
mysql group by语句流程是怎么样的
group by流程是怎么样的
注意点:
select id%10 as m, count(*) as c from t1 group by m;
-
group by是用于对数据进行分组,我们排序用到了sort_buff,join用到了join_buff,group by就会用到
内部临时表。join_buffer 是无序数组,sort_buffer 是有序数组,临时表是二维表结构; -
多使用explain分析sql语句,在 Extra 字段里面,我们可以看到三个信息:
- Using index,表示这个语句使用了覆盖索引,选择了索引 a,不需要回表;
- Using temporary,表示使用了临时表;
- Using filesort,表示需要排序。
- 使用内部临时表默认都是引擎,union和人工创建临时表都是使用到临时表。
- 如果你的需求并不需要对结果进行排序,那你可以在 SQL 语句末尾增加 order by null。
- 内存临时表也会有大小限制,如果临时表空间放不下数据,也会使用磁盘空间作为临时表的空间
- group by 的字段尽可能也需要索引,有序的数据, 在执行就可能不需要排序和临时表了。
- group by优化还可以不使用临时表,比如大量数据group by,临时表空间肯定不够,你可以在 group by 语句中加入 SQL_BIG_RESULT 这个提示(hint),就可以告诉优化器:这个语句涉及的数据量很大,请直接用磁盘临时表。这种情况下在explain就不会有使用了临时表的关键字了。直接排序使数据有序。有序数据就直接使用第6点性能优化。
流程如下:
- 创建内存临时表,表里有两个字段 m 和 c,主键是 m;
- 扫描表 t1 的索引 a,依次取出叶子节点上的 id 值,计算 id%10 的结果,记为 x;
- 如果临时表中没有主键为 x 的行,就插入一个记录 (x,1);如果表中有主键为 x 的行,就将 x 这一行的 c 值加 1;
- 遍历完成后,再根据字段 m 做排序,得到结果集返回给客户端。
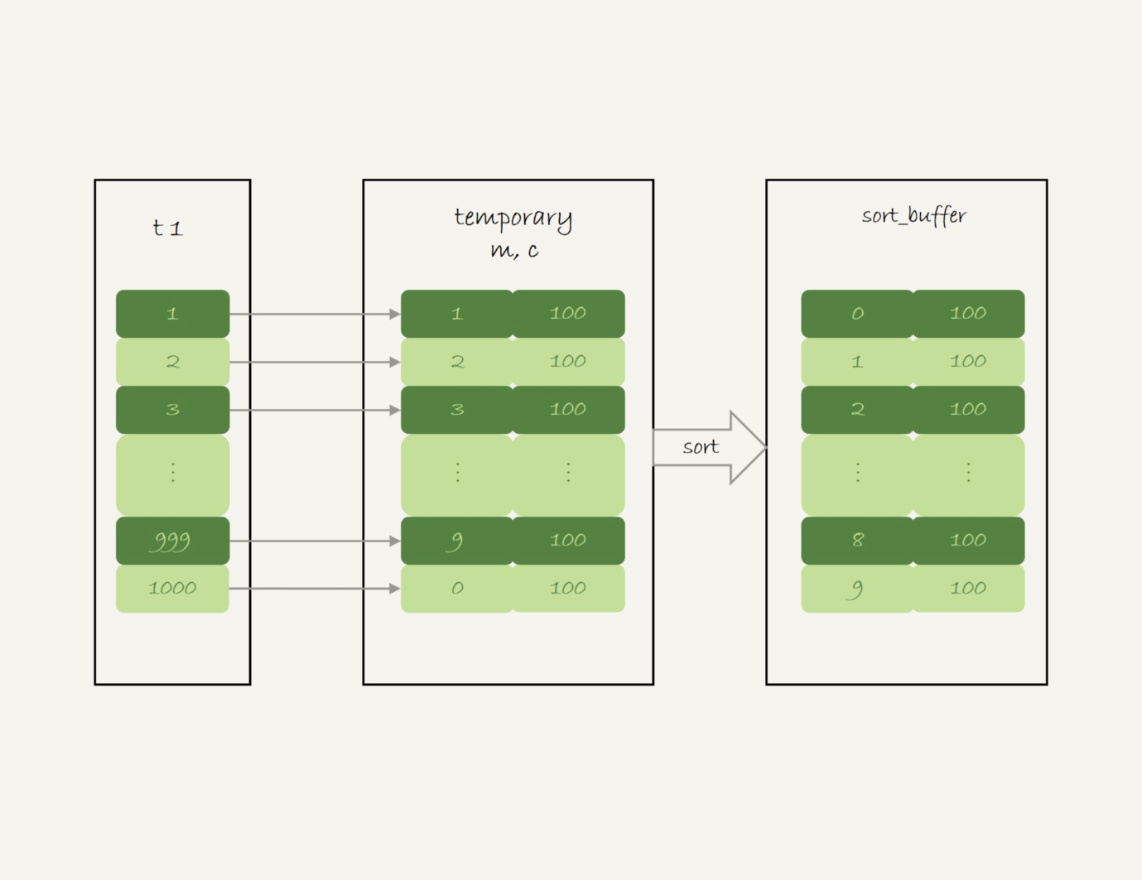
这个语句需要排序,排序过程参考如下:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号