
python与selenium自动化基础-定位元素
一、使用selenium的webdirver模块对浏览器进行操作
xpath路径表达式
通过节点名定位(http://www.ifeng.com/)
html 定位到html节点
html/head 定位到head节点
html/head/meta 定位好head中的所有meta节点
相对路径定位节点(http://www.ifeng.com/)
//title 使用相对路径定位到title节点
//meta 使用相对路径定位到所有meta节点
使用.和..定位本身和父节点(http://www.ifeng.com/)
/html/head/title/./.. 使用.定位到title本身再使用..定位到title的父节点
/html/head/title/./../body 使用.定位到title本身再使用..定位到title的父节点,然后在定位到body子节点
通过@定位 格式 标签名[@属性名='属性值']
/meta[@name='author'] 定位到所有的meta,再从中找到name=author的那一个
//div[@id] 定位到所有div标签,再过滤出有id属性的节点
通配符定位节点
//* 匹配所有节点
/* 匹配绝对路径最外层
//*[@*] 匹配所有有属性的节点
/html/node()/meta 匹配所有含有meta的节点
糗事百科练习xpath
//div[@id="content-left"]/div 定位到所有糗事帖子节点
//div[@id="content-left"]/div[1] 通过索引定位到第一个节点
//div[@id="content-left"]/div[last()] 通过last()索引定位到结果中的最后一个
//div[@id="content-left"]/div[last()-n] 通过last()-n索引定位到结果集中的倒数第n+1个
//div[@id="content-left"]/div[position()=n] 定位到结果集中第n个节点
//div[@id="content-left"]/div[position()<n] 定位到结果集中索引小于n的节点
//div[@id="content-left"]/div[position()>n] 定位到结果集中索引大于n的节点
//span[i=n] 定位到好笑计数等于n的节点
//span[i>n] 定位到好笑计数大于n的节点
//meta | //script | //link 使用多个xpath,所有xpath的结果都放到一个结果集中
//*[starts-with(@name,'rend')] 匹配以标签属性值以给定值开头的节点
//*[contains(@name,'end')] 匹配给定值在标签属性中的节点
//*[@content="noarchive" and @name="robots"]匹配同时符合两个属性值的节点
css选择器
.weixinBottom 通过class的值进行定位
#wx 通过id的值进行定位
div 通过标签进行定位
meta,link 匹配两种标签结果集
div a 匹配div标签中的所有后代a标签
div>a 匹配div后是一个a标签的节点
div+div 匹配div后面的同胞div节点
[id] 匹配所有含有id属性的标签
[id='wx'] 匹配所有含有id并且值为wx的标签
[type="submit"]
[class~="Login"] 定位标签属性class值中有独立Login的节点
[name|=msapplication] 定位标签属性name的值以msapplicatio开头的节点(该节点需为一个完整的单词)
[src^="http://"] 匹配scr属性以http://开头的节点
[src$="js"] 匹配src属性以js结尾的节点
[src*="ifengimg"] 匹配src属性中含有ifengimg的节点
img:only-child 匹配所有独生子女的img节点
body>div:nth-child(1) 匹配body的第n个div子节点
body>*:nth-last-child(1) 匹配body的最后一个子节点
:not(link) 查找不是link标签的节点
注意:需要安装浏览器版本对应的driver驱动
from selenium import webdriver b = webdriver.Firefox() b.get('https://www.baidu.com') #打开一个网页 print(b.title) # 打印title print(b.current_url) # 打印 url
二、webdriver模块对浏览器进行操作:元素的定位

元素定位方法的分类(按定位方式):
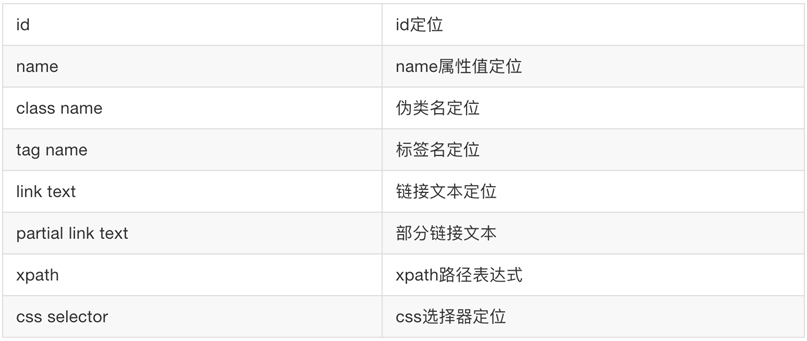
# 根据id获取元素 ele = b.find_element_by_id("kw") ele.clear() # 清除元素内容 ele.send_keys("麦子学院") # 模拟按键输入 b.back() #返回
# 根据name获取元素 ele = b.find_element_by_name("wd") ele.clear() ele.send_keys("麦子学院")
ele = b.find_element_by_class_name("s_ipt") ele = b.find_element_by_tag_name('input') #页面中有多个input,这样查找有问题;z只能找到第一个
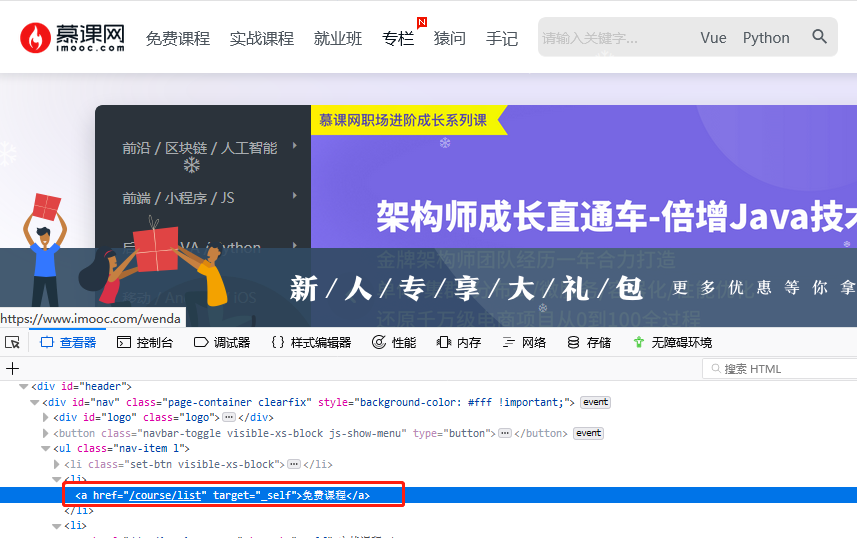
from selenium import webdriver b = webdriver.Firefox() b.get('https://www.imooc.com/') b.maximize_window() #最大化窗口 ele = b.find_element_by_link_text("免费课程") # ele = b.find_element_by_partial_link_text("免费") #模糊查询 ele.click() #点击
b.find_element_by_css_selector() #根据css路径获取元素
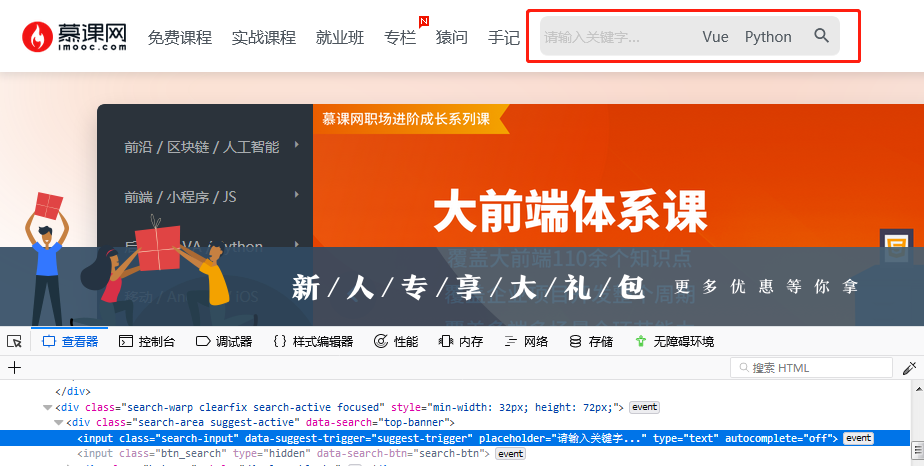
from selenium import webdriver b = webdriver.Firefox() b.get('https://www.imooc.com/') ele_css = b.find_element_by_css_selector('input[type="text"]') ele_css.clear() ele_css.send_keys("python")
xpath定位元素
xpath:通过路径表达式从XML文档中选取节点或者节点位置
/xxx 选取根节点xxx
/xxx/yyy 根据绝对路径选择元素
//xxx 整个文档扫描,找到所有xxx元素
. 选取当前节点的父元素节点
.. 选取父元素地址
//xxx[@id] 选取所有xxx元素中有id属性的元素
//xxx[@id=yyy] 选取所有xxx元素id属性为yyy的元素
b.find_element_by_xpath('/html/body/form/input') #form元素下的所有input b.find_element_by_xpath('/html/body/form/input[1]') #根据下标定位某一个input b.find_element_by_xpath('//*[count(input=2)]') #遍历找input标签值有2个的元素
//*[count(x)=2] 统计x元素个数=2的节点
//*[local-name()='x'] 找到tag为x的元素
//*[starts-with(local-name(),'x')] 找到所有tag以x开头的元素
//*[contains(local-name(),'x')] 找到所有tag包含x的元素
//*[string-length(local-name())=3] 找到所有tag长度为3的元素
//x|//y 多个路径查找
b.find_element_by_xpath('//*[count(input=2)]/..') #遍历找input标签值有2个的元素的父节点 b.find_element_by_xpath('//form//*[contains(local-name(),"i")][last()]') #form下包含i的节点的最后一个 b.find_element_by_xpath('//form//*[contains(local-name(),"i")][last()-1]')
通过节点名定位(http://www.ifeng.com/)
html 定位到html节点
html/head 定位到head节点
html/head/meta 定位好head中的所有meta节点
相对路径定位节点(http://www.ifeng.com/)
//title 使用相对路径定位到title节点
//meta 使用相对路径定位到所有meta节点
使用.和..定位本身和父节点(http://www.ifeng.com/)
/html/head/title/./.. 使用.定位到title本身再使用..定位到title的父节点
/html/head/title/./../body 使用.定位到title本身再使用..定位到title的父节点,然后在定位到body子节点
通过@定位 格式 标签名[@属性名='属性值']
/meta[@name='author'] 定位到所有的meta,再从中找到name=author的那一个
//div[@id] 定位到所有div标签,再过滤出有id属性的节点
通配符定位节点
//* 匹配所有节点
/* 匹配绝对路径最外层
//*[@*] 匹配所有有属性的节点
/html/node()/meta 匹配所有含有meta的节点
糗事百科练习xpath
//div[@id="content-left"]/div 定位到所有糗事帖子节点
//div[@id="content-left"]/div[1] 通过索引定位到第一个节点
//div[@id="content-left"]/div[last()] 通过last()索引定位到结果中的最后一个
//div[@id="content-left"]/div[last()-n] 通过last()-n索引定位到结果集中的倒数第n+1个
//div[@id="content-left"]/div[position()=n] 定位到结果集中第n个节点
//div[@id="content-left"]/div[position()<n] 定位到结果集中索引小于n的节点
//div[@id="content-left"]/div[position()>n] 定位到结果集中索引大于n的节点
//span[i=n] 定位到好笑计数等于n的节点
//span[i>n] 定位到好笑计数大于n的节点
//meta | //script | //link 使用多个xpath,所有xpath的结果都放到一个结果集中
//*[starts-with(@name,'rend')] 匹配以标签属性值以给定值开头的节点
//*[contains(@name,'end')] 匹配给定值在标签属性中的节点
//*[@content="noarchive" and @name="robots"]匹配同时符合两个属性值的节点
css选择器
.weixinBottom 通过class的值进行定位
#wx 通过id的值进行定位
div 通过标签进行定位
meta,link 匹配两种标签结果集
div a 匹配div标签中的所有后代a标签
div>a 匹配div后是一个a标签的节点
div+div 匹配div后面的同胞div节点
[id] 匹配所有含有id属性的标签
[id='wx'] 匹配所有含有id并且值为wx的标签
[type="submit"]
[class~="Login"] 定位标签属性class值中有独立Login的节点
[name|=msapplication] 定位标签属性name的值以msapplicatio开头的节点(该节点需为一个完整的单词)
[src^="http://"] 匹配scr属性以http://开头的节点
[src$="js"] 匹配src属性以js结尾的节点
[src*="ifengimg"] 匹配src属性中含有ifengimg的节点
img:only-child 匹配所有独生子女的img节点
body>div:nth-child(1) 匹配body的第n个div子节点
body>*:nth-last-child(1) 匹配body的最后一个子节点
:not(link) 查找不是link标签的节点

 浙公网安备 33010602011771号
浙公网安备 33010602011771号