【算法】希尔排序学习笔记
【参考资料】
《算法(第4版)》 — — Robert Sedgewick, Kevin Wayne
在本篇笔记里,我从简单的插入排序,到希尔排序,中间的一系列算法,看起来就像是插入排序的“发展史”一般。这些点分别是:
- 直接插入排序(插入排序1.0版本)
- 基于插入排序的简单优化(插入排序1.1和1.2版本)
- 折半插入排序(插入排序2.0版本)
- 希尔排序(插入排序3.0版本)
直接插入排序(插入排序1.0)
直接插入排序的概念
将一个数组元素插入到已经有序的序列中, 并使得比它大的元素全部右移一位,如此对所有元素处理的排序方式, 叫做直接插入排序。
(文章的排序默认是左小右大的顺序)
单个元素的插入过程
对待插入元素来说, 它的左边是一堆已经有序但未来可能发生位置变动(右移)的元素。
这两点很重要: 已经有序和位置变动。
- 待排序元素左边序列已经有序, 这是正确插入的基础, 只有在这个前提下, 待排序元素才能在从左到右的比较和交换中插入正确的位置。
- 待排序元素的插入需要腾出空间, 这就需要使已有序序列中比它大的元素全部右移一位。
(下图中显示的是a[0]<a[4]<a[1]的情况)
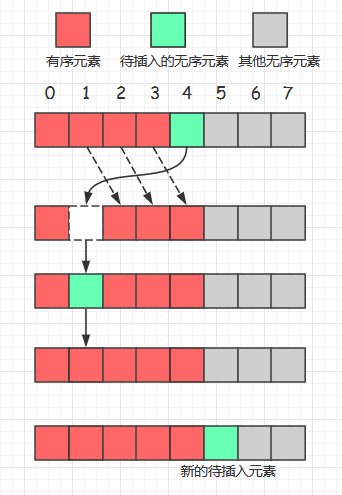
上面的图示范告诉我们要做两件事: “将元素放入适当位置”,“将有序序列中大于元素的部分全部右移一位”, 具体应该怎么做呢?
我们是这样做的:
- 和相邻的左边元素的值比较大小
- 如果左边元素大于待排序元素,则交换两者的值,左边元素的值“右移”一位。
- 如果左边元素小于等于待排序元素,说明已经插入到“合适位置”了,一趟插入结束。
单个元素插入结束后,原来的有序序列的长度增加了一位, 当这个长度不断增长直到覆盖整个数组时,直接插入排序就完成了。
直接插入排序的代码
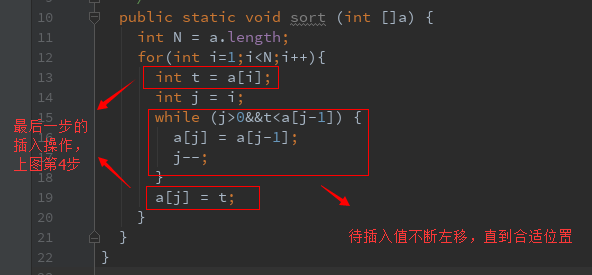
我们一般用两个嵌套的for循环来处理上面的逻辑, 在外部for循环中,设置变量 i 控制当前待插入元素的下标的移动;在内部for循环中,设置变量j用于控制待插入的值的比较和交换(左移到合适位置)
代码如下:
/** * @Author: HuWan Peng * @Date Created in 23:16 2017/12/1 */ public class InsertSort { /** * @description: 交换a[i]和a[j]的值 */ private static void exch (int []a,int i,int j) { int temp = a[i]; a[i] = a[j]; a[j] = temp; } /** * @description: 插入排序 */ public static void sort (int []a) { int N = a.length; for(int i=1;i<N;i++){ for(int j=i;j>0&&a[j]<a[j-1];j--){ exch(a,j,j-1); } } } }
测试:
public class Test { public static void main (String args[]){ int [] a = {1,6,3,2,9,7,8,1,5,0}; InsertSort.sort(a); for(int i=0;i<a.length;i++){ System.out.println(a[i]); } } }
时间复杂度
对于随机排列的长度为N的值不重复的数组
最好情况下: 数组是完全有序的,那么这个时候,每插入一个元素的时候,只要和前一个元素做比较就可以了,而且不需要交换。总共: 比较次数为N-1, 交换次数为0。时间复杂度为O(N)
最坏情况下: 数组是完全逆序的,插入下标为N的元素的时候, 要做N次比较和N次交换。例如对{5,4,3,2,1}。插入下标为1的4时候,4要和5比较和交换,数组变成{4,5,3,2,1};这时到下标为2的3插入,3要和4,5比较和交换。 所以,总的比较、交换次数是1+2+3...+(N-1) = N(N-1)/2≈ (N^2) / 2,时间复杂度为O(N^2)
平均情况: 需要(N^2) / 4次比较和(N^2) / 4次交换,时间复杂度为O(N^2)
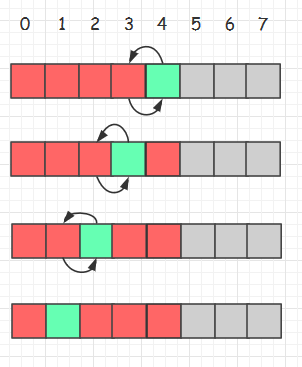
直接插入排序的轨迹
对插入排序简单优化(插入排序1.1版本)
在排序中,有两项重要的任务,分别是“条件判断”和“元素移动”。因此,我们优化插排的着眼点也在于次,如何“减少条件判断”和“减少元素移动”,从而优化插排的性能
优化点一: 去除内循环中j>0的判断条件
先来看看我们的内循环的判断条件
for(int j=i;j>0&&a[j]<a[j-1];j--){ exch(a,j,j-1); }
原因
j>0的判断是为了防止j不断自减的过程中到达a[-1]导致数组越界的错误。
更直接,具体一点说, 这个可能发生的错误是针对j>0后面的a[j]<a[j-1]这个表达式的。(就为了防止a[0]<a[-1]的发生)
思路
基于这一点,去除j>0判断条件的思路是: 只要a[j]<a[j-1]能“主动防御”数组越界的错误,例如在j=1这个临界点变为false跳出循环, 我们不就不需要加j>0这个条件判断了吗?
方法
基于上面的思路,我们的方法是:
在排序开始前将数组里最小的元素移动到数组的最左边即a[0]。这样,当j减小到1的时候,无论a[1]是数组中任何一个元素, 对 a[1]<a[0]都是false ! 循环自动跳出,这样,就算没有j>0的保护, 我们的a[j]<a[j-1]也是安全的! 于是我们就可以把j>0去除了
代码如下:
/** * @Author: HuWan Peng * @Date Created in 23:16 2017/12/1 */ public class InsertSort { /** * @description: 交换a[i]和a[j]的值 */ private static void exch (int []a,int i,int j) { int temp = a[i]; a[i] = a[j]; a[j] = temp; } /** * @description: 将数组a中最小的元素移到最左边即a[0]; */ private static void moveMinLeft (int []a) { int min=0; for (int i=0;i<a.length;i++) { if(a[i]<a[min]){ min = i; } } exch(a,0,min); } /** * @description: 插入排序 */ public static void sort (int []a) { moveMinLeft(a); int N = a.length; for(int i=1;i<N;i++){ for(int j=i;a[j]<a[j-1];j--){ // j<0的条件已经去除 exch(a,j,j-1); } } } }
优化点二:避免交换,减少移动(元素)
在原始的插入排序中,我使用了元素交换的方法exch:
private static void exch (int []a,int i,int j) { int temp = a[i]; a[i] = a[j]; a[j] = temp; }
这会在待插入值左移的过程中,每移一位, 造成两次的元素移动:a[i] = a[j];和 a[j] = a[i];
但实际上,我们可以实现插入值左移一位时, 只移动一次元素的操作:
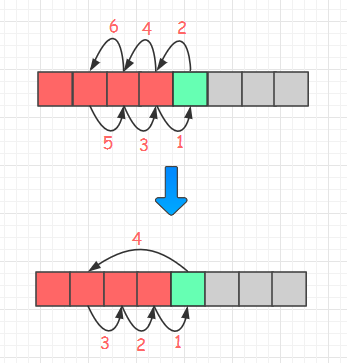
我们可以先用一个临时变量保存待插入的值,将“插入”的操作留给最后一步(4),这样,在忽略最后一步的情况下,我们的确把数组元素的移动次数减少了一半!
代码如下:
/** * @Author: HuWan Peng * @Date Created in 23:16 2017/12/1 */ public class InsertSort { /** * @description: 不用exch的插入排序 */ public static void sort (int []a) { int N = a.length; for(int i=1;i<N;i++){ int t = a[i]; int j = i; while (j>0&&t<a[j-1]) { a[j] = a[j-1]; j--; } a[j] = t; } } }
折半插入排序(插入排序2.0)
虽然上面我们做了减少元素移动量的优化, 元素的移动量已经被减至最低了,在这一部分已经“没有油水可以压榨了”,如果想要进一步“削减开支”的话,就要从另一方面——“元素比较”入手啦
如下图所示,我们要把3插入到0 1 2 4 5 6 7 8 9中的话,总共要做8次a[j]<a[j-1]的比较,这种比较操作量感觉有点昂贵,有什么减少这个比较量的方法吗?

让我们思考下已有的条件和要解决的问题: 有序序列, 插入元素到合适位置。
等等!! 似乎这让我们想起了什么。
是二分法! 这个需求简直就是为二分法私人定制的,因为二分法最擅长处理的情景,就是:在一个有序数组中找到目标元素,或者确认该元素并不存在。在这种情景需求下,二分法显得相当简洁高效。我们的任务是在“在有序数组中寻找一个值的合适位置”, 这和二分法的“主体业务”很类似,嗯,就决定是它了!
和二分法相结合的插入排序, 叫做折半插入排序
二分法的思想以及高效的原因
二分法查找:设置一个循环,不断将数组的中间值(mid)和被查找的值比较,如果被查找的值等于a[mid],就返回mid; 否则,就将查找范围缩小一半。如果被查找的值小于a[mid], 就继续在左半边查找;如果被查找的值大于a[mid], 就继续在右半边查找。 直到查找到该值或者查找范围为空时, 查找结束。
如下图所示:
(注意:前提是数组有序!)

更准确地说,折半插入排序的场景类似于二分法中的未命中查找(如上图所示)
通过二分法查找插入位置时的轨迹

如果我们把二分查找的思想运用到插入排序中去就可以把原来需要8次的比较减少至3次!
未使用二分法: 8次比较
使用二分法: 3次比较
这个差距随着数组规模的扩大会越发剧烈。
我们的目标是: 在a[0]到a[9]中查找数值3的插入位置。
第一轮二分
首先取中间值: mid = (0 + 9)/2 = 4; 又因为a[4] = 5 > 3, 结合数组有序性可知: 数值3插入的目标位置一定在a[0]到a[4]之间(一定不在a[5]到a[10]之间), 于是将查找范围缩小一半,下一轮在a[0]到a[4]间查找
第二轮二分
取得中间值: mid = (0 + 4)/2 =2; 因为a[2] = 2< 3, 数值3插入的目标位置一定在a[3]到a[4]之间(一定不在a[0]到a[2]之间)。 于是将查找范围缩小一半,下一轮在a[3]到a[4]间查找
第三轮二分
取中间值: mid = (3 + 4)/2 = 3, 因为a[3] = 4 >3, 所以a[3]就是最终插入的位置。
找到插入位置之后, 将插入位置后面所有比插入元素大的有序元素全部右移一位,再将待插入的值放入对应位置。 这一点和上面介绍的优化点二做的事情一样。 也就是说:折半插入排序在减少比较次数的同时, 也减少了元素移动次数。
折半插入排序代码如下:
/** * @Author: HuWan Peng * @Date Created in 11:27 2017/12/2 */ public class BinaryInsertSort { private static int binarySearch (int []a,int low,int high, int target) { int mid; while (low<=high) { mid = (low + high)/2; if(a[target]>a[mid]) { low = mid+1; } else { high = mid-1; } } return low; } public static void sort (int []a) { int N = a.length; for (int i=1;i<N;i++) { int temp = a[i]; int low = binarySearch(a,0,i-1,i); for(int j=i;j>low;j--){ a[j]=a[j-1]; } a[low]= temp; } } }
时间复杂度
折半插入排序在一定程度上优化了插排的性能, 但是因为它仅仅减少了关键字间的比较次数,而记录的移动次数保持不变。因此,折半插入排序的时间复杂度仍然是O(n^2)
希尔排序(插入排序3.0)
出现的原因
总的来说,插入排序是一种基础的排序方法,因为移动元素的次数较多, 对于大规模的复杂数组,它的排序性能表现并不理想。 而对于长度较短的、部分有序(或有序)的数组的处理,性能表现比较良好。
所以根据插排优于处理小型,部分有序数组的特性, 人们在插入排序的基础上设计出一种能够较好地处理中等规模的排序算法: 希尔排序
实现的过程
希尔排序又叫做步长递减插入排序或增量递减插入排序
(下面的h就是步长)
1. 选择一个递增序列。并在递增序列中,选择小于数组长度的最大值,作为初始步长 h。
2. 开始的时候,将数组分为h个独立的子数组(1中h), 每个子数组中每个元素等距离分布,各个元素距离都是h。
3. 对2中分割出的子数组分别进行插入排序
4. 第一轮分组的插入排序完成后,根据递增序列(逆向看)减少h的值并进行第二轮分组, 同样对各个子数组分别插入排序。 不断循环1、2、4, 直到h减少到1时候, 进行最后一轮插入排序,也就是针对整个数组的直接插入排序(这个时候分组只有1个,即整个数组本身)
5. 一开始的时候h的值是比较大的(例如可以占到整个数组长度的一半),所以一开始的时候子数组的数量很多,而每个子数组长度很小。 随着h的减小,子数组的数量越来越少,而单个子数组的长度越来越大。
【注意】 递增序列的选择是任意的 , 但不同的递增序列会影响排序的性能
下面的代码中, 我们选择的递增序列是1,4 ,13,40,121,364,1093... 假设数组长度是N的话,一开始通过
while(h<N/3){ h=3*h+1; }
选择初始步长, 并通过h = h/3,使h按照逆序的递增序列减少,一直到1, 分别进行多轮分组插入排序。
代码如下:
/** * @Author: HuWan Peng * @Date Created in 12:54 2017/12/2 */ public class ShellSort { private static void exch(int []a,int i,int j) { int temp = a[i]; a[i] = a[j]; a[j] = temp; } public static void sort (int [] a) { int N = a.length; int h = 1; while(h<N/3){ h=3*h+1; } // 在递增序列1,4,13,40...中选择小于数组长度的最大值,作为初始步长。 while (h>=1) { for (int i = h; i < N; i++) { for (int j = i; j >=h && a[j] < a[j - h]; j-=h) { exch(a, j, j - h); } } h = h/3; // 按照选定的递增序列逆向减少 } } }
希尔排序图示
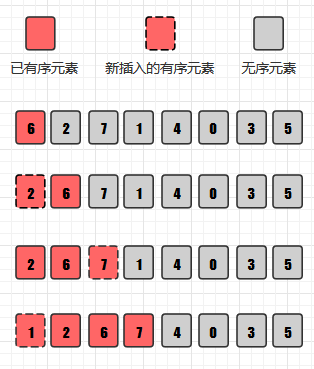
为了方便展示,下面展示的是选定递增序列为1...N/4,N/2的希尔排序的图示(初始步长为h =N/2= 5, 并按照 h = h / 2的趋势递减)
(颜色相同表示的是同一个分组)
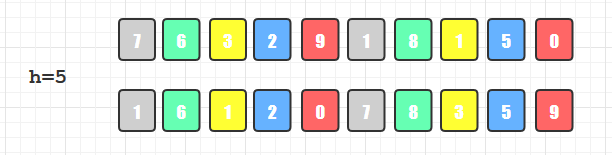
第一轮分组排序: h=5,所以将数组分为5组:7 1, 6 8, 3 1, 2 5, 9 0分别进行直接插入排序,得到
1 7, 6 8, 1 3, 2 5,9 0。 数组整体变为1 6 1 2 0 7 8 3 5 9
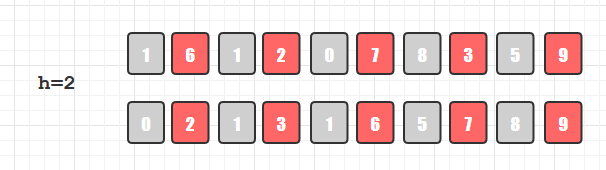
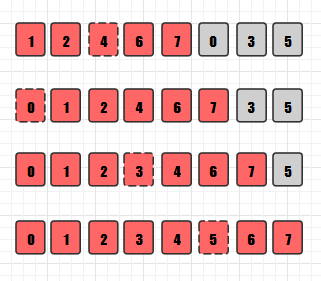
第二轮分组排序, h=2,所以将数组分为2组: 1 1 0 8 5, 6 2 7 3 9;经过分别的插入排序得到:
0 1 1 5 8, 2 3 6 7 9。数组整体变成 0 2 1 3 1 6 7 9。
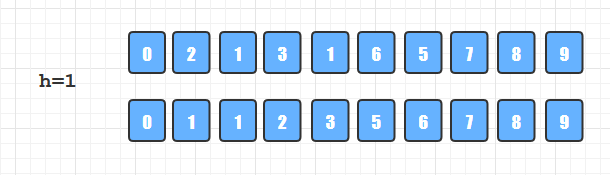
第三轮分组排序, h=1, 所以就是对整个数组进行直接插入排序了
希尔排序分析
人们设计希尔排序的思路可以简单描述为: “对症下药”, 因为插入排序擅长处理长度较短的, 部分有序(或有序)的数组, 那么就按这两点着手好了:
- 一开始的时候,每个子数组的长度短, 插入排序效率较高
- 每一轮分组排序后,数组有序性增强, 也提高了插入排序的效率。
关于第二点可以从希尔排序的柱状轨迹图看出(40-sorted表示此时 h =4)
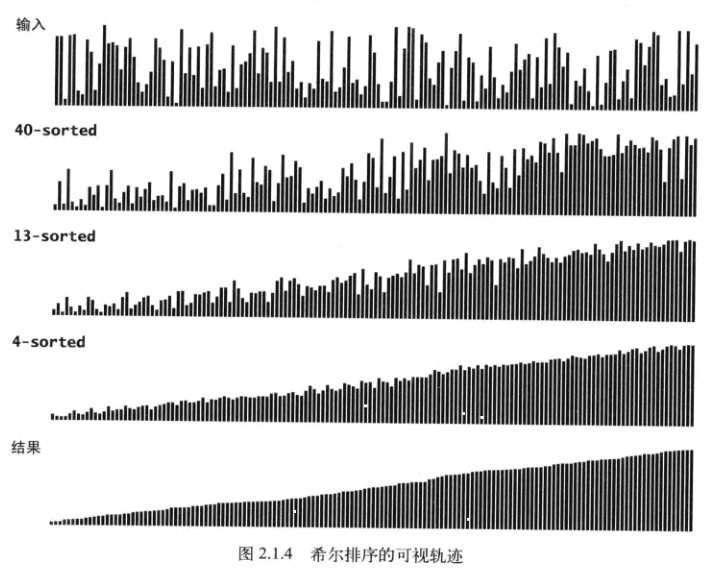
每一轮的分组排序, 有序性都逐渐增强, 到最后一轮直接插入排序之前,数组已经接近完全有序了,这时候插排的效率是比较高的。
跑下题,这里我再用一个比喻描述一下直接插入排序和希尔排序的关系:
奥特曼打小怪兽的时候,为什么不直接上来就用大招消灭(对整个数组直接插入排序),而是到最后一步才放光波呢? 理性一点可以这样看: 一开始的时候怪兽还是满血状态(无序的大规模数组), 这个时候放大招可能连怪兽都没打死自己能量就全耗光了(总体排序性能太差)。 所以要采用“分步打法”(步长递减插入排序),先用小招耗掉怪兽的血量(小型数组插排), 等怪兽防御力渐弱的时候(数组整体逐渐有序)才用祭出较强的大招(大型数组插排)和怪兽正面刚,到最后的时机到来的时候, 用光波灭掉血线已经降到斩杀阶段的小怪兽,并不需要消耗太多的体力。(h=1时候对整个数组直接插排)
为何希尔排序后一定有序?
因为h到最后一定会减少到1,到最后就是对整个数组的直接插入排序
时间复杂度
关于希尔排序的时间复杂度,它和我们选择的递增序列有关, 在数学上研究起来比较复杂 ,且尚无定论
目前最重要的结论是:它的运行时间不到平方级别,也即时间复杂度小于O(n^2), 例如我们上面选择的1,4 ,13,40,121递增序列的算法, 在最坏情况下比较次数和N^(3/2)成正比。

我叫彭湖湾,请叫我胖湾

 浙公网安备 33010602011771号
浙公网安备 33010602011771号