Flink
这些都是用来大数据处理的
spark是一个计算框架,在现有数据的基础上提供一个高性能的计算引擎,然后提供一些上层的处理工具比如做数据查询的Spark SQL、做机器学习的MLlib等 spark依赖于第三方的数据源,够配合HBase、Hive,以及关系型数据库Oracle、Mysql等多种类型的数据工作。 spark可以弥补hadoop的性能不足
storm实时性高,但是吞吐量有限
hadoop包括了数据存储(HDFS)、任务计划和集群资源管理(YARN)以及离线并行计算(MapReduce)的一整套技术栈。
hive的出现是因为java语言比较费劲,不是所有人都会java,因此需要把java语言改成sql,hive就干了这个活,hive不是数据库,而是数据仓库,依赖于hadoop来实现 hive的底层文件系统是hadoop的hdfs,实现对hdfs上结构化数据的SQL操作HQL,速度较慢 计算引擎是hadoop的mapreduce 不具备数据库的一些主键、索引、update操作等特性,但是提供了分区、块索引、SQL等特性 适合存储海量的全量(历史+更新)轨迹数据,比对数据进行批量的挖掘、分析等操作
hbase:全称是Hadoop databse,是一个hadoop的数据库 nosql数据库之一,弥补了hadoop只能处理SQL,而不能处理NoSQL的短板 基于分布式列式存储,适合海量半结构化带时间序列的数据的存储和检索,性能较优秀,hbase底层存储依赖于hdfs,与rdbms的区别与其他nosql类似,比如不支持SQL、事务性相对较差等等。 MapReduce(分布式计算框架,包括map切割和reduce汇合)、YARN(分布式计算框架)、HDFS(分布式存储系统)
但是MapReduce的缺点是计算速度慢,适合中低速数据处理的要求。
为解决MapReduce的缺点,让计算速度变快,发明了流计算streaming,如Storm.Storm是最流行的流计算平台。 它可以实时更新的原因是在数据流进来的时候就处理了
对于Kafka,一条消息来了以后,他是怎么选择不同的通道A、B、C?---------------这是个问题
flink一统流计算和批量计算的修炼
最基本的知识:
数据集分类:
-
无穷数据集:
-
有界数据集:
数据运算模型
-
流式:只要数据一直在产生,计算就持续地进行
-
批处理:在预先定义的时间内运行计算,当完成时释放计算机资源
flink过程
-
部署:Flink 支持本地运行、能在独立集群或者在被 YARN 或 Mesos 管理的集群上运行, 也能部署在云上。
-
运行:Flink 的核心是分布式流式数据引擎,意味着数据以一次一个事件的形式被处理。
-
API:DataStream、DataSet、Table、SQL API。
-
扩展库:Flink 还包括用于复杂事件处理,机器学习,图形处理和 Apache Storm 兼容性的专用代码库。
Flink数据流编程模型
-
最底层提供了有状态流。它将通过 过程函数(Process Function)嵌入到 DataStream API 中。它允许用户可以自由地处理来自一个或多个流数据的事件,并使用一致、容错的状态。除此之外,用户可以注册事件时间和处理事件回调,从而使程序可以实现复杂的计算。
-
DataStream / DataSet API 是 Flink 提供的核心 API ,DataSet 处理有界的数据集,DataStream 处理有界或者无界的数据流。用户可以通过各种方法(map / flatmap / window / keyby / sum / max / min / avg / join 等)将数据进行转换 / 计算。
-
Table API 是以 表 为中心的声明式 DSL,其中表可能会动态变化(在表达流数据时)。Table API 提供了例如 select、project、join、group-by、aggregate 等操作,使用起来却更加简洁(代码量更少)。
你可以在表与 DataStream/DataSet 之间无缝切换,也允许程序将 Table API 与 DataStream 以及 DataSet 混合使用。
-
Flink 提供的最高层级的抽象是 SQL 。这一层抽象在语法与表达能力上与 Table API 类似,但是是以 SQL查询表达式的形式表现程序。SQL 抽象与 Table API 交互密切,同时 SQL 查询可以直接在 Table API 定义的表上执行。
Flink 程序与数据流结构
1、Source: 数据源,Flink 在流处理和批处理上的 source 大概有 4 类:基于本地集合的 source、基于文件的 source、基于网络套接字的 source、自定义的 source。自定义的 source 常见的有 Apache kafka、Amazon Kinesis Streams、RabbitMQ、Twitter Streaming API、Apache NiFi 等,当然你也可以定义自己的 source。
2、Transformation:数据转换的各种操作,有 Map / FlatMap / Filter / KeyBy / Reduce / Fold / Aggregations / Window / WindowAll / Union / Window join / Split / Select / Project 等,操作很多,可以将数据转换计算成你想要的数据。
3、Sink:接收器,Flink 将转换计算后的数据发送的地点 ,你可能需要存储下来,Flink 常见的 Sink 大概有如下几类:写入文件、打印出来、写入 socket 、自定义的 sink 。自定义的 sink 常见的有 Apache kafka、RabbitMQ、MySQL、ElasticSearch、Apache Cassandra、Hadoop FileSystem 等,同理你也可以定义自己的 sink。
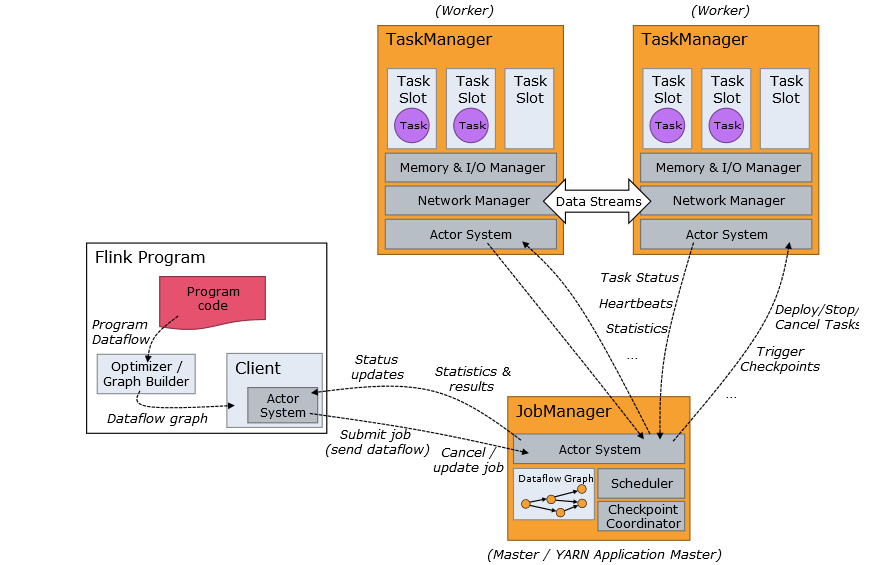
Program code是自己的代码
Job Client是任务执行的起点。 Job Client 负责接受用户的程序代码,然后创建数据流,将数据流提交给 Job Manager 以便进一步执行。 执行完成后,Job Client 将结果返回给用户。
Job Manager:主进程(也称为作业管理器)协调和管理程序的执行。机器集群中至少要有一个 master,master 负责调度 task,协调 checkpoints 和容灾,高可用设置的话可以有多个 master,但要保证一个是 leader, 其他是 standby; Job Manager 包含 Actor system、Scheduler、Check pointing 三个重要的组件。
Task Manager:从 Job Manager 处接收需要部署的 Task。Task Manager 的一个 Slot 代表一个可用线程,该线程具有固定的内存,注意 Slot 只对内存隔离,没有对 CPU 隔离。默认情况下,Flink 允许子任务共享 Slot,即使它们是不同 task 的 subtask,只要它们来自相同的 job。这种共享可以有更好的资源利用率。
一、有状态的流式处理
事务处理
当应用程序需要拓展到更多不同用户时,可能会由于紧耦合导致问题,拓展和更改表结构更加困难,因此微服务设计模式
分析处理
根据大量宝贵的数据,我们可以分析他们,得到一定的结论。
但是数据太多了,要分别放在不同服务器的数据库中,因此获取数据的时候,要获取所有服务器的数据库中的数据。
数据通常需要转换为通用格式。
将数据复制到数据仓库的过程称为extract-transform-load(ETL)。
ETL过程可能非常复杂,并且通常需要技术复杂的解决方案来满足性能要求。
ETL过程需要定期运行以保持数据仓库中的数据同步。
将数据导入数据仓库后,可以查询和分析数据。通常,在数据仓库上执行两类查询。第一种类型是定期报告查询,第二种类型是即席查询。两种查询由批处理方式由数据仓库执行
Hadoop:将大量数据(如日志文件,社交媒体或Web点击日志)写入Hadoop的分布式文件系统(HDFS)、S3或其他批量数据存储库
有状态的流式处理
如果我们想要无限处理事件流,并且不愿意繁琐地每收到一个事件就记录一次,那这样的应用程序就需要是有状态的,也就是说能够存储和访问中间数据
包括事件驱动应用程序、数据管道、流分析
事件驱动应用程序
事件驱动的应用程序是有状态的流应用程序,可以用于实时推荐、行为模式检测或复杂事件处理、异常检测。
Flink可以将应用程序的状态重置为先前的保存点(save point),从而可以在不丢失状态的情况下更新或重新扩展应用程序。
数据管道
在不同存储系统中同步数据的两种方法:
-
定期ETL作业(Extract-Transform-Load的缩写,用来描述将
-
事件日志(event log)来发布更新
操作数据管道的流处理器还应具有许多源(source)和接收器(sink)的连接器
流分析
Flink简介
Flink具有高吞吐量和低延迟。
-
事件时间(event-time)和处理时间(processing-tme)
-
精确一次(exactly-once)的状态一致性保证。
-
每秒处理数百万个事件,毫秒级延迟。
流处理引擎通常提供一组内置操作:摄取(ingest),转换(transform)和输出流(output)。
任务失败后如何处理?
EXACTLY-ONCE 恰好处理一次
最好的方式是端对端恰好处理一次
系统架构
Flink是一个用于有状态的并行数据流处理的分布式系统。它由多个进程构成,这些进程一般会分布运行在不同的机器上。对于分布式系统来说,面对的常见问题有:集群中资源的分配和管理、进程协调调度、持久化和高可用的数据存储,以及故障恢复。
对于这些问题,Flink借鉴了别人的解决方案。这样它就可以把精力集中在核心工作——分布式数据流处理上了。
Flink运行时架构主要包括四个不同的组件:
-
作业管理器(JobManager)
-
ResourceManager主要负责管理任务管理器(TaskManager)的插槽(slot)
-
任务管理器(TaskManager)是Flink中的工作进程。
-
分发器(Dispatcher)可以跨作业运行,它为应用提交提供了REST接口。
一个TaskManager可以同时执行多个任务(tasks)。
Flink如何重启失败的进程?
发生原因7*24小时运行很可能挂了。故障的原因包括:
-
TaskManager故障
-
作业管理器故障
任务链
Flink采用了一种称为任务链的优化技术,可以在特定条件下减少本地通信的开销。
将两个或多个算子设为相同的并行度,并通过本地转发(local forward)的方式进行连接。
水位线(watermark)
-
必须单调递增,以确保任务的事件时间时钟在向前推进,而不是在后退。
-
水位线可带有时间戳
水位线的传递和事件时间
待补充。。。
时间戳的分配和水位线的产生
-
在数据源(source)处分配
-
定期分配
-
间断分配
状态管理
任务会接收一些输入数据,在处理数据时,任务可以读取和更新状态,并根据输入数据和状态计算结果。有点像前端数据的感觉。。。
在Flink中,状态始终与特定算子相关联。算子需要预先注册其状态。有两种类型的状态:算子状态(operator state)和键控状态(keyed state)
算子状态
Flink为算子状态提供三种基本数据结构:
列表状态、联合列表状态(用于列表故障的时候的启动与恢复)、广播状态(有多项任务,而它的每项任务状态又都相同,那么这种特殊情况最适合应用广播状态。)
键控状态
flink的安装(windows环境下)
需要java,看下java版本,是否大于1.8,如果没有java需下载1.8以上版本
java -version
下载flink
git clone https://github.com/apache/flink.git
cd flink
安装maven
进入官网:http://maven.apache.org/download.cgi
下载红色文件
解压文件到指定位置
配置环境变量MAVEN_HOME,将【%maven_home%\bin】追加到PATH路径中
在cmd中输入以下命令,看是否安装成功
mvn -version
如果没成功,在环境变量Path中改成【%SystemRoot%\system32;%maven_home%\bin】
编译flink
mvn clean package -DskipTests
cd build-target
我遇到的问题:
[ERROR] No compiler is provided in this environment. Perhaps you are running on a JRE rather than a JDK?
如何解决?
问题的原因是jdk路径的错误设置所导致的,在安装jdk的时候确实指定了一个自己的安装路径,但是打开该路径下的jdk文件夹,发现并不存在jre等文件夹
在oracle上下载jdk,重新装一下jdk,添加环境变量
启动本地Flink群集
打开git
cd 对应flink的目录
./bin/start-cluster.sh
pyflink操作基本知识
对于pyflink,只需要知道pyflink是一个:
-
数据流处理的框架
-
这个框架是同时运行在多台主机上
-
通过某种方式这多台主机之间可以通信
-
可以单机运行
-
pyflink只是对java的flink的一个调用工具,不能直接用python来对source、sink组件进行实现。
我们把输入叫做source,处理叫做transform,输出叫做sink。
尽量不要使用print和input之类的方法。
而且有一部分代码运行在python环境中,有一部分代码运行在jre中
检查点机制(checkpoint)
state是 Checkpoint 进行持久化备份的主要角色。
其中 MemoryStateBackend(内存的状态管理器) 和 FsStateBackend(基于文件系统的状态管理器) 在运行时都是存储在 java heap 中的。
Backend如果什么都没有,是后端的意思;如果加上State,即(StateBackend)那么是状态管理器的意思。
第一步:检查点 coordinator向所有的source节点触发 Check-point;
第二步:source节点向下游广播barrier,下游的task只有收到所有input的barrier才会执行checkpoint。
第三步:task完成state备份后,会将备份数据的地址通知给Checkpoint coordinator.
第四步:下游的sink节点收集齐上游两个input的barrier后,执行本地快照。
第五步:sink结点在完成自己的checkpoint之后,返回state handle值给Coordinator.
第六步:Checkpoint coordinator收集齐所有task的state handle,就可以作为checkpoint结束的标志
checkpoint的exactly_once通过input buffer在对齐阶段收到的数据缓存起来,等对齐完成后在处理(有点一一对应的感觉)。而对于at least once代表至少处理一次。
Yarn/k8s
-
Yarn是资源管理工具,也就是说管理CPU+MEM的资源隔离。
-
k8s是容器编排工具,显然,资源管理是其功能之一。
用户自定义函数(也就是我们自己定义一个函数)肯定有用到参数的时候,输入输出参数的类型是TypeInformation,生成对应类型的序列化器 TypeSerializer。
即flink的序列化过程:TypeInfrmation通过createSerialize()生成TypeSerializer
但是flink的序列化和反序列化对于一部分类型好用,另一部分类型不好用啊!不好用,可以用Kyro 来进行序列化和反序列化。如果类是public,且类有一个public的无参数构造函数,才可以使用POJO的方式。如果POJO无法序列化和反序列化,用Kyro 兜底。
Flink 常见的应用场景有:注册子类型、注册自定义序列化器、添加类型 提示、手动创建 TypeInformation
在Windows系统上,为什么总安装不上pyflink?
或许要安装Visual Studio的2019版生成工具才能正确安装pyflink
source源
transform转换器,处理逻辑
sink输出到数据库,kafaka等,print到控制台
kafaka可以作为源和输出
import argparse
import logging
import sys
from pyflink.common import Row
from pyflink.table import (EnvironmentSettings, TableEnvironment, TableDescriptor, Schema,
DataTypes, FormatDescriptor)
from pyflink.table.expressions import lit, col
from pyflink.table.udf import udtf
word_count_data = ["To be, or not to be,--that is the question:--",
"Whether 'tis nobler in the mind to suffer",
"The slings and arrows of outrageous fortune",
"Or to take arms against a sea of troubles,",
"And by opposing end them?--To die,--to sleep,--",
"No more; and by a sleep to say we end",
"The heartache, and the thousand natural shocks",
"That flesh is heir to,--'tis a consummation",
"Devoutly to be wish'd. To die,--to sleep;--",
"To sleep! perchance to dream:--ay, there's the rub;",
"For in that sleep of death what dreams may come,",
"When we have shuffled off this mortal coil,",
"Must give us pause: there's the respect",
"That makes calamity of so long life;",
"For who would bear the whips and scorns of time,",
"The oppressor's wrong, the proud man's contumely,",
"The pangs of despis'd love, the law's delay,",
"The insolence of office, and the spurns",
"That patient merit of the unworthy takes,",
"When he himself might his quietus make",
"With a bare bodkin? who would these fardels bear,",
"To grunt and sweat under a weary life,",
"But that the dread of something after death,--",
"The undiscover'd country, from whose bourn",
"No traveller returns,--puzzles the will,",
"And makes us rather bear those ills we have",
"Than fly to others that we know not of?",
"Thus conscience does make cowards of us all;",
"And thus the native hue of resolution",
"Is sicklied o'er with the pale cast of thought;",
"And enterprises of great pith and moment,",
"With this regard, their currents turn awry,",
"And lose the name of action.--Soft you now!",
"The fair Ophelia!--Nymph, in thy orisons",
"Be all my sins remember'd."]
def word_count(input_path, output_path):
t_env = TableEnvironment.create(EnvironmentSettings.in_streaming_mode()) # 表环境创建
# write all the data to one file
t_env.get_config().get_configuration().set_string("parallelism.default", "1") # 设置并行度
# define the source
if input_path is not None:
t_env.create_temporary_table( # 临时表放在内存中,其读取和写入较快
'source', # 表名
TableDescriptor.for_connector('filesystem') # 输出表的元数据,for_connector表的驱动,'filesystem'打印的内容
.schema(Schema.new_builder() # Schema表的框架(表结构)
.column('word', DataTypes.STRING())
.build())
.option('path', input_path)
.format('csv')
.build())
tab = t_env.from_path('source')
else:
print("Executing word_count example with default input data set.")
print("Use --input to specify file input.")
tab = t_env.from_elements(map(lambda i: (i,), word_count_data),
DataTypes.ROW([DataTypes.FIELD('line', DataTypes.STRING())])) # 生成table,env.,定义一个源
# define the sink
if output_path is not None:
t_env.create_temporary_table(
'sink',
TableDescriptor.for_connector('filesystem')
.schema(Schema.new_builder()
.column('word', DataTypes.STRING())
.column('count', DataTypes.BIGINT())
.build())
.option('path', output_path)
.format(FormatDescriptor.for_format('canal-json')
.build())
.build())
else:
print("Printing result to stdout. Use --output to specify output path.")
t_env.create_temporary_table(
'sink',
TableDescriptor.for_connector('print')
.schema(Schema.new_builder()
.column('word', DataTypes.STRING())
.column('count', DataTypes.BIGINT())
.build())
.build())
@udtf(result_types=[DataTypes.STRING()])
def split(line: Row):
for s in line[0].split():
yield Row(s)
# compute word count
ds = ds.flat_map(split) \
.map(lambda i: (i, 1), output_type=Types.TUPLE([Types.STRING(), Types.INT()])) \
.key_by(lambda i: i[0]) \
.reduce(lambda i, j: (i[0], i[1] + j[1])) # flat_map展开,把他每个单词作为列表,key_by用来分组
# remove .wait if submitting to a remote cluster, refer to
# https://nightlies.apache.org/flink/flink-docs-stable/docs/dev/python/faq/#wait-for-jobs-to-finish-when-executing-jobs-in-mini-cluster
# for more details
if __name__ == '__main__':
logging.basicConfig(stream=sys.stdout, level=logging.INFO, format="%(message)s")
parser = argparse.ArgumentParser()
parser.add_argument(
'--input',
dest='input',
required=False,
help='Input file to process.')
parser.add_argument(
'--output',
dest='output',
required=False,
help='Output file to write results to.')
argv = sys.argv[1:]
known_args, _ = parser.parse_known_args(argv)
word_count(known_args.input, known_args.output)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号