Federated Learning发展前景探讨
前两天听了CCF YOCSEF举办的关于Federated Learning的讲座,感觉收获颇丰,开个帖子记录一下。
总体来说作为一个还不太成熟的新领域,围绕Federated Learning可做的东西还是非常多的,下至system/network/security,上至AI/RL甚至HCI都可以有事情可搞。
Part1、基于边缘计算的联邦学习挑战与展望
这是PolyU的郭嵩老师和阿里的合作课题。联邦学习相当于将原来在cloud上做的分布式ml搬到了edge device上。随着edge device算力的增强,郭老师总体是很看好这个领域的。

郭老师介绍了以下一些可做的问题:
1. 系统异构
看过Google的Towards Federated Learning System Design那篇paper的同学都知道FL是一个需要多节点synchronize(进行模型聚合)的过程,然而多节点协同还是比较难的。体现在以下两点:
- 通信异构:不同节点的带宽有限,而且异构(2G/4G/5G/WiFi/…)。
- 计算异构:不同节点算力不一样。
因为这些异构性的存在,会出现最慢的节点把整个训练时间拉长、降低总体效率的情况(大家只能等它完成了才能sync)。一个解决思路是让计算与通信同步重叠化(也就是同时计算和通信)。还有就是根据算力和网络情况动态调节batch size。
值得一提的是,重叠化的思想在SOSP19 PipeDream中也有应用。
2. 统计异构
不同节点上的数据在不同feature上的分布会不均匀(Non-IID),不同用户的数据量/数据质量也会很不一致,导致训练时间拉长,还会降低accuracy。但目前针对这个topic还没有一个理论的分析。
其中,数据质量的定义体现在:和总体的分布是否一致/label标的准不准确。一个简单衡量指标就是看这部分数据能让loss下降多少。
一些解决方案包括:对于和总体差距太大的节点,降低它对总体的contribution(也是控制batch size…)。其中的一个工作是用reinforcement learning的方法动态调节每个用户的batch size。
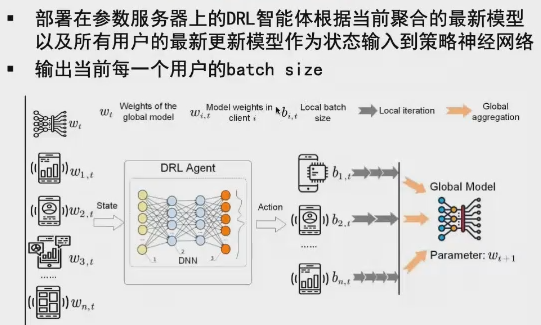
3. 安全可信
- 恶意节点攻击:例如某个节点构造一些恶意数据(比如对抗样本),导致整个模型不可靠。
- 隐私问题:training过程中节点需要和server交换gradient,然而这一过程中有可能可以crack出原始数据。
对于第一个问题,在传统的分布式ml中,可以在server侧发现恶意的gradient,然后直接踢掉这个节点。然而在edge device环境下又有一个问题:为降低模型通信开销,有时会用类似quantized的思路,只传输比较重要的参数(维度降低)。这种环境下再想做安全就有点难了。一个解决方案是稀疏化差分梯度。

最后郭老师展望了一下未来可做的topic:
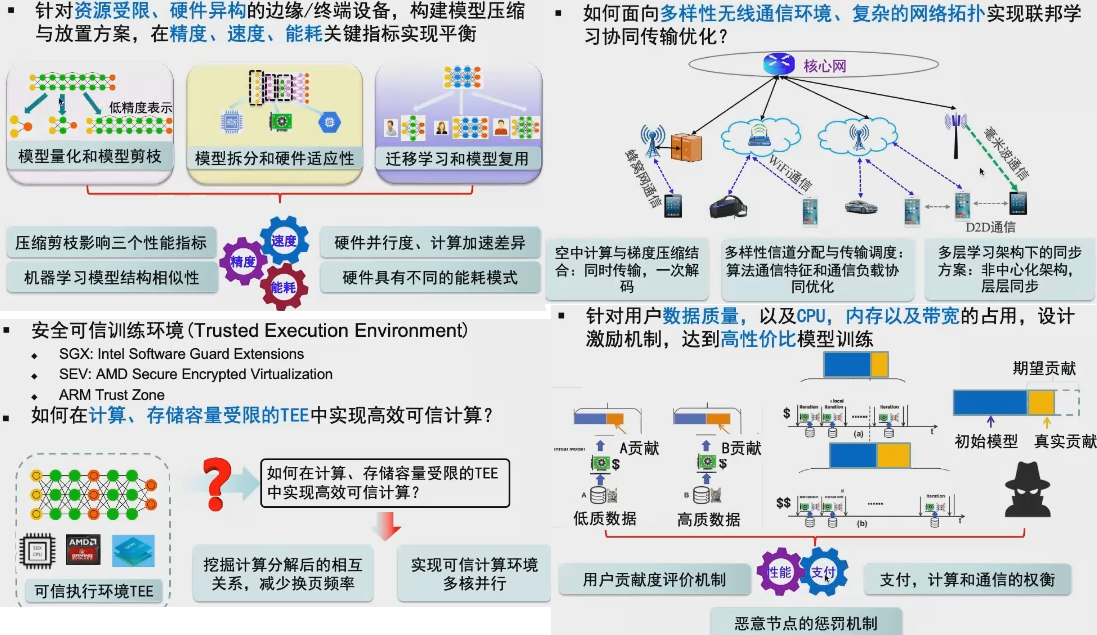
1. 模型压缩与放置:如何把大的model塞进资源有限的edge device。
这里面可用的方法包括:1). 在ml+arch界常用的模型量化和剪枝。 2). 模型拆分和硬件适应性(硬件架构、并行度、能耗、计算速度差异)。 3). 迁移学习和模型复用。重点关注的metric包括accuracy、运行速度和能耗。
2. 通信优化。这里值得一提的是hierarchical结构,可以分成多个层,每一层单独sync。这个思路和storage system里经常提的multiple tier有点像。
3. 安全计算。不太了解这个就先跳过了…
4. 激励机制。保证不同用户的contribution/数据质量和用户的收益是fair的(计算用户的贡献度),有点BT下载的意思。还有之前提到过的Non-IID。
Part2、联邦学习在工业界的落地场景 [0:53:00]
这里是三个来自工业界的presentation。
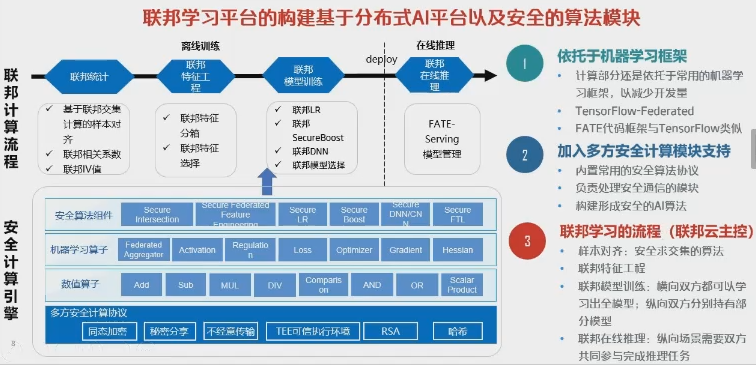
一个工业级的FL system需要关注两个topic:1). 分布式ML。这个了解的已经比较多了。 2). 安全的参数交换。模型参数交换需要采用安全计算的方式,来保证不泄露参数信息(工业界一般采用特定端口/VPN加上两层同态加密来实现)。另外还要保证计算结果不能反推出原始数据。 大致需要涉及以下内容:
Part3、Privacy-preserving federated machine learning [2:09:00]
这里会涉及一些密码学、differential privacy的内容。
虽然FL不会把数据共享出去,但还是存在一些安全上的risk:
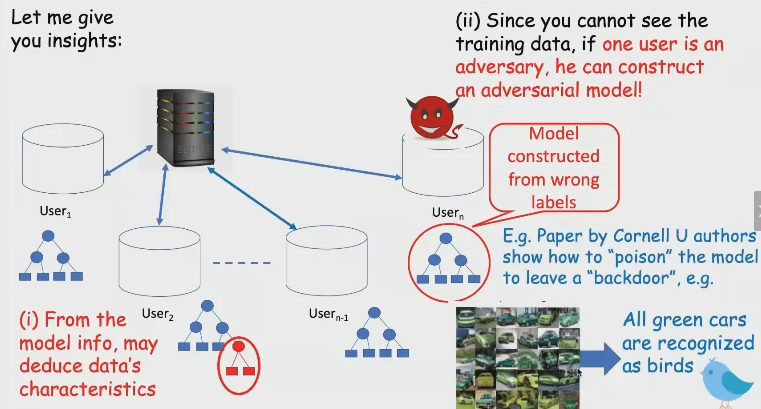
- user1和user2的local model是有一些差异的,可以从中推断出二者原始数据的一些特征
- 对抗样本
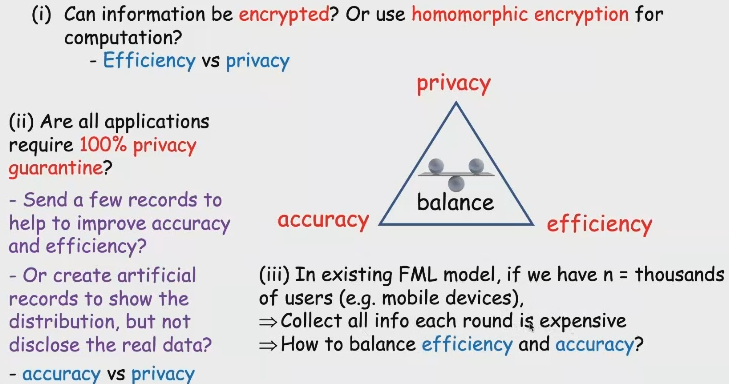
FL的安全性需要在以下三个方面做trade-off:privacy/accuracy/efficiency。这个就是要根据业界的应用场景而定了
Part4、联邦学习的激励机制 [2:34:00]
前面提到过这个topic,NTU的于涵老师对这一点做了更深入的研究。
1. 对每个节点贡献的评估——影响力评价
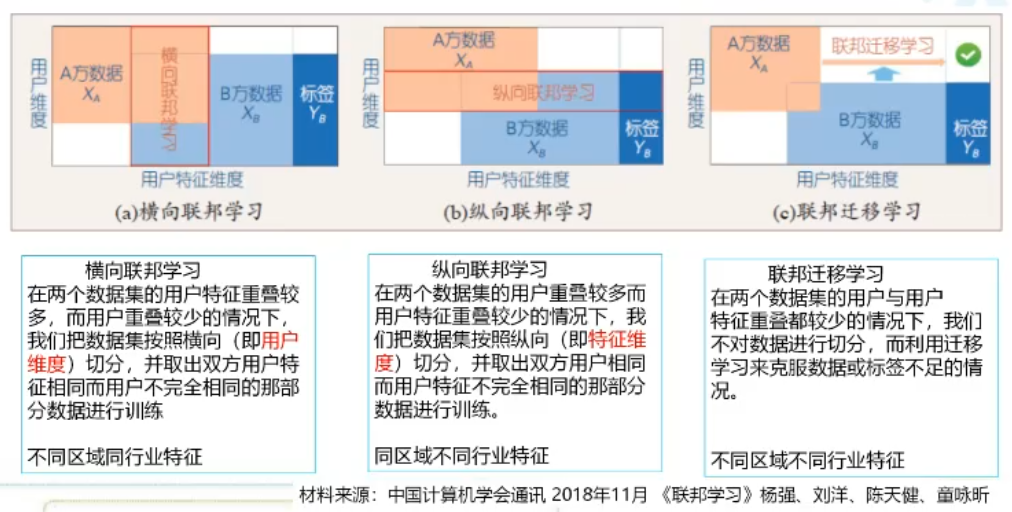
第一个场景是在横向联邦学习,意思是每个参与节点的background/feature都是一样的(比如都是医院),需要关注的是不同节点上的数据质量差异。一个方法是:可以在服务端搞个质量比较高数据集作为一个benchmark,当所有客户端节点都送来他们的本地model进行sync时,先对每个local model都跑一下benchmark,得到B[i]。模型聚合后的global model传回客户端后,每个客户端再用新model用本地数据跑一遍,得到L[i]。B[i]和L[i]的相互交叉熵就可以用来评估用户端的数据质量如何。
第二个场景是纵向联邦学习,此时每个节点差异会比较大(feature都不一样,甚至有的根本无label),但它们还是希望共同train一个model大家一起用。比如利用一个用户在不同公司的资料来学习出该用户的信用记录。一个工作是用Sparse Group Lasso对每个参与方重要性和特征重要性(哪个feature更有用)进行联合评估。
还有一个问题是通过奖惩措施来遏制恶意节点,可以参考这篇综述。
还有一个问题是去除不同参与顺序对贡献度计算的影响。比如设备A数据质量不太好,但参与的时间比较早,对global model的提升就比较明显(比如40%->80%);后来设备B也参与了,虽然B的数据质量更好,但global model的提升空间已经不大了(比如80%->85%),这种情况下可能就会对A和B的贡献度有误判。一个方案是用Data Shapley的方法把不同节点的加入顺序打乱,在不同顺序的条件下各计算一波,但这样复杂度太高了。一个改进方案是用一个blockchain来辅助计算。
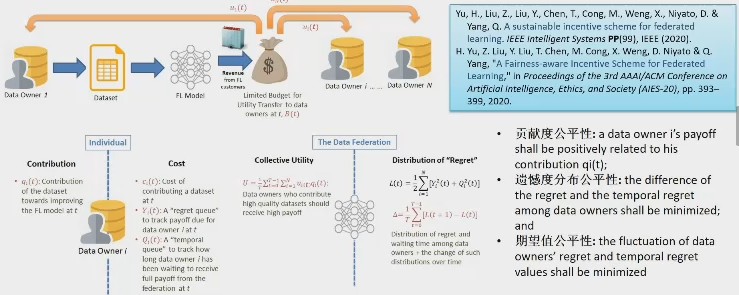
2. 如何设计公平、可解释的利益分配方案
Topic1:现有隐私保护技术(同态加密、安全多方计算、差分隐私)能否直接解决联邦学习中用户数据隐私的新需求? [3:00:00]
Topic2:现有指标(精度、算力、存储、传输)和新增隐私需求能否在联邦学习中得到有效平衡? [3:32:00]
posted on 2020-03-25 01:57 Pentium.Labs 阅读(1087) 评论(1) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号
