魔法代码 - 缓存对齐 C#版
代码
我们先看下面一段代码,非常的简单。
using System.Diagnostics;
namespace CacheConsistency
{
internal class Program
{
class Test
{
public long X { get; set; }
//public long x1, x2, x3, x4, x5, x6, x7;
}
static void Main(string[] args)
{
Stopwatch stopwatch = Stopwatch.StartNew();
stopwatch.Start();
long count = 100000000;
List<Test> list = new List<Test>();//业务数据项集合
for (int i = 0; i < 4; i++)
{
list.Add(new Test());
}
Parallel.ForEach(list, test =>
{
for (int i = 0; i < count; i++)
{
test.X = i;
}
Console.WriteLine(test.X);
});
stopwatch.Stop();
Console.WriteLine("耗时:" + stopwatch.ElapsedMilliseconds);
}
}
}
上面的代码中Main方法主要是定义一个Test实例集合,然后并行执行为集合的Test实例的属性X赋值这样一个过程。
运行这个控制台程序,多运行几次并记一下执行时间,我取我其中一次执行的结果如下图:
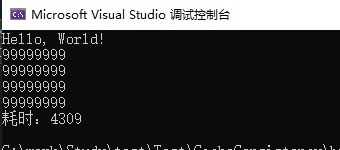
现在让我们施展“魔法”:取消public long x1, x2, x3, x4, x5, x6, x7;这行代码的注释。是的,我们仅仅是定义这些变量,没有修改其它任何地方的代码,现在我们执行看看会发生什么,我取其中一次的执行结果如下图:
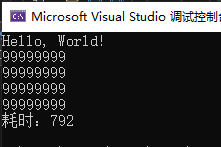
神奇的事情发生了——执行时间缩短了5倍,为什么?怎么做到的?
揭秘
- 缓存对齐
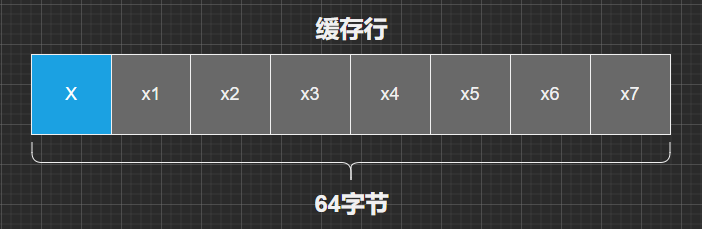
上面代码实现的效果就是因为缓存对齐,定义7个long类型的变量使得有被使用的变量X一起被放到同一缓存行,这样就避免变量X被缓存到不同的CPU内核。
在解释上面的原理之前,我们需要先了解一些概念:
-
内存的空间局部性
在一个具有良好空间局部性的程序中,如果一个内存位置被引用了一次,那么程序很可能在不远的未来引用附近的一个内存位置。
-
缓存行
计算机将数据从主存读入CPU高速缓存时,如果一个变量一个变量的同步效率比较低,而且根据内存的空间局部性原理:这个变量相邻的变量将来很可能也要被使用,所以CPU从主存读取数据时是读取一个数据块,这个数据块大小一般是64个字节。
-
CPU的缓存一致性同步
CPU的L1、L2缓存是每个CPU内核独享的,当从主存读取缓存行到不同的CPU内核时,如果读取的是相同的缓存行,当其中一个CPU的内核修改了缓存行的数据,就必须把修改的数据同步到另一个内核的缓存,从而保证数据的一致。
OK,以上的理论知识比较枯燥,我们结合代码来画一些图:
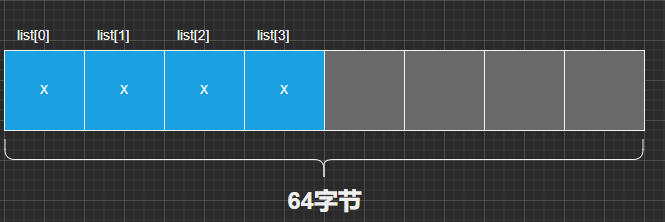
前后代码的缓存行对比
-
取消注释代码前
![]()
-
取消注释代码后
![]()
实际的应用场景

...

 浙公网安备 33010602011771号
浙公网安备 33010602011771号