

02_昇腾推荐系统架构解析:嵌入表存储到多级缓存的全链路设计
昇腾推荐系统架构解析:嵌入表存储到多级缓存的全链路设计
1. 昇腾 A2 处理器架构与 Embedding 优化策略
昇腾 A2 处理器采用独特的达芬奇架构,具备完整的片上多级缓存系统。其缓存体系并非"以 CPU 为中心的多级缓存替代方案",而是基于自身架构理念设计了高效的多级缓存机制,与 NVIDIA GPU 在缓存策略上存在差异,但具备相当的高效缓存能力。
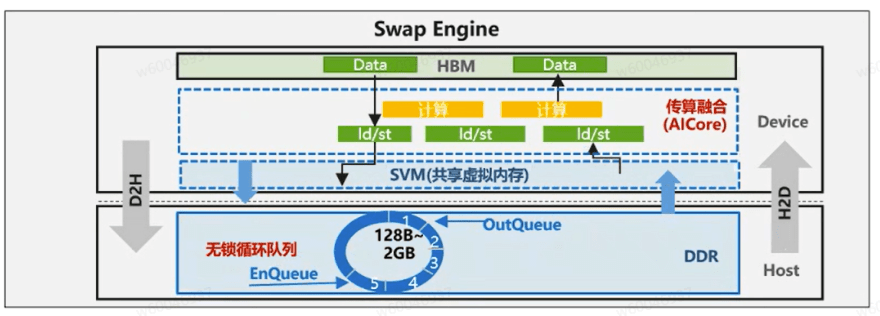
在整体架构上,多个 AI 节点通过互联形成集群(Cluster)。单个 AI 节点内部包含多个 Worker(支持单机 16 卡或 8 卡配置),节点内 CPU 侧通过网卡互联,NPU 侧则通过高速网络(当前为 HCCS,下一代为 UB 网络)实现卡间互联。在这一架构中,HBM 内存具有高访问效率但容量有限,通常用作热点 Key 的 Embedding Cache,功能上类似于 KVCache;而 DDR 主存容量可达 TB 级,用于存储完整的 Embedding 表。
Host 侧以 CPU 为核心,负责批处理(Batch Processing)、Embedding 表更新及流水线调度等任务。此外,昇腾通过自研的 FastHashMap 结构实现 CPU 侧的高效 Key-Value 访问与存储。目前该方案已支持两种存储模式:单层纯 HBM 模式与双层 HBM-DDR 混合模式。
在通信方面,Host 侧采用 FeatureID 的 All-to-All 互联方式,Device 侧则进行 Embedding 及梯度(Grad)的 All-to-All 通信。当前支持的 Embedding 表切分策略为 RowWise,数据并行(DP)模式正在积极开发中。
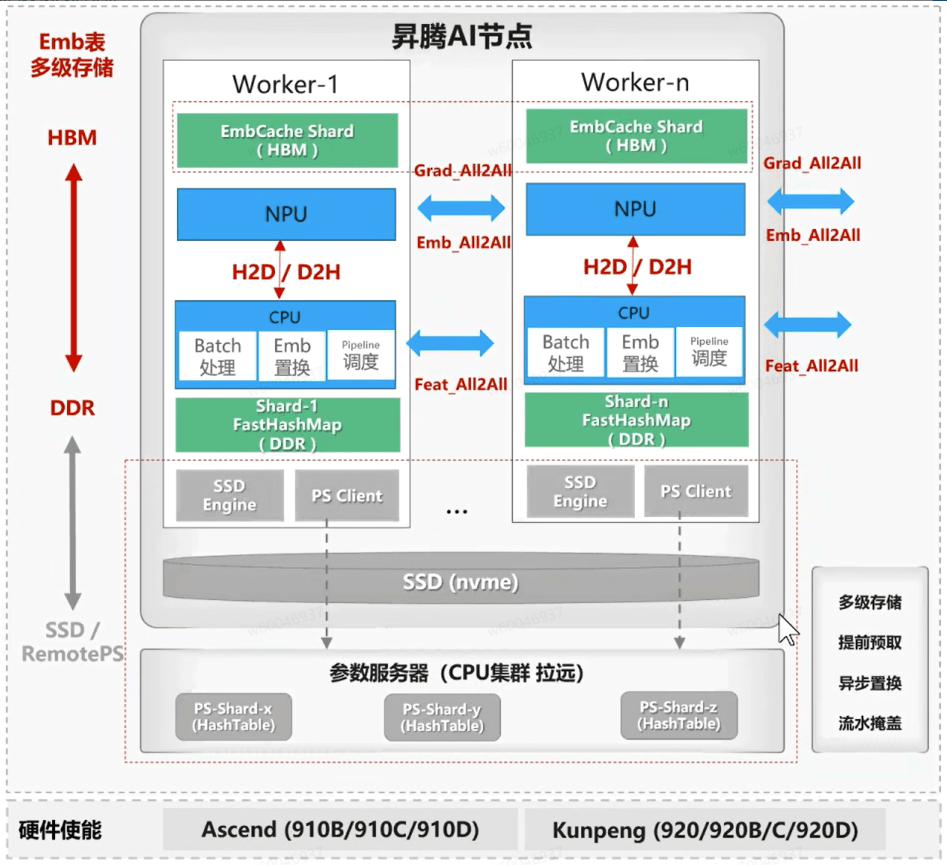
目前昇腾侧解决方案具备动态扩容能力:初始阶段为NPU侧分配固定容量的HBM作为Embedding Cache(嵌入缓存),后续将升级为支持从零容量(Size=0)逐步扩展至预设上限。训练时,完整Embedding表存储于DDR内存的FastHashMap结构中,系统通过SwapOut机制换出暂时未使用的Embedding向量,并通过SwapIn操作将待训练的Embedding换入HBM缓存(注:CPU侧的FastHashMap支持完整的增删查改功能,其存储空间可动态扩展,但为预留模型保存所需的DDR空间,设有总容量上限)。为提升整体效率,系统结合Pipeline流水线技术以掩盖数据搬运开销:CPU在处理样本特征的同时,会异步预取(Prefetch)Embedding数据并执行SwapIn/SwapOut操作,从而实现计算与数据通信的高效重叠。
上述架构在 TensorFlow 和 PyTorch 框架中保持一致,仅在底层实现细节上有所差异。在 C++ 侧,所有接口已被统一封装,上层业务调用时可无需感知底层实现区别。因此,用户可直接基于提供的高级接口进行适配与调用,无需额外开发工作量。
2. 软件架构介绍
昇腾软件侧整体实现架构图如下图所示,从上往下看分别是客户业务模型(例如:GR、DLRM、OneRec等)、RecSDK插件、TorchRec、Pytorch、FBGemm算子库、torch-npu、CANN、驱动和底层硬件等。其中RecSDK插件是npu侧的核心实现,其对Torchrec做好了适配,其中Hybrid是指支持纯HBM方案,EmbCache指支持多级存储方案(当前是HBM-DDR)。以外,针对nv侧原生的Fbgemm算子库也在npu侧做了适配和优化。
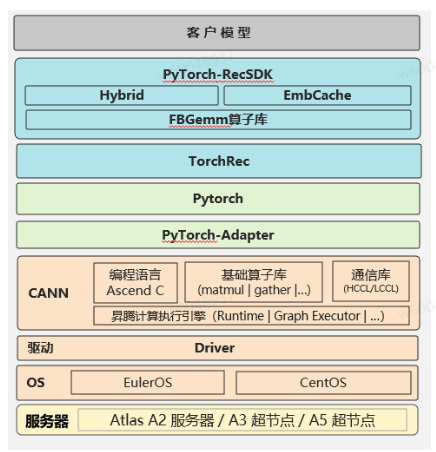
软件架构层面核心代码可分为5大模块,分别是Embedding存储模块、Embedding cache管理模块、Swap引擎、TorchRec EmbeddingCache插件和FBGemm模块,接下来将分别介绍前4个部分的功能和实现代码参考。
3. Embedding存储模块
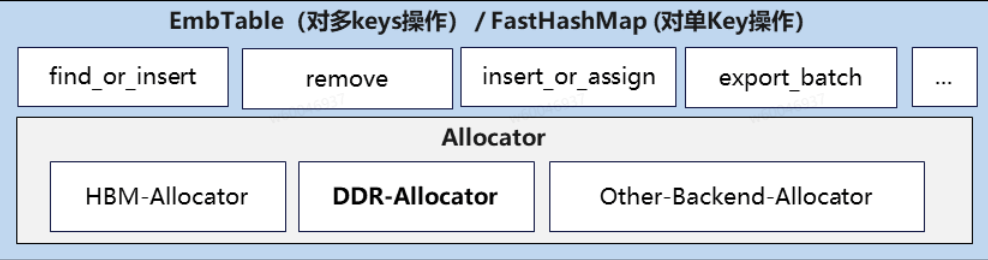
Embedding存储模块负责在CPU上高效、线程安全地管理大规模嵌入参数,支持查找、插入、更新、删除等核心操作。为适配不同性能与场景需求,模块底层提供多种存储引擎(如基于std::unordered_map或自研高性能哈希表FastHashMap),并通过统一的抽象接口EmbTable屏蔽实现差异,提升可扩展性与易用性。
为优化内存使用效率,模块引入内存池(EmbMemoryPool)及自定义分配器,实现对Embedding向量的高效分配与回收。EmbTable作为虚基类,向上层Embedding Cache管理模块提供一致的访问接口,使其可透明获取指定Key对应的Embedding及优化器状态。
扩展性设计:模块支持用户自定义存储实现。如需适配特定哈希逻辑,可继承EmbTable基类,并重写以下关键方法:
FindOrInsert():查询Key是否存在,若存在则返回对应Embedding及优化器状态(如一阶/二阶动量),并复制到输出缓冲区;不存在则执行插入。InsertOrAssign():支持并行插入或指定位置赋值。Remove():淘汰Key并回收其内存地址(地址可复用,不立即释放物理内存)。Save()/Load():保存或加载Key相关数据;在双层存储架构下,Save操作需确保Cache中的数据同步更新至DDR。
// 重写某个基类的函数
void ForEachKey(const std::function<void(const int64_t, const float*)>& callback) override
{
std::lock_guard<std::mutex> lk(mtx);
for(const auto& [key, vec] : this->table){
callback(key, vec.data());
}
}
Embedding存储模块功能展开来看可分成三层:接口层、核心存储功能模块和内存动态申请管理。类图实现如下:
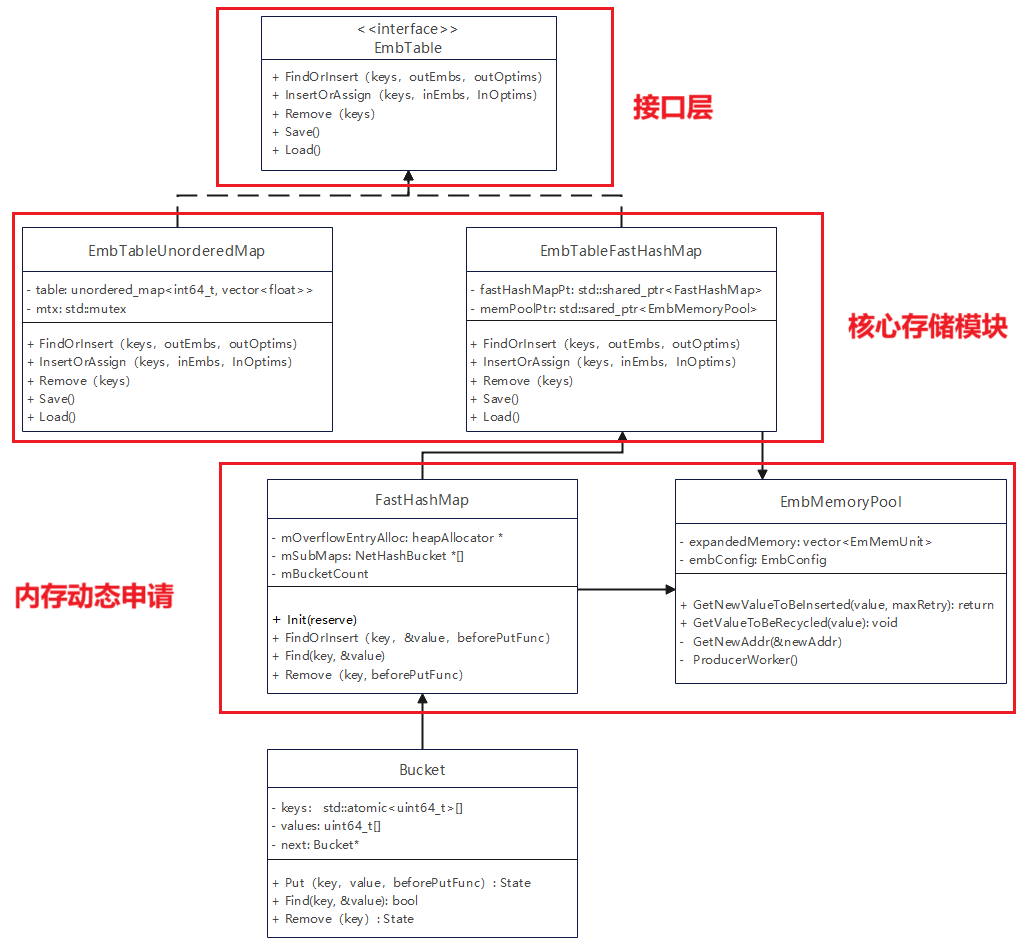
接口层主要是对外提供统一的调用接口供上层调用,该接口实现的功能这里主要是对一个batch的Key进行操作lookup操作。其输入一般是多个key,返回的是多个key的embedding向量或优化器的映射地址。EmbTable中定义了embedding表的统一接口,包括查找/插入、赋值、删除、遍历等操作。
核心存储功能模块通过自定义FasthashMap类来高效地实现单key的插入、删除、查找和导出等功能,EmbTableFasthashMap类是多个key的操作,通过并行的方式对key进行高效的操作。涉及到删除操作需要释放内存可通过EmbMemoryPool进行管理从而对内存进行高效的复用。EmbTableFasthashMap功能对标的是C++库中UnorderedMap。EmbTableUnorderedMap和EmbTableFastHashMap均继承自EmbTable,前者基于C++ 中std::unordered_map 实现的embedding表,后者是自研FastHashMap和EmbMemoryPool实现,适合大规模高性能场景。
内存动态申请管理实现的是DDR侧内存申请和释放,用来存放全量的key和value,主要通过HeapAllocator类实现内存申请和释放,HeapAllocator核心实现通过C++的calloc来动态分配内存。Bucket的核心功能是在Host侧对输入的key进行分桶以便高效地对大Embedding表进行分布式存储,当前版本侧实现的是取余对Key进行分桶操作。
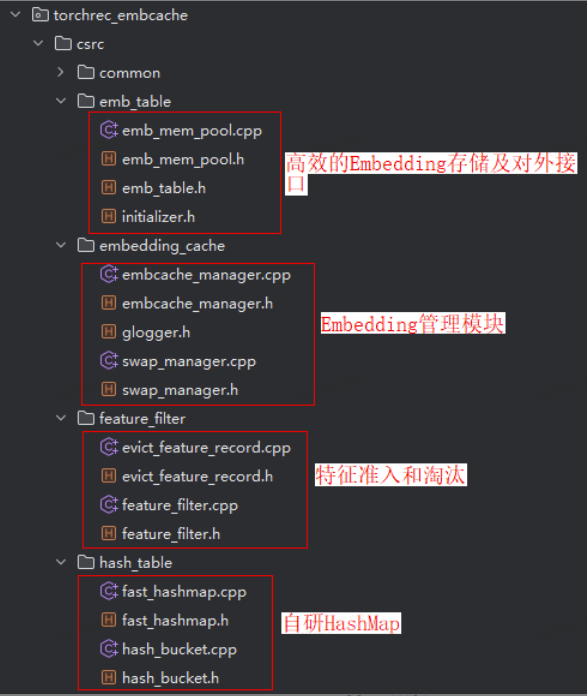
3. Embedding Cache管理模块
Embedding Cache源码位于:torchrec/torchrec_embcache · Ascend/RecSDK - 码云 - 开源中国

Embedding Cache模块是双层缓存架构中非常重要的模块,其核心作用是保障在CPU侧能够高效并快速的访问HBM侧的内存,通过内存映射的方式将HBM侧Key对应向量的地址与CPU侧建立关系。其提供了Embedding表创建、查找、更新、淘汰、准入、保存、加载、计算换入换出位置等功能,并通过Pybind形式结合C++接口提供能直接调用的python层接口。
Embedding Cache 的管理机制基于对缓存状态的持续追踪。系统会记录 DDR (Host侧存储内存)主存中已存在的每个 Embedding 所对应的 Key、其所在的 Batch ID,以及在 HBM 中的地址映射关系。
当新的一个 Batch 数据输入时,管理模块会执行以下核心操作:
- 计算换入/换出集合:通过比对当前 Cache 状态与新 Batch 的 Key,精确计算出需要从 Cache 中换出的 Key(如最近最少使用的数据),以及新 Batch 中需要从 DDR 换入到 HBM 的 Key。
- 执行换入换出操作:根据计算出的集合,执行具体的 Swap-Out 和 Swap-In 操作,将数据在 HBM 与 DDR 之间迁移。
- 更新缓存映射:完成数据交换后,同步更新 Embedding Cache 的内部映射表,确保 Key 与 HBM 地址的对应关系是正确的,此过程即为 EmbeddingUpdate。
此外,Embedding Cache 的容量需要预先配置。为支持预取功能,其最小容量必须至少能容纳两个完整 Batch 的 Key 及其对应的 Embedding 数据 。具体的缓存大小可在 EmbCacheEmbeddingCollection 的初始化过程中,通过 _caculate_caches() 方法计算得出。
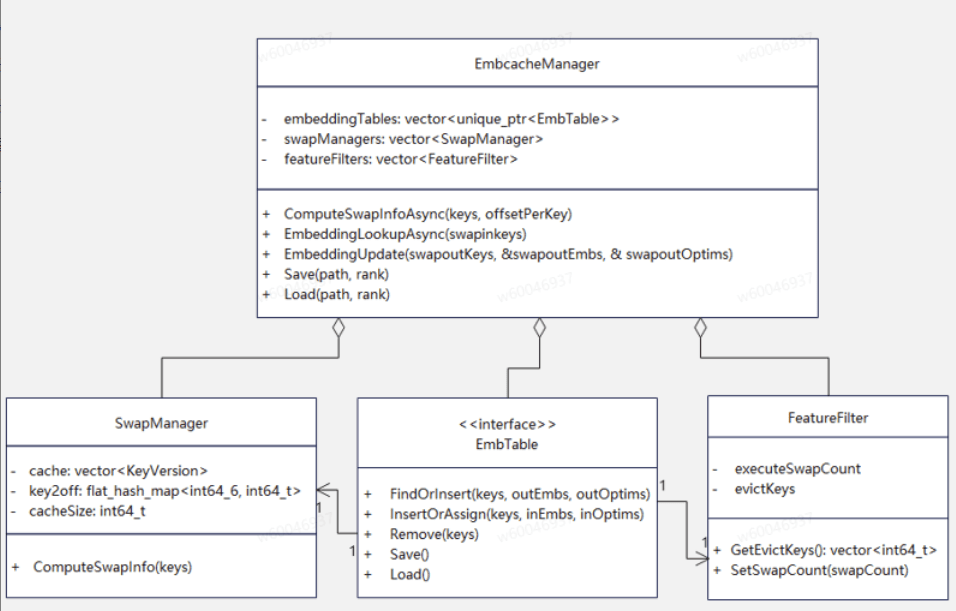
EmbcacheManager 作为 Embedding Cache 管理的核心组件,负责统一管理多张 Embedding 表的缓存策略、特征过滤、数据换入换出(Swap)及持久化存储等功能。该类聚合了多个功能模块,主要包括:
- SwapManager:负责缓存数据的换入换出与数据迁移调度;
- EmbTable:提供 Embedding 表的存储管理与访问接口;
- FeatureFilter:实现对输入特征的筛选与预处理。
通过上述模块的协同工作,EmbcacheManager 能够高效支持大规模稀疏特征的动态加载与更新,显著提升内存利用率和访问性能。系统还集成异步任务处理机制,借助 AsyncTask 模板类将用户任务封装后提交至线程池(ThreadPool)执行,并通过 future 异步获取结果,从而有效提升系统吞吐能力与响应效率。
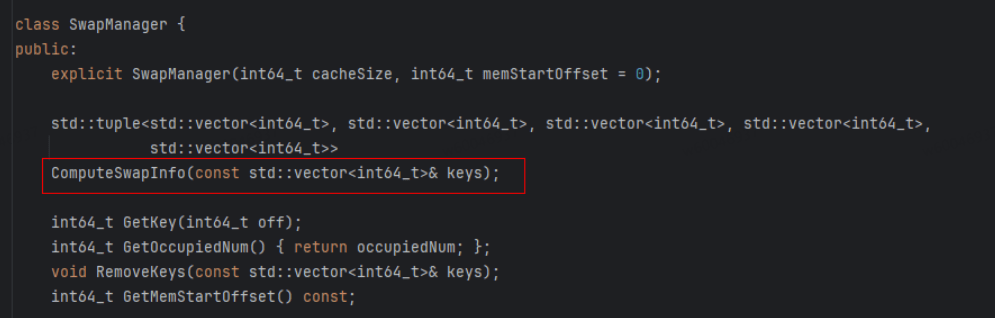
通过配置参数,可设定每张表的表名、缓存容量(即 HBM 连续存储空间中该表可容纳的 Embedding 数量,同时对应其在 HBM 中的起始地址)、优化器参数等信息。在运行过程中,ComputeSwapInfoAsync 方法负责异步计算当前批次所有表需查询的 Key,并生成包含五个关键信息的 SwapInfo 结构(后续详述),供调用侧获取本轮每张表的换入换出需求。
EmbcacheManager::EmbcacheManager(const std::vector<EmbConfig>& embConfigs, bool needAccumulateOffset)
: embNum(embConfigs.size()), needAccumulateOffset(needAccumulateOffset)
因此,HBM存储的所有表会是一整块连续的空间。上层调用侧通过每张表在配置中设定的缓存容量(cache size)计算起始偏移量(offset),从而利用统一的查询算子高效完成多表查询,显著提升查询效率。
执行流程上,系统首先在 Host 端并行查询需换入的 Embedding 数据,完成数据从 DDR 到 HBM 的换入操作(SwapIn),随后在 HBM 上执行 Gather 操作获取当前批次所需的 Embedding 向量。因此,整体执行顺序为:Gather 操作等待 SwapIn 完成,SwapIn 等待 Host 端查询(host_lookup)完成。
如下图所示:假设有4张表,在Vocabulary Size一致(假设是10)得情况下,第一张表的起始地址是0、第二张表起始地址是320,第三张表起始地址是720,以此类推。

4. Embedding Cache的换入(swap-in)&& 换出(swap-out)模块
为了加速训练,可以预先将下一个batch中的数据拷入到HBM做准备,数据从DDR拷入到HBM的过程称之为换入。为什么会有swap-out操作呢?明明DDR表有全量的数据,我们只需要往HBM上拷入不就行了?因为这是训练流程,在HBM上训练是会更新参数的。放到HBM上的是应届生,拷回来DDR的已经是工龄两年半的社畜了。可以说swap-out过程就是swap-in的逆向,即从HBM->DDR。
本方案主要是想实现mindxrec中swap引擎的功能,目前使用pin memeory可满足性要求,后续会根据需要看是否进行搬移。
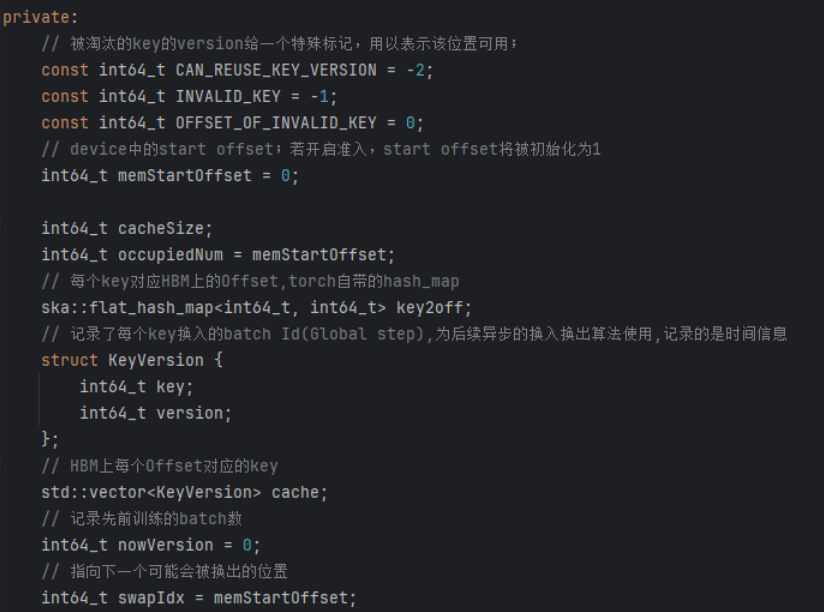
SwapManager负责管理每个表的 key 映射与换入换出信息的计算。其类成员变量如下所示,每个关键变量均在代码中注释,其中KeyVersion用来记录所有key对应的batch信息(全局信息),用来为换入换出做准备。比如通过nowVersion与version对比,小于某个阈值不能被换出,大于某个阈值需要被换出等等,此处可以结合LRU或LFU等算法设置准入或淘汰策略。
SwapManager类中ComputeSwapInfo()获取一个batch的作为输入计算批次键的换入换出信息,这是缓存管理的核心功能。该方法通过分析当前批次的键,确定哪些需要从DDR换入HBM,哪些需要从HBM换出到DDR这些关键信息,通过下面5个关键变量信息即可实现本地key与HBM上Embedding向量的换入和换出及更新。
class SwapInfo:
swapout_keys: List[List[int]] // 需要换出的向量在DDR侧表的索引号
swapout_offs: torch.Tensor // 需要换出的向量在DDR侧表的偏移量
swapin_keys: List[List[int]] // 需要换入的向量在HBM侧表的索引号
swapin_offs: torch.Tensor // 需要换入的向量在HBM侧表的偏移量
//本轮训练batch在HBM上对应的起始位置, # [ddr_to_hmb_idx(idx) for idx in KJT.values()]
batch_offs: torch.Tensor
包括swapoutKeys(换出的Key)、swapoutOffs(换出的Key对应HBM上的offset位置)、swapinKeys(换入的Key)、swapinOffs(换入Key对应HBM上的offset位置)、batchOffs(本轮训练batch在HBM上对应的起始位置),
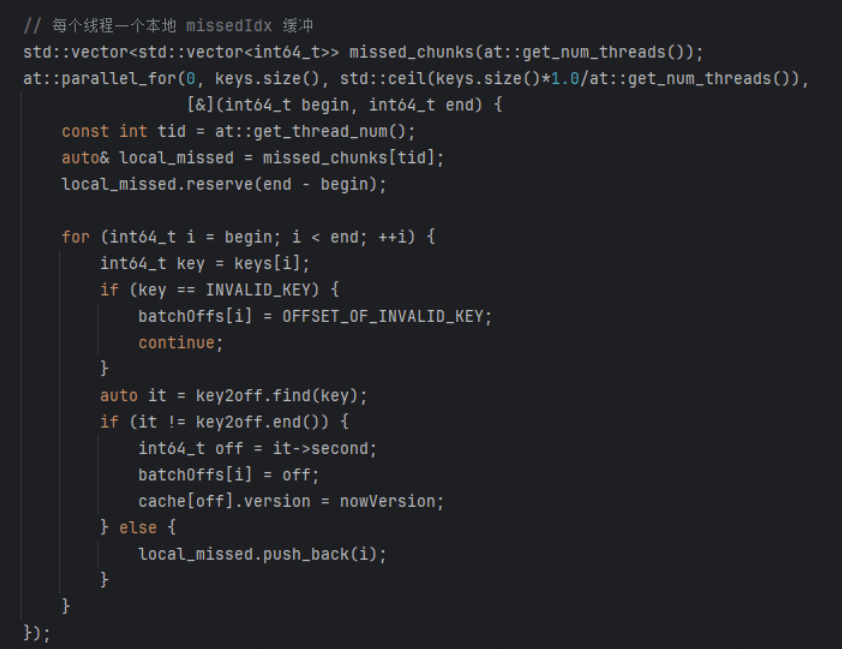
ComputeSwapInfo遍历每个表,统计特征出现次数,调用 SwapManager 计算需换入/换出的 key及 offset。然后通过多线程的方式将cache中不存在的key放入到各线程的local_miss中,待所有线程计算完成后合并各个线程的结果即可得到本轮cache中哪些key不在cache中,最终组装成SwapInfo并返回。
随后为本轮不在cache中的key寻找换入的位置,分cache已满和cache未满两种情形。若cache未满的话直接在cache中新增;若cache已满,需要找到可以被换出的位置,本方案设置的是当前步和上一步在用的key不能被换出。
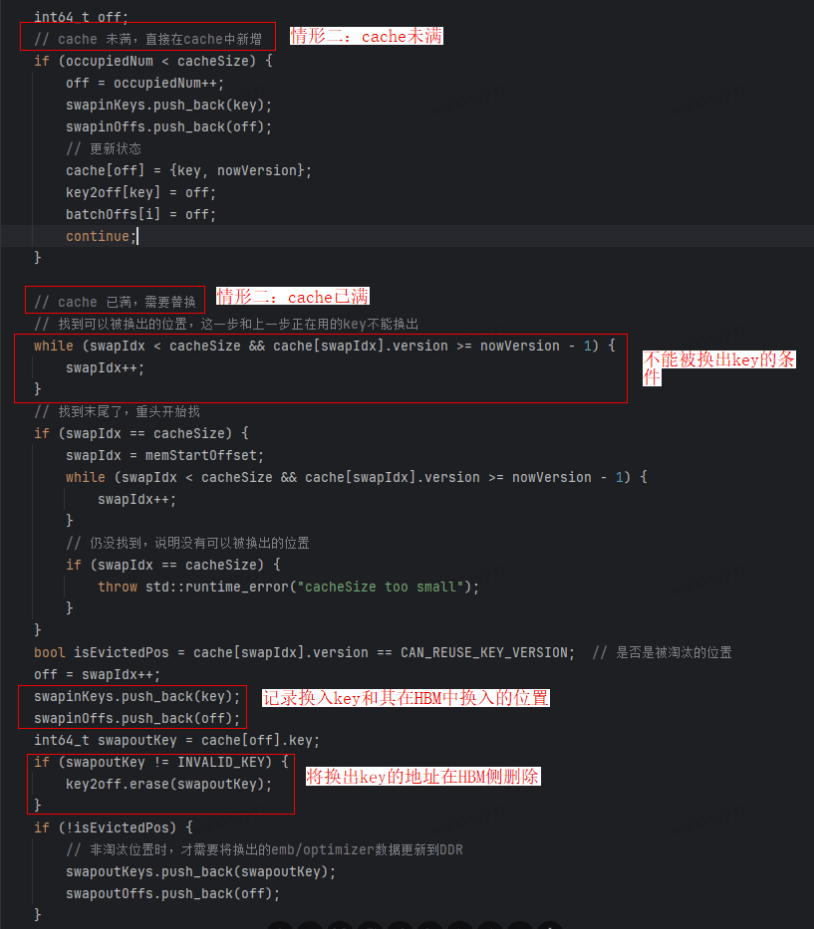
5. Embedding Cache的准入淘汰模块
- 准入:通过LFU(Least Frequently Used)、LRU(Least Recently Used) 或者其他算法,对训练过程中的ids进行统计和过滤。当ids的出现频次/最近出现时间满足要求时,才对该ids进行embedding存储和查表。
- 淘汰:当训练进行到一定阶段时,对所有的ids进行过滤,将满足条件(如长期未使用到)的ids和emb进行淘汰,减少存储压力和提升查表性能。
准入过滤(如果启用):
if (embConfigs[idx].admitAndEvictConfig.IsAdmitEnabled()) {
featureFilters[idx].CountFilter(keyPtr, offsetPerKey[i], offsetPerKey[i + 1]);
}
5.1、 Recsdk源码准入机制理流程
当前嵌入缓存系统采用 LFU(最近最少使用)策略对 ID 进行频率统计和过滤。
核心流程如下:
- ID 计数统计 (需适配 Local Unique 机制)
- 在 Local Unique 处理时,系统会统计每个 ID 的出现次数
- 通过自定义的
KeyedJaggedTensorWithCount结构实现计数数据的 All2All 跨卡通信 - 将统计结果记录到 C++ map 中
- 准入判断
- 在
EmbcacheManager::ComputeSwapInfo()中调用特征过滤模块 - 将出现次数未达到准入阈值(
admit_threshold)的 ID 标记为 -1
- 在
- 索引映射处理
- 在交换管理器中为 ID 计算对应的索引位置
- 被标记为 -1 的未准入 ID 会被映射到特殊的索引 0
- 嵌入向量重置
- 在嵌入查找完成后,对未准入 ID 对应的嵌入向量进行特殊处理
- 将这些位置的嵌入值重置为预设的默认值(
not_admitted_default_value)
5.2、 Recsdk源码淘汰机制流程
当前嵌入缓存系统基于时间戳实现淘汰机制,支持异步流水线和多Batch并行处理。
核心流程如下:
- 数据准备与配置
- 要求Batch数据包含timestamp字段,使用自定义的
KeyedJaggedTensorWithTimestamp结构 - 在embedding config中配置淘汰参数:
evict_threshold(淘汰阈值)和evict_step_interval(淘汰步间隔)
- 要求Batch数据包含timestamp字段,使用自定义的
- 时间戳记录
- 在input_dist阶段记录timestamp数据到C++
unordered_map<id, timestamp> - 通过
EmbCacheShardedEmbeddingCollection → cache_mgr.record_timestamp()链路完成记录
- 在input_dist阶段记录timestamp数据到C++
- 淘汰触发机制
- 当训练步数满足
global_step % evict_step_interval == 0时触发淘汰 - 触发时机可优化:考虑整合到
EmbcacheManager::ComputeSwapInfo()中统一管理
- 当训练步数满足
- 淘汰执行过程
- 调用
EmbcacheManager::EvictFeatures()进行实际淘汰 - 具体操作:
- 从swapManagers中移除被淘汰keys的映射关系
- 记录当前淘汰操作的swapCount
HostEmbeddingUpdate在相应步数时清理table embedding数据
- 调用
6. TorchRec EmbeddingCache插件
TorchRec 的核心功能在于大规模嵌入表的分片与管理,主要提供三大优化:多样的分片策略、专用的稀疏数据结构(Jagged Tensor)以及高度优化的 FBGEMM 计算内核。TorchRec EmbeddingCache插件模块复用的是TorchRec的生态,由于TorchRec并没有原生对NPU进行适配和支持,需要定制化的开发和适配。主要分为框架层适配和底层FBGEMM算子适配两部分。
框架层主要是对TorchRec中EC(EmbeddingCollection)与EBC(EmbeddingBagCollection)的对接与适配。npu侧对TorchRec中EC和EBC进行继承从而复用TorchRec中EC和EBC的功能,复用后的模块是没有经过分片(shard)的表,若要对原始表进行分片(shard)需结合EmbCacheShardedEmbeddingCollection实现,该模块也复用了TorchRech中原生的ShardedEmbeddingCollection方法。EmbCacheEmbeddingCollection中稀疏表存储使用的是Torch原生的Embedding,此处用户也可从C++层自行定义和实现Embedding表来替换原生Torch的Embedding功能(目前绝大部分互联网客户均是自行实现)。通过Pybind接口将C++层的EmbcacheManager模块封装成python接口在EmbCacheEmbeddingCollection中调用。框架层整体架构如下图所示:
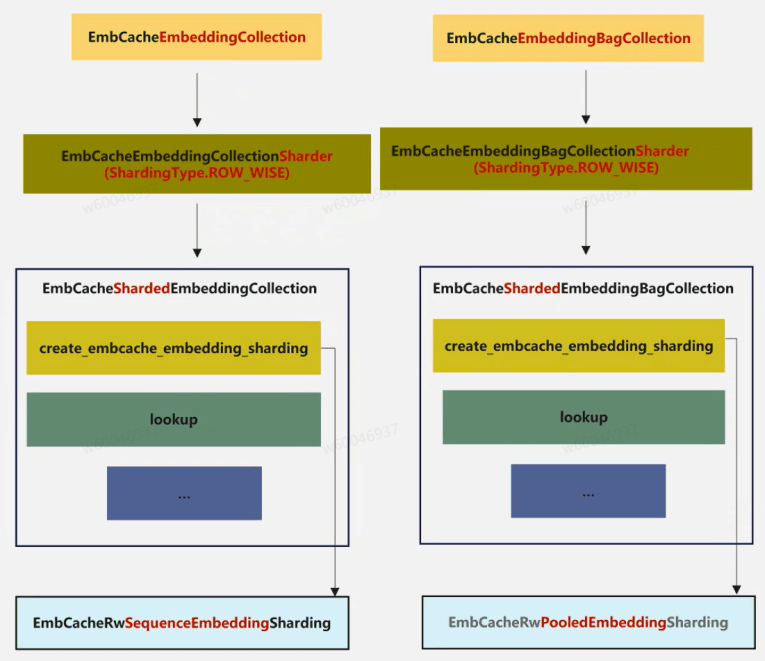
图中左侧部分从上往下看 :EmbCacheEmbeddingCollection 旨在支持大规模稀疏特征的多级缓存 Embedding 表,主要面向分布式推荐系统场景。其核心思想是通过分层缓存(如设备内存、主机内存等)和准入/淘汰机制,提升Embedding 查找和更新的效率,降低内存压力,并支持动态特征的高效管理。该类在 torchrec.EmbeddingCollection 基础上扩展,结合了缓存管理、特征准入与淘汰、分布式分片等机制。为支持分布式训练, EmbCacheEmbeddingCollection 需要实现对应的EmbCacheShardedEmbeddingCollection (分布式实现),EmbCacheEmbeddingCollectionSharder (分片器) 和RwSequenceEmbeddingSharding (分片策略)。
EmbCacheEmbeddingCollection存储的是所有表的信息,其通过EmbCacheEmbeddingCollectionShard生成分片策略(Sharding Planner)。主要分片策略是根据嵌入表的结构(如大小、维度)和硬件配置(NPU数量、内存)自动选择最优分片方式(如TABLE_WISE、ROW_WISE),它不直接管理数据,而是输出分片方案供执行层使用。EmbCacheShardedEmbeddingCollection 依据分片策略进行分布式嵌入表的管理,其根据分片计划将完整的嵌入表切分并分布到各个设备上,处理跨NPU的嵌入查找(Lookup)、梯度聚合和参数更新。它是EmbeddingCollection的分布式实现,直接操作分片后的数据。
主要类实体关系分析如下:
继承关系: EmbCacheEmbeddingCollection 继承自 torchrec.EmbeddingCollection 。
组合关系: EmbCacheEmbeddingCollection 组合多个 EmbCacheEmbeddingConfig 和 EmbCacheHashTable ,每个embedding表对应一个。
配置关系: EmbCacheEmbeddingConfig 包含 AdmitAndEvictConfig ,用于准入/淘汰策略。
图中右侧部分从上往下看:EmbCacheEmbeddingBagCollection 继承于EmbeddingBagCollection,旨在解决大规模稀疏特征嵌入表在分布式训练场景下的高效存储与访问问题。通过引入 EmbCache 机制,将嵌入表按需分布在不同层级的存储介质(如NPU/CPU/Host等)上,结合动态缓存管理(如冷热数据迁移、异步swap等),提升嵌入查找与更新的效率,降低内存压力,并支持大表训练。核心思路包括:
分层存储 :将Embedding表分为多级缓存(如NPU缓存、Host缓存),热点数据优先驻留在高性能设备上。
动态管理 :通过 EmbCacheManager 进行缓存命中、数据迁移、异步swap等管理。
分布式支持 :结合Sharding机制,支持表的行级/表级分片,适配大规模分布式训练。
接口兼容:对上层保持 EmbeddingBagCollection 接口兼容,便于集成与替换。
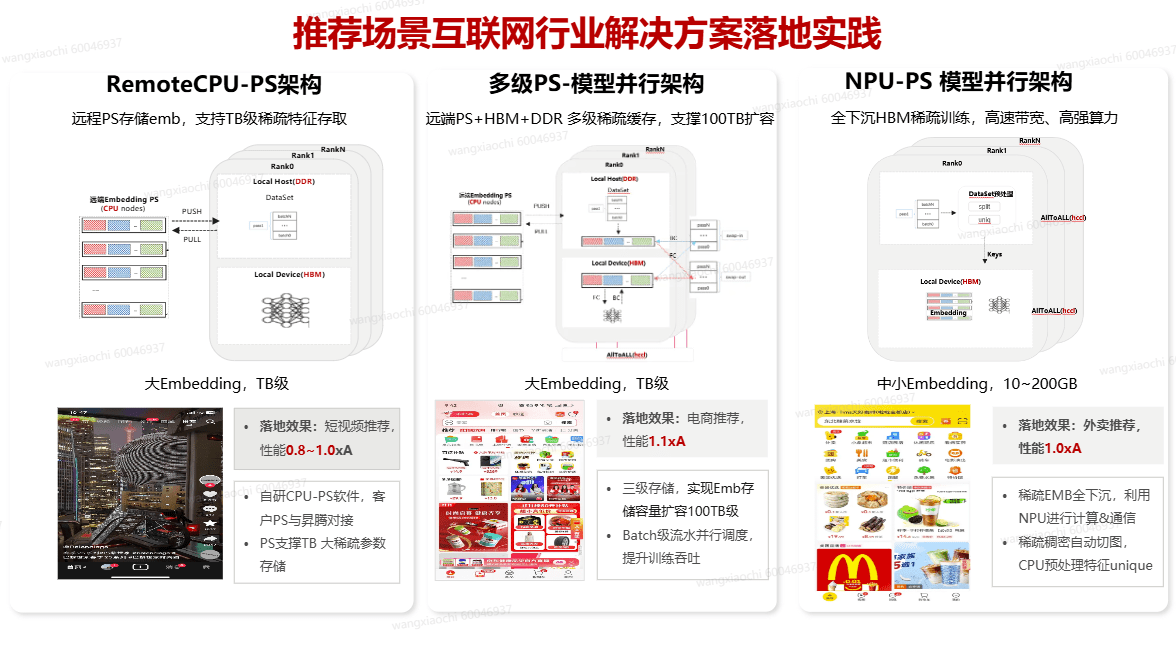
7. 互联网推荐系统架构演进与实践全景
本图系统梳理了推荐系统架构的核心演进路径与落地实践。它清晰对比了三种代表性解决方案:从适用于短视频场景、基于远程参数服务器(PS)的 RemoteCPU-PS架构 ,到支持超大规模特征、结合多级存储(HBM+DDR)的电商推荐方案 多级PS-模型并行架构 ,再到利用NPU算力实现特征全下沉的下一代 NPU-PS模型并行架构。每种架构均配有对应的典型应用场景(如短视频、电商、外卖推荐)与实测性能数据,直观展现了技术选型如何驱动业务效果提升,为架构决策提供有力参考。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号