汉安全。
饿汉编译时就分配了空间。
协程是安全。 c++11后,局部静态变量是安全的。
索引失效
https://segmentfault.com/a/1190000021464570
线程池
https://www.bilibili.com/video/BV1dt4y1i7Gt?from=search&seid=8100876741143048826&spm_id_from=333.337.0.0
- 初始化线程池,会创建设置数量的线程,规定最大线程对象数量,等待队列大小,超时时间。
- 当有线程需要执行,线程池里的线程不足的话,线程会进入等待队列,等待队列也满了的话,如果没达到线程池容量上线,就会创建新的线程对象,会先执行新加的任务,而不是从队列中取。当线程对象达到容量上限,等待队列也满了,根据拒绝策略决定,比如直接抛异常。
- 如果线程池里有线程对象超过设置的超时时间还没有任务执行,就会销毁,让出资源。
进程线程协程
https://www.bilibili.com/video/BV1Wr4y1A7DS/?spm_id_from=333.788.videocard.3
真正执行程序的是kernel的thread,当高io任务很小的情况下,会创建很多的routine,是轻量级线程,协程就是routine的一种实现。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号