mysql查询优化 -执行计划
一、查看查询计划
查询优化器如何找到最优计划:explain + sql
演示数据表:
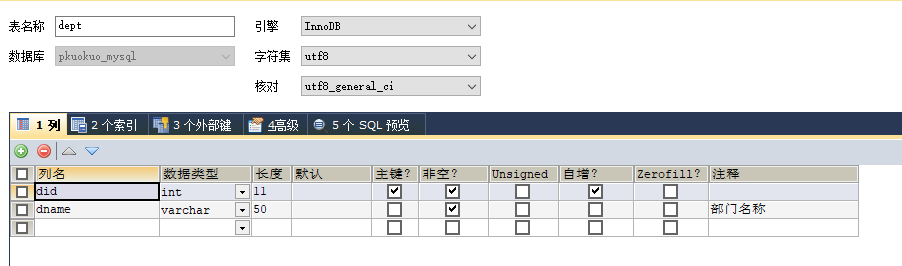
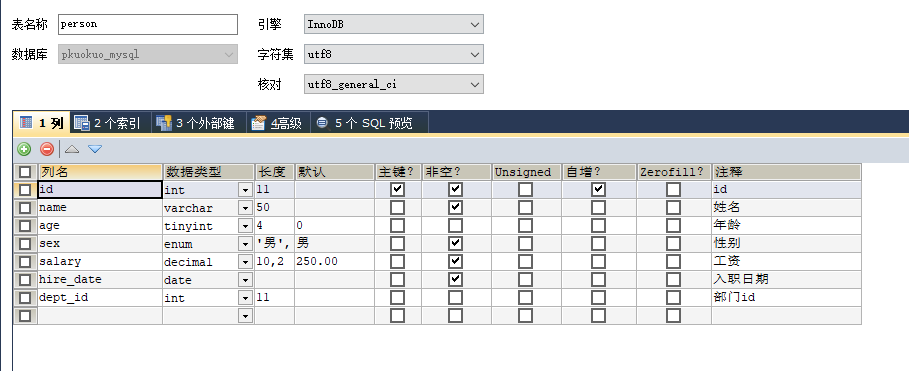
演示命令:
EXPLAIN SELECT * FROM `person` p LEFT JOIN dept d ON p.dept_id = d.did \G

二、参数解析
1、id:select查询的序列号,标识执行的顺序
- id相同,执行顺序由上至下,联表查询使用union id为空。
- id不同,如果是子查询,id的序号会递增,id值越大优先级越高,越先被执行
- id相同又不同即两种情况同时存在,id如果相同,可以认为是一组,从上往下顺序执行;在所有组中,id值越大,优先级越高,越先执行
2、select_type:查询的类型,主要是用于区分普通查询、联合查询、子查询等
- SIMPLE:简单的select查询,查询中不包含子查询或者union
- PRIMARY:查询中包含子部分,最外层查询则被标记为primary
- SUBQUERY/MATERIALIZED:SUBQUERY表示在select 或 where列表中包含了子查询
- MATERIALIZED表示where 后面in条件的子查询
- UNION:若第二个select出现在union之后,则被标记为union;
- UNION RESULT:从union表获取结果的select
3、table :查询涉及到的表
- 直接显示表名或者表的别名
- <unionM,N> 由ID为M,N 查询union产生的结果
- <subqueryN> 由ID为N查询生产的结果
4、type:访问类型,sql查询优化中一个很重要的指标,结果值从好到坏依次是:system > const > eq_ref > ref > range > index > ALL
- system:表只有一行记录(等于系统表),const类型的特例,基本不会出现,可以忽略不计
- const:表示通过索引一次就找到了,const用于比较primary key 或者 unique索引
- eq_ref:唯一索引扫描,对于每个索引键,表中只有一条记录与之匹配。常见于主键 或 唯一索引扫描
- ref:非唯一性索引扫描,返回匹配某个单独值的所有行,本质是也是一种索引访问
- range:只检索给定范围的行,使用一个索引来选择行(至少要这个级别)
- index:Full Index Scan,索引全表扫描,把索引从头到尾扫一遍
- ALL:Full Table Scan,遍历全表以找到匹配的行
执行计划:
5、possible_keys:查询过程中有可能用到的索引
6、key:实际使用的索引,如果为NULL,则没有使用索引 rows,根据表统计信息或者索引选用情况,大致估算出找到所需的记录所需要读取的行数。
7、filtered:它指返回结果的行占需要读到的行(rows列的值)的百分比。表示返回结果的行数占需读取行数的百分比,filtered的值越大越好。
8、Extra :十分重要的额外信息
- Using filesort :mysql对数据使用一个外部的文件内容进行了排序,而不是按照表内的索引进行排序读取 order by xxx desc这样子的,如果是索引字段的排序则不是这样的,就不需要使用外部文件了
- Using temporary:使用临时表保存中间结果,也就是说mysql在对查询结果排序时使用了临时表,常见于order by 或 group by
- Using index:表示相应的select操作中使用了覆盖索引(Covering Index),避免了访问表的数据行,效率高
- Using where :使用了where过滤条件
- select tables optimized away:基于索引优化MIN/MAX操作或者MyISAM存储引擎优化COUNT(*)操作,不必等到执行阶段在进行计算,查询执行。计划生成的阶段即可完成优化
分享所感,如有侵权,请联系删除,可扫码关注微信公众号获取更多福利噢。
本文仅限于技术交流,若造成不良影响,本文创作人员概不负责,请支持正版应用,注重产权保护!!
(您的“打赏”将是我最大的写作动力!转载请注明出处.)
本文仅限于技术交流,若造成不良影响,本文创作人员概不负责,请支持正版应用,注重产权保护!!
(您的“打赏”将是我最大的写作动力!转载请注明出处.)
 关注微信公众号 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号