
Redis主从复制
主从复制配置:
在 slave 上:
slaveof ip port 就可以将从节点复制到主节点上面
slaveof no one 这个slave节点不能成为任何节点的从节点
全量复制:
在主节点向从节点复制时,除了生成当前RDB文件,从节点通过这个RDB文件来实现复制,同样在主节点生成这个RDB文件的过程中,也可能还会有节点向主节点写入,这一部分写入的数据会被写入到一个缓冲区,再发送给slave节点RDB文件以后会再发送给slave节点缓冲区文件,这样就可以保证主从节点之间的完全同步。
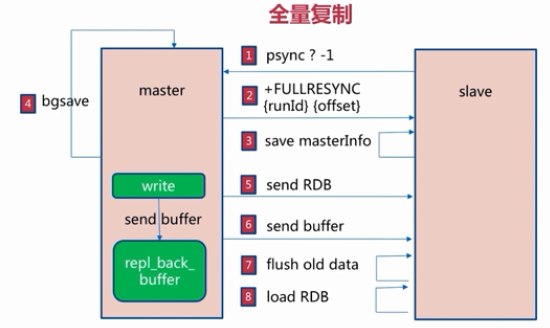
具体过程
1.在slave第一次向master同步数据时,不知道master的run_id和offset,使用`psync ? -1`命令向master发起同步请求 2.master接受请求后,知道slave是做全量复制,master就会把run_id和offset响应给slave 3.slave保存master发送过来的run_id和offset 4.master响应slave后,执行BGSAVE命令把当前所有数据生成RDB文件,然后将RDB文件同步给slave 5.Redis中的repl_back_buffer复制缓冲区可以记录生成RDB文件之后到同步完成这个时间段时写入的数据,然后把这些数据也同步给slave 6.slave执行flushall命令清空slave中原有的数据,然后从RDB文件读取所有的数据,保证slave与master中数据的同步
部分复制:
主要针对避免频繁的全量复制(要尽量避免全量复制,如果非要做全量复制,我们要尽量在小节点和低峰比如夜间这样的时间做全量复制),比如网络波动,丢失一小部分数据,就进行全量复制是非常不划算的。(这里主要利用的就是主节点在写入的时候会有一个缓冲区,这是一个队列,一般是1m大小,这个范围太小也会产生全量复制)
slave节点只用传输offset和runId可以避免全量复制带来的开销。
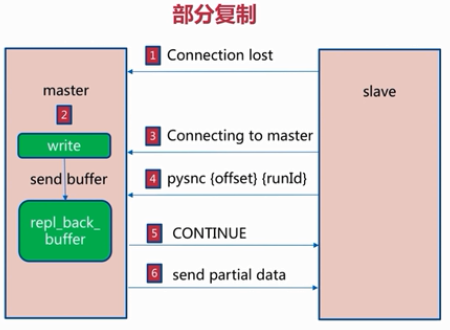
当master与slave之间的连接断开时,master在写入数据同时也会把写入的数据保存到repl_back_buffer复制缓冲区中
当master与slave之间的网络连通后,slave会执行psync {offset} {run_id}命令,offset是slave节点上的偏移量
master接收到slave传输的偏移量,会与repl_back_buffer复制缓冲区中的offset做对比,
如果接收到的offset小于repl_back_buffer中记录的偏移量,master就会把两个偏移量之间的数据发送给slave,slave同步完成,slave中的数据就与master中的数据一致
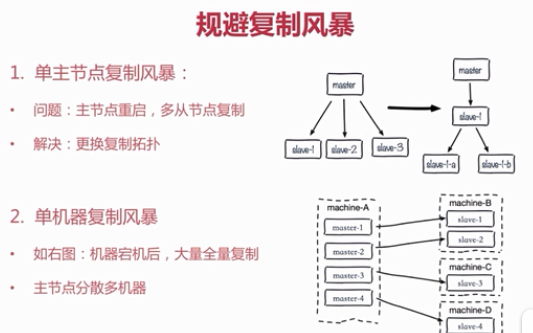
规避复制风暴:主要是针对主节点重启的时候,带来的大量复制。
主从复制故障:
master-slave:在主结点上开持久化,主结点不对外提供查询,查询由slave结点提供,从结点不提供持久化;这样,所有的fork耗时的操作都在主结点上,而查询请求由slave结点提供;
对于主从节点出现故障的故障自动转移:(这里我们只讨论一主多从)
slave节点宕掉,直接将这个节点的读操作转移到其他slave节点上面,这个问题很好解决。
master节点宕掉
1.把其中一个slave为成master,以提供写入数据功能,另外一台slave重新做为新的master的从节点,提供读取数据功能,这种解决方法依然需要手动完成
2.以下这种方案:
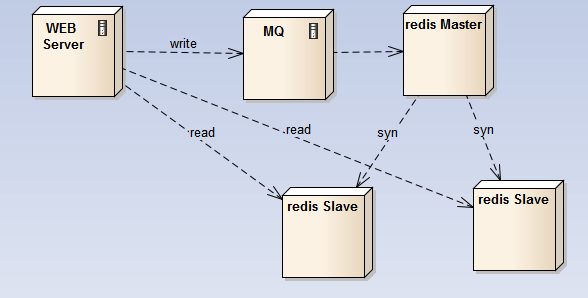
主节点不具有可替代性,坏了之后,redis集群对外就只能提供读,而无法更新;待主结点启动后,再继续更新操作;对于之前的更新操作,可以用MQ缓存起来,等主结点起来之后消化掉故障期间的写请求;
开发运维中的问题
读写分离:在我们的业务中通常都是读多,写少,所以可以将读流量分摊到从节点。
1.复制数据延迟:
大多数情况下,master采用异步方式将数据同步给slave,在这个过程中会有一个时间差
当slave遇到阻塞时,接收数据会有一定延迟,在这个时间段内从slave读取数据可能会出现数据不一致的情况
可以对master和slave的offset值进行监控,当offset值相差过多时,可以把读流量转换到master上,但是这种方式有一定的成本
2.读到过期数据
读到过期的数据(因为我们规定子节点只能读数据不能删除数据,所以是可能产生很多过期数据的)
3.节点故障的转移
4.主从配置不一致
master节点分配的内存为4G,而slave节点分配的内存只有2G时,此时虽然可以进行正常的主从复制
但当slave从master同步的数据大于2G时,slave不会抛出异常,但会触发slave节点的maxmemory-policy策略,对同步的数据进行一部分的淘汰,此时slave中的数据已经不完整了,造成丢失数据的情况
5.避免全量复制
当master重启时,master的run_id会发生变化。slave在同步数据时发现之前保存的master的run_id与现在的run_id不匹配,会认为当前master不安全,我们就会做全量复制
Redis4.0版本中提供新的方法:当master的run_id发生改变时,做故障转移可以避免做全量复制
复制缓冲区不足也会导致我们做全量复制。在配置文件中修改rel_backlog_size选项来加大复制缓冲区的大小,来减少全量复制的情况出现
本文来自博客园,作者:LeeJuly,转载请注明原文链接:https://www.cnblogs.com/peterleee/p/10701375.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号