

PYQT5+Pytorch的猫狗分类(从数据集制作->网络模型搭建和训练->界面演示)
1.猫狗数据集制作
利用python爬虫爬取网上的猫狗图片,有关python爬取图片参考了这篇文章
https://blog.csdn.net/zhangjunp3/article/details/79665750
有关python爬取图片代码如下
1 # 导入需要的库 2 import requests 3 import os 4 import json 5 6 7 # 爬取百度图片,解析页面的函数 8 def getManyPages(keyword, pages): 9 ''' 10 参数keyword:要下载的影像关键词 11 参数pages:需要下载的页面数 12 ''' 13 params = [] 14 15 for i in range(30, 30 * pages + 30, 30): 16 params.append({ 17 'tn': 'resultjson_com', 18 'ipn': 'rj', 19 'ct': 201326592, 20 'is': '', 21 'fp': 'result', 22 'queryWord': keyword, 23 'cl': 2, 24 'lm': -1, 25 'ie': 'utf-8', 26 'oe': 'utf-8', 27 'adpicid': '', 28 'st': -1, 29 'z': '', 30 'ic': 0, 31 'word': keyword, 32 's': '', 33 'se': '', 34 'tab': '', 35 'width': '', 36 'height': '', 37 'face': 0, 38 'istype': 2, 39 'qc': '', 40 'nc': 1, 41 'fr': '', 42 'pn': i, 43 'rn': 30, 44 'gsm': '1e', 45 '1488942260214': '' 46 }) 47 url = 'https://image.baidu.com/search/acjson' 48 urls = [] 49 for i in params: 50 try: 51 urls.append(requests.get(url, params=i).json().get('data')) 52 except json.decoder.JSONDecodeError: 53 print("解析出错") 54 return urls 55 56 57 # 下载图片并保存 58 def getImg(dataList, localPath): 59 ''' 60 参数datallist:下载图片的地址集 61 参数localPath:保存下载图片的路径 62 ''' 63 if not os.path.exists(localPath): # 判断是否存在保存路径,如果不存在就创建 64 os.mkdir(localPath) 65 x = 0 66 for list in dataList: 67 for i in list: 68 if i.get('thumbURL') != None: 69 print('正在下载:%s' % i.get('thumbURL')) 70 ir = requests.get(i.get('thumbURL')) 71 open(localPath + '%d.jpg' % x, 'wb').write(ir.content) 72 x += 1 73 else: 74 print('图片链接不存在') 75 76 77 # 根据关键词皮卡丘来下载图片 78 if __name__ == '__main__': 79 dataList = getManyPages('狗', 40) # 参数1:关键字,参数2:要下载的页数 80 getImg(dataList, './dataset/dog/') # 参数2:指定保存的路径
在这里与原文章不同之处是加了这段代码。
1 for i in params: 2 try: 3 urls.append(requests.get(url, params=i).json().get('data')) 4 except json.decoder.JSONDecodeError: 5 print("解析出错") 6 return urls
因为我发现若下载页数过多会报错,导致下载失败,插入try except可以解决这个问题。


这里猫和狗的图片我各爬取了40页,也就是1200张图片左右,最后剔除重复及模糊错误图片还剩800张左右。
因为网络训练和测试的原因还需要将我们的数据集分为训练集和测试集。这里需要编写一个分离脚本split_data.py。
1 import os 2 3 from shutil import copy 4 5 import random 6 7 8 9 10 11 def mkfile(file): 12 13 if not os.path.exists(file): 14 15 os.makedirs(file) 16 17 18 19 20 21 file = 'data/dataset' 22 23 flower_class = [cla for cla in os.listdir(file) if ".txt" not in cla] 24 25 mkfile('data/train') 26 27 for cla in flower_class: 28 29 mkfile('data/train/'+cla) 30 31 32 33 mkfile('data/val') 34 35 for cla in flower_class: 36 37 mkfile('data/val/'+cla) 38 39 40 41 split_rate = 0.1 42 43 for cla in flower_class: 44 45 cla_path = file + '/' + cla + '/' 46 47 images = os.listdir(cla_path) 48 49 num = len(images) 50 51 eval_index = random.sample(images, k=int(num*split_rate)) 52 53 for index, image in enumerate(images): 54 55 if image in eval_index: 56 57 image_path = cla_path + image 58 59 new_path = 'data/val/' + cla 60 61 copy(image_path, new_path) 62 63 else: 64 65 image_path = cla_path + image 66 67 new_path = 'data/train/' + cla 68 69 copy(image_path, new_path) 70 71 print("\r[{}] processing [{}/{}]".format(cla, index+1, num), end="") # processing bar 72 73 print() 74 75 76 77 print("processing done!")
首先我们要把数据集文件夹目录设置好。文件夹目录为data/dataset/cat dog。刚刚爬取的图片就放在cat 和 dog 文件夹内。然后在data文件夹目录下使用命令行窗口使用split_data.py脚本,按9:1的大小分离训练集和测试集。
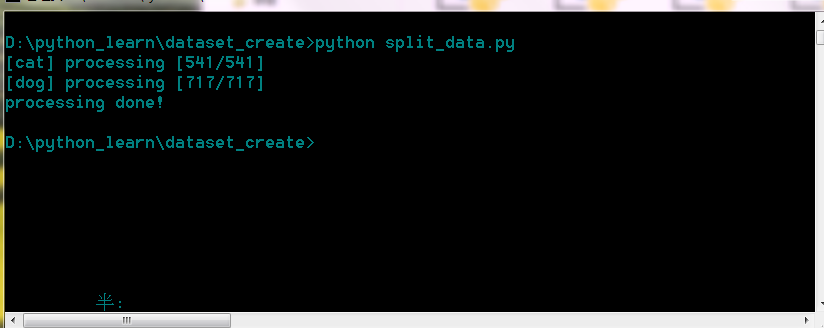
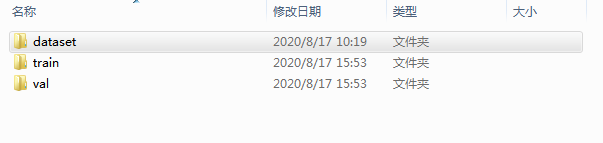
这样就分离好了,可以看到我们的数据集分成了训练集和测试集,到此我们第一步制作数据集的工作就大功告成啦。
2.基于pytorch的网络模型的搭建及训练
这部分就是卷积神经网络分类的模型和训练了,采用的是pytorch框架,基本代码都差不多,这里就直接上代码了。
首先是网络模型搭建,这里采用的经典的LeNet网络。
1 import torch 2 import torch.nn as nn 3 import torch.nn.functional as F 4 from PIL import Image 5 6 7 class LeNet(nn.Module): 8 def __init__(self): 9 super(LeNet, self).__init__() 10 self.conv1 = nn.Conv2d(3, 16, 5) 11 self.pool1 = nn.MaxPool2d(2, 2) 12 self.conv2 = nn.Conv2d(16, 32, 5) 13 self.pool2 = nn.MaxPool2d(2, 2) 14 self.fc1 = nn.Linear(32*53*53, 120) 15 self.fc2 = nn.Linear(120, 84) 16 self.fc3 = nn.Linear(84, 2) 17 18 def forward(self, x): 19 x = F.relu(self.conv1(x)) # input(3, 32, 32) output(16, 28, 28) 20 21 x = self.pool1(x) # output(16, 14, 14) 22 x = F.relu(self.conv2(x)) # output(32, 10, 10) 23 24 x = self.pool2(x) # output(32, 5, 5) 25 x = torch.flatten(x,start_dim=1) # output(32*5*5) 26 x = F.relu(self.fc1(x)) # output(120) 27 # out_put.append(x) 28 x = F.relu(self.fc2(x)) # output(84) 29 x = self.fc3(x) # output(10) 30 # out_put.append(x) 31 return x
其次是网络的训练
1 import torch 2 import torchvision 3 import os 4 import torchvision.transforms as transforms 5 import torchvision.datasets as datasets 6 import torch.optim as optim 7 from alexnet_model import AlexNet 8 from model import LeNet 9 import torch.nn as nn 10 11 12 device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu') 13 14 data_tranform ={ 15 'train':transforms.Compose( 16 [transforms.RandomResizedCrop(224), 17 transforms.ToTensor(), 18 transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))] 19 ), 20 'val':transforms.Compose( 21 [transforms.Resize((224, 224)), 22 transforms.ToTensor(), 23 transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))] 24 ) 25 } 26 27 data_root = os.getcwd() 28 29 image_path = data_root + './data' 30 31 train_dataset = datasets.ImageFolder(root=image_path+'/train',transform=data_tranform['train']) 32 val_dataset = datasets.ImageFolder(root=image_path + './val',transform=data_tranform['val']) 33 34 category_list = train_dataset.class_to_idx 35 cla_dict = dict((value,key) for key,value in category_list.items() ) 36 37 trainloader = torch.utils.data.DataLoader(train_dataset,batch_size=32,shuffle=True,num_workers=0) 38 valloader = torch.utils.data.DataLoader(val_dataset,batch_size=16,shuffle=True,num_workers=0) 39 40 #model = AlexNet(num_classes=2,init_weights=True) 41 model = LeNet() 42 model.to(device) 43 loss_function = nn.CrossEntropyLoss() 44 optim = optim.Adam(model.parameters(),lr=0.0002) 45 #savepath = './alexnet.pth' 46 savepath = './lenet.pth' 47 best_acc=0 48 49 for epoch in range(50): 50 run_loss = 0 51 model.train() 52 for step,data in enumerate(trainloader,start=0): 53 train_images,train_labels = data 54 optim.zero_grad() 55 output = model(train_images.to(device)) 56 loss = loss_function(output,train_labels.to(device)) 57 loss.backward() 58 optim.step() 59 60 # print statistics 61 run_loss += loss.item() 62 # print train process 63 rate = (step + 1) / len(trainloader) 64 a = "*" * int(rate * 50) 65 b = "." * int((1 - rate) * 50) 66 print("\rtrain loss: {:^3.0f}%[{}->{}]{:.3f}".format(int(rate * 100), a, b, loss), end="") 67 print() 68 69 model.eval() 70 acc = 0 71 with torch.no_grad(): 72 for val_data in valloader: 73 val_images,val_labels = val_data 74 val_out = model(val_images.to(device)) 75 val_pre = torch.max(val_out,dim=1)[1] 76 acc += (val_pre==val_labels.to(device)).sum().item() 77 acc_test = acc/len(val_dataset) 78 if acc_test > best_acc: 79 best_acc = acc_test 80 torch.save(model.state_dict(), savepath) 81 print('[epoch %d] train_loss: %.5f test_accuracy: %.5f' % 82 (epoch + 1, run_loss / step, acc_test))
网络最后训练的准确率大概在70%左右。
最后编写了一个预测脚本,方便和我们qt结合。
import torch
import torchvision.transforms as transforms
from PIL import Image
from alexnet_model import AlexNet
from model import LeNet
#import matplotlib.pyplot as plt
def predict_(img):
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
data_tranform ={
'train':transforms.Compose(
[transforms.RandomResizedCrop(224),
transforms.ToTensor(),
transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))]
),
'val':transforms.Compose(
[transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))]
)
}
# img = Image.open('./1.jpg')
img = data_tranform['val'](img)
img = torch.unsqueeze(img,dim=0)
# model = AlexNet(num_classes=2)
model = LeNet()
# model_weight_pth = './alexnet.pth'
model_weight_pth = './lenet.pth'
model.load_state_dict(torch.load(model_weight_pth))
model.to(device)
model.eval()
class_indict = {'0':'cat','1':'dog'}
with torch.no_grad():
# predict class
#print(model(img).size())
output = torch.squeeze(model(img))
#print(output)
predict = torch.softmax(output, dim=0)
predict_cla = torch.argmax(predict).numpy()
return class_indict[str(predict_cla)], predict[predict_cla].item()
#print(class_indict[str(predict_cla)], predict[predict_cla].item())
这样我们的第二部分工作--网络的搭建和训练就完成啦。
3.基于Pyqt5的Gui设计
这个界面设计的比较简单,直接上代码。
1 from PyQt5.QtWidgets import (QWidget,QLCDNumber,QSlider,QMainWindow, 2 QGridLayout,QApplication,QPushButton, QLabel, QLineEdit) 3 4 from PyQt5.QtGui import * 5 from PyQt5.QtCore import * 6 from PyQt5.QtWidgets import * 7 import sys 8 from PyQt5.QtCore import Qt 9 from predict import predict_ 10 from PIL import Image 11 12 13 class Ui_example(QWidget): 14 def __init__(self): 15 super().__init__() 16 17 self.layout = QGridLayout(self) 18 self.label_image = QLabel(self) 19 self.label_predict_result = QLabel('识别结果',self) 20 self.label_predict_result_display = QLabel(self) 21 self.label_predict_acc = QLabel('识别准确率',self) 22 self.label_predict_acc_display = QLabel(self) 23 24 self.button_search_image = QPushButton('选择图片',self) 25 self.button_run = QPushButton('运行',self) 26 self.setLayout(self.layout) 27 self.initUi() 28 29 def initUi(self): 30 31 self.layout.addWidget(self.label_image,1,1,3,2) 32 self.layout.addWidget(self.button_search_image,1,3,1,2) 33 self.layout.addWidget(self.button_run,3,3,1,2) 34 self.layout.addWidget(self.label_predict_result,4,3,1,1) 35 self.layout.addWidget(self.label_predict_result_display,4,4,1,1) 36 self.layout.addWidget(self.label_predict_acc,5,3,1,1) 37 self.layout.addWidget(self.label_predict_acc_display,5,4,1,1) 38 39 self.button_search_image.clicked.connect(self.openimage) 40 self.button_run.clicked.connect(self.run) 41 42 self.setGeometry(300,300,300,300) 43 self.setWindowTitle('猫狗分类') 44 self.show() 45 46 def openimage(self): 47 global fname 48 imgName, imgType = QFileDialog.getOpenFileName(self, "选择图片", "", "*.jpg;;*.png;;All Files(*)") 49 jpg = QPixmap(imgName).scaled(self.label_image.width(), self.label_image.height()) 50 self.label_image.setPixmap(jpg) 51 fname = imgName 52 53 54 55 def run(self): 56 global fname 57 file_name = str(fname) 58 img = Image.open(file_name) 59 60 a,b = predict_(img) 61 self.label_predict_result_display.setText(a) 62 self.label_predict_acc_display.setText(str(b)) 63 64 65 66 67 if __name__ == '__main__': 68 app = QApplication(sys.argv) 69 ex = Ui_example() 70 sys.exit(app.exec_())
4.效果演示
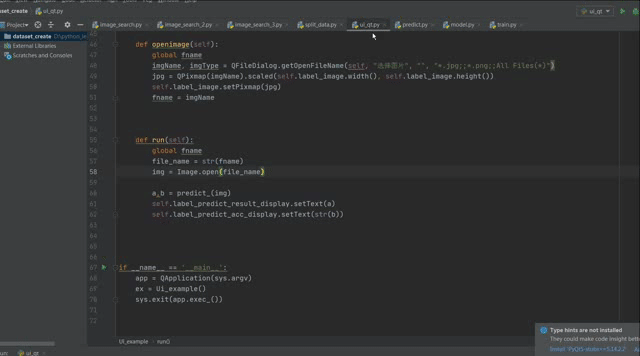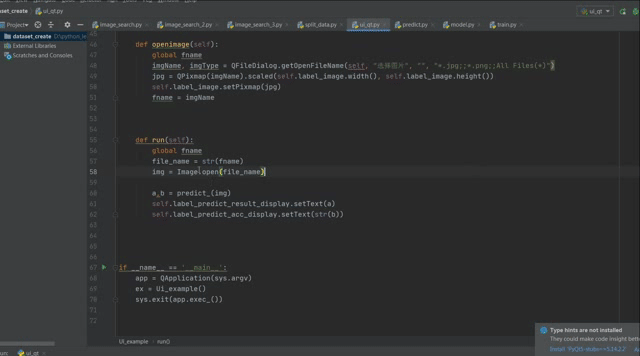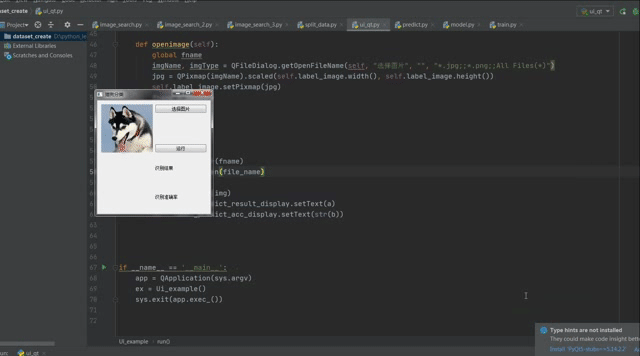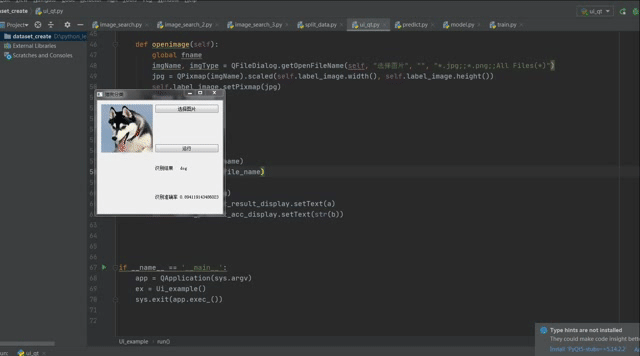

 浙公网安备 33010602011771号
浙公网安备 33010602011771号