

01_万亿级推荐系统嵌入表的技术挑战与现状
1、问题与挑战
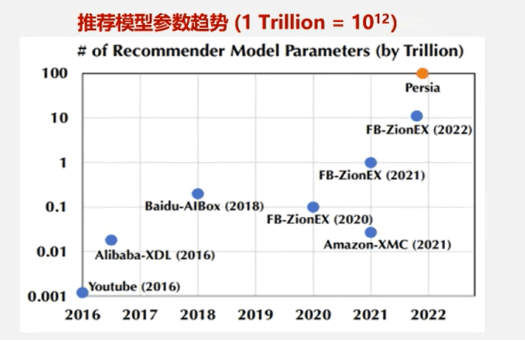
推荐系统中的用户(User)、物品(Item)及上下文(Context)特征具有高度异构性,其物理含义和量纲差异显著。为将这些特征有效引入深度神经网络(DNN),须通过Embedding技术将其映射为统一的低维稠密向量表示,从而解决特征间的语义鸿沟并提升模型泛化能力。为提升推荐系统的整体推荐效果,满足用户个性化推荐的需求,加速互联网电商企业快速变现。如下图所示:近10年来推荐模型的参数量呈指数级增长,2016年YouTube及Alibaba-XDL等早期模型参数量级仅亿级(~10^9),其中Embedding表占比超90%。到2022年Persia模型参数规模突破百万亿级(10¹⁴),7年间增长万倍,Embedding表已成为系统内存消耗的绝对主体(占比>98%)对存储带来了巨大的挑战。
传统模型(如矩阵分解、深度CTR模型)的 Embedding 表严重依赖离散型 ID 特征(例如用户 ID、物品 ID)。在电商场景下,用户与物品的 ID 总量可达数亿甚至十亿规模,每个 ID 都需要分配一个独立的嵌入向量。这种全量预分配的机制导致显存利用率低下:即便低频 ID 很少被访问,仍会持续占用固定大小的存储空间,从而造成显著的"静态存储冗余"。此外,由于不同特征域之间缺乏参数共享机制(例如"用户性别"与"用户 ID"需分别存储于不同的 Embedding 表),推荐模型的参数量会随 ID 数量的增长呈指数级膨胀。与自然语言处理中规模通常在十万级别的大语言模型静态词表相比,推荐系统所面对的实际上是动态变化、规模达亿级的"词表",训练难度与复杂度显著更高。
GPT-3在1-2个月内使用数千个GPU在300B个tokens上进行训练(GPT3 Brown,2020)。最大的互联网平台每天服务数十亿活跃用户,这些用户每天与数十亿帖子、图片和视频进行互动。在极端情况下,用户序列的长度可达到100万(Twin-lifelong Chang,2023)。语言模型在1-2个月内处理的令牌数量相比,推荐系统需要每天处理更多数量级的令牌。因此,高昂的计算与存储成本也成为制约大规模序列建模技术在推荐系统中落地的关键瓶颈之一。
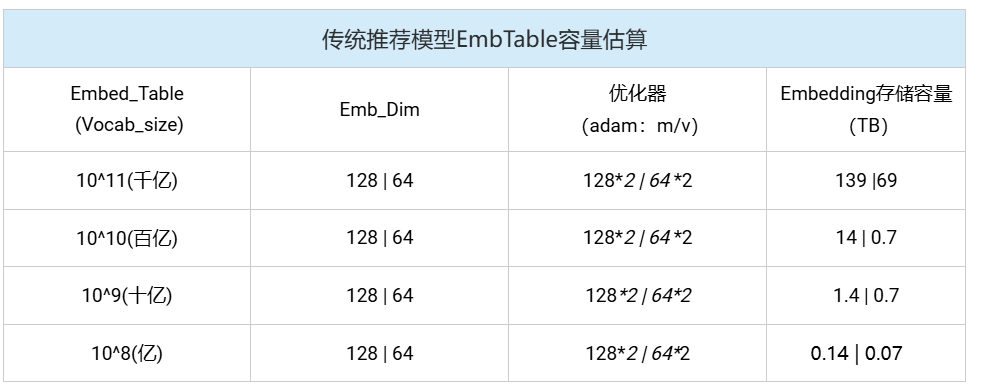
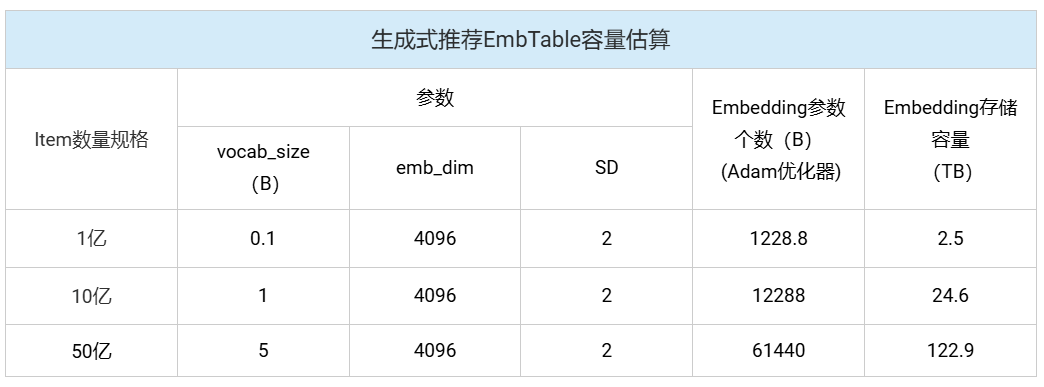
如下表所示:传统推荐模型的核心思想是通过学习低维稠密向量(Emb_dim:64/128)来表征用户和物品之间的相关性,其存储开销与用户数量及物品数量呈线性增长关系。虽然其Emb_dim维度较小,但在词表size较大时(千亿级),仍然需要较大的存储空间(TB级)。生成式推荐模型的Embedding模块在功能上与传统模型类似,但因其采用序列化、统一化的特征处理方法,具备更强大的特征空间表示能力,通常需要更高的Embedding维度(Emb_dim:4096)以捕捉更丰富的语义信息。如表所示,在一般词表size的情况下,存储需求已达到了TB级。此外,生成式推荐模型通常基于大规模预训练语言模型(如Transformer架构)构建其稠密网络层。这类模型的参数量并不直接随用户或物品数量变化,但其本身已极为庞大,例如部分生成式推荐模型的参数量可达万亿级别。因此,尽管两类模型在结构设计和增长逻辑上存在差异,它们都对计算基础设施的存储容量和计算效率提出了严峻挑战。
综上,推荐系统的在演进历程中,Embedding Table(嵌入表)作为特征表示的核心载体,其容量设计经历了从静态膨胀 到动态压缩 的根本性转变。这一变革并非简单的技术优化,而是数据范式、模型架构与硬件约束三重力量驱动的必然结果。如何应对这些数据力量的驱动,高效的利用算力,提升转化率成为当今业界(尤其是头部互联网公司)丞待解决的重点难题。
2、业界解决方案
推荐系统中大部分参数开销集中在嵌入表,千亿级向量规模带来数量巨大的NPU存储需求。按下表千亿量级计算,全部存入HBM中需要745百张卡。按照当前单张显卡的价格预估(GPU每张显卡约1600美元),每TB参数训练纯HBM方案成本约20,000美元,而DDR4 每TB成本3,000美元、DDR5 每TB成本5,000美元。如何在显存资源有限的情况下,有效地利用计算机其他存储资源的同时训练效率又能有所保障即"存的下"并"训得快"成为当今业界热点研究方向。

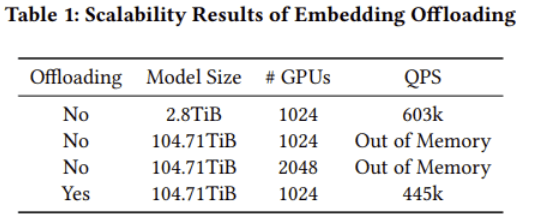
《Toward 100TB Recommendation Models with Embedding Offloading》这篇论文通过少量的性能代价来换取大容量的存储空间,给业界提供了新的解决思路。主要做法是将全量的Embedding表卸载到Host侧并结合Cache和预取的方式来提升访存命中率和掩盖计算和通信。此外,还利用Meta高性能的算子开源库FBGEMM GPU和TorchRec通过局部感知分片和迭代规划方法,能够自动优化缓存大小并生成高效的分片方案。实现了Embedding表的37倍模型规模扩展 ,达到100TB模型 规模,训练速度仅下降26% ((603k-445k)/603k)。
该方案的主要贡献如下:
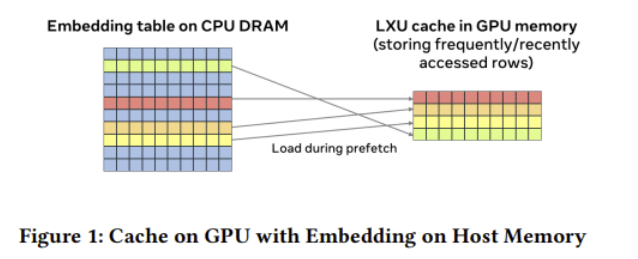
1、多级缓存 :Embedding模块实现了Table Batched Embedding (TBE) 技术,当Embedding容量超出GPU内存限制,将Embedding表放置于主机内存(DDR)。如下图所示:为能够高效的对主机侧Embedding表进行访问,TBE通过使用统一虚拟地址访问主机内存中的Embedding表,同时将Embedding页固定以防止迁移。此外,由于Embedding不能全量的加载到HBM侧且TBE在主机内存上的访问性能受限于 GPU 与 CPU 之间的通信连接(例如 PCIe),因此TBE 提供了cache机制 将部分频繁被访问的key加载到cache中,提升访存命中率。缓存中的key更新策略可使用最近最少使用(LRU)算法进行驱逐。
Embedding模块通过实现Table Batched Embedding (TBE) 技术,将多个Embedding表的查找操作合并执行,极大提升了GPU的计算效率。为了突破单卡GPU内存对模型容量的限制,系统采用了分级存储 策略:将完整的Embedding表存放于主机内存,同时在GPU内存中维护一个动态缓存 。通过高效的数据换入换出 机制,确保训练时GPU能快速访问到当前所需的热点数据,从而实现了用有限显存支撑超大规模稀疏模型训练的目标。
2、预取与流水线相互结合实现掩盖 :预取操作在 TBE 前向传播之前,将下一次迭代的嵌入加载到缓存中。 如果某些行无法预取,TBE 会在前向和反向传播过程中直接访问主机内存。为了确保预取过程不被暴露,其在训练流水线中增加了一个预取阶段,并使其在独立流上运行,以实现与其他 GPU 操作的重叠。预取流水线需要确保batch i+1的行不会驱逐batch i的现有行。
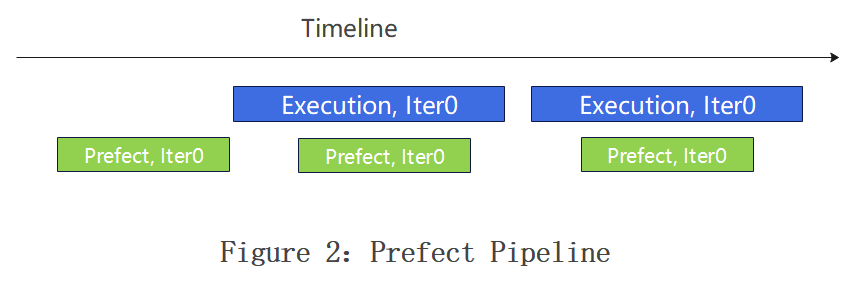
预取和Pipline结合需要综合考虑当前batch和预取batch之间的cache冲突,需要为当前训练batch所需的key预留缓存资源。若当前批次(batch i)中某个key的预取因缓存容量不足失败,该key将直接由主机内存加载以供训练。此时,若下一批次(batch i+1)尝试预取同一key,会因该行key可能正在被batch i的反向传播更新,而引发缓存读写竞态。为确保一致性,必须要求batch i+1的预取操作在batch i的嵌入反向传播开始前完成。基于此约束,当前方案中预取的size设置为1,HBM侧的内存申请空间一般不少于两个batch。
3、分片策略优化:大Embedding表场景下,双级缓存方案的Cache Size(缓存大小)设计与HBM存储容量之间存在紧密的协同优化关系,核心目标是在有限HBM容量约束下最大化缓存命中率,其动态平衡关系受分片策略影响,需在内存容量和性能之间做一个平衡。
好的分片策略需要提前统计Embedding表的局部信息,包括多个批次数据中活跃的key数量确定有效缓存大小、离线统计不同cacheSize下缓存未命中率情况获取最佳cacheSize等。缓存设置过小会使得预取操作失效(cacheSize存放不下预取数据导致加载数据时还得从host读取),缓存设置过大会导致缓存淘汰(如LFU算法)的计算开销显著上升,可能抵消命中率收益。因此,本方案中将最小缓存大小定义为两个批次Embedding的活跃数据集来同时容纳正在训练的批次和正在预取的批次。此外,分片策略还得平衡各rank间的预取时间,避免慢节点拖慢整个同步训练过程。为此,预取操作的持续时间需要提前被估算,该时间通过Embedding的LoopUp次数、缓存未命中率及计算预取数据量和GPU与主机之间的数据量和带宽来综合评估。
综上,业界普遍采用上述思想并通过高效的算法(bin-packing)在计算节点间进行分片。即使总缓存大小满足内存限制,方案可能无法分区,或者使用较少缓存预算可能产生整体更优的布局。由于bin-packing算法中的非线性,我们观察到缓存预算与方案成本之间存在非平滑关系。还可以通过一种自动搜索方法,利用无梯度优化算法探索多种缓存预算,以选择最优方案。
综上,业界普遍采用上述思想并通过高效的算法(bin-packing)在计算节点间进行分片。即使总缓存大小满足内存限制,方案可能无法分区,或者使用较少缓存预算可能产生整体更优的布局。由于bin-packing算法中的非线性,我们观察到缓存预算与方案成本之间存在非平滑关系。还可以通过一种自动搜索方法,利用无梯度优化算法探索多种缓存预算,以选择最优方案。
3、 业界方案落地实践
美团MTGR框架是美团自主研发的面向下一代推荐系统的生成式推荐模型框架,基于Meta的TorchRec大规模推荐系统训练库构建。其核心理念在于将推荐系统从传统的"匹配"或"排序"模式升级为"生成"模式,能够高效支持千亿级参数、每样本100GFLOPs甚至更高计算复杂度的大规模模型分布式训练。
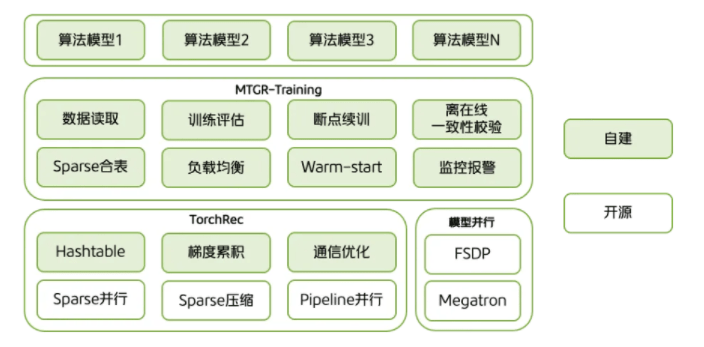
如上图所示,系统框架分为三层:
- 底层(TorchRec增强):TorchRec是Meta开源的稀疏模型训练框架,美团对其进行了功能扩展,包括支持动态哈希表、梯度累积和通信优化,以满足实际业务需求。针对生成式推荐模型中可能出现的较大稠密模块,框架借鉴了大语言模型社区的并行方案(如FSDP和Megatron)以提供支持。
- 中间层(MTGR-Training):该层是框架的核心,对训练流程进行了全面封装,涵盖离线与流式数据读取、训练与评估流程管理、断点续训、离在线一致性校验、热启动等功能,同时通过简洁的模型定义接口降低用户使用门槛。
- 上层(算法模型层):各业务线可基于框架提供的接口灵活定义个性化推荐模型,实现业务适配。
在性能优化方面,系统通过以下措施提升效率与可扩展性:
- 分布式嵌入层:支持TB级嵌入表与千亿级参数规模,确保大规模稀疏特征的高效处理。
- 高性能数据加载:优化稀疏特征处理流水线,提升数据读取与预处理效率。
- 混合并行策略:结合数据并行、模型并行与流水线并行,充分发挥分布式训练优势。
- 内存优化机制:通过动态嵌入缓存、梯度压缩等技术,有效管理内存资源,降低训练开销。
这一设计使MTGR框架能够高效支撑生成式推荐模型的训练与部署,推动推荐系统技术升级。这一新的架构,成功在美团核心的外卖首页推荐场景落地。对比基准模型,单样本前向推理FLOPs提升65倍,离线CTCVR GAUC + 2.88pp,外卖首页列表订单量+1.22%(近2年迭代单次优化最大收益),PV_CTR + 1.31%。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号