

07_昇腾嵌入表性能提升
嵌入表性能提升:优化策略及算法介绍
1、 多流并行策略(MultiStream多流并行)
多流并行机制通过对通信和计算过程进行掩盖来有效地减少训练过程中的空泡率,Torchrec中TrainPipelineSparseDist模块实现的是NV的方案,其通过三流并行机制来将计算和通信过程进行掩盖,有效的减少了通信延迟的同时又保持前反向能够顺序执行;forward, backward过程使用默认的CUDA stream、D2H使用memcpy CUDA stream、数据的切分、分布式并行使用data_dist CUDA stream。
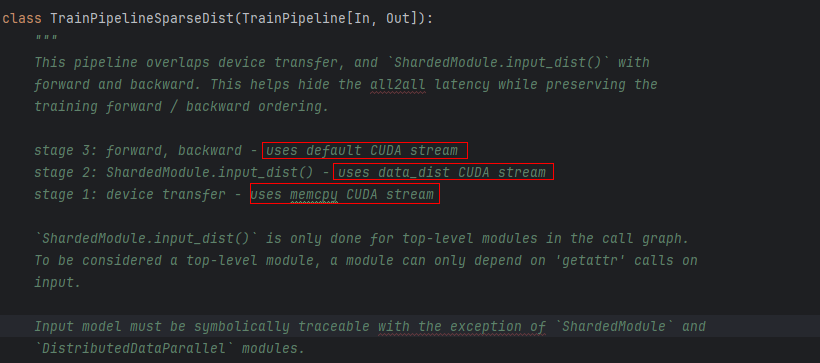
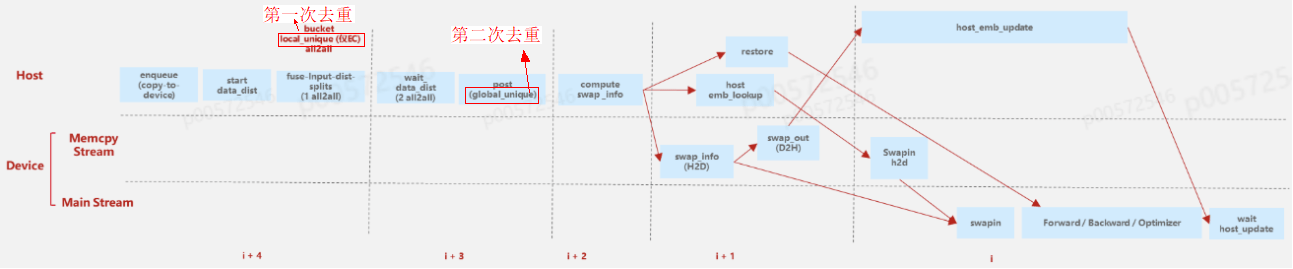
NPU中多流并行流程如下:
第一阶段:将单个batch的数据从dataloader中load进来并通过enqueue队列入队并将label和dense特征copy-to-device,待copy完成后host侧会启动对parse特征分布式并行处理。待处理完成后执行sparse数据的分发(bucket、local_unique、alltoall),这里的alltoall是work间通信矩阵的alltoall,告知每个work间需进行的通信量。
第二阶段:当前阶段包括两次通信过程,分别是KeyJaggedTensor中 length和value 的alltoall,此外do_post_input_dist过程是等待alltoall完成后对key进行一次全局的Unique操作,对应goobal Unqiue,这里做全局的Unique的目的是为后续计算换入换出key做准备。
第三阶段:调用EmbCache管理模块中compute swap_info计算5个key相关的关键数据(swapoutKeys、swapoutOffs、swapinKeys、swapinOffs、batchOffs)得到换入换出信息。
第四阶段:该阶段可以执行通信和计算掩盖;在Device侧,通过swap_info信息得到需要换出的key并通过D2H将该key通过swapout操作从device侧换出到本地,host cache中为下一阶段本地表的更新做准备。
第五阶段:在Host侧,将上阶段从device侧换出的key所对应的向量对本地Embedding表进行更新;在Device侧,通过swap操作将需要换入key和已从本地host查询的向量换入到Device侧;由于前面对数据进行了去重操作,通过restore操作将向量恢复成原始key列表,这样一来得到本轮次的训练batch数据将其送入forward、backward和optimizer进行训练和更新。这里训练完成后会更跟host 换出的embedding表的更新进行同步,保障换出的输出已全部更新到本地Embedding表中。
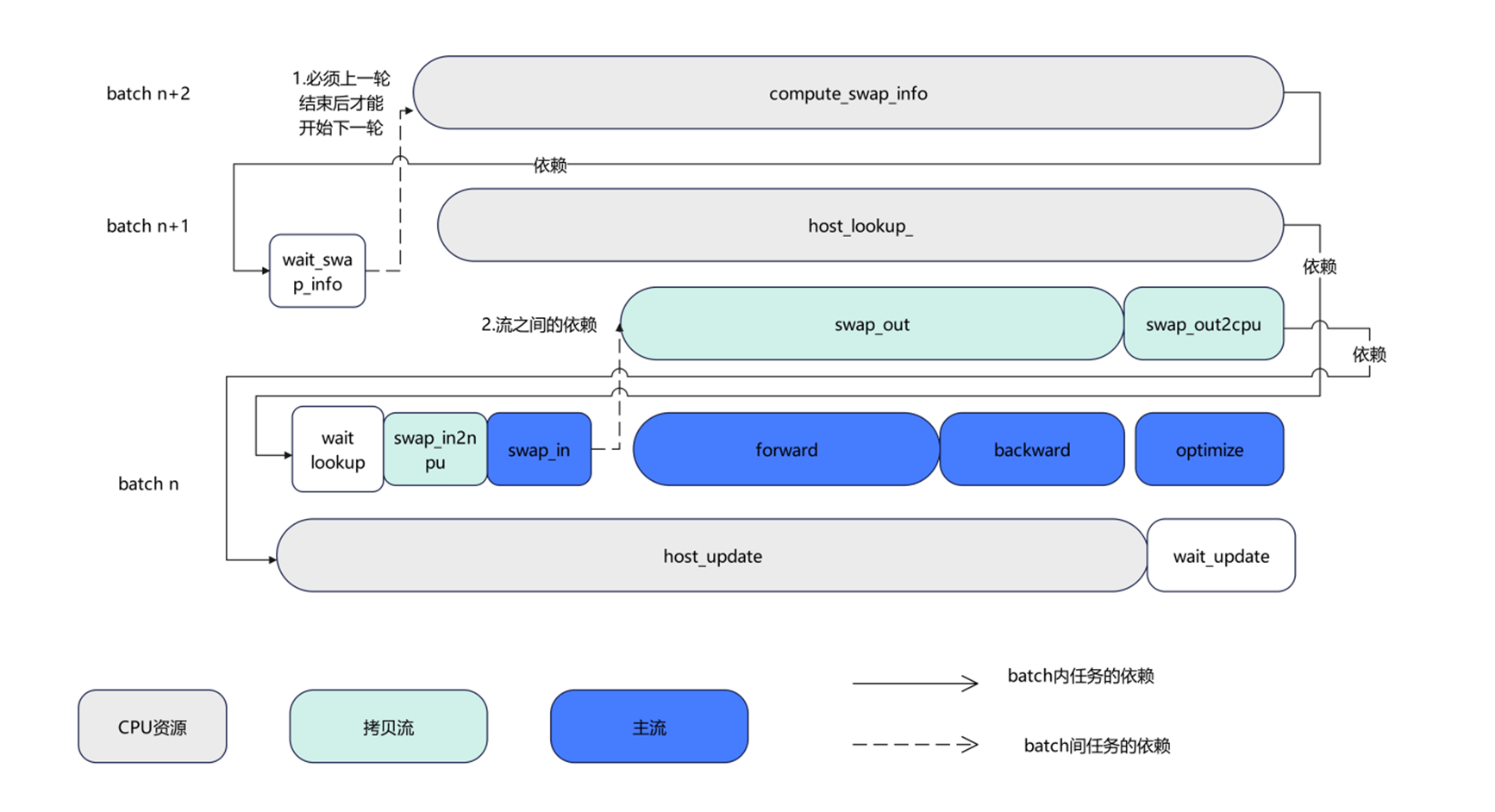
NPU侧的多流并行的实现继承了TrainPipelineSparseDist,但沿用了其中两流(主流和拷贝)的思想来掩盖计算和通信;如下图所示:主流(Main Stream)用来实现Forward、Backward和optimize的更新和device侧的换入,对应计算过程;从流(Memcpy Stream)用来处理H2D和D2H操作,对应图中swap_out、swap_out2cpu和swap_in2npu,对应通信过程。CPU侧通常来执行换出换出key计算(compute_swap_info)、换入向量的本地查询(host_lookup)和换出向量到本地Embedding的更新操作。
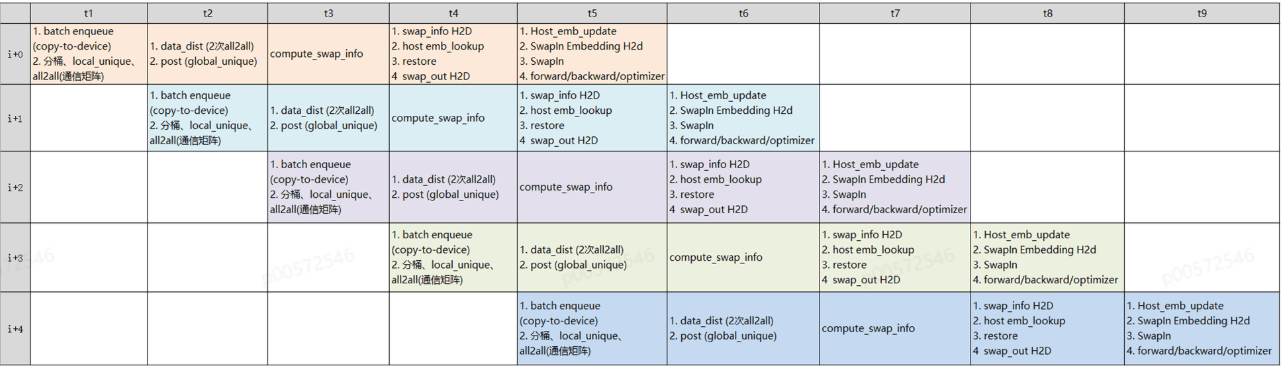
综上,Npu侧的多流并行可将pipeline过程通过fill_pipeline函数将整个流程切分成5个更细粒度的阶段,每个阶段之间串行执行,相互有顺序依赖,通过将一个大的batch拆分成若干个小batch,然后在每个小batch间数据进行overlap从而掩盖计算和通信从而达到减少空泡的目的,通过对上述3个小batch的任务间和任务内的依赖进行分析,详细的流水并行过程如下表所示:t1时刻处理第i个batch的第一阶段;t2时刻处理i个小batch的第二阶段,此时i+1个batch的第一阶段与当前batch没有依赖关系可同时进行处理。t3时刻处理i个小batch的第三阶段,此时i+1个batch第二阶段可以同步处理,与此同时i+2个batch第一阶段也可以同步处理;以此类推等到t5时刻可以看到所有batch均对应阶段的数据在处理,此时机器利用率达到最高(没有空泡)。
2、 Pin Memory
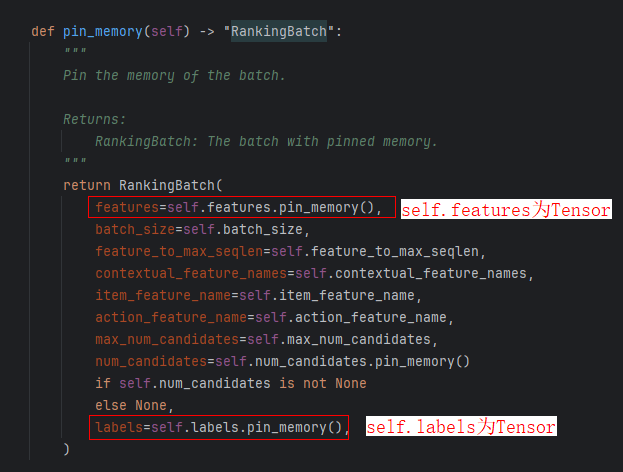
Pin Memory是PyTorch中用于优化CPU到NPU数据传输的核心机制,通过物理地址固定的锁页内存和DMA直传机制,成为NPU训练中突破数据传输瓶颈的关键技术,在性能上可以实现传输带宽翻倍,训练吞吐量提升近2倍;效率上通过异步传输实现计算-加载流水线,消除NPU空闲,在大规模数据、分布式训练及实时推理场景频繁被使用。
通过将部分需要H2D的Pytorch Tensor(例如:需swap in tensor的offset)设置在Pin memory上,使得npu能够通过DMA直接访问数据,加速访问速度。使用方式是在创建的时候指定tensor在npu上即可放到pin memeory空间内,这样npu可直接访问到。
3、 两级特征去重
通过对训练的数据分析发现,单个batch数据中会有大量重复的key,需要对输入数据进行去重;通常对key进行bucket后每张卡上会得到均分的key(一般是平均分到每一张卡),该部分key会存在大量重复(重复率在30%以上);通过unique操作可以对该部分key实现局部的去重操作(第一次去重)。本地卡与其他卡查询并通信交换万所有查询的embedding信息后,通过全局去重操作来得到全局唯一的key来计算本batch需要换入换出的信息(第二次去重操作)。
通过local unique和global unique两次去重操作可以,减少all2all数据量,加速all2all性能,大幅度的减少单个batch的查询量;此外还能通过减少lookup (index_select/Gather)和update(index_add/scatter_nd_add)两个操作的数据量,进而加速HBM上稀疏访存速度。
4、通信优化
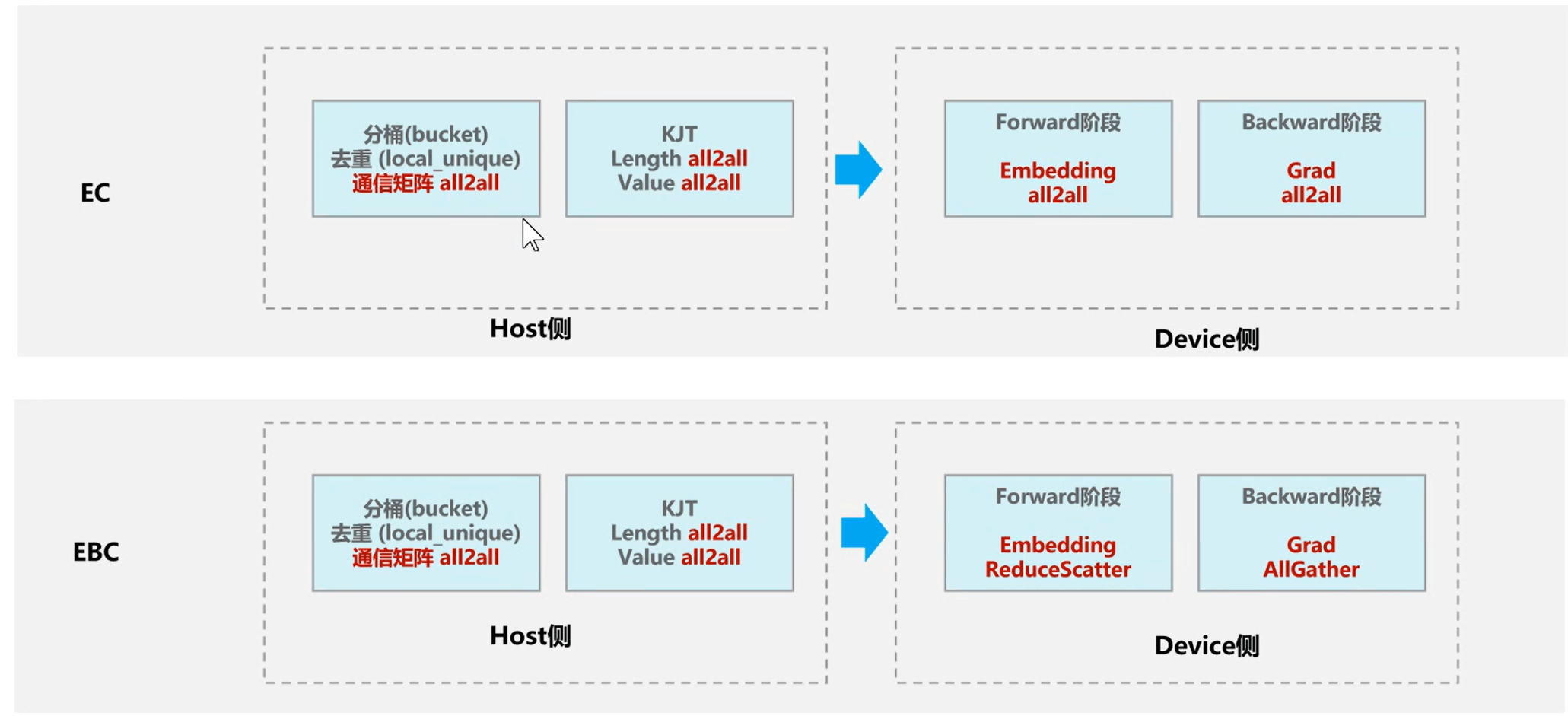
TorchRec 中,EmbeddingCollection(EC) 和 EmbeddingBagCollection(EBC) 是两种处理稀疏Embedding的核心模块,其通信模式的差异源于设计目标、数据结构特性和计算逻辑的本质不同。
| 维度 | EmbeddingCollection(EC) | EmbeddingBagCollection(EBC) |
|---|---|---|
| 输入特征 | 离散的单个特征 ID(如用户 ID、商品 ID) | 特征包(多个 ID 组成的包,如用户历史行为序列) |
| 计算方式 | 为每个 ID 独立查找 embedding 向量 | 对包内所有 ID 的 embedding 做池化操作(如 sum/mean) |
| 输出形式 | 返回每个 ID 对应的独立 embedding 向量 | 返回池化后的单一聚合向量 |
EC需为每个 ID 返回独立向量,在分布式环境下(如嵌入表分片到不同 NPU),EC 必须通过 All-to-All 通信收集所有 ID 的完整 embedding 向量,确保每个 NPU 获取全局数据,尤其在特征稀疏且分布不均时,这会导致高通信开销。EBC通过本地池化(如对用户历史行为 ID 求和)生成聚合向量,仅需传输聚合后的稠密向量而非原始稀疏 ID 列表。EBC通信量显著降低(减少 60%~90%),且可通过 Reduce-Scatter 等高效通信协议实现。对于Backward而言,其是前向的反过程,在EC模式下,梯度也需要All-to-All通信收集所有Grad,反传到每个NPU卡。在EBC模式下,Backward实现的是Reduce-Scatter 的逆过程也就是AllGather操作。
5、梯度累积(MP模式)
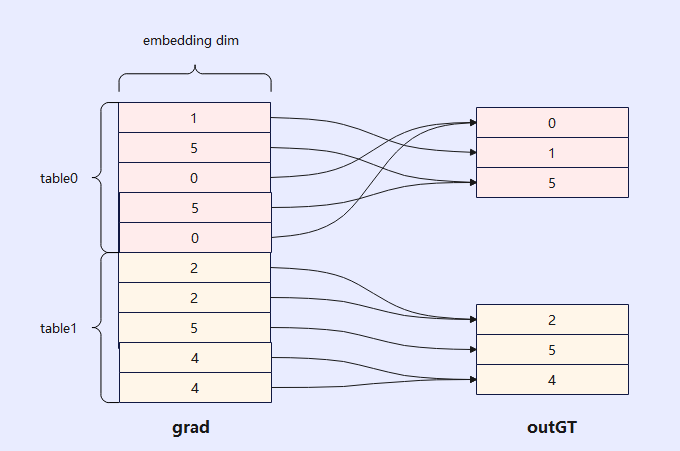
由于稀疏表可能会比较大,全量存储梯度会导致内存会爆炸,梯度累积的作用是希望用较小的存储空间将多轮多张表的梯度进行叠加,如下图所示:展示了单轮迭代中两张表backward过程获取梯度后将不同table中的相同索引位置对应的梯度进行累加(例:table0中的0、5,table1中的2和4)得到最后的梯度送入优化器进行梯度更新。
此外,indice需要结合unique inverse从unique indice取值可以还原成table0和table1中的向量,也就是说unique inverse中存储的是restore向量,这样可以将unique indice后的向量还原成原始向量。
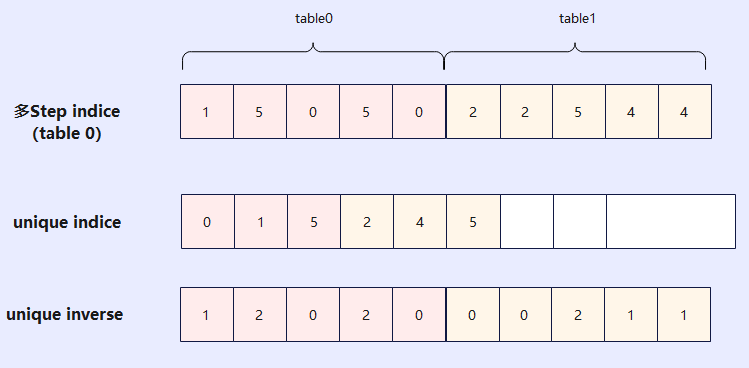
上述介绍的是多表的梯度聚合,那么如何实现多轮次多张表的梯度累加呢?如下图所示:我们在算子层实现了多表梯度动态存储(将不多个step中相同的indice的梯度进行聚合,图中展示的是2步,其取值作为参数可设置),再结合输入的unique inverse将原始表还原出来。此处需要维护step indice和unique inverse两块空间。
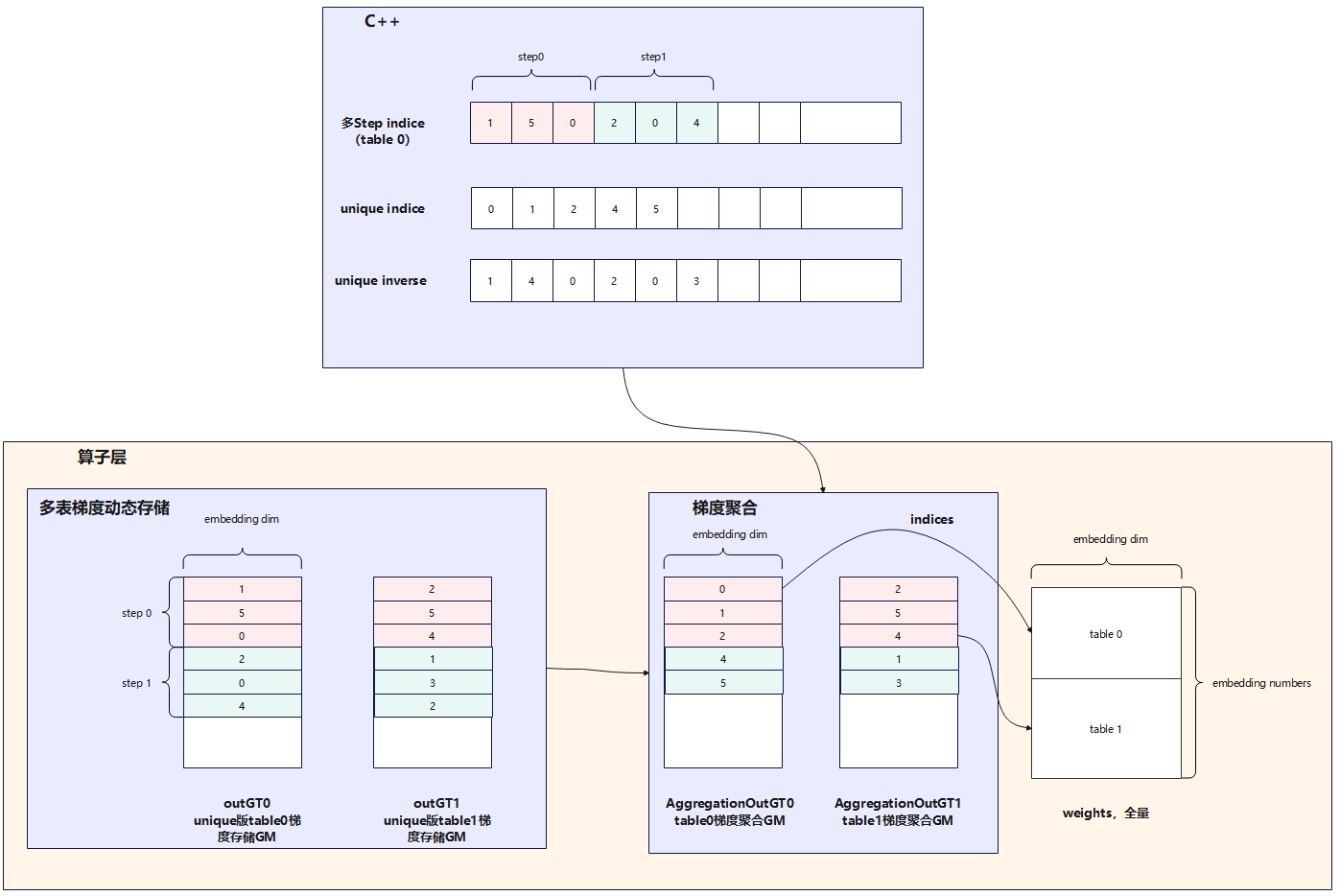
上述实现方案C++侧通过GradientAccumulator类实现,其中每个入参和函数的作用均在图中有注解。每个表独立对应一个buffers,通过buffer_names区分,其中buffers初始空间申请的是当前step和上一个step所需的indices空间,当空间不足时通过resize_buffer重新申请空间。current_accumulate_step表示当前训练迭代多少个step(上图中step=2)。通过total_index_size、total_index_size_pre和index_multi_step可得到当前step的indice和历史step的indice并结合unique_inverse_multi_step在训练xx个step后对所有表中梯度累积的梯度进行叠加并将其结果还原成原始索引排布并输出全量的indices。

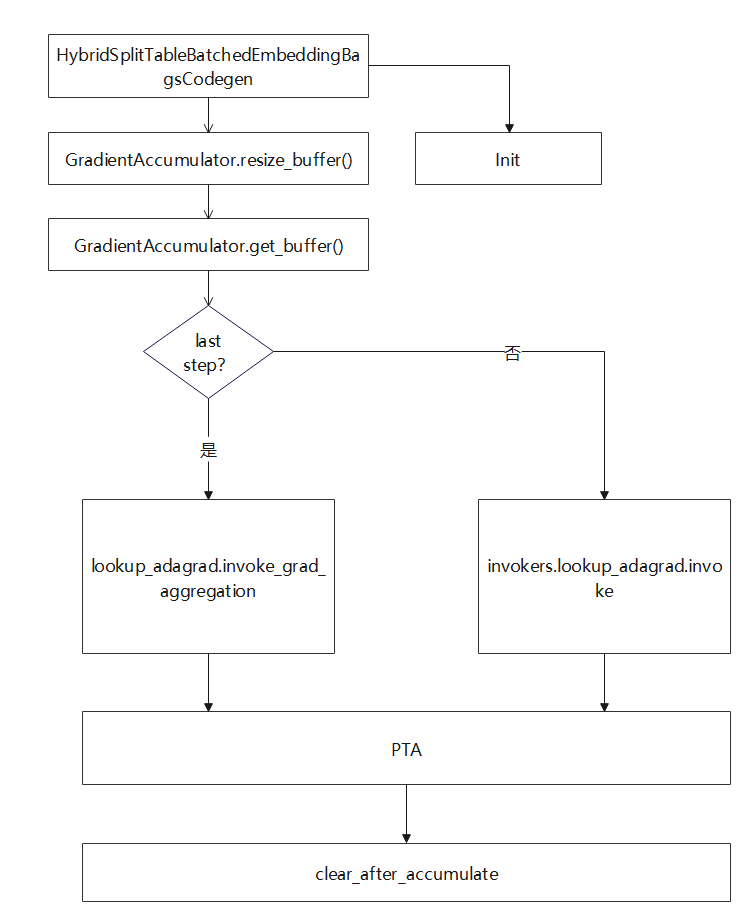
实现流程如下图所示,其中HybridSplitTableBatchedEmbeddingBagsCodegen为查表类,类中定义一个GradientAccumulator变量并在其初始化时调用GradientAccumulator的初始化方法将GradientAccumulator中所有的成员变量进行初始化。具体成员函数的作用在上述类图中有体现,这里就不在做额外的解释。HybridSplitTableBatchedEmbeddingBagsCodegen前向过程中调用GradientAccumulator中resize_buffer方法判断空间是否满足,如果空间不够则对空间进行扩容。然后可以拿到多个step进行梯度累积后的buffer,并判断step是否达到阈值(可设置),如果达到设定step,则会对所有step累积后的梯度再次进行合并;否则,则调用正常的查表算子对梯度值进行查询。
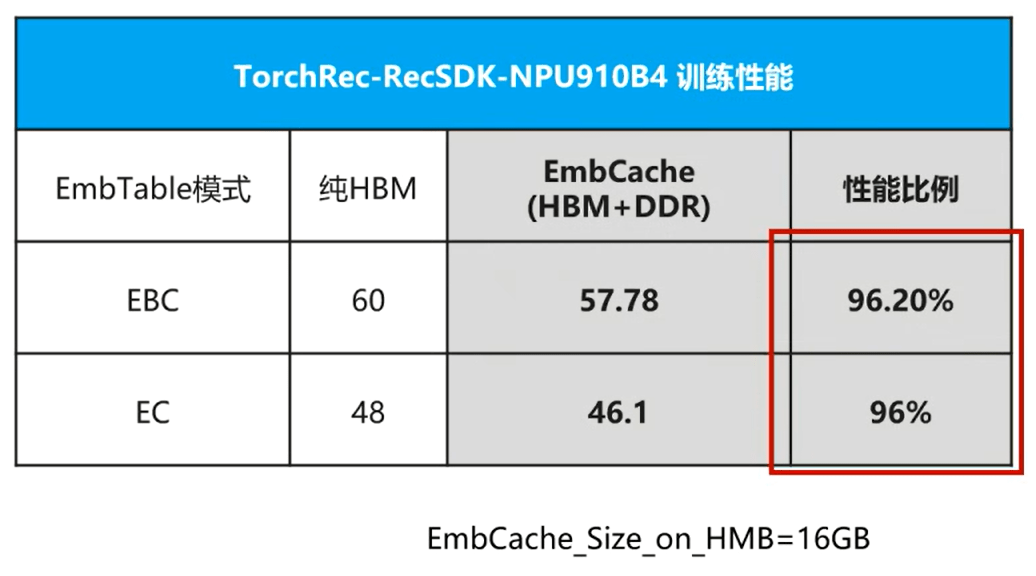
6、实验对比介绍(Embedding表的压测实验补充)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号