数据预处理|1.Numpy and Pandas 回顾
NumPy和Pandas模块能够满足你对大多数数据分析和数据预处理任务的需求。在我们开始回顾这两个有价值的模块之前,我想让你知道,本章并不是要成为这些模块的全面教学指南,而是要收集一些概念、功能和例子,这些概念、功能和例子将是非常宝贵的,因为我们将在接下来的章节中讨论数据分析和数据预处理。
在本章中,我们将首先回顾Jupyter笔记本及其作为优秀编码用户界面(UI)的能力。接下来,我们将回顾NumPy和Pandas Python模块中最相关的数据分析资源。
本章将涵盖以下主题。
- Jupyter笔记本的概述
- 我们是否通过计算机编程来分析数据?
- NumPy的基本功能概述
- Pandas的概述

1 技术要求
开始使用Python编程的最简单方法是安装Anaconda Navigator。它是一个开放源码软件,汇集了许多对开发者有用的开放源码工具。你可以通过以下链接下载Anaconda Navigator:https://www.anaconda.com/products/individual。
我们将在本书中使用Jupyter Notebook。Jupyter Notebook是Anaconda Navigator提供的开源工具之一。Anaconda Navigator也会在你的电脑上安装一个Python版本。因此,在Anaconda Navigator的简单安装之后,你所需要做的就是打开Anaconda Navigator,然后选择Jupyter Notebook。
你可以在为本书专门创建的GitHub仓库中找到本书中使用的所有代码和数据集。要找到该仓库,请点击以下链接:
2 回顾Jupyter Notebook
Jupyter笔记本作为Python编程的一个成功的用户界面(UI)正变得越来越流行。作为一个用户界面,Jupyter笔记本提供了一个交互式的环境,在这里你可以运行你的Python代码,看到即时输出,并做笔记。
Jupyter笔记本的设计者Fernando Pérezthe和Brian Granger就他们在一个创新的编程用户界面中寻找的东西概述了以下原因。
- 个人探索性工作的空间
- 协作的空间
- 学习和教育的空间
如果你已经使用过Jupyter笔记本,你可以证明它实现了所有这些承诺,如果你还没有使用它,我有个好消息要告诉你:我们将在本书中全部使用Jupyter笔记本。我将分享的一些代码将以Jupyter笔记本用户界面的截图形式出现。
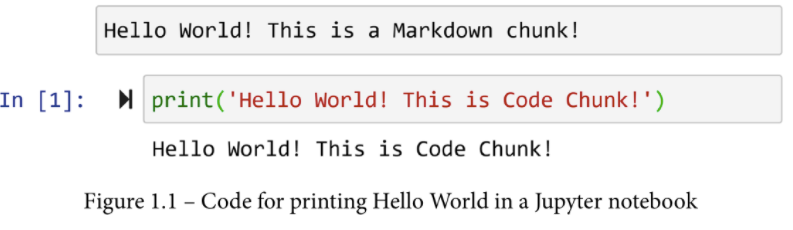
Jupyter笔记本的用户界面设计非常简单。你可以把它想象成一列材料。这些材料可以是代码块或Markdown块下的材料。解决方案的开发和实际编码发生在代码块下,而给你自己或其他开发者的笔记则呈现在Markdown块下。下面的截图显示了一个Markdown chunk和一个代码chunk的例子。你可以看到,代码块已经被执行了,所要求的打印也已经发生了,输出结果紧随代码块之后显示。
要创建一个新的块,你可以点击用户界面顶部缎带上的+号。默认情况下,新添加的块将是一个代码块。你可以通过使用顶部功能区的下拉列表,将代码块切换为Markdown块。此外,你还可以通过使用功能区上正确的箭头向上或向下移动这些块。你可以在下面的截图中看到这三个按钮。
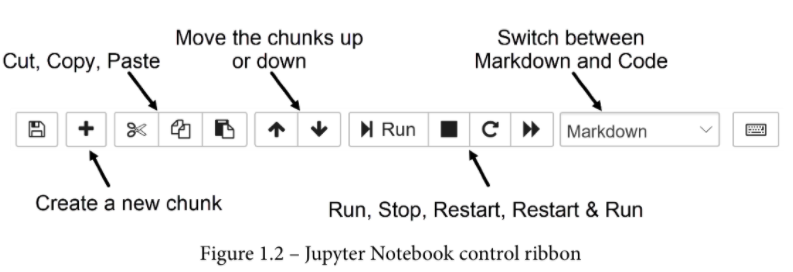
你可以在前面的截图中看到以下内容。- 截图中显示的功能区还允许你剪切、复制和粘贴数据块。 - 功能区上的 "运行 "按钮是用来执行一个块的代码的。
- 停止 "按钮是为了停止运行代码。如果你的代码已经运行了一段时间而没有输出,你通常会使用这个按钮。
- 重新启动 "按钮可以将石板擦拭干净;它删除了你所定义的所有变量,这样你就可以重新开始。
- 最后,"重启和运行 "按钮重新启动内核并运行Jupyter笔记本文件中的所有代码块。
Jupyter笔记本还有更多的内容,比如有用的短键来加快开发速度,以及特定的Markdown语法来格式化Markdown块下的文本。然而,这里的介绍只够你通过Jupyter笔记本用户界面开始有意义地使用Python分析数据。
3 我们是否通过计算机编程来分析数据?
为了从本章将要介绍的两个模块中获得最大利益,我们需要了解它们到底是什么,以及当我们使用它们时,我们到底在做什么。我相信不管是谁,包括我在内,都会告诉你,当你使用这些模块来操作你的数据时,你是在使用计算机编程来分析你的数据。然而,你所做的实际上不是计算机编程。计算机编程的部分已经完成了大部分。事实上,这已经由那些把这些宝贵的软件包放在一起的一流的程序员完成了。你所做的是使用他们的代码,作为这些模块下的编程对象和功能提供给你。好吧,如果我是完全诚实的,你正在做一点点计算机编程,但只是足以访问好东西(这些模块)。多亏了这些模块,你在使用计算机编程分析数据时不会遇到任何困难。
因此,在开始本章和本书的旅程之前,请记住这一点:在大多数情况下,我们作为数据分析师的工作是将三件事联系起来--我们的业务问题、我们的数据和技术。技术可以是商业软件,如Excel或Tableau,或者,在本书中,是这些模块。
4 NumPy的基本功能概述
简而言之,正如其名字所暗示的,NumPy 是一个充满了处理数字的有用函数的 Python 模块。NumPy名字的第一部分中的Num代表数字,Py代表Python。你有了它。如果你有数字,而且你在 Python 中,你知道你需要导入什么。这是正确的;你需要导入NumPy,就这么简单。
正如你所看到的,我们在导入模块后给了它一个别名np。实际上,你可以指定任何你想要的别名,你的代码也可以运行;但是,我建议坚持使用np。我有两个令人信服的理由这样做。
- 首先,其他人都使用这个别名,所以如果你与其他人分享你的代码,他们会知道你在整个项目中做什么。
- 第二,很多时候,你最终会在你的项目中使用别人写的代码,所以一致性会使你的工作更容易。你会看到大多数著名的模块也有一个著名的别名,例如,Pandas的pd,matplotlib.pyplot的plt。
良好的实践建议
NumPy可以处理所有类型的数字集合的数学和统计计算,如平均值、中位数、标准差(std)和方差(var)。如果你有其他的想法,但不确定NumPy是否有这个功能,我建议在尝试写你自己的东西之前先上网搜索一下。如果它涉及到数字,NumPy就有可能有。
# 1. 导包
import numpy as np
# 2.The np.arange() function
#这个函数,产生一个增量相等的数字序列。通过改变两个输入,你可以让这个函数输出许多不同的数字序列,这些都是你的分析目的所需要的。
np.arange(5) #array([0, 1, 2, 3, 4])
np.arange(1,5)#array([1, 2, 3, 4])
np.arange(-5.1,5)#array([-5.1, -4.1, -3.1, -2.1, -1.1, -0.1, 0.9, 1.9, 2.9, 3.9, 4.9])
# 3.np.zeros:创建一个充满0的NumPy数组
np.zeros([3,2])#np.zeros((3,2))
'''array([[0., 0.],
[0., 0.],
[0., 0.]])'''
# 4.np.ones:创建一个充满1的NumPy数组
np.ones(7)#array([1., 1., 1., 1., 1., 1., 1.])
np.ones((3,2))
'''array([[1., 1.],
[1., 1.],
[1., 1.]])'''
# 5.The np.linspace() function:返回指定区间内均匀分布的数字。前两个输入指定了区间,第三个输入显示了输出将有的元素的数量。(end-start)/ 步长 + 1 = numbers
np.linspace(0,10,11)#array([ 0., 1., 2., 3., 4., 5., 6., 7., 8., 9., 10.])
np.logspace(0,5,6,base=2)#array([ 1., 2., 4., 8., 16., 32.])
# 6.np.mean()与 .mean()
# type:list
lst_nums = [3,4,5,1,6]
np.mean(lst_nums)#3.8
# type:numpy.ndarray
ary_nums = np.array(lst_nums)
ary_nums.mean()#3.8
#np.mean():使用这种方法的好处是,在NumPy满足你的请求之前,你不需要在大多数时候改变你的数据类型。你可以输入列表、Pandas系列或DataFrames。
#.mean():它是任何NumPy数组的一个属性
如上代码块中第33-43行所示,有两种方法可以做到这一点。第一种,描绘在最上面的那块,使用np.mean()。这个函数是NumPy模块的属性之一,可以直接访问。使用这种方法的好处是,你不需要在NumPy满足你的请求之前改变你的数据类型。你可以输入列表、Pandas系列或DataFrames。你可以看到在最上面的一块,np.mean()很容易地计算出lst_nums的平均值,它是列表类型的。第二种方法,如下面这块所示,首先使用np.array()将列表转化为NumPy数组,然后使用.mean()函数,它是任何NumPy数组的一个属性。在继续推进本章内容之前,花点时间,使用Python type()函数看看lst_numbs和ry_nums的不同类型,如下面的截图所示。

4.1 np.arrange()函数
请注意第4-10行代码,看看np.range()在只传递一个或两个输入时的默认行为。
- 当只有一个输入时,如第一块代码,
np.range()的默认行为是你想要一个从0到输入数字的序列,增量为1。 - 当有两个输入时,如第二段代码,该函数的默认值是你想要一个从第一个输入到第二个输入的数字序列,增量为1。
4.2 np.zeros()和np. ones()函数
np. ones()创建一个充满1的NumPy数组,而np.zeros()对0做同样的事情。与np.arange()不同的是,np.zeros()和np. ones()是通过输入来计算输出数组中需要包含的内容。例如,下面的截图中最上面的一块指定了对一个四行五列充满零的数组的请求。正如你在下面这块看到的,如果你只传入一个数字,输出的数组就只有一个维度。

这两个函数是创建占位符以保持循环中的计算结果的优秀资源。例如,回顾下面的例子,观察这个函数是如何促进编码的。
例子 - 使用占位符来适应分析的需要
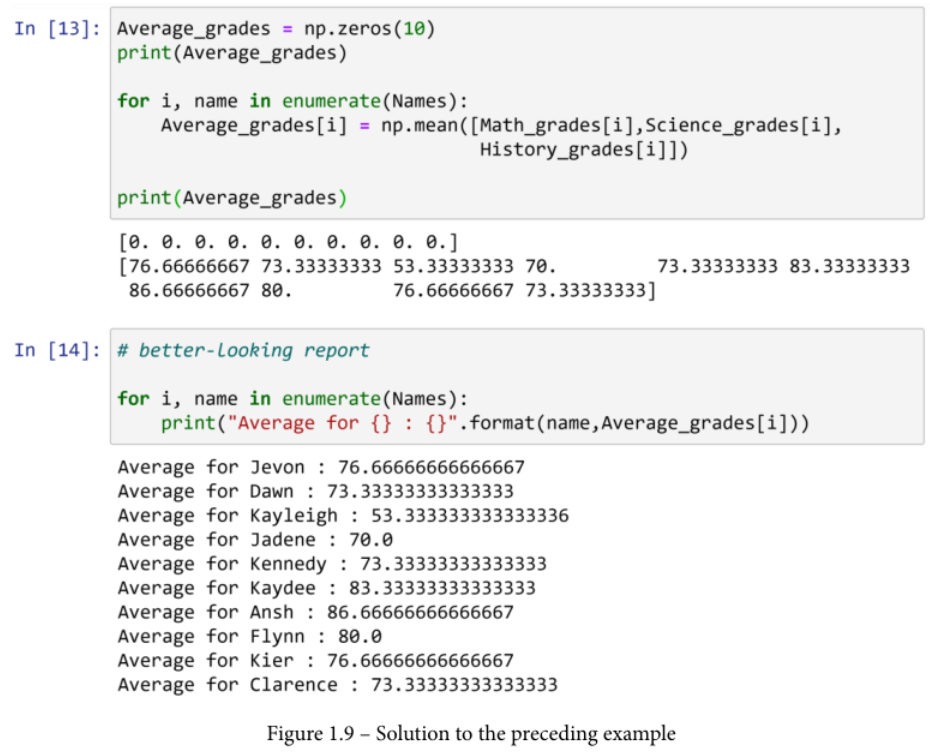
给出10个学生的成绩数据,用NumPy创建一个代码,计算并报告他们的平均成绩。
下面的截图中提供了10名学生的数据和这个例子的解决方案。在进展之前,请审阅并试用这段代码。

现在你已经有机会接触这个例子了,请允许我强调一下图1.9中提供的解决方案的几个事项:
- 注意
np.zeros()是如何通过大幅精简来促进解决方案的。代码完成后,所有的平均成绩都已计算并保存。比较for循环前后的打印值。 - for循环中的
enumerate()函数对你来说可能听起来很奇怪。它的作用是帮助代码同时拥有一个索引(i)和来自集合(Names)的项目(name)。 .format()函数是任何字符串变量的一个宝贵的属性。如果字符串中存在任何符号,如{},这个函数将用依次输入的内容替换它们。#更好看的报告是代码的第二块中的注释。注释是不被编译的,其唯一的目的是与阅读源代码的人交流一些东西
4.3 np.linspace()函数
这个函数在一个指定的间隔内返回均匀的数字。该函数需要三个输入。前两个输入指定区间,第三个输入显示输出的元素数。例如,请参考下面的屏幕截图。

在第一个代码块中,19个数字均匀地分布在0和1之间,总共创建了一个有21个数字的数组。第二个给出了另一个例子。在尝试了截图中的两个例子后,尝试一下np.linspace(0,1,20),在调查了结果后,想想为什么我的例子中选择了21而不是20。
np.linspace()是一个非常方便的函数,适用于需要尝试不同数值以找到最适合自己的数值的情况。下面的例子展示了这样一个简单的情况。
例子 - np.linspace()创建候选解决方案
我们有兴趣找到一个(几个)值,以保持以下数学语句:
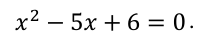
想象一下,我们不知道该语句可以很容易地被简化,以确定2或3可以成立该语句:
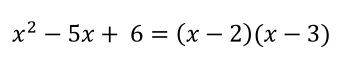
所以我们想用NumPy来尝试-1000和1000之间的任何整数,并找到答案。
下面的截图显示了为这个问题提供解决方案的Python代码。
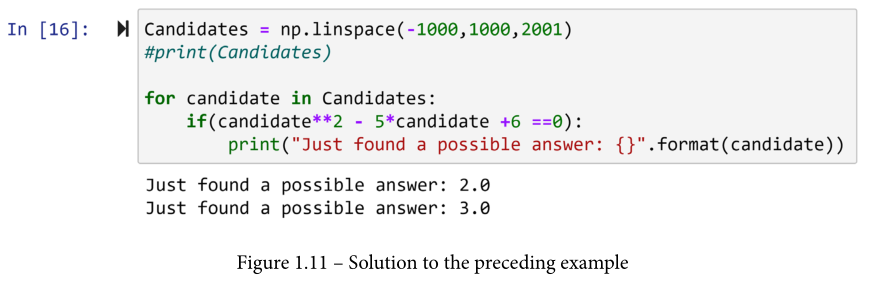
在继续前行之前,请回顾并尝试这段代码。
现在你已经有机会接触这个例子了,请允许我强调几件事情。
- 注意到
np.linspace()的巧妙使用导致一个包含所有我们感兴趣的数字的数组。 - 取消注释
#print(Candicates),并回顾所有试过的数字,以确定理想的答案。
我们对 NumPy 模块的回顾到此结束。接下来,我们将回顾另一个非常有用的Python模块,Pandas。
5 Pandas回顾
简而言之,Pandas是我们处理数据的主要模块。该模块充满了有用的功能和工具,但让我们先从基础开始。Pandas最伟大的工具是它的数据结构,也就是所谓的DataFrame。简而言之,DataFrame是一种二维数据结构,具有良好的界面和强大的可编性。
DataFrame一开始就对你有用。当你用Pandas读取一个数据源的时候,数据就会被重组并以DataFrame的形式显示给你。让我们试一试吧。
我们将使用著名的成人数据集(adult.csv)来练习和学习Pandas的不同功能。参考下面的截图,它显示了导入Pandas,然后读取和显示数据集的过程。在这段代码中,.head()要求只输出数据的前五行。.tail()代码可以对数据的底部五行做同样的处理。
.head()要求只输出前五行的数据。
.tail()代码可以对数据的底部五行做同样的处理。

成人数据集有六个连续属性和八个分类属性。由于打印的限制,我只能包括数据的某些部分;但是,如果你注意图1.12,输出结果在底部带有一个滚动条,你可以通过滚动来查看其余属性。试一试这段代码,研究一下它的属性。正如你所看到的,这个数据集中的所有属性都是不言自明的,除了fnlwgt。 标题是最终权重的简称,它是由人口普查局计算出来的,代表每一行所代表的人口比例。
良好的实践建议
始终了解你将要工作的数据集是一种良好的实践。
这个过程总是从确保你了解每个属性开始,就像我刚才做的那样。如果你刚刚收到一个数据集,而你不知道每个属性是什么,请问。相信我,你会看起来更像一个专家。
还有其他步骤可以了解数据集。我将在这里提到它们,你将在本章结束时学会如何操作它们。
第一步。按照我刚才的解释,了解每个属性。
第二步。检查数据集的形状。数据集有多少行和多少列?这个很容易。例如,只需尝试 adult_df.shape 并查看结果。
第三步。检查数据是否有任何缺失值。
第四步。计算数字属性的总结值,如平均数、中位数和标准差,并计算分类属性的所有可能值。
第五步。将属性可视化。对于数字属性,使用直方图或波谱图,对于分类属性,使用条形图。
正如你刚才所看到的,在你意识到之前,你正在享受Pandas DataFrame的好处。
因此,更好地理解DataFrame的结构是很重要的。简单地说,DataFrame是一个系列的集合。Series是另一种Pandas数据结构,它没有得到那么多的赞誉,但它同样有用,甚至更有用。
为了更好地理解这一点,试着调用成人数据集的一些列。每一列都是一个DataFrame的属性,所以要访问它,你所需要做的就是在DataFrame后面使用.ColumnName。例如,尝试运行adult_df.age来查看列age。试着运行所有的列并研究它们,如果你遇到某些列的错误,不要担心,如果你继续阅读,我们会很快解决这些问题。下面的截图显示了你如何确认刚才描述的成人数据集的情况。

它变得更加令人兴奋。不仅每个属性是一个Series,而且每行也是一个Series。要访问一个DataFrame的每一行,你需要在DataFrame后面使用.loc[]。大括号之间的内容是每一行的索引。回去研究一下图1.12中df_adult.head()的输出,你会发现每一行都由一个索引表示。索引不一定是数字的,我们将看到Pandas DataFrame的索引是如何调整的,但是当使用默认属性的pd.read_csv()读取数据时,数字的索引将被分配。所以,试一试,访问一些行并研究它们。例如,你可以通过运行 adult_ df.loc[1]访问第二行。在运行了一些之后,运行type(adult_df.loc[1])来确认每一行是一个系列。
当单独访问时,DataFrame的每一列或每一行都是一个系列。列系列和行系列的唯一区别是,列Series的索引是DataFrame的索引,而行Series的索引是列名。研究一下下面的截图,它比较了 adult_df 的第一行的索引和 adult_df 的第一列的索引。
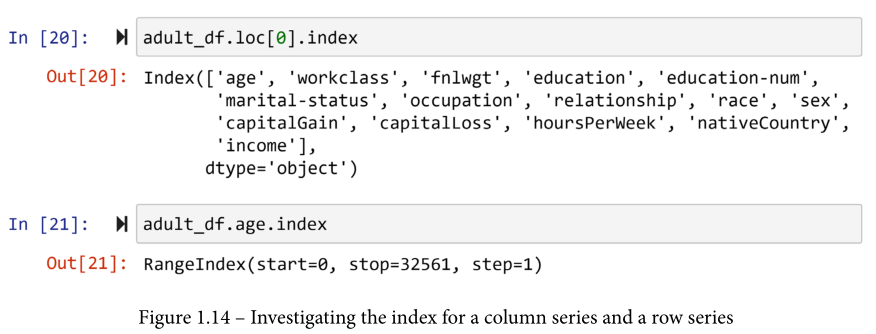
现在我们已经介绍了Pandas数据结构,接下来我们将介绍如何访问这些结构中呈现的值。
5.1 了解你将要工作的数据集
第一步。按照我刚才的解释,了解每个属性。
第二步。检查数据集的形状。数据集有多少行和多少列?这个很容易。例如,只需尝试 df.shape 并查看结果。
第三步。检查数据是否有任何缺失值。
第四步。计算数字属性的总结值,如平均数、中位数和标准差,并计算分类属性的所有可能值。
第五步。将属性可视化。对于数字属性,使用直方图或boxplot,对于分类属性,使用条形图。
5.2 Pandas 数据访问
Pandas Series和DataFrames的最大优势之一是它们为我们提供了很好的接入。让我们从DataFrames开始,然后我们将转向Series,因为这两者之间有很多共同点。
5.2.1 Pandas DataFrame 访问
由于DataFrames是二维的,本节首先讨论如何访问行,然后是列。本节的最后部分将讨论如何访问每个值。
DataFrame 访问行
你唯一需要访问DataFrame的行的两个关键字是.loc[]和.iloc[]。为了理解它们之间的区别,你需要知道每个Pandas系列或DataFrame携带两种类型的索引:默认索引或分配索引。默认索引是读取时自动分配给你的数据集的整数。然而,Pandas允许你更新它们。你可以使用的函数是.set_index()。例如,我们想确保adult_df中的所有索引都有五位数,所以我们希望索引在0到32651之间(运行len(adult_df)可以看到这是adult_df的行数),而不是从10000到42651。下面的截图使用了np.range()和.set_ index()来做这件事。在这段代码中,inplace=True向.set_index()函数表示,你想把变化应用到DataFrame本身。
为什么当inplace=True被纳入时,没有输出,而当它被纳入时,Jupyter Notebook显示更新的DataFrame?答案是.set_index()函数,默认情况下,输出一个新的DataFrame,该DataFrame具有请求的索引,除非指定inplace=True,要求将改变应用于原始DataFrame。
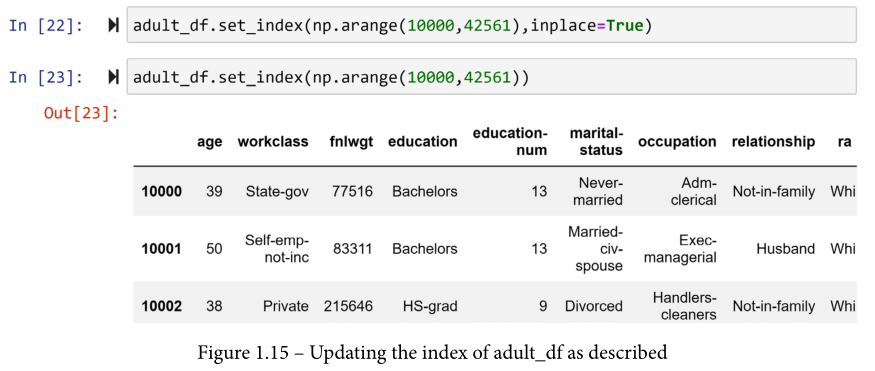
现在,可以通过在.loc[]的括号中指定索引来访问DataFrame的每一行。例如,运行 adult_df.loc[10001] 会给你第二行。这就是你使用分配的索引访问DataFrame的方式。如果你开始错过了默认的索引,就像你在预处理数据时经常做的那样,Pandas为你提供了帮助。
你可以使用.iloc[]来访问使用默认整数索引的数据。例如,运行 adult_df.iloc[1] 也会返回第二行。换句话说,Pandas会根据你的喜好改变索引,但在幕后,它也会保留它的整数默认索引,如果你愿意,也可以让你使用它。
DataFrame 访问列
由于有两种方法来访问每一行,也有两种方法来访问每一列。
访问列的更简单和更好的方法是知道每一列被编码为DataFrame的一个属性。所以,你可以通过使用.ColumnName来访问每一列。
例如,运行adult_df.age、adult_df.occupation,等等,看看以这种方式访问列是多么容易。
如果你碰巧运行了adult_df.education-number,你已经看到这给了你一个错误。如果你没有,请继续做,以研究这个错误。为什么会发生这个错误?
每一列都被编码为DataFrame的一个属性。你可以通过使用.ColumnName访问每一列.
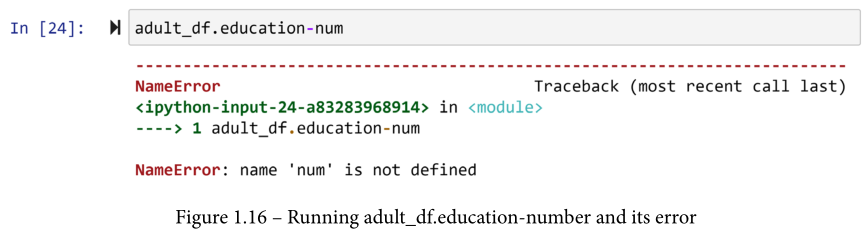
如果你研究一下错误信息,它提示说'num'没有被定义。这是真的;我们没有名为'num'的东西。这是使用这个错误来回答我的问题的关键。
Python 将破折号解读为减法运算符,除非出现在引号内。所以这一切都归结于此。由于这个变量的命名方式,你不能使用 .ColumnName 方法来访问这个变量。你要么需要改变变量的名称,要么使用第二个方法来访问这些列。
第二种方法将名称作为一个字符串传递,或者说,在一个引号内。试着运行 adult_df['education-num'] ,这次你将不会得到一个错误。
良好的实践建议
如果你是编程新手,我给你的建议之一是不要被错误吓倒,不仅如此,要张开双臂欢迎错误,因为它们是学习的绝佳机会。我只是用一个错误来教你一些东西。
DataFrame 访问值
想象一下,你想访问 adult_df 第三行的教育值。你有很多方法可以做到这一点。你可以从列开始,一旦你得到一个列序列,就可以访问这个值,或者你可以从行开始,一旦你得到一个行序列,就可以访问这个值。研究一下下面的截图;前三块代码显示了这样做的不同可能性。然而,我最喜欢的访问数值的方式是使用.at[],显示在最后一大块。
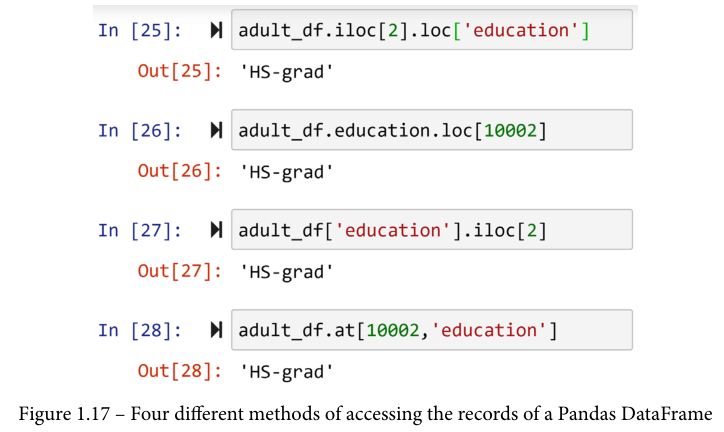
用.at[]访问值是我最喜欢的,原因有二。首先,它更整洁、更直接。第二,你可以把DataFrame当成一个矩阵,因为它就是一个矩阵,至少在视觉上是这样。
5.2.2 Pandas series 访问
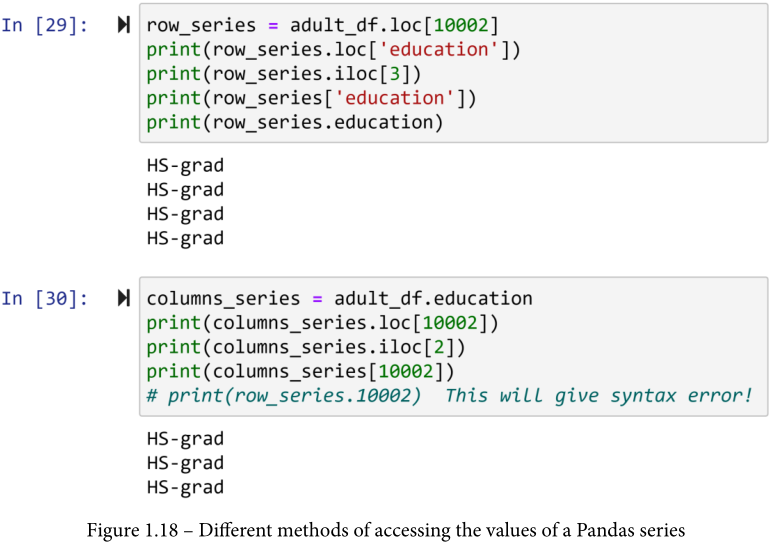
对系列值的访问与DataFrames非常相似,只是更简单。你可以使用所有提到的DataFrames的方法来访问系列的值,除了.at[]。你可以在下面的屏幕截图中看到所有的可能性。如果你尝试第二块代码的最后一行,Python 会产生一个语法错误,因为数字不能作为编程对象的名称。要使用这个方法,你必须确保系列索引是字符串类型的。
5.2.3 切片
切片同时适用于NumPy和Pandas;然而,由于这是一本关于数据预处理的书,我们将更多地在Pandas DataFrame中使用它。让我们从切分NumPy数组开始来理解切分,然后将其应用于Pandas DataFrame。
切分一个NumPy数组
当我们需要访问一个以上的数据值时,我们会对NumPy数组进行切片。例如,考虑下面截图中的代码。

在这里,my_array是一个4 x 4的矩阵,已经被以不同的方式切片了。第二块代码不是切分的;你可以看到,只有一个值被访问。区分正常访问和分片访问的是任何一个索引输入中的冒号(:)的存在。
例如,第三块代码中的冒号意味着你在请求所有的列,输出包括所有的列,但是由于只指定了第二行(索引1),所以输出的是第二行的全部内容。第四块代码正好相反;指定了一列,请求了整行,所以第二列的全部内容都被输出。
你也可以使用冒号(:)来指定从某一索引到另一索引的访问。例如,在下面代码的第二块中,虽然所有的列都被请求,但只有第二到第四行(1:3)被请求。第三块代码显示,列和行都可以同时被切分。最后,最后一大块代码显示,你可以传递一个你想包含在切片中的索引列表。

切分一个 Pandas DataFrame
就像NumPy数组一样,Pandas DataFrames也可以在列和行上进行切分。然而,切分功能只能在.loc[]或.iloc[]内进行。
访问方法,.at[],以及其他访问数据的方式不支持切分。
例如,下面的代码对adult_df进行切片,以显示所有的行,但只显示从教育到职业的列。运行 adult_df.iloc[:,3:6] 将导致相同的输出。
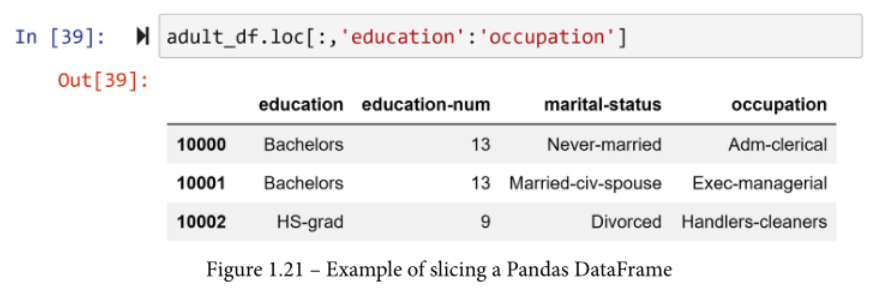
你想对Pandas数据框架的切分感到满意。这是一种非常有用的访问数据的方式。请看下面的例子,它展示了你可以使用切分的一种实际方式
切片的实际例子
运行 adult_df.sort_values('education-num')。你将会看到这段代码根据 education-num 列对 DataFrame 进行排序。在Jupyter笔记本的输出中,你只看到这个排序的前五行和最后五行。从整个DataFrame中对行进行切片输出,而不是仅仅从开头和结尾开始。
下面的截图显示了切分DataFrame是如何实现的。
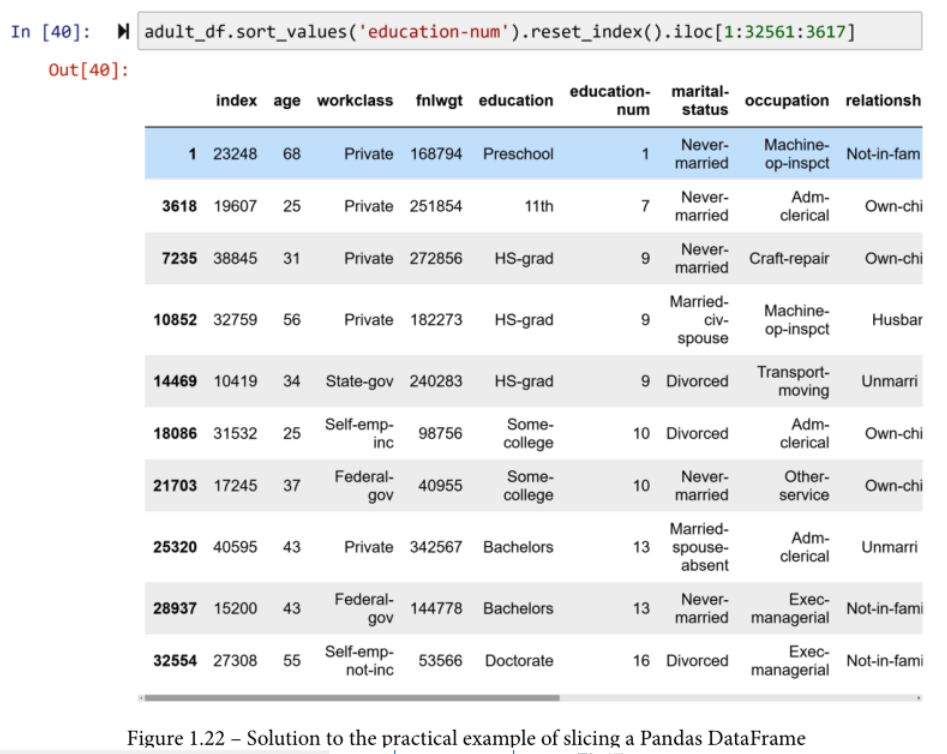
让我们一步一步地看一下这段代码。
- 第一部分,
.sort_values('education-num'),如前所述,按照education-num对DataFrame进行排序。我希望你在继续阅读之前已经试过了。请注意排序后的 adult_df 的索引。它们看起来杂乱无章,应该如此。原因是DataFrame现在是按另一列排序的。 - 如果我们想有一个新的索引来匹配这个新的顺序,我们可以使用
.reset_ index(),正如前面的截图中所使用的那样。来吧,也试一试。运行adult_df.sort_values('education-num').reset_ index()。你会看到,旧的索引作为一个新的列出现,新的索引看起来和任何新读的数据集一样有序。 - 添加
.iloc[1:32561:3617]可以实现这个例子的要求。这个特定的片断请求第一行和此后的第3617行,直到DataFrame的结束。数字32561是adult_df中的行数(运行len(adult_df)),3617是32561除以9的商。这个除法计算了从第一行到adult_df几乎结束的等量跳跃。请注意,如果32561除以9没有余数,代码将把你一直带到DataFrame的末端。
良好的实践建议
在了解数据集的初始阶段,能够以这种方式切分DataFrames是很有利的。使用编程而不是Excel等电子表格软件进行数据操作的一个缺点是,你不能像在Excel中那样滚动浏览数据。然而,以这种方式切分数据可以让你在某种程度上减轻这一缺点。
5.3 用于过滤数据框架的布尔掩码
处理数据的最简单但也是最强大的工具之一是布尔掩码。当你想用布尔掩码过滤一个DataFrame时,你需要一个布尔值(真或假)的一维集合,其布尔值的数量与你想过滤的DataFrame的行数相同。
下面的屏幕截图显示了一个布尔掩码的例子。
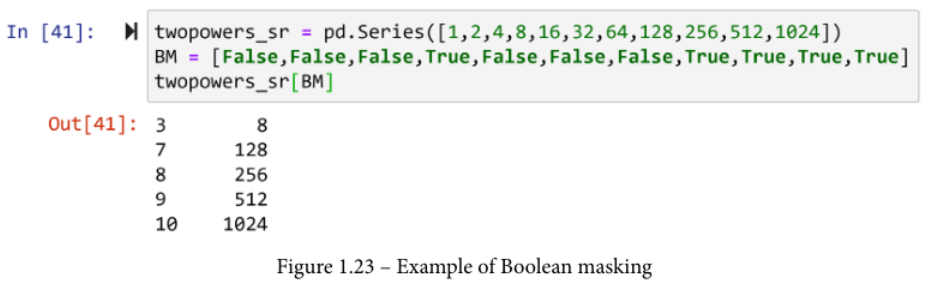
该代码以三个步骤描绘了布尔掩码。
- 代码首先创建了Pandas系列
twopowers_sr,其中包含2到0到10的幂的值(20,21,22,...,210)。 - 然后,设置一个布尔掩码。请注意,
twopowers_sr有11个数值,而BM也有11个布尔值。从现在起,在本书中,每当你看到BM,你可以放心地认为它代表布尔掩码。 - 最后一行代码使用掩码对序列进行过滤。
布尔掩码的工作方式是很直接的。如果布尔掩码(BM)中来自twopowers_sr的数值的对应值是假的,掩码就会阻止这个数字,如果是真,掩码就会让它通过。检查一下前面代码的输出是否是这样的情况。这在下图中显示。

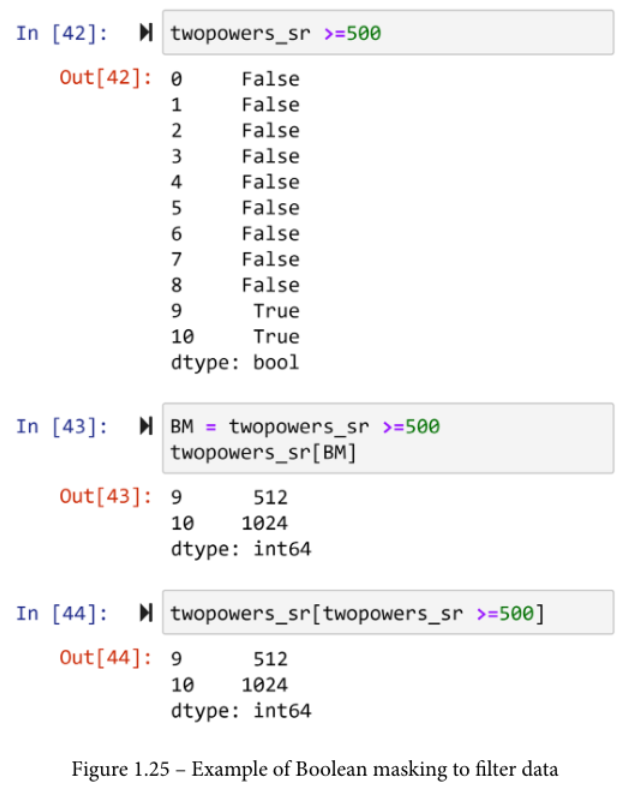
Pandas的伟大之处在于,你可以使用DataFrame或Series本身来创建有用的布尔掩码。你可以使用任何一个数学比较运算符来做到这一点。例如,下面的截图首先创建了一个布尔掩码,只包括大于或等于500的数字的真。然后,布尔掩码被应用于twopowers_sr,以两种方式过滤掉这些数字。
这两种方式都是合法的、正确的,而且都能发挥作用。在第一种方式中,你仍然给布尔掩码一个名字。如前所述,我们用BM这个名字来做。然后,我们用BM来应用布尔掩码。在第二种情况下,你在飞行中创建并使用布尔掩码,正如程序员所说的那样。这意味着你在一行代码中完成所有工作。 我更经常使用第一种,因为我相信它使代码更易读。
从前面的代码中你可能会问,如果我们可以用布尔掩码来过滤数据呢?这是个合理的问题。当你把布尔掩码用在DataFrames上进行分析时,它就发挥了作用。下面的两个例子将为你澄清这一点。
使用布尔掩码的分析实例1
我们对计算 adult_df 中受过学前教育的人的平均年龄和中位数感兴趣。
这可以用布尔掩码轻松完成。下面的截图首先使用 adult_df.education 系列创建 BM
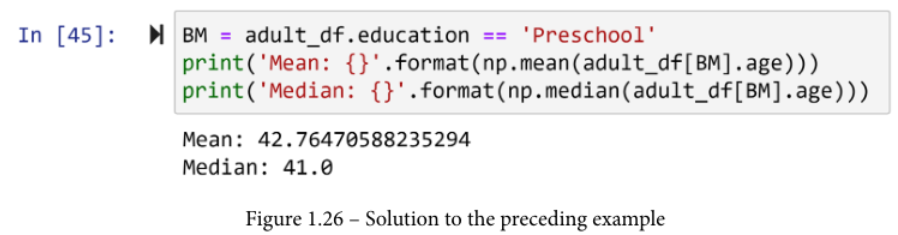
由于BM系列有和adult_df DataFrame一样多的元素(为什么?),所以可以应用BM来过滤它。一旦使用 adult_df[BM] 过滤了 DataFrame,它就只包含教育程度为 "学前 "的行。因此,现在你可以很容易地使用 np.mean() 和 np.median() 来计算这些被过滤的行的年龄的平均值和中位数。
使用布尔掩码的分析实例2
我们感兴趣的是比较受教育时间少于10年的个人与受教育时间超过10年的个人的资本收益。
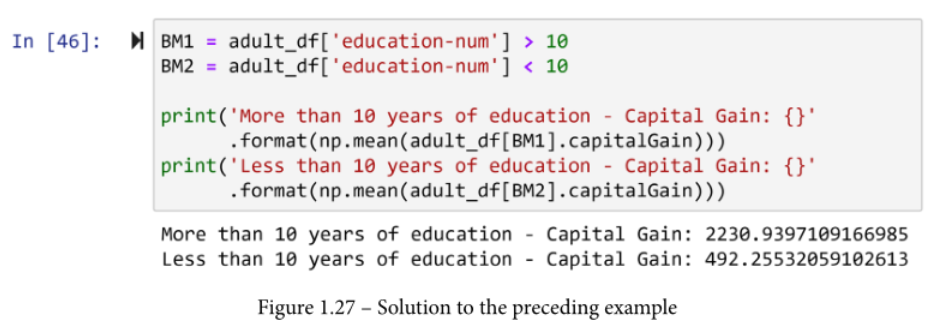
同样,布尔掩码在这里可以给我们很大的帮助。其中两个,BM1和BM2,首先根据我们感兴趣的计算内容来创建。然后,两个计算和报告显示了受过10年以上和10年以下教育的人的资本收益的平均值。
df.query()
from faker import Faker
import numpy as np
import pandas as pd
Faker.seed(0)
f = Faker(locale='zh_CN')
df_query_demo = pd.DataFrame(columns=['name','value_'])
df_query_demo.name = [f.name_male() for i in range(20)]
np.random.seed(0)
df_query_demo.value_ = np.random.randint(50,80,size=20)
df_query_demo.head()
'''
name value_
0 廖婷婷 62
1 刘凤兰 65
2 赵莉 71
3 黄红霞 50
4 陈帆 53
'''
BM = df_query_demo.name == '廖婷婷'
df_query_demo.loc[BM].head()
'''
name value_
0 廖婷婷 62
1 廖婷婷 65
2 廖婷婷 71
3 廖婷婷 50
4 廖婷婷 53
'''
df_query_demo.query("name == '廖婷婷'").head()
'''
name value_
0 廖婷婷 62
1 廖婷婷 65
2 廖婷婷 71
3 廖婷婷 50
4 廖婷婷 53
'''
BM = (df_query_demo.name == '廖婷婷') & (df_query_demo.value_ == 62)
df_query_demo.loc[BM].head()
'''
name value_
0 廖婷婷 62
17 廖婷婷 62
'''
df_query_demo.query("name == '廖婷婷' and value_ == 62").head()
'''
name value_
0 廖婷婷 62
17 廖婷婷 62
'''
5.4 用于探索DataFrame的Pandas函数
当你比较Excel等电子表格软件和编码时,编码的一个明显的缺点是,你不能像Excel那样与你的数据建立有形的关系。这是一个公平的比较,因为Excel可以让你上下滚动你的数据,所以允许你了解它。虽然编码并没有赋予你这种特权,但Pandas有一些有用的功能,可以帮助你熟悉数据。
熟悉一个数据集有两个方面。第一是了解数据的结构,如行数、列数和列名。第二是要了解每一列下的数值。因此,我们首先介绍了解数据集的结构,然后再重点介绍每一列下的值。
5.4.1 了解数据集的结构
你可以使用Pandas Dataframe的三个有用的属性来研究一个数据集的结构。它们是.shape, .columns, 和.info()。在下面的章节中,我们将逐一介绍它们。
.shape属性
.shape是任何Pandas DataFrame的属性。它告诉你这个DataFrame有多少行和多少列。因此,一旦你将其应用于adult_df,正如下面截图中的代码所执行的,你可以看到DataFrame有32,561行和15列。

.columns属性
.columns允许你查看和编辑你的DataFrame中的列名。在下面的代码中,你可以看到 adult_df.columns 导致 adult_df 的所有列名的输出。当然,你可以在读取数据集时滚动查看所有的列;但是,当数据有超过20列时,这是不可能的

此外,.columns可以用来更新列的名称。这在下面的截图中已经显示。运行以下代码后,你可以安全地使用 adult_df.education_num 来访问相关属性。我们只是将属性名称从'education-num'改为'education_num',现在可以使用.columnName方法访问该属性。参考图1.16,它显示了如果你要运行 adult_df.education-num,你会得到的错误。

.info()函数
这个函数提供了关于DataFrame的形状和列的信息。如果你运行adult_df.info(),你会看到其他信息,如非空值的数量,还有每一列下的数据类型将被报告出来
5.4.2 了解数据集的价值
Pandas用来了解数字列的功能与分类列的功能不同。数字列和分类列的区别在于,分类列没有用数字表示,或者更准确地说,没有携带数字信息。
为了了解数字列,.describe()、.plot.hist()和.plot.box()函数非常有用。另一方面,.unique()和.value_counts()函数对分类列很有帮助。我们将逐一介绍这些函数。
.describe()函数
这个函数输出许多有用的统计指标,旨在总结每一列的数据。这些指标包括计数、平均值、标准差(std)、最小值(min)、第一四分位数(25%)、第二四分位数(50%)或中位数、第三四分位数(75%)和最大值(max)。下面的截图显示了adult_df函数的执行情况和它的输出情况
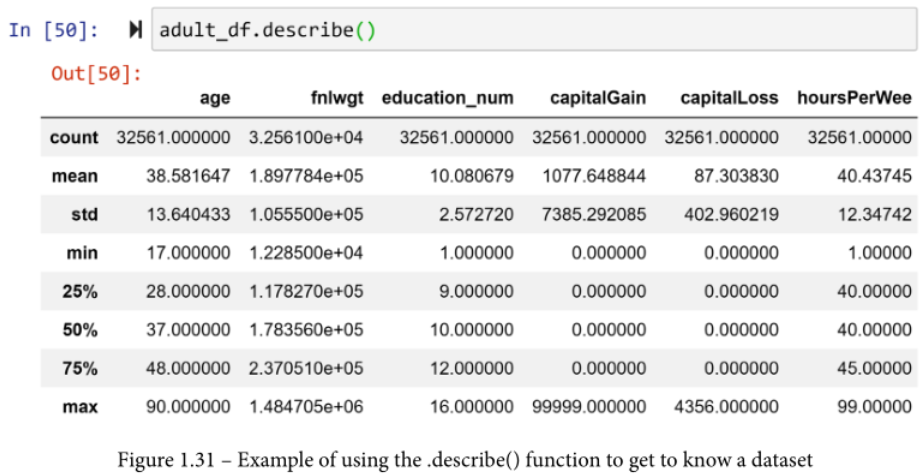
.describe()函数输出的指标是非常有价值的总结工具,特别是如果这些指标是为了用于算法分析。然而,一下子研究这些指标还是会让我们的人类理解力吃不消。为了总结数据以利于人类理解,还有更有效的工具,比如用直方图和boxplots将数据可视化。
直方图和boxplots,使数字列可视化
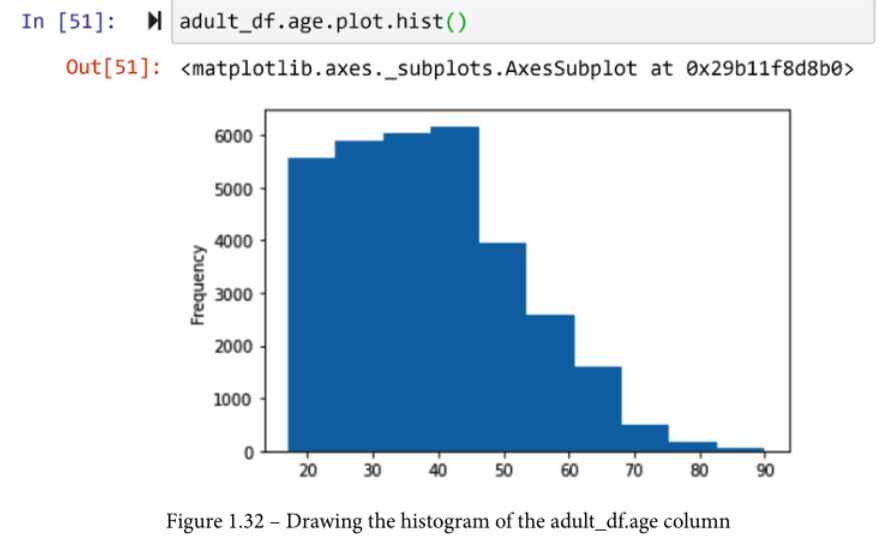
Pandas使得绘制这些视觉效果非常容易。每个潘达斯系列都有非常有用的绘图函数集合。例如,下面的截图显示了绘制年龄列的直方图是多么容易。要创建年龄列的boxplot,你只需要改变代码的最后一部分:adult_df.age.plot.box()。试一试吧。
另外,为所有其他数字属性绘制boxplot和直方图,自己看看用可视化的方式理解每一列有多容易。
每个Pandas series都有一个非常有用的绘图函数集合
.unique()函数
如果该列是分类的,我们了解它的方法将完全不同。
首先,我们需要查看该列的所有可能性。.unique()函数就是这样做的。它简单地返回列的所有可能的值。请看下面的截图,这是adult_df中关系列的所有可能值的一个例子。

The .value_counts() 函数
了解分类列的下一步是了解每种可能性的发生频率。.value_counts()函数正是这样做的。下面的截图显示了这个函数在列的关系上的结果。

.value_counts()函数的输出也被称为频率表。
还有一种相对频率表,它显示的是出现的比率,而不是每种可能性的出现次数。要得到相对频率表,你只需要指定你希望该表被规范化:.value_counts(normalize=True)。试一试吧!
用于可视化数字列的柱状图
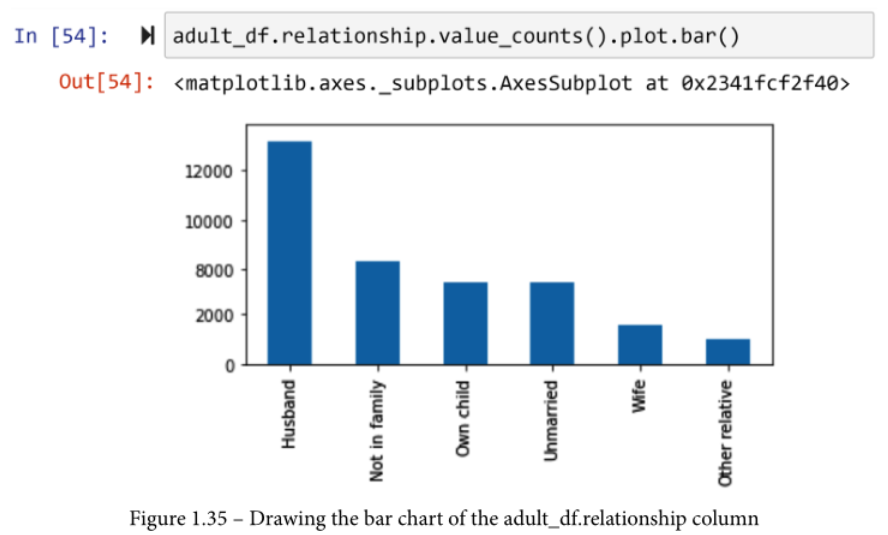
要画出分类属性的条形图,即使你可能想尝试像adult_df.relationship.plot.bar()这样的方法,也是行不通的。试一试吧,研究一下错误。
为了创建条形图,你必须首先创建频率表。由于频率表本身就是一个Pandas系列,你可以用它来绘制柱状图。下面的截图显示了我们如何使用函数.value_counts()和.plot.bar()为关系列绘制柱状图。
5.5 Pandas应用一个函数
在很多情况下,我们要对数据集中的每一行进行同样的计算。进行这种计算的传统方法是在数据中进行循环,在循环的每一次迭代中执行并保存计算结果。Python 和 Pandas 通过引入应用函数的概念改变了这种模式。
当你对一个 DataFrame 应用一个函数时,你要求 Pandas 为每一行运行它。
你可以将一个函数应用于一个系列或一个DataFrame。由于将函数应用到系列中比较容易,我们将首先学习这个,然后我们将继续将函数应用到DataFrame中。
将一个函数应用于一个系列
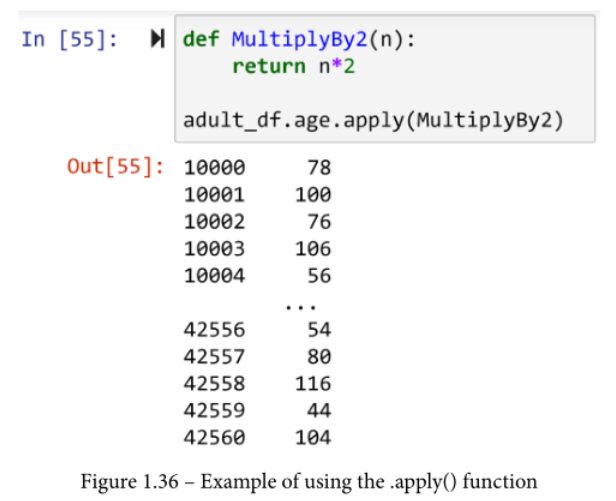
假设我们想把 adult_df.age 系列乘以 2。首先,你需要写一个函数,假设一个输入为数字,把输入乘以 2,然后输出结果。下面 的屏幕截图显示了这一点。首先,定义了MutiplyBy2()函数,然后,使用adult_df.age.apply(MutiplyBy2),应用于系列。
应用一个函数--分析性例子1
不仅adult_df.fnlwgt系列没有一个直观的名称,而且它的数值也不容易被联系起来。如前所述,这些数值是指每一行所代表的人口比例。由于这些数字既不是百分比,也不是每一行所代表的实际人数,因此这些数值既不直观,也不具有关联性。
现在我们知道如何对系列中的每个值进行计算,让我们用一个简单的计算来解决这个问题。我们用每个值除以系列中所有值的总和,怎么样?下面的截图显示了进行这一操作的步骤。
- 首先,计算
total_fnlwgt,也就是fnlwgt列中所有数值的总和。 - 第二,定义
CalculatePercentage函数。这个函数输出输入值除以total_fnlwgt,再乘以100(形成一个百分比)。 - 第三,
CalculatePercentage函数被应用于系列adult_df.fnlwgt。
现在,请注意! 下面的代码没有仅仅看到计算结果,而是将结果分配给 adult_df.fnlwgt 本身,它用新计算的百分比替换了原来的值。下面的代码没有显示代码的输出,但在你的Jupyter笔记本上试一下,自己研究一下输出。

应用Lambda函数
lambda函数是一个用一行表示的函数。所以,很多时候,应用lambda函数可能会使编码变得更容易,也许有时会帮助我们的代码变得更有可读性。例如,如果你想 "即时 "回答前面的计算,你可以简单地应用一个lambda函数而不是显式函数。请看下面的代码,比较一下使用lambda函数而不是显式函数的简单性和简洁性。

重要的是要明白,在lambda函数或显式函数之间的正确选择取决于情况。有时,不得不把一个也许很复杂的函数塞进一行,导致编码变得更加困难,并使代码的可读性降低。如果该函数有一个以上的条件语句,就会出现这种情况。
将一个函数应用于一个DataFrame
将函数应用于DataFrame和系列的主要区别在于你在定义函数的时候。对于一个系列,我们必须假设在函数中输入一个值,而对于一个DataFrame,我们必须假设将输入一个行系列。因此,当你定义一个应用于DataFrame的函数时,你可以参与任何你需要的列。
例如,下面的代码已经定义并应用了一个函数,从每一列的年龄中减去education_num。请注意三个方面。
- 首先,在定义
CalcLifeNoEd()函数时,输入行被假定为adult_df的行系列。换句话说,CalcLifeNoEd()函数只是为应用于adult_df或任何以年龄和eduction_num为列的DataFrame而定制。 - 第二,
.apply()函数直接出现在DataFrame本身之后,而不是任何列之后。比较一下将函数应用于DataFrame的代码和系列的代码。比较最后两个代码段和下面的代码段。 - 第三,包含
axis=1是必要的,这意味着你要将函数应用于每一行而不是每一列。你也可以将一个函数应用于每一列。对于分析来说,这几乎从未发生过,但如果你需要的话,你必须把它改为axis=0。
我没有包括这个执行代码的输出。请试一试这段代码并研究其输出。

这也可以用lambda函数轻松完成。你需要运行的代码如下。试一试吧。
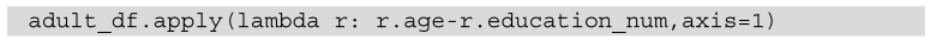
应用一个函数--分析性例子2
就你的财务成功而言,哪一个更重要:教育或生活经验?为了回答这个问题,我们可以使用adult_df作为一个样本数据集,从1966年的人口中提取一些洞察力。以下截图中的代码首先在数据中创建了两个新的列。
- lifeNoEd:你没有受过正规教育的年数
- capitalNet。从资本收益中减去资本损失。
为了回答这个问题,我们可以检查 education_num 和 lifeNoEd 中的哪一个与 capitalNet 的相关性更高。使用Pandas很容易做到这一点,因为每个Pandas DataFrame都有一个函数.corr(),可以计算DataFrame中所有数字属性组合的Pearson相关系数。由于我们只对education_num、lifeNoEd和capitalNet之间的相关性感兴趣,代码的最后一行在运行.corr()函数之前已经删除了其他列。

从输出结果中,你可以看到,虽然LifeNoEd和capitalNet之间的相关性为0.051490,但education_num和capitalNet之间的相关性更高,为0.117891。因此,我们有一些证据表明,在财务成功方面,教育比单纯的生活经验具有更有效的作用。
现在你已经学会了如何有效地应用一个函数进行分析,我们可以继续学习Pandas中另一个非常强大和有用的函数,它对于数据分析和预处理是非常有价值的。
5.6 Pandas的groupby函数
这是Pandas中最有用的分析和预处理工具之一。正如Groupby这个名字所暗示的那样,它将你的数据按某种东西分组。通常情况下,你会希望通过分类属性来分组你的数据。
如果你熟悉SQL查询,Pandas groupby几乎与SQL groupby相同。
对于SQL查询和Pandas查询,将你的数据分组本身不会有任何附加价值或任何输出,除非它伴随着一个聚合函数。
例如,如果你想计算每个婚姻状况类别的行数,你可以使用Groupby函数。请看并尝试以下代码。

你可以根据需要对DataFrame进行多列分组。要做到这一点,你必须以列名列表的形式介绍你要对DataFrame进行分组的那些列。例如,下面的代码是根据婚姻状况和性别两列对数据进行分组。

请注意,这两列是作为一个字符串值的列表被引入函数的。
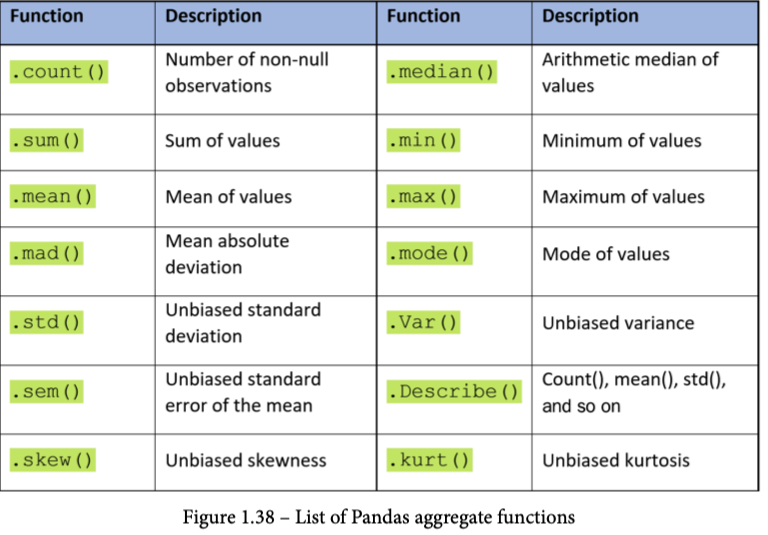
唯一不需要指定感兴趣的列的聚合函数是.size(),如上所示。然而,一旦你指定了你想要聚合数据的感兴趣的列,你就可以使用任何你可以在Pandas系列或DataFrame上使用的聚合函数。下表显示了你可以使用的所有聚合函数的列表。
例如,下面显示了按婚姻状况和性别对adult_df进行分组的代码,并计算出每组的中位数。

当你研究这个代码及其输出时,你可以开始欣赏.groupby()函数的分析价值。接下来,我们将看一个例子,它将帮助你进一步了解这个宝贵的函数。
使用Groupby进行分析的例子
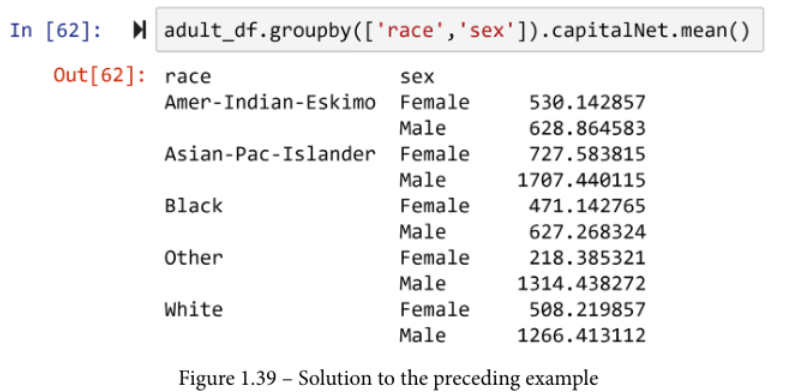
1966年个人的种族和性别对他们的财务成功有影响吗?顺便说一下,adult_df是在1966年收集的,所以我们可以用它来对这个问题提供一些见解。你可以采取不同的方法来解决这个问题。如下图所示,一种方法是按种族和性别对数据进行分组,然后计算各组资本网的平均值并研究其差异。
另一种方法是根据种族、性别和收入对数据进行分组,然后计算fnlwgt的平均值。 试一试这个方法,看看你是否会得出不同的结论。
Count与Size的区别
df_groupby_demo.groupby('A')['D'].count()
'''
A
one 3
three 2
two 4
Name: D, dtype: int64
'''
.count() 与 .size() 的区别:.count()聚合不包含空值。.size()聚合包含空值。
mode函数
df_groupby_demo.groupby('A').D.mode()
'''
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
/Users/peanut123/Documents/IT/datascience/numpy.ipynb Cell 67 in <cell line: 1>()
----> 1 df_groupby_demo.groupby('A').D.mode()
File ~/opt/miniconda3/envs/datascience/lib/python3.10/site-packages/pandas/core/groupby/groupby.py:904, in GroupBy.__getattr__(self, attr)
901 if attr in self.obj:
902 return self[attr]
--> 904 raise AttributeError(
905 f"'{type(self).__name__}' object has no attribute '{attr}'"
906 )
AttributeError: 'SeriesGroupBy' object has no attribute 'mode'
'''
df_groupby_demo.groupby('A').D.agg(pd.Series.mode)
'''
The mode points value for one are 7,8,10. #众数
The mode points values for three are 3,7.
The mode points value for two is 2,4,5,7.
A
one [7, 8, 10]
three [3, 7]
two [2, 4, 5, 7]
Name: D, dtype: object
'''
平均平均差(MAD)是用来测量观测数据与其平均值之间的平均距离。MAD 使用数据的原始单位,这简化了解释。较大的值表示数据点远离平均值。相反,较低的值对应于聚集在它附近的数据点。平均平均差也称为平均偏差和平均平均差。(https://statisticsbyjim.com/basics/mean-absolute-deviation/)

5.7 Pandas的多级索引
首先让我们了解一下什么是多级索引。如果你看一下按多列分组的DataFrame的输出,输出的索引看起来与正常情况不同。虽然输出是一个Pandas系列,但它看起来是不同的。造成这种不同的原因是多级索引。下面的截图向你展示了前面截图的.groupby()输出的索引。你可以看到,该系列的索引有两个层次,具体来说,就是种族和性别。

现在,让我们学习几个有用的相关函数,它们可以帮助我们进行数据分析和预处理。这些函数是.stack()和.unstack()。
.unstack()函数
这个函数将多级索引的外层推送到列中。如果多级索引只有两级,在运行.unstack()之后,它将变成单级。同样,如果对一个具有多级索引的系列运行.unstack()函数,输出将是一个DataFrame,其列是被推送的外级索引。例如,下面的截图展示了执行.unstack()函数时输出的外观和结构的变化。
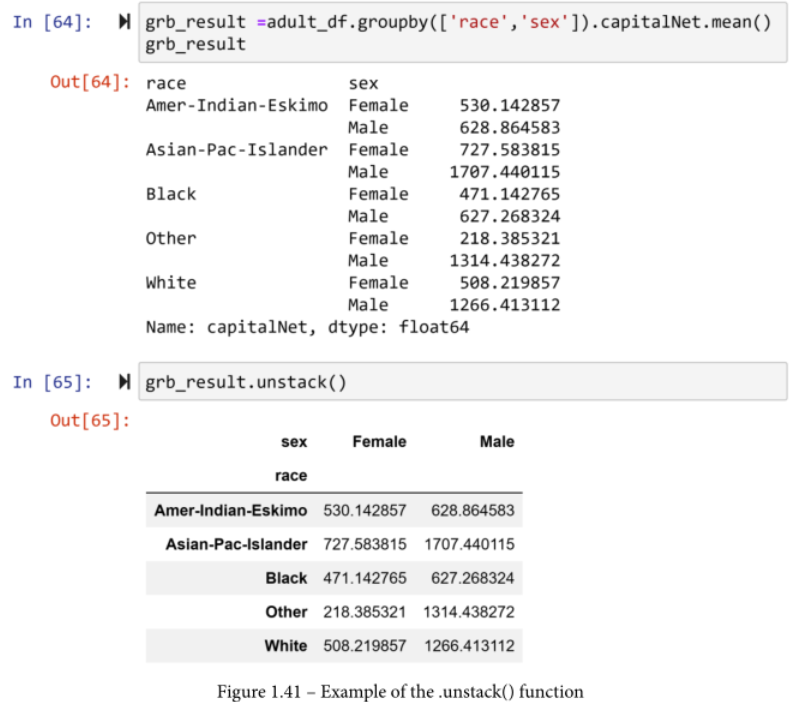
如果有两层以上的索引,多次执行.unstack()会逐一将外层的索引推到列中。例如,你可以在下面的截图中看到,第一块代码的结果是grb_result,它是一个具有三层索引的系列。第二块代码执行了一次.unstack(),grb_result中的外层索引,即收入,被推送到列中。然而,第三段代码执行了两次.unstack(),grb_result中索引的第二层,也就是性别,加入到列中的收入。
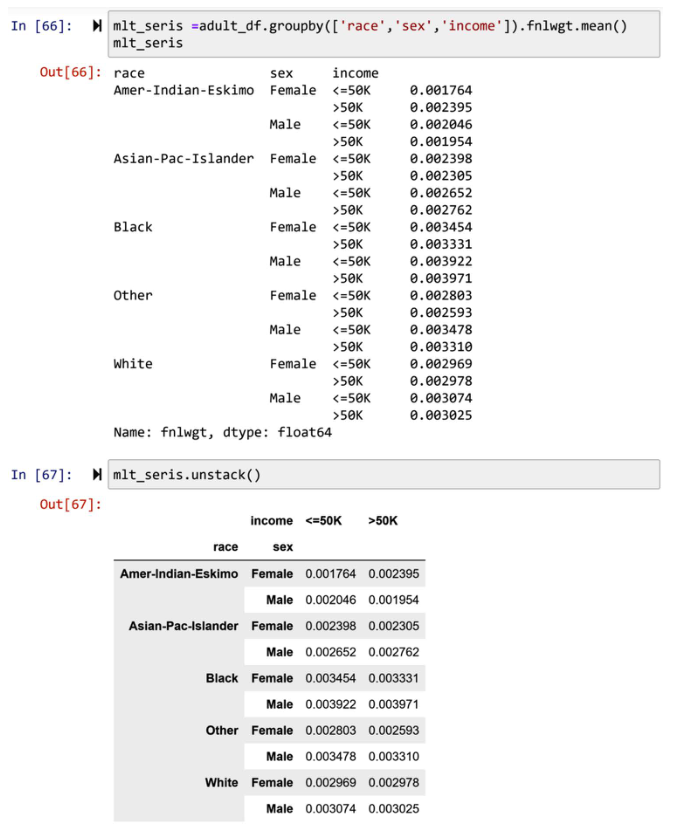

由于Pandas中的索引可以是多级的,所以列也可以有多级。例如,在下面截图的第一块中,你可以看到输出的DataFrame有两个层次。第二块代码输出了DataFrame的列。你可以看到,这些列有两个级别,是用.unstack()从索引中推送的。
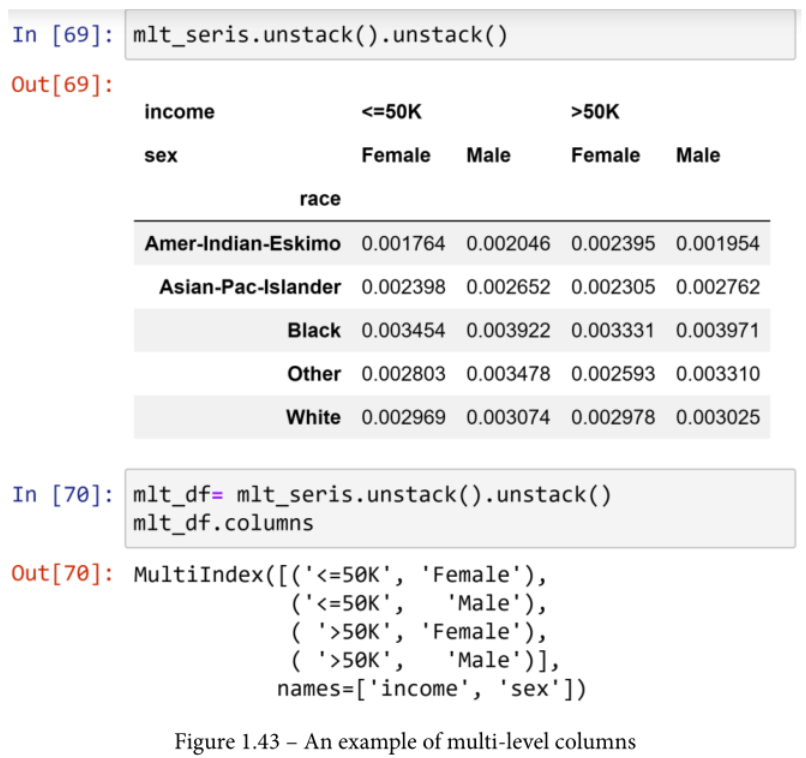
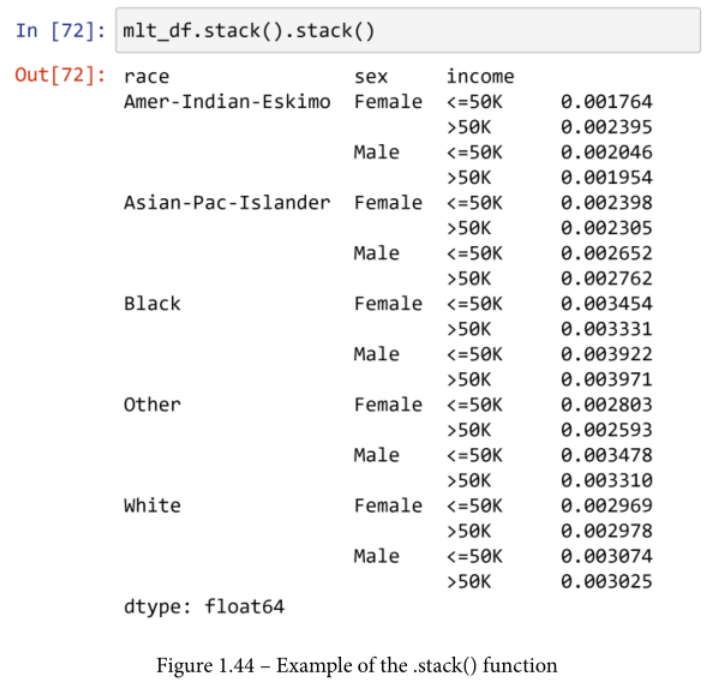
The.stack() 函数
与.unstack()相反的是.stack(),在这里,列的外层被推送,作为索引的外层加入。例如,在下面的截图中,你可以看到mlt_df,我们看到它有两个级别的列,已经经历了两次.stack()。第一个.stack()函数将收入级别推到索引中,第二个.stack()函数将性别级别推到索引中。这使得数据被呈现为一个系列,因为只有一列数据。

多层次访问
在系列或具有多级索引的DataFrames中,或具有多级列的DataFrames中,值的访问略有不同。本章末尾的练习2就是为了帮助你学习。
在本小节中,我们收集了相当多的关于多级索引和列的内容。
现在我们将进入另一组函数,它们与.stack()和.unstack()函数有些相似,但同时又有所不同。这些函数是.pivot()和.melt()。
from faker import Faker
from datetime import date, datetime
import pandas as pd
import numpy as np
Faker.seed(0)
np.random.seed(0)
f = Faker(locale='zh_CN')
multi_index_demo = pd.DataFrame(columns=['date','city','gender','money'])
multi_index_demo.date = [f.date_time_between(datetime(2021,9,1),datetime(2022,8,31)).strftime('%Y年%m月') for i in range(200)]
multi_index_demo.city = [f.city_name() for i in range(200)]
gender_lst = ['男','女']
multi_index_demo.gender = [gender_lst[i] for i in np.random.randint(0,2,size=200)]
multi_index_demo.money = np.random.randint(500,1000,size=200)*10
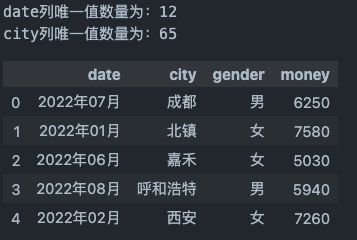
print('date列唯一值数量为:{}\ncity列唯一值数量为:{}'.format(multi_index_demo.date.nunique(),multi_index_demo.city.nunique()))
multi_index_demo.head()
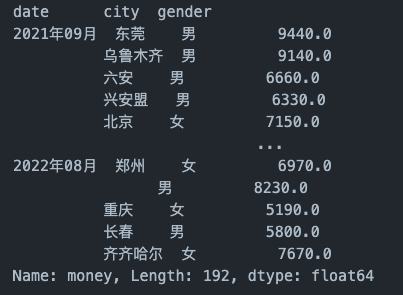
df_groupby_city = multi_index_demo.groupby(['date','city','gender'])['money'].mean()
df_groupby_city
df_groupby_city.loc['2021年09月']
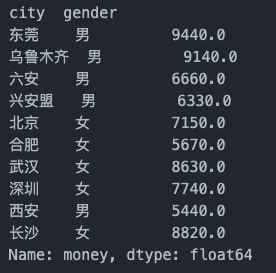
df_groupby_city.loc['2021年09月']['东莞']
'''
gender
男 9440.0
Name: money, dtype: float64
'''
df_groupby_city.loc['2021年09月']['东莞']['男']
# 9440.0
df_groupby_city.iloc[0]
# 9440.0
set_index设置多级索引
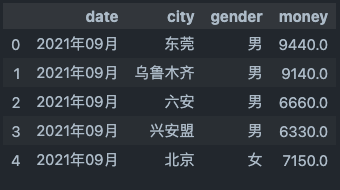
df_set_index = multi_index_demo.groupby(['date','city','gender'],as_index=False)['money'].mean()
df_set_index.head()
df_set_index.set_index(['date','city','gender'],inplace=True)
df_set_index.head()
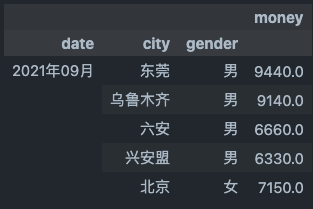
groupby与unstack()
df_unstack = df_groupby_city.loc['2021年09月'].unstack()
type(df_unstack) #pandas.core.frame.DataFrame
df_unstack.head()
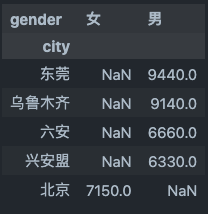
5.8 Pandas pivot and melt 函数
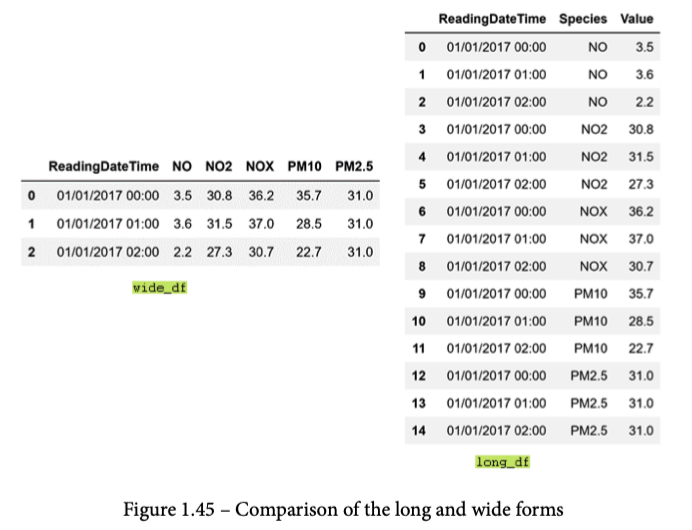
简而言之,.pivot()和.melt()帮助你在两种形式的二维数据结构之间切换:宽形式和长形式。下图描述了这两种形式之间的区别。如果你是一个电子表格用户,你通常会习惯于宽形式。宽形式使用许多列来引入数据集的新维度。然而,长形式使用不同的数据结构逻辑,使用一个索引列来包括所有相关的维度。.melt()函数,根据melt这个词的含义,你可能会在脑海中想象出它的样子,它可以很容易地将数据集从宽形式重塑为长形式。.pivot()函数则可以做相反的事情。
为了练习和学习这两个函数,我们将使用Pandas把wide.csv读成wide_df,并使用Pandas把long.csv读成long_df。
要在长格式和宽格式之间切换,你所需要做的就是向这些函数提供正确的输入。下面的截图显示了.melt()在wide_df上的应用,将其重塑为长格式。在第二块代码中,你可以看到,.melt()需要四个输入。
- id_vars。这个输入需要识别列。
- value_vars。此处输入的是持有数值的列。
- var_name: 这个输入是你想给识别列的名字,它将被添加到长格式中。
- value_name: 此处输入的是你想给将添加到长格式中的新值列的名称。
下面的截图显示了一个使用.melt()函数将数据从宽格式转换为长格式的例子。

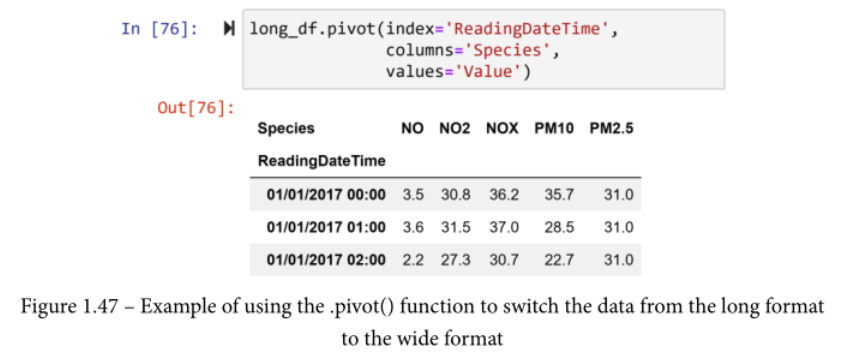
.pivot()函数将一个DataFrame从长形式重塑为宽形式。例如,下面的截图显示了该函数在long_df上的应用。
与需要四个输入的.melt()不同,.pivot()需要三个输入。
- index。这个输入将是宽表的索引。
- columns。这个输入需要长表的列,这些列将被扩展以创建宽表的列。
- values。此处输入的是长形表格中保存数值的列。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号