

09_昇腾适配GR模型实践
昇腾适配GR(生成式推荐)模型实践
摘要/引言
- 简要介绍GR模型在生成式推荐领域的重要性。
- 阐述将GR模型适配到昇腾NPU的战略意义与技术挑战。
- 概述本文将要展示的适配路径、关键技术与最终成果。
一、 GR模型核心原理
1.1 GR模型背景介绍
生成式推荐的兴起是推荐系统领域应对互联网“存量时代”挑战的一次根本性范式变革。传统基于深度学习的判别式推荐模型(如DIN、DIEN)依赖于复杂的多阶段 pipeline(召回 -> 粗排 -> 精排 -> 重排)和人工特征工程,将推荐问题定义为孤立的点击率预估,难以捕捉用户行为的序列依赖性,且易受曝光数据偏差的影响,导致“信息茧房”和长尾物品推荐效果不佳。
与此同时,生成式AI技术,特别是Transformer架构和大语言模型(LLM)的成功,证明了生成式模型在序列建模和内容生成方面的强大能力。这促使推荐系统将问题重新定义为“序列生成任务”——即根据用户的历史行为序列,直接生成下一个可能的交互物品。这一转变不仅自然融入了序列上下文信息,更为实现端到端的统一建模、提升推荐的智能化水平和个性化内容生成开辟了全新路径。因此,生成式推荐代表了从“判别匹配”到“生成序列”的战略性演进,是技术发展的必然趋势。
生成式推荐模型相较于传统深度学习推荐模型,在技术栈的五个核心模块上实现了范式级的创新与突破。下表系统对比了二者在各模块的核心做法与根本差异:

1.2 GR模型核心思想介绍
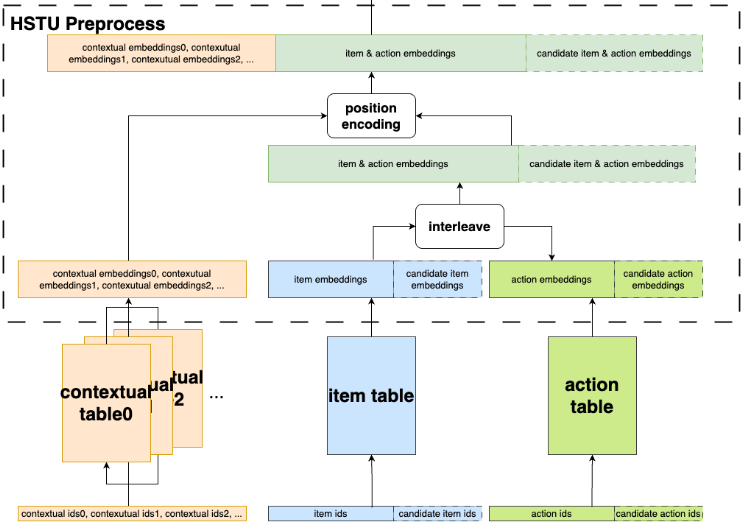
理解核心思想:流程将推荐任务从独立的“用户-物品”匹配问题,转变为基于历史序列预测下一个物品的生成问题。例如,图片中的“interleave”操作将物品和行为嵌入交错组合,形成连续的序列输入,直接支持序列到序列的建模。这要求模型能够处理用户行为序列,并生成下一个可能的交互项。
下图中的HSTU Preprocess流程图直观地展现了GR模型核心思想的具体实现。该流程通过多步骤处理,将异构特征(如上下文(contextual tables)、物品(item table)和行为(action table))统一转化为序列化的嵌入表示:首先,从contextual tables、item table和action table中提取对应的嵌入向量;随后,通过interleave操作将物品与候选物品、行为与候选行为的嵌入进行交错组合,形成统一的序列表示;最后,引入position encoding对序列进行位置编码,以重构数据流。这一系列操作巧妙地将传统排序/检索任务重构为序列生成任务(transduction),为后续的生成式推荐建模奠定了基础。
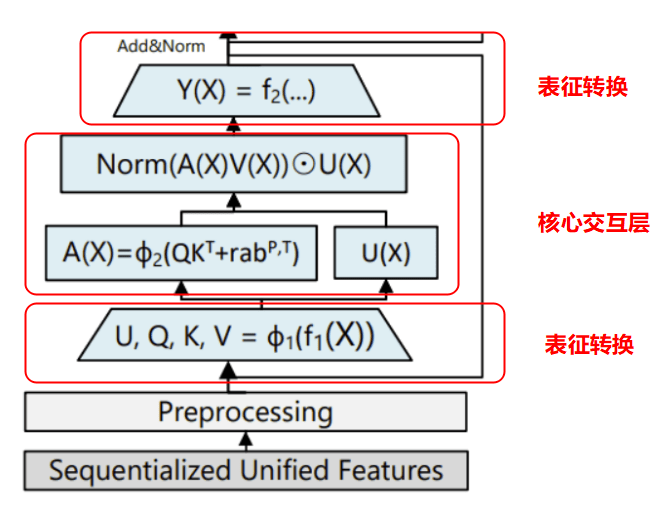
1.3 HSTU模块网络架构
HSTU(Hierarchical Sequential Transduction Unit)是一种基于Transformer架构的层次化序列转换单元,专为生成式推荐系统设计。
HSTU模块输入为“Sequentialized Unified Features”,即序列化后的统一特征,这些特征通常来自用户行为序列(如itemID、时间戳、行为类型等类别型特征),经过预处理( Preprocess)转化为稠密向量。
如下图所示,hstu模块网络框架主要分为三个模块:
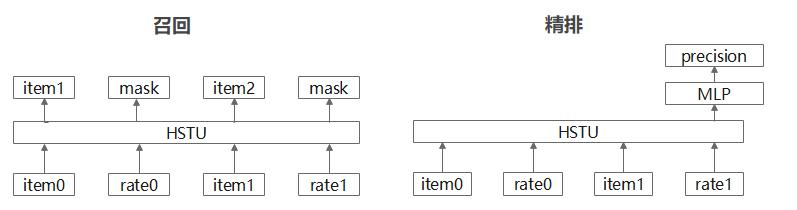
1.4 GR模型特点概述
生成式推荐系统一体化建模
使用同一个基础模型(HSTU),通过不同的输入构建方式和任务目标,来同时解决召回和排序两大任务。
召回任务:为每个用户学习概率分布,整个模型输出一个表征。图中显示了召回阶段的结构,其中包含item0、rate0、item1、rate1等输入,通过HSTU模块处理后,输出预测内容item1、item2等结果。捕获用户长期、宏观的兴趣偏好。
排序任务:交错插入物品(item)和动作(action)来进行建模,在action上进行mask来做预测。图中显示了精排阶段的结构,其中包含item0、rate0、item1、rate1等输入,通过HSTU模块处理后,再经过MLP模块,最终输出precision,即候选物品的点击概率。
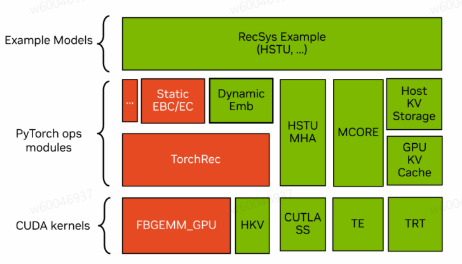
支持超大规模参数训练
-
超大规模嵌入表存储:基于TorchRec::DynamicEmbedding动态管理千亿级参数,解决内存瓶颈。
-
长序列注意力计算效率:优化HSTU Attention CUDA内核,结合fbgemm_gpu加速矩阵运算,提升长序列处理性能。
-
分布式并行训练:依托Megatron-Core支持模型并行、数据并行和分布式优化器,确保高效扩展性。
1.5 适配总体方案
我们的核心适配策略是:以PyTorch框架为基础,利用昇腾提供的torch_npu库进行模型迁移,通过分层、分阶段的算子改造与优化,最终实现GR模型在昇腾硬件上性能与精度均优于或持平GPU的目标。
本样例为开源Generative Recommendations模型, 将其迁移至NPU侧训练,并使用 NPU的HSTU融合算子来实现性能的优化。 模型参考的开源链接为https://github.com/facebookresearch/generative%02recommenders克隆源码并固定版本为:Commits on Dec 16, 2024,提交的SHA-1 hash值(提交ID):bb389f9539b054e7268528efcd35457a6ad52439
验证运行的算力平台:Atlas 800T A2
方案主要围绕以下三个层面展开:
- 模型层:确保GR模型的所有算子能够在NPU上正确执行,重点解决不兼容算子的替换与实现。
- 计算层:针对NPU的硬件特性,对计算密集型算子(如注意力机制、大规模矩阵乘法)进行定制化优化,充分释放算力。
- 数据层:优化数据流水线,减少数据在Host与Device间的传输开销,确保NPU计算单元的高利用率。
二、 昇腾软硬件环境搭建与配置
2.1 环境及配套准备
硬件:800T A2
操作系统:ubuntu 20.04
配套信息:
| torch版本 | 适配依赖版本 |
|---|---|
| torch==2.6.0 | fbgemm_gpu==1.1.0+cpu |
| torch_npu=2.6.0 | torchrec==1.1.0+npu |
| python版本:3.10 | hybrid_torchrec==1.1.0 |
2.1.1 创建并配置昇腾NPU运行容器
参考使用镜像地址:https://www.hiascend.com/developer/ascendhub/detail/rec_sdk-torch 创建启动脚本run_docker.sh,参考如下
docker run -u root -it --privileged --net=host --shm-size="300g" \
--name ${container_name} \
-v /etc/localtime:/etc/localtime \
-e ASCEND_VISIBLE_DEVICES=0-7 \
-v /etc/ascend_install.info:/etc/ascend_install.info \
-v /home:/home \
-v /root/ascend:/root/ascend \
-v /root/.ssh:/root/.ssh \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver \
ascend_torch26_recsdk:v1 \
/bin/bash
# 启动容器
docker start container_name
# 进入容器
docker exec -it container_name bash
2.1.2 基础环境安装:PyTorch, fbgemm, torch_npu
安装torch和fbgemm,torch_npu
pip3 install torch==2.6.0+cpu --index-url https://download.pytorch.org/whl/cpu
pip3 install fbgemm_gpu==1.1.0+cpu --index-url https://download.pytorch.org/whl/cpu
# 下载插件包
wget https://gitcode.com/Ascend/pytorch/releases/download/v7.2.0-pytorch2.6.0/torch_npu-2.6.0.post3-cp310-cp310-manylinux_2_28_aarch64.whl
# 安装命令
pip3 install torch_npu-2.6.0.post3-cp310-cp310-manylinux_2_28_aarch64.whl
安装Rec SDK Torch软件包
git clone https://gitee.com/ascend/RecSDK.git
cd RecSDK/torchrec/
# torchrec,提供分表,查表等功能特性,需要对NPU进行适配操作
# 下载torchrec源码并编译
git clone -b release/v1.1.0 https://github.com/pytorch/torchrec.git
cd torchrec && git checkout 2c5f6ee && cd ..
bash build_whl.sh
# 安装
cd dist
pip3 install torchrec-1.1.0+npu-*.whl
pip3 install -r requirements.txt
# htbrid_torchrec,支持纯HBM方案
cd RecSDK/torchrec/hybrid_torchrec
bash build_whl.sh
cd ../../../
pip3 install RecSDK/torchrec/hybrid_torchrec/dist/hybrid_torchrec-1.1.0+npu-*.whl
# torchrec_embcache,支持多级缓存方案
cd RecSDK/torchrec/torchrec_embcache/src/3rdparty
bash produce_git_modules.sh
#编译+打whl包
bash zbuild.sh
# 安装
cd ./dist
pip3 uninstall -y torchrec-embcache
pip3 install torchrec_embcache-*-py3-none-any.whl
三、 GR模型适配昇腾NPU的关键技术实现
GR模型向昇腾NPU的成功迁移,其核心在于对模型中关键算子的系统性适配与深度优化。首先对一些基础算子尽心底层的NPU适配,确保基础功能的快速打通;进而针对NPU硬件特性,对已有算子进行性能优化以释放算力;对于模型中的核心瓶颈,则通过开发自定义算子来实现性能突破。以下将分别从这三个层面详细阐述我们的关键技术实现。
3.1 直接迁移:基于GPU原始实现的算子适配
以下四个算子是基于Gpu的实现和调用,完整的适配NPU设备。调用接口一致,无迁移工作量。
| 算子API | 接口功能 |
|---|---|
| torch.ops.fbgemm.jagged_to_padded_dense | 将不定长序列张量转为稠密类型,用pad_calue进行填充 |
| torch.ops.fbgemm.dense_to_jagged | 将稠密向量转为不定长向量 |
| torch.ops.fbgemm.permute_2D_sparse_data | 不定长数据进行维度置换或顺序重排 |
| torch.ops.fbgemm.asynchronous_complete_cumsum | 计算输入数组的累加和,生成偏移量数组 |
3.2 性能优化:NPU侧特定优化算子
以下算子在原始算子基础上,添加了昇腾侧自定义的算子功能。
| 算子API | OP Type | 接口功能 |
|---|---|---|
| torch.ops.fbgemm.split_embedding_codegen_lookup_adam_function | SplitEmbeddingCodegenForwardUnweighted | 前向查表 |
| BackwardCodegenAdagradUnweightedExact | adam优化器+稀疏表反向更新融合算子 |
原始torch.ops.fbgemm.split_embedding_codegen_lookup_adam_function算子只提供了前向embedding bag的查询功能。昇腾侧在实现其原始功能的基础上,在C++中注册自动求导,将前向和反向绑定起来,在pytorch的自动求导时可找到其对应的BackwardCodegenAdagradUnweightedExact的算子,将反向梯度计算过程中的dam优化器+稀疏表反向更新组合起来的融合算子,提升运行效率。
3.3 创新优化:NPU侧自定义算子算子开发
针对昇腾硬件架构上的特点,对HSTU模块的注意力机制部分做了许多优化,通过NpuFusedHSTUAttention实现。
| 算子API | 接口功能 |
|---|---|
| torch.ops.mxrec.hstu_dense | hstu注意力机制的前向接口,目前支持四种不同的mask类型 |
| torch.ops.mxrec.hstu_dense_backward | hstu注意力机制的反向接口,支持auto_grad时,自动调用 |
mxrec库是基于昇腾原生的RecSDK进行hstu_dense算子的安装在使用过程中,可以仅调用hstu_dense,反向过程中自动调用hstu_dense_backward算子自动求导。
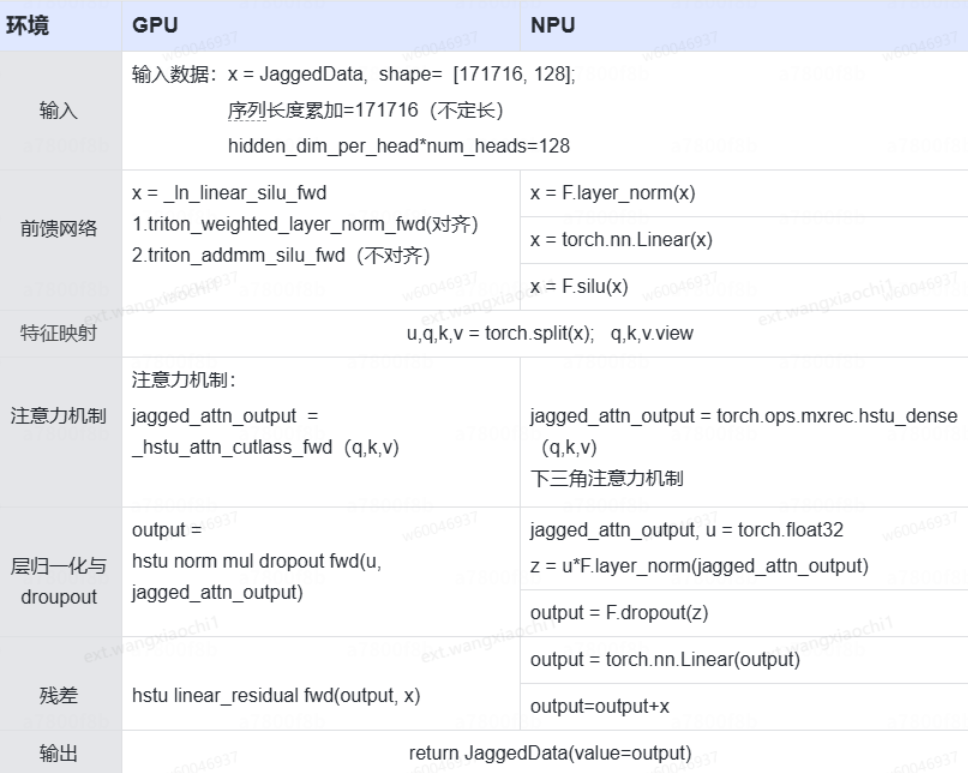
目前NPU与GPU在实现功能和计算方式上是一致,只是GPU采用triton的方式,调用C++底层实现的功能模块。NPU除Attention机制外,均调用torch原生的模块。如下图所示为hstu模块,GPU与NPU在实现上的差异点:
四、 实验验证与性能分析
4.1 实验环境介绍
如下表所示为测试阶段NPU和GPU的实验环境配置详情。
| 设备 | 型号 | CPU版本 | 操作系统版本 | HBM容量(GB) | FP32算力(TFLOPS) |
|---|---|---|---|---|---|
| NPU | 910B | Intel(R) Xeon(R) Platinum 8468V | x86 | 64 | 5.7 |
| GPU | A800 | Intel(R) Xeon(R) Platinum 8338C CPU @ 2.60GHz | x86 | 80 | 19.5 |
4.2 性能测试结果
本测试流程旨在系统对比 NPU 与 GPU 两种不同硬件设备在运行 Generative Recommendations 开源推荐模型时的性能表现。测试在相同配置文件下进行,并分别基于两种推荐系统框架——torchrec 与 unirec展开评估。
其中,torchrec 框架来源于 github.com 开源项目,NPU 团队在其基础上进行了部分适配优化以支持 NPU 设备;unirec 框架则由JD开源,天然兼容 NPU 与 GPU 两种硬件设备,具备良好的跨平台支持能力。
通过本测试,可全面分析不同硬件与框架组合下的计算效率指标,为模型部署的硬件选型与框架选择提供数据支持与参考依据。
单机单卡测试详情:
| 设备 | 卡数 | 数据集 | 数据类型 | 训练框架 | batch_size | seq_lens | num_head | attention_dim | e2e耗时(单位:ms) |
|---|---|---|---|---|---|---|---|---|---|
| NPU | 单机单卡 | Kuairand-1k | fp32 | torchrec | 32 | 8000 | 4 | 128 | 336 |
| NPU | 单机单卡 | Kuairand-1k | bf16 | unirec | 32 | 8000 | 4 | 128 | 176(无流水) |
| GPU | 单机单卡 | Kuairand-1k | fp32 | torchrec | 32 | 8000 | 4 | 128 | 306 |
| GPU | 单机单卡 | Kuairand-1k | bf16 | unirec | 32 | 8000 | 4 | 128 | 132 |
单机四卡测试详情:
| 设备 | 卡数 | 数据类型 | 训练框架 | 数据集 | 流水线并行 | batch_size | seq_lens | num_head | attention_dim | e2e耗时(单位:ms) |
|---|---|---|---|---|---|---|---|---|---|---|
| NPU | 单机四卡 | bf16 | unirec | Kuairand-1k | True | 32 | 8000 | 4 | 128 | 328.60 |
| GPU | 单机四卡 | bf16 | unirec | Kuairand-1k | True | 32 | 8000 | 4 | 128 | 274.03 |
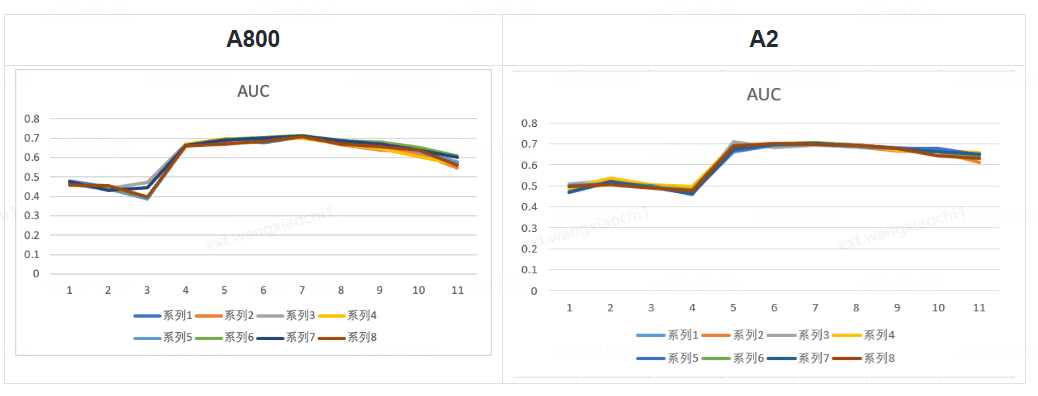
4.3 模型效果验证:
在相同训练配置下,本文对比了 GPU A800 与 NPU 910B-A2 服务器上的模型表现。模型输出为8类核心用户行为(如点击、评论)的预测 logit,通过将其与真实标签进行对比,并基于 BinaryAUROC 指标进行评估,得到验证集 AUC 结果如下图所示。实验表明,NPU 与 GPU 在全部8项任务中的预测精度基本一致,未出现显著精度损失。该流程有效验证了模型从隐藏特征到预测输出的转换性能,评估结果具备客观性与可复现性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号