第一次个人编程作业
https://github.com/peter456963/PlagiarismCheck
项目信息
| 问题 | 内容 |
|---|---|
| 作业要求 | 要求链接 |
| 所属班级 | 班级链接 |
| 作业目标 | 初步学习git的使用 |
| 学号 | 3123001598 |
| Github仓库 | 仓库链接 |
PSP表
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 40 | 30 |
| · Estimate | · 估计这个任务需要多少时间 | 815 | 930 |
| Development | 开发 | 250 | 250 |
| · Analysis | · 需求分析(包括学习新技术) | 110 | 150 |
| · Design Spec | · 生成设计文档 | 40 | 50 |
| · Design Review | · 设计复审 | 15 | 20 |
| · Coding Standard | · 代码规范(为目前的环境制定合适的规范) | 10 | 15 |
| · Design | · 具体设计 | 60 | 50 |
| · Coding | · 具体编码 | 120 | 180 |
| · Code Review | · 代码复审 | 10 | 15 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 40 | 45 |
| Reporting | 报告 | 50 | 55 |
| · Test Report | · 测试报告 | 30 | 40 |
| · Size Measurement | · 计算工作量 | 30 | 25 |
| · Postmortem & Process Improvement Plan | · 事后总结,并提出过程改进计划 | 10 | 5 |
| Total | · 合计 | 815 | 930 |
算法与主要接口设计
在算法方面,首先在预处理阶段,程序会去掉文本的中英文标点,并将中文分词,即词之间以空格隔开。之后,两篇文档的所有词按TF-IDF值转成两个数字向量。最后,通过两个向量的方向是否接近来计算相似度。
该算法的独到之处是针对中文文本特性,通过混合标点清洗+Jieba精准分词,结合TF-IDF自动降权高频词和余弦相似度计算,实现了轻量高效的文本比对,适用于快速查重场景。
在接口设计方面,下面的表展示了核心函数的功能。
| 接口 | 功能 |
|---|---|
| get_file_context | 获得文件的内容 |
| remove_punctuation | 删除文字的中文标点符号和英文标点符号 |
| tokenize_with_spaces | 中文分词,之间以空格隔开 |
| get_similarity_score | 计算两段文字的相似度,返回浮点数,范围在0到1之间 |
| main | 主程序,根据对应参数,计算相似度,并将其写入指定文件 |
性能分析
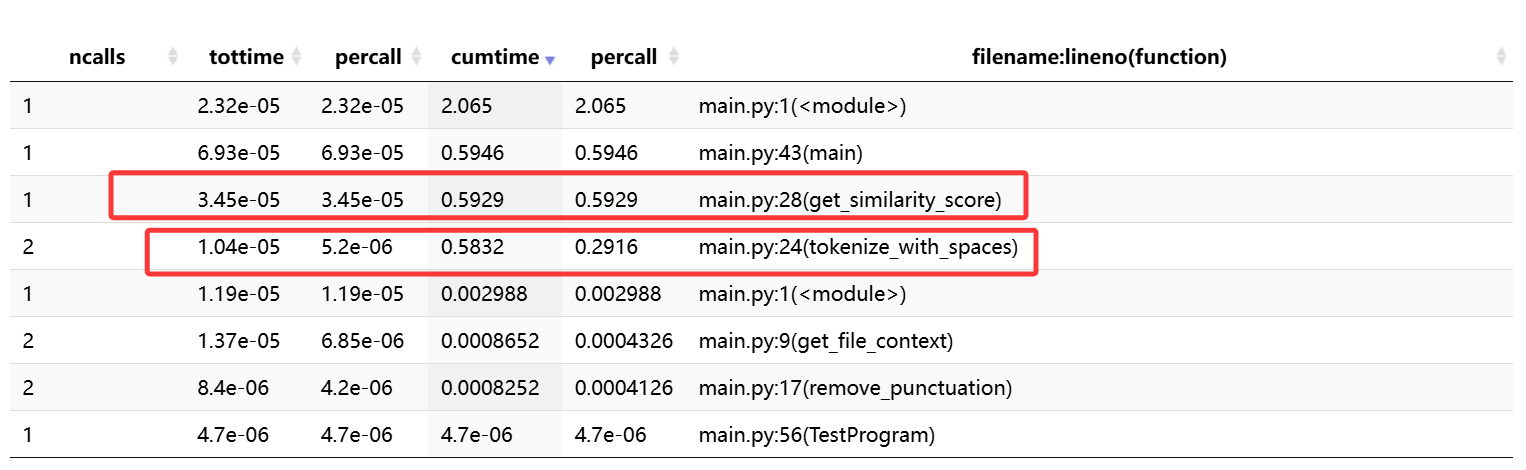
在CPU资源方面,tokenize_with_spaces函数和get_similarity_score函数运行均接近0.6s。
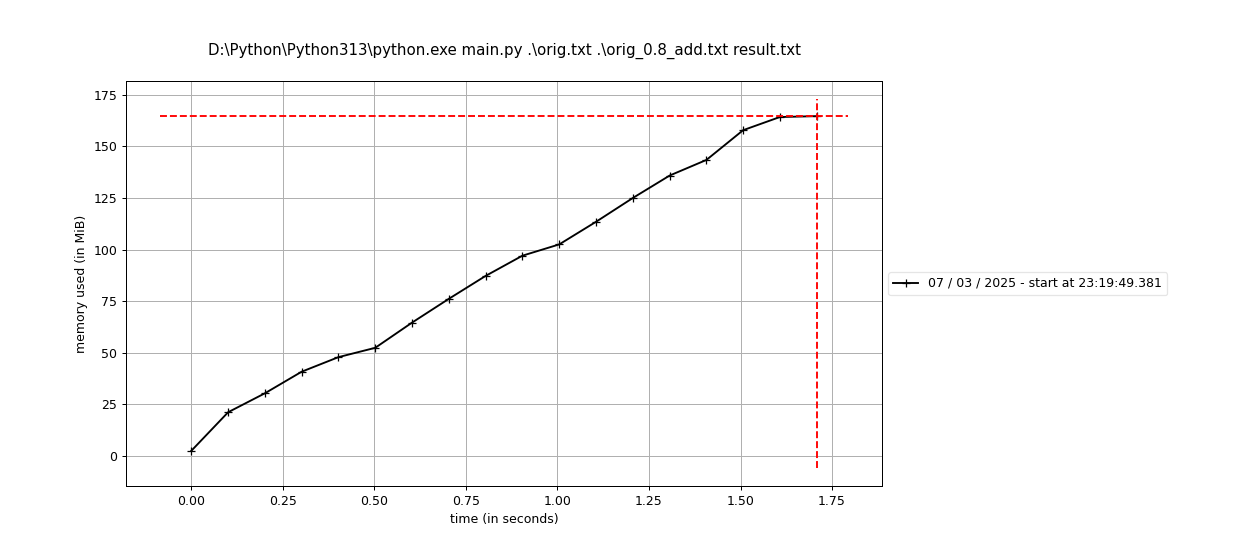
在内存资源方面,程序内存占用最高到168MB左右。
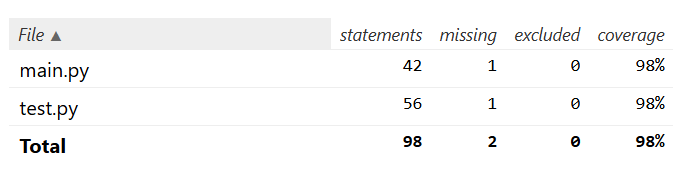
单元测试
异常处理
该设计防止因用户输入不存在的文件路径而程序发生未知行为。当用户输入错误的文件路径,系统会提醒用户找不到该文件。
def get_file_context(file_path):
if(os.path.exists(file_path) == False):
raise FileNotFoundError(f"找不到 '{file_path}' 文件!");
with open(file_path, 'r', encoding='utf-8') as file:
return file.read()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号