MySQL--数据查询运行机理(mysql底层运行流程)
数据库可能是每个开发人员都接触过的东西,而在所有数据库操作中,数据查询又是最为常见的一种数据库操作方式,但是你真的了解查询吗?本文将利用MySQL带你进一步了解数据库查询。
一、MySQL运行机理
以Java程序为例,最为基本的操作过程是利用JDBC与MySQL建立连接,然后利用不同的SQL语句去完成我们所需要的操作,最终获取到执行结果。这时,Java服务就相当于是一个MySQL客户端,通过SQL语句与MySQL服务端进行交互。这一过程可以概括为下图:

从图中看,MySQL的查询流程可以分为五个步骤:
- MySQL客户端/服务端通信阶段。
- 查询缓存阶段。
- 查询解析及优化处理阶段。
- 查询执行引擎阶段。
- 返回客户端阶段。
下面依次讲解这五个阶段。
二、MySQL客户端/服务端通信阶段。
先来了解下什么是通信方式:
通信方式主要分为以下三种:
- 全双工:双向通信,发送同时也可以接收
- 半双工:双向通信,同时只能接收或者是发送,无法同时做操作
- 单工:只能单一方向传送
Mysql客户端与服务端的通信方式是“半双工”的通信方式。
也就是说,在任何一个时刻,要么是有服务器向客户端发送数据,要么是客户端向服务端发送数据,这两个动作不能同时发生。所以我们无法也无需将一个消息切成小块进行传输。
特点和限制:
客户端一旦开始发送消息,另一端要接收完整个消息才能响应。客户端一旦开始接收数据没法停下来发送指令。
三、查询缓存阶段
在解析一个查询SQL之前,如果查询缓存是开启的,那么MySQL会先去检查查询缓存中是否存在与之相同的查询。如果缓存中存在,即缓存命中,先查询用户权限,若权限允许则直接返回缓存中的结果集,无须解析本次的查询SQL语句的;如果缓存中没有,即缓存未命中,则查询会进入下一阶段的处理,等到查询出结果后,会将本次的查询SQL与查询结果存放在查询缓存中,以便之后使用。
缓存是否命中的判断标准:
查询的SQL语句与缓存的SQL语句,是否完全一样,区分大小写 (简单认为缓存存储了一个key-value结构,key为sql,value为sql查询结果集)。
查看缓存的设置情况:
show variables like 'query_cache%';
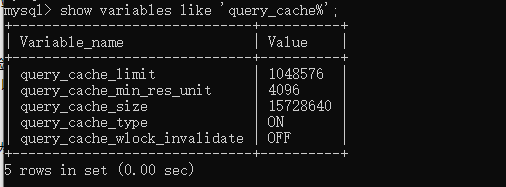
query_cache_limit: MySQL能够缓存的最大结果,如果超出,则增加 Qcache_not_cached的值,并删除查询结果,默认设置为1M。
query_cache_min_res_unit: 分配内存块时的最小单位大小。
query_cache_size: 缓存使用的总内存空间大小,单位是字节,这个值必须是1024的整数倍,否则MySQL实际分配可能跟这个数值不同(感觉这个应该跟文件系统的blcok大小有关),允许设置的值最小为40K,默认1M,推荐设置 为:64M/128M。
query_cache_type: 是否打开缓存 OFF: 关闭 ON: 总是打开。
query_cache_wlock_invalidate: 如果某个数据表被锁住,是否仍然从缓存中返回数据,默认是OFF,表示仍然可以返回。
查看缓存情况:
show status like 'Qcache%';

Qcache_hits:缓存命中次数
Qcache_inserts:往缓存中插入几条记录
需要注意的是,一旦表数据发生一点变化,与这个表所相关的缓存全部失效,不会缓存的情况:
- 当查询语句中有一些不确定的数据时,则不会被缓存。如包含函数NOW(),SQL_NO_CACHE,CURRENT_DATE()等类似的函数,或者用户自定义的函数,存储函数,用户变量等都不会被缓存。
- 当查询的结果大于query_cache_limit设置的值时,结果不会被缓存。
- 对于InnoDB引擎来说,当一个语句在事务中修改了某个表,那么在这个事务提交之前,所有与这个表相关的查询都无法被缓存。因此长时间执行事务,会大大降低缓存命中率。
- 查询的表是系统表。
- 查询语句不涉及到表。
四、查询解析及优化处理阶段
1、语法解析器和预处理器
MySQL是通过SQL关键字将SQL语句进行解析的(lex词法分析,yacc语法分析),生成一棵对应的“解析树”。
MySQL预处理器根据MySQL的语法规则进一步检查验证解析树的合法性,例如表、字段是否存在,是否使用了错误的关键字,关键字的顺序是否正确合法,还会解析名字和别名是否会有歧义等等。
2、查询优化器
查询优化器:优化器的主要作用就是找到最优的执行计划。
查询优化器如何找到最优计划:explain + sql
经过语法解析器和预处理器形成的语法树被认为是合法的了,这时将有优化器将其转化成执行计划。一条查询可以有很多种执行方式,但最后返回的结果是相同的,优化器的作用就是找到这其中最好的执行计划。
MySQL使用基于成本(CBO)的优化器,它将尝试预测一个查询使用某种执行计划的成本,并选择其中成本最小的一个。最初,成本的最小单位是随机读取一个4K数据页的成本,后来成本计算公式变得更加复杂,并且引入了一些“因子”来估算某些操作的代价,如当执行一次where条件比较的成本。可以通过查询当前会话的last_query_cost的值来得知MySQL计算的当前查询的成本。
五、查询执行引擎阶段
调用插件式的存储引擎的原子API的功能进行执行计划的执行,执行计划的好坏也是依赖于搜索引擎的。
mysql学习--MySQL存储引擎对比总结
六、返回客户端阶段
1、有需要做缓存的,执行缓存操作。
2、增量的返回结果:开始生成第一条结果时,mysql就开始往请求方逐步返回数据。
好处: mysql服务器无须保存过多的数据,浪费内存。用户体验好,马上就拿到了数据。
七、总结
MySQL使用的是“选取-投影-联接”策略进行查询。
用一个例子就可以理解: select uid,name from user where gender = 1;
1:这个select 查询先根据where 语句进行选取,而不是先将表全部查询出来以后再进行gender过滤
2:这个select查询先根据uid和name进行属性投影,而不是将属性全部取出以后再进行过滤
3:将这两个查询条件联接起来生成最终查询结果
分享所感,如有侵权,请联系删除,可扫码关注微信公众号获取更多福利噢。
本文仅限于技术交流,若造成不良影响,本文创作人员概不负责,请支持正版应用,注重产权保护!!
(您的“打赏”将是我最大的写作动力!转载请注明出处.)
本文仅限于技术交流,若造成不良影响,本文创作人员概不负责,请支持正版应用,注重产权保护!!
(您的“打赏”将是我最大的写作动力!转载请注明出处.)
 关注微信公众号 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号