FastDFS
一、简介
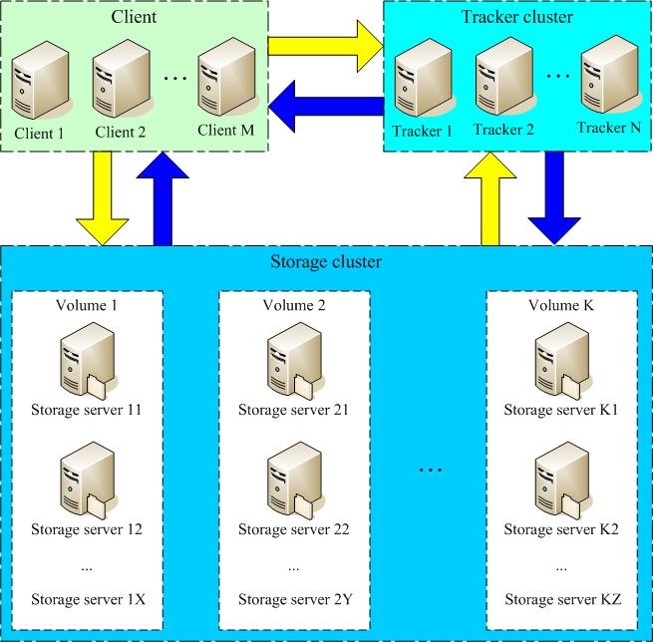
#FastDFS是一个轻量级的开源分布式文件系统 #FastDFS主要解决了大容量的文件存储和高并发访问的问题,文件存取时实现了负载均衡 #FastDFS实现了软件方式的RAID,可以使用廉价的IDE硬盘进行存储 #支持存储服务器在线扩容 #支持相同内容的文件只保存一份,节约磁盘空间 #FastDFS特别适合大中型网站使用,用来存储资源文件(如:图片、文档、音频、视频等等) #FastDFS是一个开源的轻量级分布式文件系统,由跟踪服务器(tracker server)、存储服务#器(storage server)和客户端(client)三个部分组成,主要解决了海量数据存储问题,特#别适合以中小文件(建议范围:4KB < file_size <500MB)为载体的在线服务。
原理图
上传文件流程流程图



当集群中不止一个tracker server时,由于tracker之间是完全对等的关系,客户端在upload文件时可以任意选择一个trakcer。 选择存储的group 当tracker接收到upload file的请求时,会为该文件分配一个可以存储该文件的group,支持如下选择group的规则: Round robin,所有的group间轮询 Specified group,指定某一个确定的group Load balance,剩余存储空间多多group优先 选择storage server 当选定group后,tracker会在group内选择一个storage server给客户端,支持如下选择storage的规则: Round robin,在group内的所有storage间轮询 First server ordered by ip,按ip排序 First server ordered by priority,按优先级排序(优先级在storage上配置) 选择storage path 当分配好storage server后,客户端将向storage发送写文件请求,storage将会为文件分配一个数据存储目录,支持如下规则: Round robin,多个存储目录间轮询 剩余存储空间最多的优先 生成Fileid 选定存储目录之后,storage会为文件生一个Fileid,由storage server ip、文件创建时间、文件大小、文件crc32和一个随机数拼接而成,然后将这个二进制串进行base64编码,转换为可打印的字符串。 选择两级目录 当选定存储目录之后,storage会为文件分配一个fileid,每个存储目录下有两级256*256的子目录,storage会按文件fileid进行两次hash(猜测),路由到其中一个子目录,然后将文件以fileid为文件名存储到该子目录下。 生成文件名 当文件存储到某个子目录后,即认为该文件存储成功,接下来会为该文件生成一个文件名,文件名由group、存储目录、两级子目录、fileid、文件后缀名(由客户端指定,主要用于区分文件类型)拼接而成。
文件同步
写文件时,客户端将文件写至group内一个storage server即认为写文件成功,storage server写完文件后,会由后台线程将文件同步至同group内其他的storage server。
每个storage写文件后,同时会写一份binlog,binlog里不包含文件数据,只包含文件名等元信息,这份binlog用于后台同步,storage会记录向group内其他storage同步的进度,以便重启后能接上次的进度继续同步;进度以时间戳的方式进行记录,所以最好能保证集群内所有server的时钟保持同步。
storage的同步进度会作为元数据的一部分汇报到tracker上,tracke在选择读storage的时候会以同步进度作为参考。
比如一个group内有A、B、C三个storage server,A向C同步到进度为T1 (T1以前写的文件都已经同步到B上了),B向C同步到时间戳为T2(T2 > T1),tracker接收到这些同步进度信息时,就会进行整理,将最小的那个做为C的同步时间戳,本例中T1即为C的同步时间戳为T1(即所有T1以前写的数据都已经同步到C上了);同理,根据上述规则,tracker会为A、B生成一个同步时间戳。
下载文件流程图


 浙公网安备 33010602011771号
浙公网安备 33010602011771号