OS知识点总结
图片版在这:https://www.cnblogs.com/pdev/p/10576835.html
上完5103其实就该总结一下的......还是懒 (呵
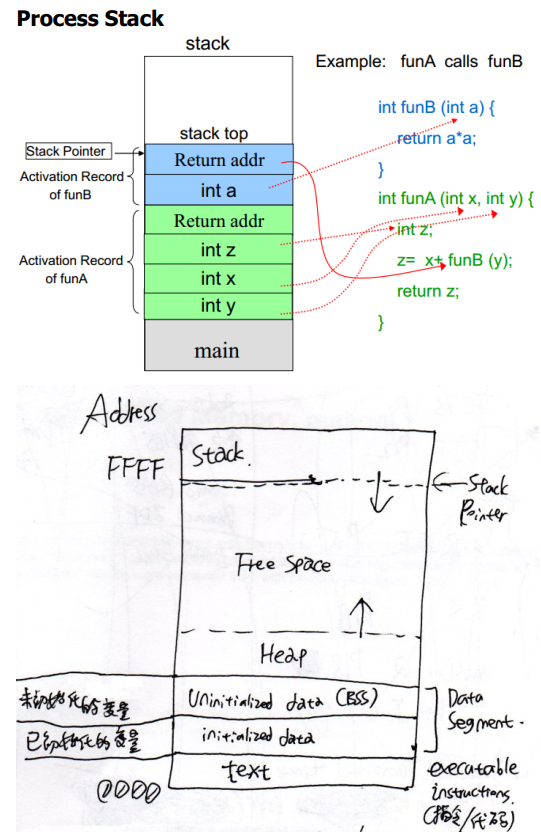
1. 进程栈
函数调用时,函数参数、返回地址、环境、函数内非static的局部变量存入栈。(栈空间是专门留给函数用的)
程序内所有malloc/new出来的空间、全局变量、所有的static变量存入堆。
(Ref:https://www.cnblogs.com/pdev/p/11289870.html)
堆是从低地址向高地址增长的,栈相反。参考下图
2. 内核态和用户态、system call
User programs are typically executed in user mode. In user mode, program cannot control devices or access memory address directly. All privileged operations should be executed by using system call. A user program executes in the USER mode and it is given limited privileges. Region of memory it can access is restricted. It cannot execute certain instructions such as HALT or setting or changing timers. It cannot directly access any I/O devices or network ports. The primary reason is to protect the system and other user processes and the file system from a misbehaving program.
Kernel code is trusted to be safe and correct. This code is executed in Privileged/Supervisor Mode. It can execute any operation (i.e. instruction). A user process executes the kernel code by making a system call.
System Call的全过程:
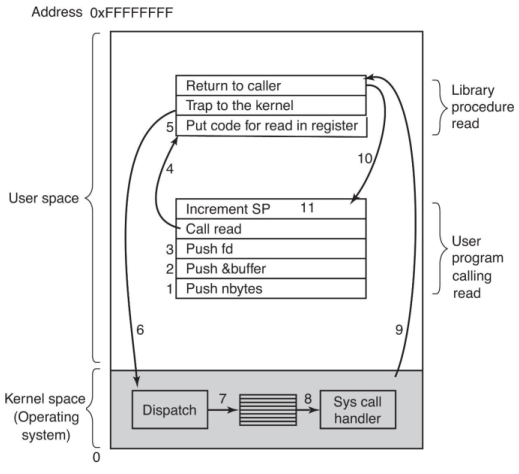
System Call和普通函数调用(procedure call)的对比:
system call:
1. Push all parameters into user mode stack
2. put the code of system call into CPU register (in other words, call this procedure)
3. execute a trap instruction, so it will start executing in kernel mode at a fixed address.
4. kernel code will be dispatched to a system-call handler, and the system-call handler runs in kernel mode.
5. After the kernel code finished, switch back to user mode and return to the instruction following TRAP in system call library procedure.
6. After the system call finished, return to user program.
7. The user program will clean up the parameters of system call in the stack, and user program continues.
procedure call:
1. Push all parameters into user mode stack
2. put the code of procedure call into CPU register (in other words, call this procedure)
3. execute the procedure in user mode
4. After procedure call finished, return to user program.
5. The user program will clean up the parameters of system call in the stack, and user program continues.
The procedure call does not need to switch betweenuser mode and kernel mode, so it will save time
Interrupts & exceptions & System calls & traps
Interrupts source: External devices (eg: finish I/O operation on hard disk). Goal: CPU could work in parallel with devices
Exceptions source: Errors in CPU when executing instructions. Goal: Handle internal errors in CPU (eg: divided by zero)
System calls source: Program manually call system call functions provided by operating system. Goal: Execute features which needs OS support (eg: I/O)
Traps source: TRAP instruction in program. Goal: Transfer from user mode into kernel mode
fork()函数
1.Only the thread who called fork() will be forked to new child process. So the child process only have 1 thread.
2.The child process will copy all the memory data from its parent process. Then they will run as independent processes. In modern operating systems, they will do
copy-on-write in fork(), which means both parents and child will receive a read-only copy of the parent's data space, instead of copying the whole data in the first
place. The copy will actually occur when one of them want to modify some data.
3.Based on (2), mutex variables will be copied into child process. Suppose we added locked a mutex before fork(). After fork(), the mutex in the child process will
remain locked, and there will be only one thread in the child process, which means this mutex in child process will never be unlocked(and this is called deadlock). Even if we unlocked mutex in parent process, the one in child process will not be modified.
4.Based on (2), File descriptors will be copied into child process. So they will have the same file pointer, which will point to the same file table. Thus the file status
opened in both processors(include their filename, current file offset) are shared.
clone()函数
Linux provides a more powerful function than fork for creating a new process or thread.
• It can be used to create a new process as in case of fork.
• It can also be used to create a new thread in the address space of the calling process.
进程的上下文切换(略)
进程和线程的区别
A process represents one single sequential activity. – one execution context (Program counter and stack)
A thread represents one activity -- one context and stack per thread.
All Threads of one process can share resources such as memory, open files, and communication channels.
- 进程是资源分配的独立单位
- 线程是资源调度的独立单位
All threads in a process share the following items:
– Address space
– Global variables
– Open files / resources
– Child processes
– Signals and signal handlers
– Accounting Information
Thread specific items:
– Program counter and registers (execution context)
– Stack
– Execution state (ready, waiting, running)
进程之间私有和共享的资源
- 私有:地址空间、堆、全局变量、栈、寄存器
- 共享:代码段,公共数据,进程目录,进程 ID
线程之间私有和共享的资源
- 私有:线程栈,寄存器,程序寄存器
- 共享:堆,地址空间,全局变量,静态变量
协程
进程是资源分配的最小单位,线程是CPU调度的最小单位。而协程可以理解为同一个线程通过上下文切换来“超线程”,并发执行两个工作。比起线程,协程更加轻量,而且多个协程访问同一资源不需要加锁(因为本质上还是在同一个线程内)。
协程的详细定义可以参考这里。另外go语言对协程有很好的支持。
进程/线程之间的通信方式总结


进程之间的通信方式以及优缺点 管道(PIPE) 有名管道:一种半双工的通信方式,它允许无亲缘关系进程间的通信 优点:可以实现任意关系的进程间的通信 缺点: 长期存于系统中,使用不当容易出错 缓冲区有限 无名管道:一种半双工的通信方式,只能在具有亲缘关系的进程间使用(父子进程) 优点:简单方便 缺点: 局限于单向通信 只能创建在它的进程以及其有亲缘关系的进程之间 缓冲区有限 信号量(Semaphore):一个计数器,可以用来控制多个线程对共享资源的访问 优点:可以同步进程 缺点:信号量有限 信号(Signal):一种比较复杂的通信方式,用于通知接收进程某个事件已经发生 消息队列(Message Queue):是消息的链表,存放在内核中并由消息队列标识符标识 优点:可以实现任意进程间的通信,并通过系统调用函数来实现消息发送和接收之间的同步,无需考虑同步问题,方便 缺点:信息的复制需要额外消耗 CPU 的时间,不适宜于信息量大或操作频繁的场合 共享内存(Shared Memory):映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问 优点:无须复制,快捷,信息量大 缺点: 通信是通过将共享空间缓冲区直接附加到进程的虚拟地址空间中来实现的,因此进程间的读写操作的同步问题 利用内存缓冲区直接交换信息,内存的实体存在于计算机中,只能同一个计算机系统中的诸多进程共享,不方便网络通信 套接字(Socket):可用于不同及其间的进程通信 优点: 传输数据为字节级,传输数据可自定义,数据量小效率高 传输数据时间短,性能高 适合于客户端和服务器端之间信息实时交互 可以加密,数据安全性强 缺点:需对传输的数据进行解析,转化成应用级的数据。 线程之间的通信方式 锁机制:包括互斥锁/量(mutex)、读写锁(reader-writer lock)、自旋锁(spin lock)、条件变量(condition) 互斥锁/量(mutex):提供了以排他方式防止数据结构被并发修改的方法。 读写锁(reader-writer lock):允许多个线程同时读共享数据,而对写操作是互斥的。 自旋锁(spin lock)与互斥锁类似,都是为了保护共享资源。互斥锁是当资源被占用,申请者进入睡眠状态;而自旋锁则循环检测保持者是否已经释放锁。 条件变量(condition):可以以原子的方式阻塞进程,直到某个特定条件为真为止。对条件的测试是在互斥锁的保护下进行的。条件变量始终与互斥锁一起使用。 信号量机制(Semaphore) 无名线程信号量 命名线程信号量 信号机制(Signal):类似进程间的信号处理 屏障(barrier):屏障允许每个线程等待,直到所有的合作线程都达到某一点,然后从该点继续执行。 线程间的通信目的主要是用于线程同步,所以线程没有像进程通信中的用于数据交换的通信机制
Process Control Block
存储了以下信息:
Process state Number
User ID, accounting info, scheduling priority
Process context
Memory info, page tables
Open files, current /root dir
Pending signals and I/O
3. Scheduling Algorithm(略)
4. 临界区、信号量、死锁
进程的几种状态:

New – process is being created and initialized
Running – currently executing
Ready – waiting to get CPU to become running
Blocked – waiting for some event, such a I/O completion
Swapped – partially executed, and its memory image has been stored on the disk
Terminated – process has completed due to normal or abnormal exit.
sleep: A process executing a system call may go to sleep to wait for a resource.
wakeup: When the resource is available it is awakened
注意区分两个概念:
忙等待(busy-waiting): while(i!=1) {…} 消耗 CPU
阻塞等待(blocked-waiting): 挂起,不消耗 CPU
临界区:同时只有一个进程可以访问的资源。为了互斥访问临界资源,每个进程在进入临界区之前,需要先进行检查。
A sequence of code is called CRITICAL SECTION has the following properties: Mutual exclusion Property : At any time, at most one process can be executing the critical section code. In general, updates to shared data structures are performed in a critical section.
信号量
The motivation was to avoid busy waiting by blocking a process execution until some condition is satisfied.
- wait():value--,一个进程想获得临界区(当value>0时才放行。否则进程睡眠,等待信号量大于 0)
- signal():value++,一个进程释放临界区
- value>=0时表示信号量的值。value<0时表示当前等待进入临界区的进程个数。


Binary Semaphore:value取值只能取0和1。0 表示临界区已经加锁,1 表示临界区解锁。

经典的信号量同步问题
1111111111111
死锁
死锁的发生条件:
- 互斥资源
- 已得到某资源的进程可以请求新的资源
- 已分配到某资源的进程不可被抢占(eg:刻光盘)
- 环路等待:A等待B,B等待C,C等待A
预防死锁的方法
- 打破互斥条件:改造独占性资源为虚拟资源,大部分资源已无法改造。
- 打破不可抢占条件:当一进程占有一独占性资源后又申请一独占性资源而无法满足,则退出原占有的资源。
- 打破占有且申请条件:采用资源预先分配策略,即进程运行前申请全部资源,满足则运行,不然就等待,这样就不会占有且申请。
- 打破循环等待条件:实现资源有序分配策略,对所有设备实现分类编号,所有进程只能采用按序号递增的形式申请资源。
- 银行家算法
银行家算法:避免死锁。在进程申请资源时,检查申请的合理性。只有不导致死锁的申请才被认可。
安全性算法:由银行家算法改进更通用的安全性算法。用于multiple resource type的情况。
Ref:https://blog.csdn.net/Caoyang_He/article/details/80819411

管程(monitor)
略
5. 内存管理
Paged memory management:eliminates fragmentation by non-contiguous allocation
- Physical memory is divided into fixed size blocks– FRAMES.
- Logical memory (as seen by the programmer) is also dividedinto the same size blocks called – PAGES.
- PAGE TABLE: Maps logical pages to physical frames. sizeof(Page)==sizeof(Frame)
页表使用虚拟地址中的页号作为索引,以找到相应的物理页号。每个进程都有它自己的页表,用来将程序的虚拟地址空间 映射到主存中。为了指出页表在存储器中的位置,硬件包含一个指向页表首地址的寄存器,我们称之为页表寄存器 ( page table register )
OS中会同时运行很多的进程。进程的地址空间,以及它在主存中可以访问的所有数据 , 都 由 驻 在主 存 中 的页表所定义 。 操 作 系统只是简单地加载页表寄存器用来指向它想激活的进程的页表 , 而不是保 存整个页 表 。 由于不同进程使用相同的虚拟地址 , 因此每个进程有各 自 的页表 。 操 作系统负责分配物 理主存和更新页表 , 因此不同进程的虚拟地址空间不会发生冲突 。
虚拟存储器系统必须使用 write-back机制,对存储器中的页进行单独的写操作(暂时不修改磁盘上对应的页),并且在该页被替换出存储器时再被复制到磁盘中去。为此,为了追踪读入 主存中 的页是否被写过 ,可以在页表中增加一 个脏位 (dirty bit) 。 当被指向的这个页中任何字被写时就将这一位置1 。修改过的页也被称为dirty page
页表的结构
程序中使用的地址都是逻辑地址(Page Number和Offset)。CPU想访问某内存空间时,首先在TLB(位于CPU中,相当于一个页表的cache)中找页号对应的页框号。如果找到了就直接去物理内存读该页框的内容。如果没找到就先进入页表找,得到页框号和物理地址(Frame Number+Offset),再去读物理内存。
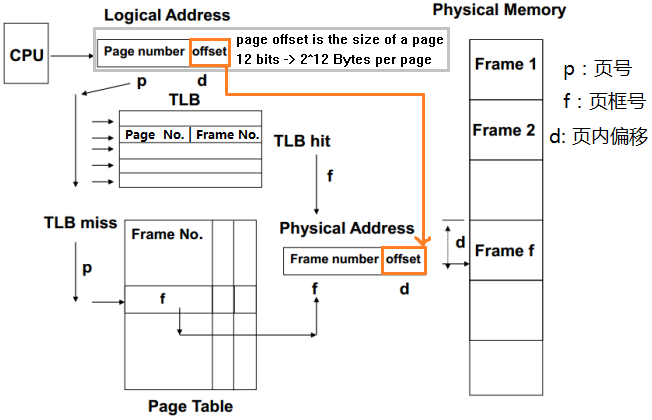
另外,每个页表项使用 1 位有效位,就像在 cache 中设计的一样 。 如果该位为0,表示该页不在主存中,就发生一次缺页 。 如果该位为1,表明该页在主存中,可以直接根据物理页号去内存中读取这个页 。 (《计算机组成与设计——硬件/软件接口》 P294)
TLB的作用就是避免每次都要查找页表(这个速度是比较慢的)。TLB 的每个标记项存放虚页号的一部分,每个数据项中存放了物理页号 。由于我们每次访问的是 TLB 而不是页表, TLB 需要包括其他状态位,如脏位和引用位。 如下图,灰色线表示直接通过TLB hit找到内存中的页面,没找到的就要去页表查了。
页表可以提供该虚拟地址的物理页号(可以用来创建TLB项),或者指出该页在磁盘上,这时就会发生缺页 。 由于页表对于每个虚页都有 一个相应的项,并不需要标记 ; 换句话说,不同于 TLB, 页表并不属于 cache 。在后面FastMATH的例子中可以更深刻的体会到这一点。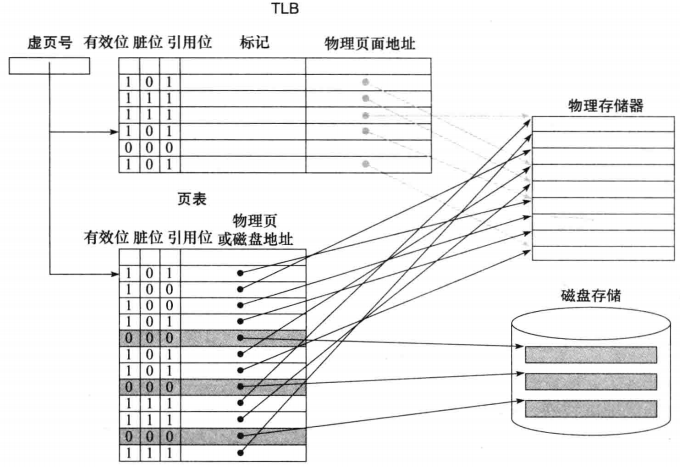
各个步骤所需的时间(clock)可以参考下图:
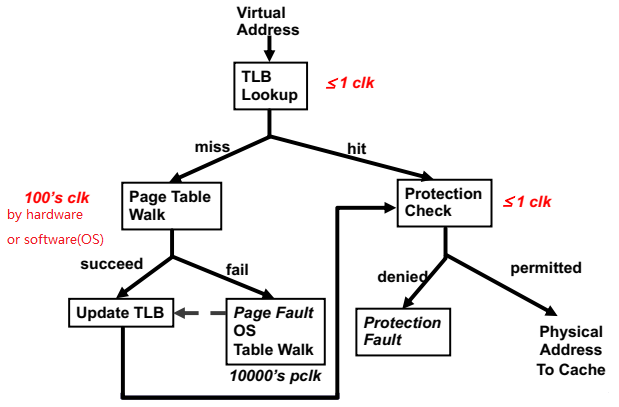
TLB和cache的关系
TLB也在CPU中,属于一种特殊的cache。那么它和普通的L1、L2 Cache有什么关系呢?
以HI书的图5-30中介绍的FastMATH芯片为例。原版的图比较复杂,简化一下大概是这样:
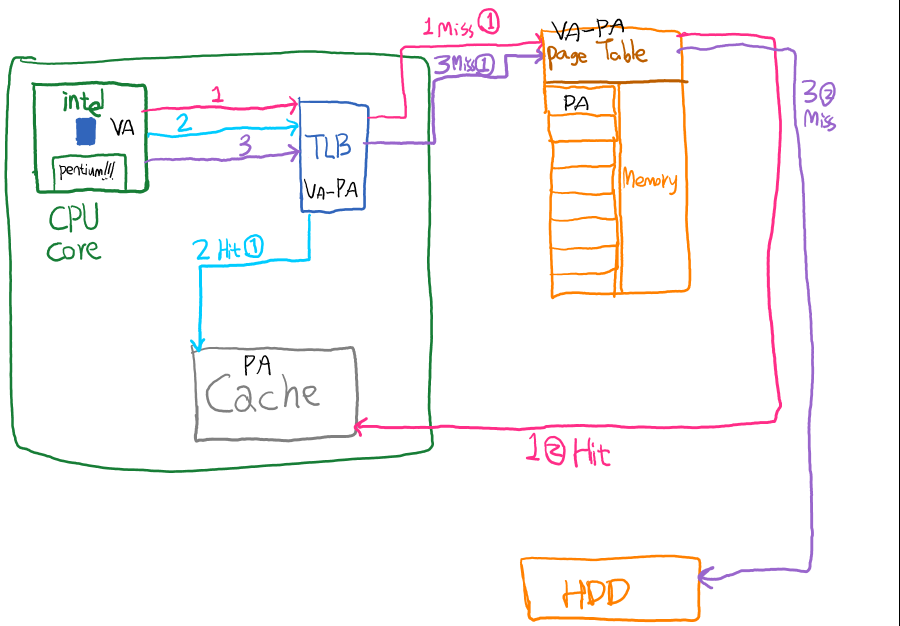
这里面CPU想访问一个虚拟地址,然后有这么几种可能性(VA: 虚拟地址 PA: 物理地址):
- 1. (1)TLB没找到VA->PA,(2)页表中找到了VA->PA。然后去Cache试图访问这个PA,如果有了就完事了,没有就再去内存读
- 2. (1)TLB找到了VA->PA。直接去Cache试图访问这个PA,如果有了就完事了,没有就再去内存读
- 3. (1)TLB没找到VA->PA,(2)页表里也没找到VA->PA。然后要去硬盘的交换区读相关的VA->PA的记录,然后这时cache里是肯定没这个PA(页面)的,只能取读内存了
可以看出:
- TLB和页表属于一类,用于完成VA->PA。
- Cache和内存属于一类,用于存储每个PA的页面。
- CPU只认识VA,所以需要先想办法转换成PA才行。这样就有了前面这套流程
上面这套流程假定了在访问 cache 之前,所有存储器地址都被转换成物理地址。在这种结构中,cache 是按物理地址索引 (physically indexed) 并且是物理标记 ( physically tagged) 的(所有 cache 的索引和标记都用物理地址,而不是虚拟地址) 。 在这个系统中,假定 cache命中,那么访问主存的时间要包括对 TLB 访问和 cache 访问的时间,当然,这些访问可以流水地执行 。这种设计叫做物理寻址的Cache。
另外还有一种虚拟寻址Cache,这里Cache里的数据是按虚拟地址索引并访问的。但这就有个问题了:如果两个很相似的进程用了某个一模一样的虚拟地址,那么存放在cache中就会导致混乱。一个办法是对不同进程搞个别名,但这样就增加了软件的复杂度。
这两种设计观点常用的折中方法是采用虚拟地址索引的 cache-—-有时仅仅使用地址的Page offset(页内偏移)部分,由 于没有被转换,因此实际上是物理地址——但使用物理标记。这些采用虚拟索引和物理标记的设计,试图同时拥有虚拟地址索引 cache 的优越性能以及物理寻址 cache (physical addressed cache) 的简单结构 。 例如 ,在 这种情况下就没有别名的问题 。 要实现这种方法,必须在最小页大小 、 cac he 大小以及相联度之间进行谨慎的权衡 。(HI P301,Problem set Q2(b))
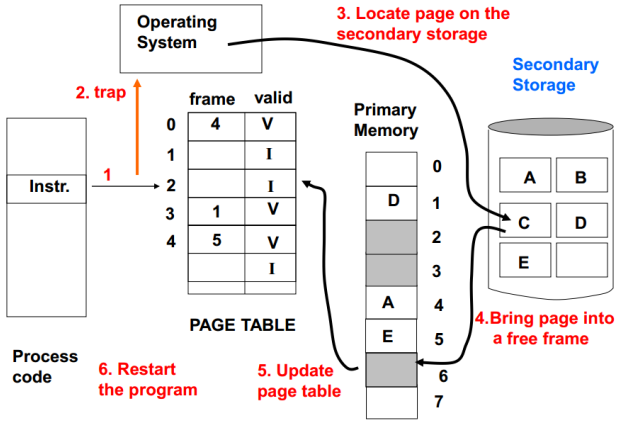
Page Fault
物理内存空间是有限的,所以引入虚拟内存的概念。当程序试图访问的内存地址现在不在物理内存中时,就会发生Page Fault。此时OS获得控制权,并进入TRAP(进入内核态,并由系统将对应的内存页从虚拟内存载入物理内存)。
操作系统在创建进程的时候通常会在闪存或磁盘上,为进程中所有的页(全部虚拟地址空间)预留一块磁盘空间 。 这一磁盘空间称为交换区 (swap space) 。 同时,它也会创建一个数据结构来记录每个虚拟页在磁盘上的存放位置 。 这个数据结构可能是页表中的一部分,也可能是辅助数据结构, 寻址方式和页表一样 。
Page Fault后的过程如下图:
页面置换算法
内存满时用于选出要放入虚拟内存的页面。(略)
当页表太大时需要分成多级页表。
二级页表:第二级页表可以按需要动态调入,从而节省空间。 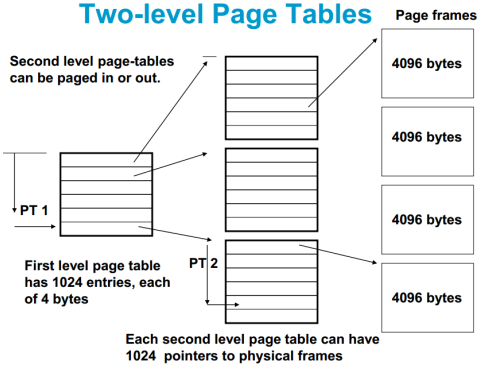
Working Set
The memory references generated by a program over some period of time tend to be confined to some small number of pages which reflects its "locality" during that execution phase. Try to maintain the pages which belong to the current working set (locality). Working set is estimated based on a time window of execution instead of some number of memory references. Parameter t defined as a time window. Working-set algorithm removes page p from then working-set if age(p) > t
程序在一段时间内访问的内存块集中在特定的几块。因此可以记录最近(某个time window内)用过的k个Page,保证它们不会被置换出去。
分段内存管理(略)
分段和分页的比较
对程序员的透明性:分页透明,但是分段需要程序员显式划分每个段。
地址空间的维度:分页是一维地址空间,分段是二维的。
大小是否可以改变:页的大小不可变,段的大小可以动态改变。
出现的原因:分页主要用于实现虚拟内存,从而获得更大的地址空间;分段主要是为了使程序和数据可以被划分为逻辑上独立的地址空间并且有助于共享和保护。
页面置换算法
FIFO:最简单的......
LRU:Replace 最久没用过的。注意如何实现LRU算法也是个经常被问的问题
NRU:按以下优先级(顺序按timestamp而定)淘汰页面:没被访问过也没被修改过 > 没被访问过但修改过 > 访问过但没被修改过 > 访问过也修改过。
Working Set:为每个页面设置一个R bit(记录当前时钟时间间隔内是否访问过该页面)和timestamp(记录上次访问时间),然后按以下规则淘汰页面:
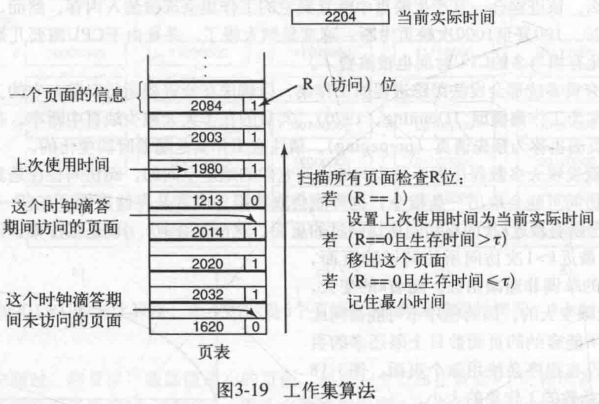
其中τ是一个参数,表示一个Working set的大小(按时间计算)。R==1表示刚刚用过,肯定不能淘汰。如果有页面满足R==0且timestamp已经在τ之外,直接淘汰它。如果扫描了一圈发现不存在这样的页面,就把R==0且timestamp最小(距离现在最久远)的一个淘汰掉。
Working Set Clock:对基本工作集算法的改进,提高了一点点性能,但意思还是一样的
6. IO、文件系统
Polling: busy waiting until device finish
Interrupt: 用中断处理,但频繁中断占用太多 cpu
DMA:传输一大段才 interrupt,而不是每个 word/byte 都中断
1. CPU sets up the DMA controller register to handler DMA transfer from a disk to memory.
•Number of bytes to be transferred
•Memory address where to transfer the data.
2. DMA controller issues a request to disk controller read the next block in its buffer and write to a memory address.
3. Disk controller reads disk block in its buffer, and writes it to memory buffer.
4. After writing the block to the memory, the disk controller “acks” the DMA controller, which then decrements the count, increases the memory address, and goes to step 2 if
the count is greater than 0.
5. DMA controller interrupts the CPU when the count reaches 0.
Disk && Disk Storage Management(略)
Concurrent Access to Files
On Unix system:
•Writes to an open file are visible immediately to other users that have this file open at the same time.
•When a process forks a child, a file open at the time of fork is shared with the child. Both parent and the child share the file position pointer
inode
Ref:https://blog.csdn.net/xuz0917/article/details/79473562
文件存储在硬盘上,硬盘的最小存储单位叫做“扇区”(Sector)。每个扇区储存512字节(相当于0.5KB)。操作系统读取硬盘的时候,不会一个个扇区的读取,这样效率太低,而是一次性连续读取多个扇区,即一次性读取一个“块”(block)。这种由多个扇区组成的“块”,是文件存取的最小单位。“块”的大小,最常见的是4KB,即连续八个sector组成一个block。
文件数据都储存在block中,那么很显然,我们还必须找到一个地方储存文件的“元信息”,比如文件的创建者、文件的创建日期、文件的大小等等。这种储存文件元信息的区域就叫做inode,中文译名为”索引节点“。每一个文件都有对应的inode,里面包含了与该文件有关的一些信息。如图所示
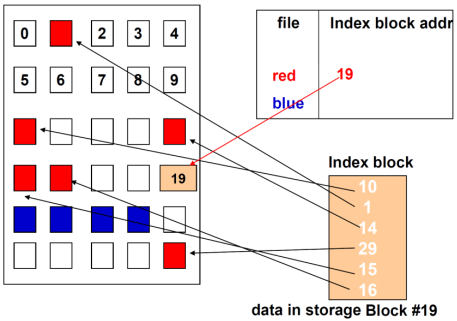
The addresses of all storage blocks of a file are recorded in one (or more) "index block". This block is maintained on the disk and is accessed through the directory entry. When a file is opened, this block is read into memory. Once this block is in memory, any block of the file can be accessed directly
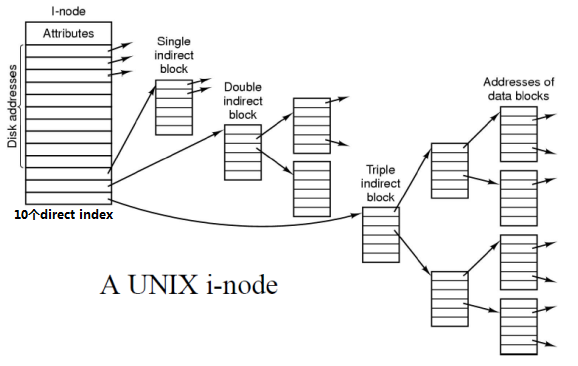
Unix的iNode是一个多级的索引结构。如下图,
- The INODE for a file contains up to 10 direct data block addresses.
- Three pointers for first, second, and third level of indirection.
Suppose that file-block size is 4KB. The first 10 direct pointers will point first 40KB of the file.
Suppose that the first level indirect block has 128 pointers. (设32bit pointer,4KB/32bit=128)
Then, with the block size of 4KB, we can now address additional 128*4KB, i.e. about 0.5 MBytes.
For a file larger than that, the INODE contains the second level indirect blocks. This block has pointers (128) for 128 first level indirect blocks, each of which points to data blocks of 0.5 MBytes. Thus by using the second level indirect pointer, we can now store additional 64 MBytes in the file.(128*128*4KB)
With third level indirect block we get file size close to 8GB. (128*128*128*4KB)
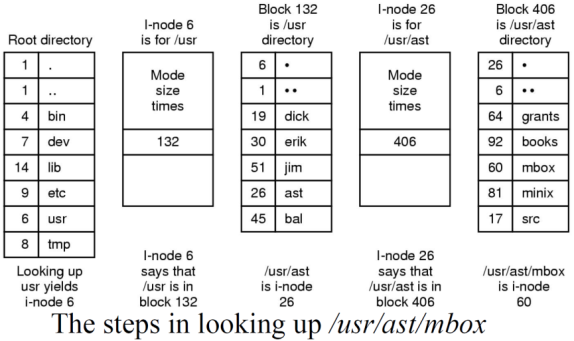
文件夹也有inode。访问文件夹时,先访问该文件夹的iNode,然后顺着iNode找该文件夹所在的block。
| Symbolic Linking(符号链接/软链接) | Hard-Link(硬链接) | |
|
类似Windows的快捷方式,只记录源文件的位置。 是个独立的文件,占用空间 |
与源文件指向相同的iNode,不占用空间。 源文件的所有hard link都被删除时,源文件才真正被删除。iNode keep count of hard links. |
|
| Pros |
可以为文件夹创建symbolic link 源文件可以在不同的文件系统。 |
可用来保护源文件 |
7. Security (略)
8. Virtual Machine(略)
9. 一些补充知识点
Ref:
https://github.com/CyC2018/CS-Notes/blob/master/notes/%E8%AE%A1%E7%AE%97%E6%9C%BA%E6%93%8D%E4%BD%9C%E7%B3%BB%E7%BB%9F%20-%20%E7%9B%AE%E5%BD%95.md
https://github.com/huihut/interview#-%E6%93%8D%E4%BD%9C%E7%B3%BB%E7%BB%9F
主机字节序与网络字节序
主机字节序又叫 CPU 字节序,其不是由操作系统决定的,而是由 CPU 指令集架构决定的。主机字节序分为两种:
- 大端字节序(Big Endian):高序字节存储在低位地址,低序字节存储在高位地址
- 小端字节序(Little Endian):高序字节存储在高位地址,低序字节存储在低位地址
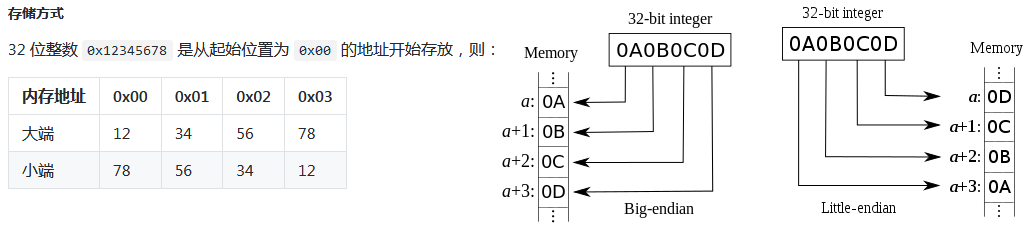
各架构处理器的字节序
- x86(Intel、AMD)、MOS Technology 6502、Z80、VAX、PDP-11 等处理器为小端序;
- Motorola 6800、Motorola 68000、PowerPC 970、System/370、SPARC(除 V9 外)等处理器为大端序;
- ARM(默认小端序)、PowerPC(除 PowerPC 970 外)、DEC Alpha、SPARC V9、MIPS、PA-RISC 及 IA64 的字节序是可配置的。
网络字节顺序是 TCP/IP 中规定好的一种数据表示格式,它与具体的 CPU 类型、操作系统等无关,从而可以保证数据在不同主机之间传输时能够被正确解释。网络字节顺序采用大端(Big Endian)排列方式。
大内核和微内核
大内核
大内核是将操作系统功能作为一个紧密结合的整体放到内核。由于各模块共享信息,因此有很高的性能。
微内核
由于操作系统不断复杂,因此将一部分操作系统功能移出内核,从而降低内核的复杂性。移出的部分根据分层的原则划分成若干服务,相互独立。在微内核结构下,操作系统被划分成小的、定义良好的模块,只有微内核这一个模块运行在内核态,其余模块运行在用户态。因为需要频繁地在用户态和核心态之间进行切换,所以会有一定的性能损失。
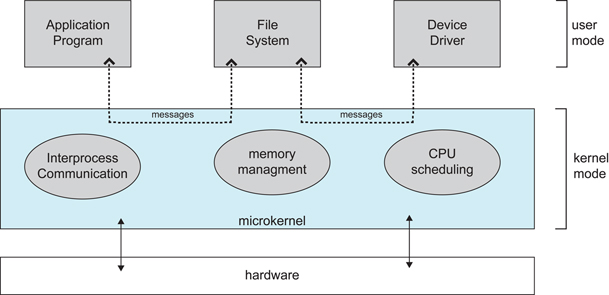
编译系统
以下是一个 hello.c 程序:
#include <stdio.h>
int main()
{
printf("hello, world\n");
return 0;
}
在 Unix 系统上,由编译器把源文件转换为目标文件。
gcc -o hello hello.c
这个过程大致如下:

- 预处理阶段:处理以 # 开头的预处理命令;
- 编译阶段:翻译成汇编文件;
- 汇编阶段:将汇编文件翻译成可重定位目标文件;
- 链接阶段:将可重定位目标文件和 printf.o 等单独预编译好的目标文件进行合并,得到最终的可执行目标文件。
静态链接
静态链接器以一组可重定位目标文件为输入,生成一个完全链接的可执行目标文件作为输出。链接器主要完成以下两个任务:
- 符号解析:每个符号对应于一个函数、一个全局变量或一个静态变量,符号解析的目的是将每个符号引用与一个符号定义关联起来。
- 重定位:链接器通过把每个符号定义与一个内存位置关联起来,然后修改所有对这些符号的引用,使得它们指向这个内存位置。

目标文件
- 可执行目标文件:可以直接在内存中执行;
- 可重定位目标文件:可与其它可重定位目标文件在链接阶段合并,创建一个可执行目标文件;
- 共享目标文件:这是一种特殊的可重定位目标文件,可以在运行时被动态加载进内存并链接;
动态链接
静态库有以下两个问题:
- 当静态库更新时那么整个程序都要重新进行链接;
- 对于 printf 这种标准函数库,如果每个程序都要有代码,这会极大浪费资源。
共享库是为了解决静态库的这两个问题而设计的,在 Linux 系统中通常用 .so 后缀来表示,Windows 系统上它们被称为 DLL。它具有以下特点:
- 在给定的文件系统中一个库只有一个文件,所有引用该库的可执行目标文件都共享这个文件,它不会被复制到引用它的可执行文件中;
- 在内存中,一个共享库的 .text 节(已编译程序的机器代码)的一个副本可以被不同的正在运行的进程共享。

111
posted on 2019-08-10 10:01 Pentium.Labs 阅读(1166) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号
