第一次个人编程作业
一、PSP表格
(2.1)在开始实现程序之前,在附录提供PSP表格记录下你估计将在程序的各个模块的开发上耗费的时间。
(2.2)在你实现完程序之后,在附录提供的PSP表格记录下你在程序的各个模块的开发上实际花费的时间。
| PSP2.1 | ** Personal Software Process Stages** | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| Estimate | 估计这个任务要多久 | 10 | 30 |
| Development | 开发 | ||
| Analysis | 需求分析(包括学习新技术) | 360 | 420 |
| Design Spec | 生成设计文档 | 30 | 25 |
| Design Review | 设计复审 | 10 | 30 |
| Coding Standard | 代码规范(为目前的开发制定合适的规范) | 30 | 15 |
| Design | 具体设计 | 120 | 150 |
| Coding | 具体代码 | 200 | 300 |
| Code Review | 代码复审 | 60 | 60 |
| Test | 测试(自我测试,修改代码,提交修改) | 75 | 90 |
| Reporting | 报告 | 40 | 60 |
| Test Repor | 测试报告 | 40 | 30 |
| Size Measurement | 计算工作量 | 30 | 40 |
| Postmortem & Process Improvement Plan | 事后总结,并提出过程改进计划 | 15 | 30 |
| 合计 | 1010 | 1250 |
二、计算机接口
(3.1)计算模块接口的设计与实现过程。设计包括代码如何组织,比如会有几个类,几个函数,他们之间关系如何,关键函数是否需要画出流程图?说明你的算法的关键(不必列出源代码),以及独到之处。
3.1.1类与函数的设计
只定义了一个类,所有函数都封装在里面
qbTransform函数:敏感字转化
sensitive函数:敏感字搜索
Initialization函数:初始化
ReadText()函数:读入文本
OutFlie函数:输出文件
3.1.2算法的关键与独到之处
作为一个新手,我参考了CSDN上的[DFA算法]( https://blog.csdn.net/tigerfz/article/details/53376338),由于我还不会python和java,所以我用C++写的,无法查出谐音替代和拆分部首偏旁的违规字。
算法的关键主要是用敏感词库进行过滤检测,如果检测到当前文字是词库里的一个结点,则进入下一个文字**继续**搜索,如果不是,则进入下一个文字**重新**排查 。
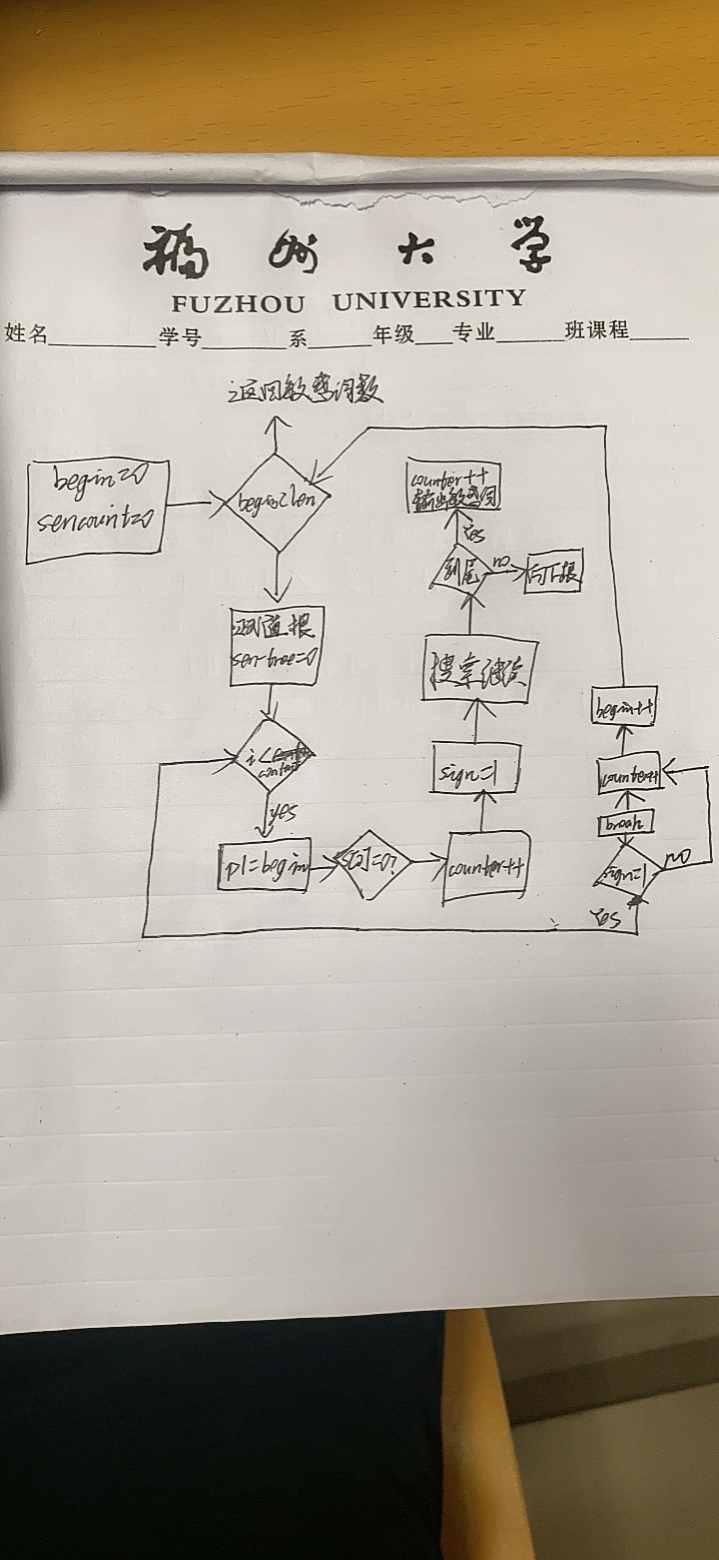
(3.2)计算模块接口部分的性能改进。记录在改进计算模块性能上所花费的时间,描述你改进的思路,并展示一张性能分析图(由VS 2019、JProfiler或者Jetbrains系列IDE自带的Profiler的性能分析工具自动生成),并展示你程序中消耗最大的函数。
因为对算法的了解不够,我对性能的改进没有太多的想法,只能对照CSDN的源码,修改一下算法冗余的判断和循环条件,以下是性能分析图。

覆盖率测试

耗时最大的是DFA算法的函数
def initSensitiveWordMap(sensitiveWordSet):
"""
初始化敏感词库,构建DFA算法模型
:param sensitiveWordSet: 敏感词库,包括词语和其对应的敏感类别
:return: DFA模型
"""
sensitiveWordMap=dict()
for category,key in sensitiveWordSet:
if type(key)=='unicode' and type(category)=='unicode' : #转换为unicode
pass
else:
key=unicode(key)
category=unicode(category)
nowMap = sensitiveWordMap
for i in range(len(key)):
keyChar =key[i] # 转换成char型
wordMap = nowMap.get(keyChar) #库中获取关键字
#如果存在该key,直接赋值,用于下一个循环获取
if wordMap != None:
nowMap =wordMap
else:
#不存在则构建一个map,同时将isEnd设置为0,因为不是最后一个
newWorMap = dict()
#不是最后一个
newWorMap["isEnd"]="0"
nowMap[keyChar]=newWorMap
nowMap = newWorMap
#最后一个
if i ==len(key)-1:
nowMap["isEnd"]="1"
nowMap["category"]=category
return sensitiveWordMap
def checkSensitiveWord(txt,beginIndex,matchType=MinMatchType):
"""
检查文字中是否包含敏感字符
:param txt:待检测的文本
:param beginIndex: 调用getSensitiveWord时输入的参数,获取词语的上边界index
:param matchType:匹配规则 1:最小匹配规则,2:最大匹配规则
:return:如果存在,则返回敏感词字符的长度,不存在返回0
"""
flag=False
category=""
matchFlag=0 #敏感词的长度
nowMap=sensitiveWordMap
tmpFlag=0 #包括特殊字符的敏感词的长度
# print "len(txt)",len(txt) #9
for i in range(beginIndex,len(txt)):
word = txt[i]
#检测是否是特殊字符,eg"..."
if word in stopWordSet and len(nowMap)<100:
#len(nowMap)<100 保证已经找到这个词的开头之后出现的特殊字符
#eg"情节中,.."这个逗号不会被检测
tmpFlag += 1
continue
#获取指定key
nowMap=nowMap.get(word)
if nowMap !=None: #存在,则判断是否为最后一个
#找到相应key,匹配标识+1
matchFlag+=1
tmpFlag+=1
#如果为最后一个匹配规则,结束循环,返回匹配标识数
if nowMap.get("isEnd")=="1":
#结束标志位为true
flag=True
category=nowMap.get("category")
#最小规则,直接返回,最大规则还需继续查找
if matchType==MinMatchType:
break
else: #不存在,直接返回
break
if matchFlag<2 or not flag: #长度必须大于等于1,为词
tmpFlag=0
return tmpFlag,category
def contains(txt,matchType=MinMatchType):
"""
判断文字是否包含敏感字符
:param txt: 待检测的文本
:param matchType: 匹配规则 1:最小匹配规则,2:最大匹配规则
:return: 若包含返回true,否则返回false
"""
flag=False
for i in range(len(txt)):
matchFlag=checkSensitiveWord(txt,i,matchType)[0]
if matchFlag>0:
flag=True
return flag
def getSensitiveWord(txt,matchType=MinMatchType):
"""
获取文字中的敏感词
:param txt: 待检测的文本
:param matchType: 匹配规则 1:最小匹配规则,2:最大匹配规则
:return:文字中的敏感词
"""
sensitiveWordList=list()
for i in range(len(txt)): #0---11
length = checkSensitiveWord(txt, i, matchType)[0]
category=checkSensitiveWord(txt, i, matchType)[1]
if length>0:
word=txt[i:i + length]
sensitiveWordList.append(category+":"+word)
i = i + length - 1
return sensitiveWordList
(3.3)计算模块部分单元测试展示。展示出项目部分单元测试代码,并说明测试的函数,构造测试数据的思路。并将单元测试得到的测试覆盖率截图,发表在博客中。
测试代码如下:
import main
import unittest
def replaceSensitiveWord(txt, replaceChar, matchType=MinMatchType):
"""
替换敏感字字符
:param txt: 待检测的文本
:param replaceChar:用于替换的字符,匹配的敏感词以字符逐个替换,如"你是大王八",敏感词"王八",替换字符*,替换结果"你是大**"
:param matchType: 匹配规则 1:最小匹配规则,2:最大匹配规则
:return:替换敏感字字符后的文本
"""
tupleSet = getSensitiveWord(txt, matchType)
wordSet=[i.split(":")[1] for i in tupleSet]
resultTxt=""
if len(wordSet)>0: #如果检测出了敏感词,则返回替换后的文本
for word in wordSet:
replaceString=len(word)*replaceChar
txt = txt.replace(word, replaceString)
resultTxt=txt
else: #没有检测出敏感词,则返回原文本
resultTxt = txt
return resultTxt
作业的样例测试图:

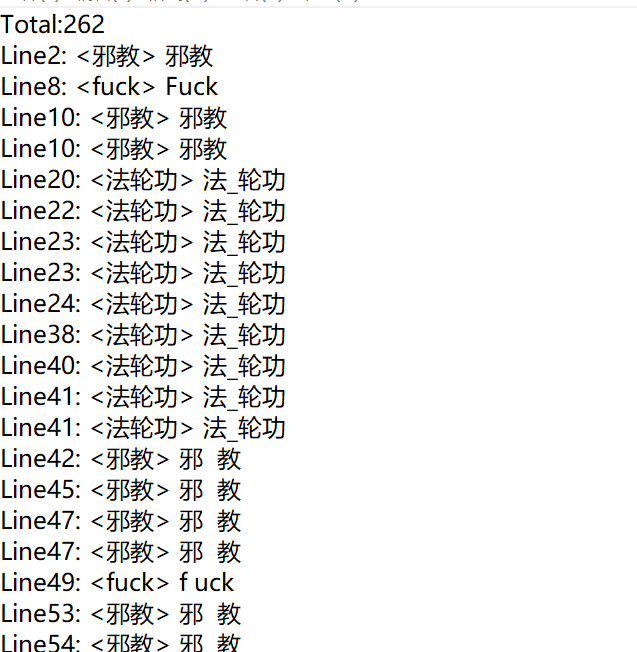
只测试了两百多个样例,没有达到更好的水平,只要是没有做到谐音字和部首偏旁拆分字的检测,希望接下来可以学会如何检测。
(3.4)计算模块部分异常处理说明。在博客中详细介绍每种异常的设计目标。每种异常都要选择一个单元测试样例发布在博客中,并指明错误对应的场景。
1。不知道怎么存储和输出中文,用string类型输出会变成符号。
解决方法:用wstring类型来存储数据,用wcin和wcout来输入输出。
2。用VS2019测试text文本读写功能时,出现了中文输出的乱码现象。
解决方法:将VS设置成utf-8编码,并且在main函数开始处加入语句:locale china("zh_CN.UTF-8");并使用locale头文件。
三、心得
没想到刚开课就要写这么难的作业,这次作业让我发现了自己的许多不足,也让我渴望摆脱小菜鸟称号的欲望越来越强烈。这次做的可能连及格都很难,因为很多样例没有测出来,对于算法的性能改进也没做到位,只能说马马虎虎完成作业(但是人真的尽力了,累趴了……)。希望老师和测试组的同学们给分宽容一些,让我混一混吧。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号