压缩算法之LZSS---lzss 算法实现
一、前言
本文是基于我的上一篇博客《无损压缩算法专题——无损压缩算法介绍》的基础上来实现的,博客链接https://blog.csdn.net/qq_34254642/article/details/103651815,这一篇当中实现基本的LZSS算法功能,先不做改进,所以算法效率比较低,但是便于理解。写了Python和C两个版本,两种语言的代码结构是一样的,代码中都有详尽的注释。实现了对任意文件的压缩和解压功能。
二、LZSS算法实现
Python实现
import ctypes
import os
class LZSS():
def __init__(self, preBufSizeBits):
self.threshold = 2 #长度大于等于2的匹配串才有必要压缩
self.preBufSizeBits = preBufSizeBits #前向缓冲区占用的比特位
self.windowBufSizeBits = 16 - self.preBufSizeBits #滑动窗口占用的比特位
self.preBufSize = (1 << self.preBufSizeBits) - 1 + self.threshold #通过占用的比特位计算缓冲区大小
self.windowBufSize = (1 << self.windowBufSizeBits) - 1 + self.threshold #通过占用的比特位计算滑动窗口大小
self.preBuf = b'' #前向缓冲区
self.windowBuf = b'' #滑动窗口
self.matchString = b'' #匹配串
self.matchIndex = 0 #滑动窗口匹配串起始下标
#文件压缩
def LZSS_encode(self, readfilename, writefilename):
fread = open(readfilename, "rb")
fwrite = open(writefilename, "wb")
restorebuff = b'' #待写入的数据缓存区,满一组数据写入一次文件
itemnum = 0 #8个项目为一组,用来统计当前项目数
signbits = 0 #标记字节
self.preBuf = fread.read(self.preBufSize) #读取数据填满前向缓冲区
# 前向缓冲区没数据可操作了即为压缩结束
while self.preBuf != b'':
self.matchString = b''
self.matchIndex = -1
#在滑动窗口中寻找最长的匹配串
for i in range(self.threshold, len(self.preBuf) + 1):
index = self.windowBuf.find(self.preBuf[0:i])
if index != -1:
self.matchString = self.preBuf[0:i]
self.matchIndex = index
else:
break
#如果没找到匹配串或者匹配长度为1,直接输出原始数据
if self.matchIndex == -1:
self.matchString = self.preBuf[0:1]
restorebuff += self.matchString
else:
restorebuff += bytes(ctypes.c_uint16(self.matchIndex * (1 << self.preBufSizeBits) + len(self.matchString) - self.threshold))
signbits += (1 << (7 - itemnum))
#操作完一个项目+1
itemnum += 1
#项目数达到8了,说明做完了一组压缩,将这一组数据写入文件
if itemnum >= 8:
writebytes = bytes(ctypes.c_uint8(signbits)) + restorebuff
fwrite.write(writebytes);
itemnum = 0
signbits = 0
restorebuff = b''
self.preBuf = self.preBuf[len(self.matchString):] #将刚刚匹配过的数据移出前向缓冲区
self.windowBuf += self.matchString #将刚刚匹配过的数据加入滑动窗口
if len(self.windowBuf) > self.windowBufSize: #将多出的数据从前面开始移出滑动窗口
self.windowBuf = self.windowBuf[(len(self.windowBuf) - self.windowBufSize):]
self.preBuf += fread.read(self.preBufSize - len(self.preBuf)) #读取数据补充前向缓冲区
if restorebuff != b'': #文件最后可能不满一组数据量,直接写到文件里
writebytes = bytes(ctypes.c_uint8(signbits)) + restorebuff
fwrite.write(writebytes);
fread.close()
fwrite.close()
return os.path.getsize(writefilename)
#文件解压
def LZSS_decode(self, readfilename, writefilename):
fread = open(readfilename, "rb")
fwrite = open(writefilename, "wb")
self.windowBuf = b''
self.preBuf = fread.read(1) #先读一个标记字节以确定接下来怎么解压数据
while self.preBuf != b'':
for i in range(8): #8个项目为一组进行解压
# 从标记字节的最高位开始解析,0代表原始数据,1代表(下标,匹配数)解析
if self.preBuf[0] & (1 << (7 - i)) == 0:
temp = fread.read(1)
fwrite.write(temp)
self.windowBuf += temp
else:
temp = fread.read(2)
start = ((temp[0] + temp[1] * 256) // (1 << self.preBufSizeBits)) #取出高位的滑动窗口匹配串下标
end = start + temp[0] % (1 << self.preBufSizeBits) + self.threshold #取出低位的匹配长度
fwrite.write(self.windowBuf[start:end]) #将解压出的数据写入文件
self.windowBuf += self.windowBuf[start:end] #将解压处的数据同步写入到滑动窗口
if len(self.windowBuf) > self.windowBufSize: #限制滑动窗口大小
self.windowBuf = self.windowBuf[(len(self.windowBuf) - self.windowBufSize):]
self.preBuf = fread.read(1) #读取下一组数据的标志字节
fread.close()
fwrite.close()
if __name__ == '__main__':
Demo = LZSS(7)
Demo.LZSS_encode("115.log", "encode")
Demo.LZSS_decode("encode", "decode")

C实现
#include <string.h>
#include <stdio.h>
#define BYTE unsigned char
#define WORD unsigned short
#define DWORD unsigned int
#define TRUE 1
#define FALSE 0
BYTE bThreshold; //压缩阈值、长度大于等于2的匹配串才有必要压缩
BYTE bPreBufSizeBits; //前向缓冲区占用的比特位
BYTE bWindowBufSizeBits; //滑动窗口占用的比特位
WORD wPreBufSize; //通过占用的比特位计算缓冲区大小
WORD wWindowBufSize; //通过占用的比特位计算滑动窗口大小
BYTE bPreBuf[1024]; //前向缓冲区
BYTE bWindowBuf[8192]; //滑动窗口
BYTE bMatchString[1024]; //匹配串
WORD wMatchIndex; //滑动窗口匹配串起始下标
BYTE FindSameString(BYTE *pbStrA, WORD wLenA, BYTE *pbStrB, WORD wLenB, WORD *pwMatchIndex); //查找匹配串
DWORD LZSS_encode(char *pbReadFileName, char *pbWriteFileName); //文件压缩
DWORD LZSS_decode(char *pbReadFileName, char *pbWriteFileName); //文件解压
int main()
{
bThreshold = 2;
bPreBufSizeBits = 6;
bWindowBufSizeBits = 16 - bPreBufSizeBits;
wPreBufSize = ((WORD)1 << bPreBufSizeBits) - 1 + bThreshold;
wWindowBufSize = ((WORD)1 << bWindowBufSizeBits) - 1 + bThreshold;
LZSS_encode("115.log", "encode");
LZSS_decode("encode", "decode");
return 0;
}
BYTE FindSameString(BYTE *pbStrA, WORD wLenA, BYTE *pbStrB, WORD wLenB, WORD *pwMatchIndex)
{
WORD i, j;
for (i = 0; i < wLenA; i++)
{
if ((wLenA - i) < wLenB)
{
return FALSE;
}
if (pbStrA[i] == pbStrB[0])
{
for (j = 1; j < wLenB; j++)
{
if (pbStrA[i + j] != pbStrB[j])
{
break;
}
}
if (j == wLenB)
{
*pwMatchIndex = i;
return TRUE;
}
}
}
return FALSE;
}
DWORD LZSS_encode(char *pbReadFileName, char *pbWriteFileName)
{
WORD i, j;
WORD wPreBufCnt = 0;
WORD wWindowBufCnt = 0;
WORD wMatchStringCnt = 0;
BYTE bRestoreBuf[17] = { 0 };
BYTE bRestoreBufCnt = 1;
BYTE bItemNum = 0;
FILE *pfRead = fopen(pbReadFileName, "rb");
FILE *pfWrite = fopen(pbWriteFileName, "wb");
//前向缓冲区没数据可操作了即为压缩结束
while (wPreBufCnt += fread(&bPreBuf[wPreBufCnt], 1, wPreBufSize - wPreBufCnt, pfRead))
{
wMatchStringCnt = 0; //刚开始没有匹配到数据
wMatchIndex = 0xFFFF; //初始化一个最大值,表示没匹配到
for (i = bThreshold; i <= wPreBufCnt; i++) //在滑动窗口中寻找最长的匹配串
{
if (TRUE == FindSameString(bWindowBuf, wWindowBufCnt, bPreBuf, i, &wMatchIndex))
{
memcpy(bMatchString, &bWindowBuf[wMatchIndex], i);
wMatchStringCnt = i;
}
else
{
break;
}
}
//如果没找到匹配串或者匹配长度为1,直接输出原始数据
if ((0xFFFF == wMatchIndex))
{
wMatchStringCnt = 1;
bMatchString[0] = bPreBuf[0];
bRestoreBuf[bRestoreBufCnt++] = bPreBuf[0];
}
else
{
j = (wMatchIndex << bPreBufSizeBits) + wMatchStringCnt - bThreshold;
bRestoreBuf[bRestoreBufCnt++] = (BYTE)j;
bRestoreBuf[bRestoreBufCnt++] = (BYTE)(j >> 8);
bRestoreBuf[0] |= (BYTE)1 << (7 - bItemNum);
}
bItemNum += 1; //操作完一个项目+1
if (bItemNum >= 8) //项目数达到8了,说明做完了一组压缩,将这一组数据写入文件,同时清空缓存
{
fwrite(bRestoreBuf, 1, bRestoreBufCnt, pfWrite);
bItemNum = 0;
memset(bRestoreBuf, 0, sizeof(bRestoreBuf));
bRestoreBufCnt = 1;
}
//将刚刚匹配过的数据移出前向缓冲区
for (i = 0; i < (wPreBufCnt - wMatchStringCnt); i++)
{
bPreBuf[i] = bPreBuf[i + wMatchStringCnt];
}
wPreBufCnt -= wMatchStringCnt;
//如果滑动窗口将要溢出,先提前把前面的部分数据移出窗口
if ((wWindowBufCnt + wMatchStringCnt) > wWindowBufSize)
{
j = ((wWindowBufCnt + wMatchStringCnt) - wWindowBufSize);
for (i = 0; i < (wWindowBufSize - j); i++)
{
bWindowBuf[i] = bWindowBuf[i + j];
}
wWindowBufCnt = wWindowBufSize - wMatchStringCnt;
}
//将刚刚匹配过的数据加入滑动窗口
memcpy((BYTE *)&bWindowBuf[wWindowBufCnt], bMatchString, wMatchStringCnt);
wWindowBufCnt += wMatchStringCnt;
}
//文件最后可能不满一组数据量,直接写到文件里
if (0 != bRestoreBufCnt)
{
fwrite(bRestoreBuf, 1, bRestoreBufCnt, pfWrite);
}
fclose(pfRead);
fclose(pfWrite);
return 0;
}
DWORD LZSS_decode(char *pbReadFileName, char *pbWriteFileName)
{
WORD i, j;
BYTE bItemNum;
BYTE bFlag;
WORD wStart;
WORD wMatchStringCnt = 0;
WORD wWindowBufCnt = 0;
FILE *pfRead = fopen(pbReadFileName, "rb");
FILE *pfWrite = fopen(pbWriteFileName, "wb");
while (0 != fread(&bFlag, 1, 1, pfRead)) //先读一个标记字节以确定接下来怎么解压数据
{
for (bItemNum = 0; bItemNum < 8; bItemNum++) //8个项目为一组进行解压
{
//从标记字节的最高位开始解析,0代表原始数据,1代表(下标,匹配数)解析
if (0 == (bFlag & ((BYTE)1 << (7 - bItemNum))))
{
if (fread(bPreBuf, 1, 1, pfRead) < 1)
{
goto LZSS_decode_out_;
}
fwrite(bPreBuf, 1, 1, pfWrite);
bMatchString[0] = bPreBuf[0];
wMatchStringCnt = 1;
}
else
{
if (fread(bPreBuf, 1, 2, pfRead) < 2)
{
goto LZSS_decode_out_;
}
//取出高位的滑动窗口匹配串下标
wStart = ((WORD)bPreBuf[0] | ((WORD)bPreBuf[1] << 8)) / ((WORD)1 << bPreBufSizeBits);
//取出低位的匹配长度
wMatchStringCnt = ((WORD)bPreBuf[0] | ((WORD)bPreBuf[1] << 8)) % ((WORD)1 << bPreBufSizeBits) + bThreshold;
//将解压出的数据写入文件
fwrite(&bWindowBuf[wStart], 1, wMatchStringCnt, pfWrite);
memcpy(bMatchString, &bWindowBuf[wStart], wMatchStringCnt);
}
//如果滑动窗口将要溢出,先提前把前面的部分数据移出窗口
if ((wWindowBufCnt + wMatchStringCnt) > wWindowBufSize)
{
j = (wWindowBufCnt + wMatchStringCnt) - wWindowBufSize;
for (i = 0; i < wWindowBufCnt - j; i++)
{
bWindowBuf[i] = bWindowBuf[i + j];
}
wWindowBufCnt -= j;
}
//将解压处的数据同步写入到滑动窗口
memcpy(&bWindowBuf[wWindowBufCnt], bMatchString, wMatchStringCnt);
wWindowBufCnt += wMatchStringCnt;
}
}
LZSS_decode_out_:
fclose(pfRead);
fclose(pfWrite);
return 0;
}
三、性能分析
因为代码都是最基本的实现,并没有对匹配串搜索函数进行优化,所以时间性能上比较低,我们这里只对比压缩前后文件的字节大小。有一点要提到的就是代码里面有个threshold参数为2,意思是匹配串大于等于2才有必要进行压缩,因为(位置,长度)这个标记的输出长度为16比特位,所以匹配串只有1字节也用这种方式表示的话显然起不到压缩效果。大家还可以发现一个问题,写入文件时匹配长度并不是实际值,因为0和1的匹配长度是不存在的,所以干脆把0当做2,1当做3这样来看待,就可以把匹配长度扩充两个长度了。
确定了(位置,长度)的输出格式为两个字节后,接下里就是怎么选取“位置”和“长度”各自所应该占用的比特位是多少了,我们可以设置为(8,8),(9,7),(10,6)等等这样的组合,但是给“位置”设置的比特位一定要大于等于“长度”的比特位,原因是滑动窗口大小要大于等于前向缓冲区大小,不然没有意义。对于相同的文件,这两个参数选取不同,那么压缩率也会不同,下面是我对一个log文件选取不同的参数进行压缩后的文件大小对比图,图中preBufSizeBits就是指的“长度”所占的比特位数:
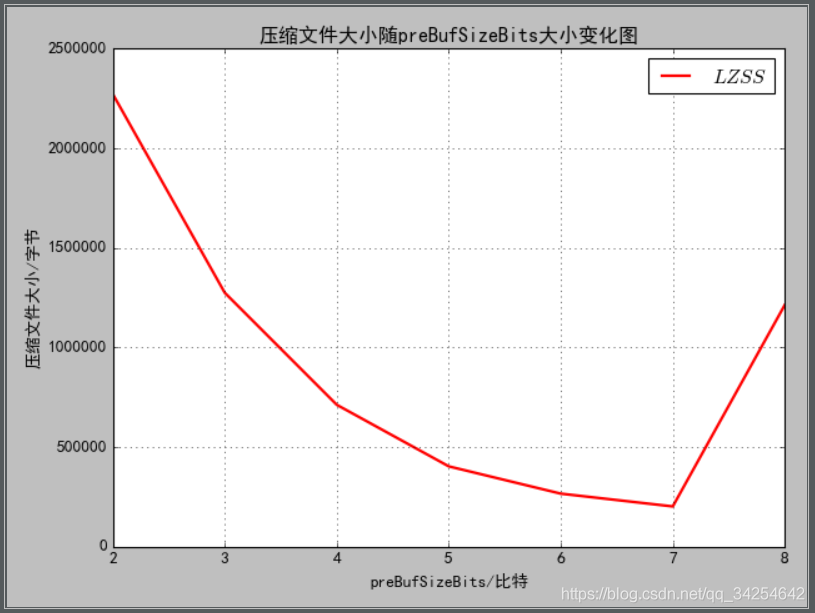
未压缩的原始文件大小是5.06MB,可以清晰的看出preBufSizeBits并不是越小越好,也不是越大越好,因为如果preBufSizeBits小了的话那么前向缓冲区也就小了,一次能匹配的数据串就小了;如果preBufSizeBits大了的话那么虽然前向缓冲区变大了,但是滑动窗口会缩小,数据串的匹配范围就变小了。所以需要选择一个合适的值才能使文件压缩性能最好。
算法内部的对比就到这里了,接下来我们和当前流行的ZIP和RAR进行压缩性能对比,虽然感觉自不量力,但是有对比才有进步嘛。
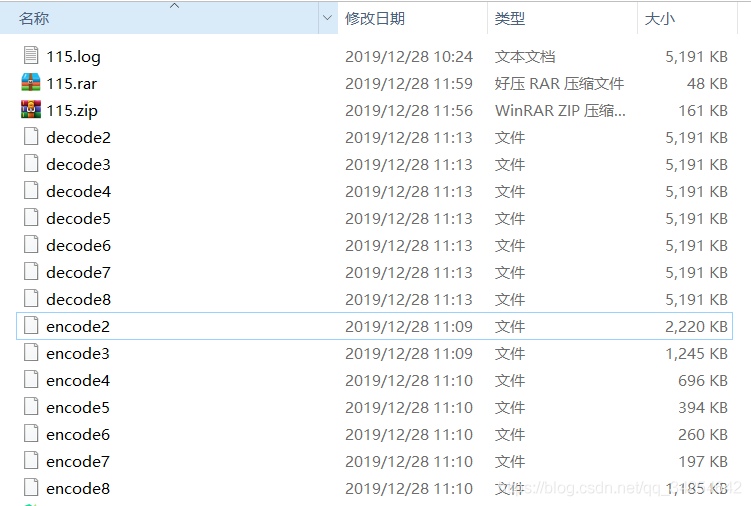
115.log是原始文件,encode2到encode8其实就是上边性能图里不同preBufSizeBits时生成的压缩文件,decode2到decode8是对应再解压缩出来的文件。115.rar是用电脑上RAR软件压缩的文件,115.zip是用电脑上ZIP软件压缩的文件。我们这个算法最好的性能是压缩到了197KB,和ZIP的161KB差距不是特别大,和RAR就差了相当一大截了。 因为ZIP其实也是类似的滑动窗口匹配压缩,所以接下来优化LZSS算法的话,还是要尽量向ZIP的性能看齐。
四、总结
接下来还会继续思考LZSS算法的改进,包括压缩率和压缩/解压时间的性能,因为我本人是嵌入式工程师,所以会思考实现在嵌入式设备上如何运用数据压缩,在网上查找资料的时候也找到了一些开源的压缩库,但是使用上可能会存在一些问题和限制,当然最好是我们使用的算法我们是知根知底的,这样我们就可以根据项目的需求和特点进行灵活的修改和运用,出了什么问题也不会太慌。
https://blog.csdn.net/I_canjnu/article/details/106353207 闪存——磨损均衡
https://blog.csdn.net/m0_37621078/article/details/103282134
https://github.com/StreamAI/LwIP_Projects LwIP_Projects
https://github.com/jiejieTop/LwIP_2.1.2_Comment/tree/master/lwip-2.1.2/src
https://blog.csdn.net/m0_37621078/article/details/103282134 TCP/IP协议栈之LwIP(十一)--- LwIP协议栈移植

 浙公网安备 33010602011771号
浙公网安备 33010602011771号