

Redis基础
Redis快速的原因:
1.redis是基于内存的,内存的读写速度非常快;
2.redis是单线程的,省去了很多上下文切换线程的时间;
3.redis使用多路复用技术,可以处理并发的连接。非阻塞IO 内部实现采用epoll,采用了epoll+自己实现的简单的事件框架。epoll中的读、写、关闭、连接都转化成了事件,然后利用epoll的多路复用特性,绝不在io上浪费一点时间。
采用单线程的原因?
Redis是基于内存的操作,CPU不是Redis的瓶颈,Redis的瓶颈最有可能是机器内存的大小或者网络带宽。既然单线程容易实现,而且CPU不会成为瓶颈,那就顺理成章地采用单线程的方案了。
使用Redis缓存的好处:
1.降低后端的负载:
对高消耗的SQL:join结果集/分组统计结果缓存
2.加速请求时间:
在内存中做IO操作很快
3.大量写合并为批量写:
频繁更新某一个值,可以在缓存层面统一处理了,再写入到数据库中。
Redis几种基本类型
string类型:
-
缓存功能:String字符串是最常用的数据类型,不仅仅是Redis,各个语言都是最基本类型,因此,利用Redis作为缓存,配合其它数据库作为存储层,利用Redis支持高并发的特点,可以大大加快系统的读写速度、以及降低后端数据库的压力。
-
计数器:许多系统都会使用Redis作为系统的实时计数器,可以快速实现计数和查询的功能。而且最终的数据结果可以按照特定的时间落地到数据库或者其它存储介质当中进行永久保存。
-
共享用户Session:用户重新刷新一次界面,可能需要访问一下数据进行重新登录,或者访问页面缓存Cookie,但是可以利用Redis将用户的Session集中管理,在这种模式只需要保证Redis的高可用,每次用户Session的更新和获取都可以快速完成。大大提高效率。
set key value/get key/incr key/mset k1 v1 k2 v2/mget k1 k2
hash类型:
类似 Map 的一种结构,这个一般就是可以将结构化的数据,比如一个对象(前提是这个对象没嵌套其他的对象)给缓存在 Redis 里,然后每次读写缓存的时候,可以就操作 Hash 里的某个字段。
hset filed key1 value1/hexists field key/hget filed keys/hgetall field
list类型:
通常用来存储文章列表,评论列表还可以作为消息队列
lpush list-name value/lpop list-name value
set类型:
Set 是无序集合,会自动去重的,redis本身提供了交集,并集等功能
zset类型:
带排序的set
其他还有bitmap、Geospatial、HyperLogLog等
Redis事务:
最后一个功能是事务,但 Redis 提供的不是严格的事务,Redis 只保证串行执行命令,并且能保证全部执行,但是执行命令失败时并不会回滚,而是会继续执行下去。
Redis持久化:
Redis 提供了 RDB 和 AOF 两种持久化方式,RDB 是把内存中的数据集以快照形式写入磁盘,实际操作是通过 fork 子进程执行,采用二进制压缩存储;AOF 是以文本日志的形式记录 Redis 处理的每一个写入或删除操作。
RDB 把整个 Redis 的数据保存在单一文件中,比较适合用来做灾备,但缺点是快照保存完成之前如果宕机,这段时间的数据将会丢失,另外保存快照时可能导致服务短时间不可用。
AOF 对日志文件的写入操作使用的追加模式,有灵活的同步策略,支持每秒同步、每次修改同步和不同步,缺点就是相同规模的数据集,AOF 要大于 RDB,AOF 在运行效率上往往会慢于 RDB。
RDB可以理解为镜像全量持久化,AOF理解为增量持久化。因为RDB会耗费较长时间,不够实时,在停机的时候会导致大量丢失数据,所以需要AOF来配合使用。在redis实例重启时,会使用RDB持久化文件重新构建内存,再使用AOF重放近期的操作指令来实现完整恢复重启之前的状态。
对与机器突然挂掉这种情况的数据同步?
取决于AOF日志sync属性的配置,如果不要求性能,在每条写指令时都sync一下磁盘,就不会丢失数据。但是在高性能的要求下每次都sync是不现实的,一般都使用定时sync,比如everysec,这个时候最多就会丢失1s的数据。
AOF有这样几种策略:

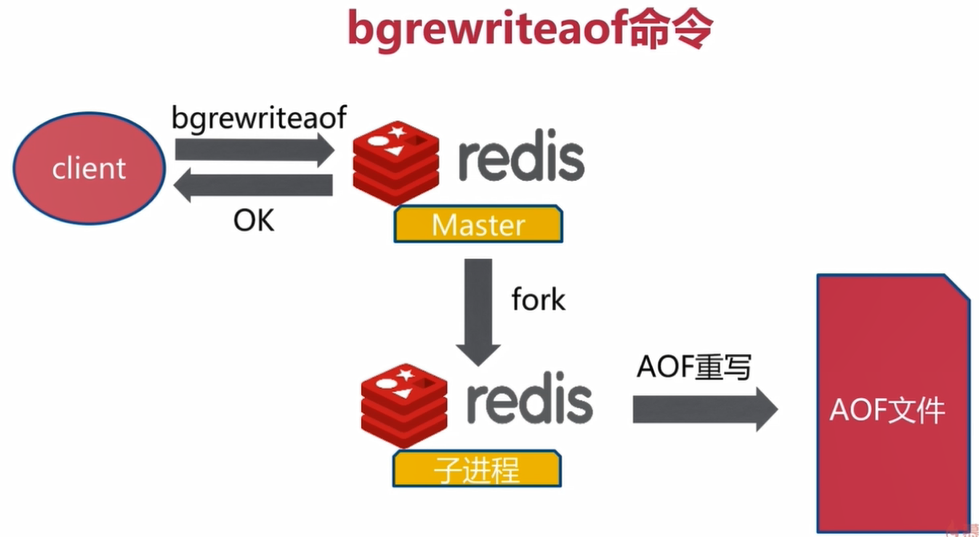
AOF重写:重复的过期的数据覆盖(可以减少磁盘占用量,加速恢复速度)
AOF重写功能就是把Redis中过期的,不再使用的,重复的以及一些可以优化的命令进行优化,重新生成一个新的AOF文件,从而达到减少硬盘占用量和加速Redis恢复速度的目的,对于AOF重写其实也是fork()一个新的进程去操作
RDB的原理是什么?
fork是指redis通过创建子进程来进行RDB操作,cow指的是copy on write,子进程创建后,父子进程共享数据段,父进程继续提供读写服务,写脏的页面数据会逐渐和子进程分离开来。
AOF和RDB适用场景:
RDB 持久化适合大规模的数据恢复但它的数据一致性和完整性较差。因此我们在主从复制,我们只会在从节点上做持久化,或者时间间隔很久的记录,我们采用这种方式(比如对一天的数据进行持久化)
AOF 的数据完整性比RDB高,但记录内容多了,会影响数据恢复的效率(我们有AOF重写机制来解决部分问题)。
Redis 4.0 对于持久化机制的优化
Redis 4.0 开始支持 RDB 和 AOF 的混合持久化(默认关闭,可以通过配置项 aof-use-rdb-preamble 开启)。
如果把混合持久化打开,AOF 重写的时候就直接把 RDB 的内容写到 AOF 文件开头。这样做的好处是可以结合 RDB 和 AOF 的优点, 快速加载同时避免丢失过多的数据。当然缺点也是有的, AOF 里面的 RDB 部分是压缩格式不再是 AOF 格式,可读性较差。
登陆redis命令
redis-cli -h xxxxx.rds.aliyuncs.com -p 6379
auth pwd
本文来自博客园,作者:LeeJuly,转载请注明原文链接:https://www.cnblogs.com/peterleee/p/11416752.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号