

大数据多维分析平台的实践
一、 大数据多维分析平台搭建的初心
随着公司业务量的增长,基于传统关系型数据库搭建的各种报表查询分析系统,性能下降明显。同时由于大数据平台的的日趋完善,实时的核心业务数据逐步进入大数据平台。数据进入了大数据平台,相伴而来的是各种业务需求,这里主要聚焦在如何高效稳定的基于大数据平台的数据进行查询。通过分析,我们面临的挑战如下:
- 亿级别表下任意维度和时间跨度的高效的统计查询
- 业务分析的维度越来越多,是否可以提供一个灵活的多维度组合查询的工具,而不是针对不同的维度组合开发不同的报表
基于以上目标,开始搭建大数据的多维分析平台。
二、 多维分析平台技术选型
搭建多维分析平台,首先面临的是技术选型,基于我们对开源框架的使用经验和实际情况,我们主要看业界主流的公司是如何使用应对的,在技术选型上会进行一定的比较,但不会投入比较大的资源进行验证,主张快速的迭代,效果的评估。多维分析平台技术选型主要面临是OLAP引擎和前端UI的选型。
我们先来看一下OLAP的基本概念和分类。
OLAP 翻译成中文叫联机分析处理,OLTP 叫联机事务处理。OLTP 它的核心是事务,实际上就是我们常见的数据库。我们业务数据库就是面向于事务。它的并发量会比较高,但是操作的数据量会比较小。它是实时更新的。数据库的设计会按照 3NF 范式,更高的话可能会按照 BC 范式之类的来做。而 OLAP 的核心是分析,面向应用是分析决策,需要分析的数据级会非常大,可能 TB,甚至 PB 都会有。它的数据更新会稍微慢一些,它的设计一般是反范式的,因为面向分析。常见的是雪花模型和星型模型。
OLAP的引擎目前主要分为3类
第一种叫 ROLAP,叫关系型 OLAP,它的特点就是它是基于关系性模型,计算的时候,根据原始数据去做聚合运算。常见的实现,小数据量可以利用 MySQL、SqlServer 这种传统数据库,而大数据量可以利用 Spark SQL、Tidb、ES 这些项目。
第二种类型叫 MOLAP,叫多维 OLAP,它的特点就是它会基于一个预定义的模型,我需要知道,要根据什么维度,要去算哪些指标,我提前就把这些结果弄好,存储在引擎上。细节数据和聚合后的数据保存在cube中,以空间换时间,查询效率高。
实际上我们的很多业务也是基于此思想去做的,比如我们会在ES里面按照电站、客户等维度进行聚合,满足日常的T+1查询需求,只不过这个地方每个聚合维度需要在ES里面做一个表,并增加上复杂的ETL处理.符合这个理念在业界用的比较多的为Kylin. 并且基于Kylin 有完整的一套开源产品KMS。涵盖了多维分析的前端UI及多维分析数据库。
第三种叫 HOLAP(Hybrid OLAP),叫混合 OLAP,特点是数据保留在关系型数据库的事实表中,但是聚合后的数据保存在cube中,聚合时需要比ROLAP高,但低于MOLAP。
综合分析,技术选型上主要考虑第ROLAP和MOLAP。关于OLAP的分类已经经过了很多年的发展,市场上相关的产品也有很多,但是大数据下基于开源组件应该如何搞?
在大数据时代,有了分布式计算和分布式存储,对于亿级别表的任意时间跨度多维度组合的查询,是不是可以直接查询,不用再预聚合。按照这个思路,查找了一些方案,没有很明显的技术倾向,我们想尝试了在Spark sql、tidb、es 上直接基于原始数据进行计算,效果不是很理想,这个按照理论,如果查询要想达到比较好的结果,可能集群规模需要加大不少。同时我们对别了大数据的MOLAP的产品,发现了KMS框架,最大的特点是同时提供了前端展现、以及数据库.并且目前业界主流互联网公司也都在用.经过对比权衡,决定先期基于KMS框架搭建多维分析平台.
三、 KMS框架介绍
- 整体介绍
KMS = Kylin + Mondrian + Saiku 是一个简单的三层架构,Git上已经有一个整合Kylin,Mondrian以及Saiku的项目。
Kylin: kylin是apache软件基金会的顶级项目,一个开源的分布式多维分析工具。通过预计算所有合理的维度组合下各个指标的值并把计算结果存储到HBASE中的方式,大大提高分布式多维分析的查询效率。Kylin接收sql查询语句作为输入,以查询结果作为输出。通过预计算的方式,将在hive中可能需要几分钟的查询响应时间下降到毫秒级
Mondrian:Mondrian是一个OLAP分析的引擎,主要工作是根据事先配置好的schema,将输入的多维分析语句MDX(Multidimensional Expressions )翻译成目标数据库/数据引擎的执行语言(比如SQL)
Saiku: Saiku提供了一个多维分析的用户操作界面,可以通过简单拖拉拽的方式迅速生成报表。Saiku的主要工作是根据事先配置好的schema,将用户的操作转化成MDX语句提供给Mondrian引擎执行
其中Mondrian和Saiku已经是非常成熟的框架,这里我们简单看下Kylin的架构.
- Kylin
Apache Kylin™是一个开源的分布式分析引擎,提供Hadoop/Spark之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由eBay Inc. 开发并贡献至开源社区。它能在亚秒内查询巨大的Hive表。
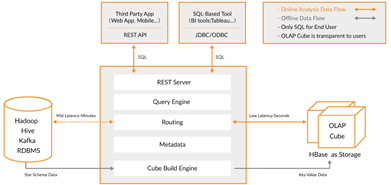
Apache kylin 能提供低延迟(sub-second latency)的秘诀就是预计算,即针对一个星型拓扑结构的数据立方体,预计算多个维度组合的度量,然后将结果保存在 hbase 中,对外暴露 JDBC、ODBC、Rest API 的查询接口,即可实现实时查询。主要的使用包含3个步骤
l 通过Kylin提供的UI界面定义多维分析模型和Cube
l 对定义好的cube进行预计算,并将计算的结果存储到hbase中
l 查询时通过kylin引擎将查询的sql引擎翻译成hbase的scan等进行数据的查询
更多关于kylin的案例、原理、调优 大家可以参考kylin的官方网站和社区,并可以通过社区邮件进行问题交流.
四、 多维分析平台的架构及应用情况
- 业务规划
多维分析报表的创建,除了工具本身之外,对系统数据的处理和设计也是非常之重要,基于目前的使用,主要考虑以下几个问题
² 多维报表的创建规划过程需要有一套数据分层划分模型,形成方法论、体系,以便指导业务人员进行报表的定义
² 新的业务需求提出时,是基于现有报表增加维度还是增加一个新的报表
² 多个报表由于业务需求,有重复的维度,重复的维度如何保证数据的一致性
基于以上我们将数据和维度进行了层次划分,业务处理过程采用逐层汇总的方式,进行数据汇总,最后通过saiku进行查询展现.数据分层结构如下:

日志数据:主要包含充电过程中的分钟报文数据、智能运维的分钟报文数据,数据主要存在HBase、ES、TIDB
明细数据:主要包含各种不同的业务订单数据。数据主要存储在sqlserver、ES。
聚合数据:聚合数据为按照不同的业务维度进行聚合的数据.比如 :按照电站、结算账户等归集的充电数据。数据主要存储在ES、Kylin.
公共维度:主要为系统共用的基础数据,比如电站、集控、终端数据。数据公用。
- 部署架构
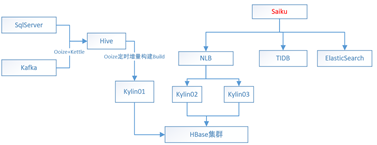
基于kylin 的设计架构,我们充分利用现有的hbase集群和计算集群,搭建了基于KMS的多维分析平台,这里重点介绍一下我们的架构部署情况.先看一下部署架构.
目前进入kylin的数据主要来自于sqlserver和kafka,通过kettle、flume等工具将数据抽取到离线计算集群hive数据库。
数据抽取到hive数据库之后,通过统一的调度工具调用Kylin的cube的build API,按照业务需求对之前定义好的cube进行预计算,计算好的结果存储到hbase集群
考虑到kylinbuild时占用资源较多,集群部署时,将kylin的build节点和查询节点进行了分离。目前build节点为一台,查询节点为2台。Hbase集群目前和线上的业务公用.
前端展示saiku是个成熟的多维分析展现工具,对接的数据源有很多种,社区开源版本主要提供了kylin、mysql的支持。在适应性上可以直接和kylin和tidb进行联通使用。由于kylin 查询节点部署了2台,为了充分使用saiku的缓存,在saiku端开发了基于用户的负载均衡。同时考虑到我们目前使用的集群,通过自定义开发实现了与ES集群的连通性.
- 应用情况
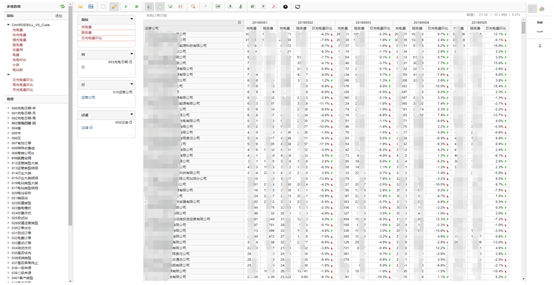
目前通过kylin定义的cube有20几个,最大的cube存储已经超过2T.基于saiku定义的报表目前主要用于公司的运营、运维、充电安全相关的查询。其中最大的查询维度已经接近100个.系统应用截图如下
- 解决的问题
² 为了保证saiku的HA同时充分利用saiku的缓存,开发了基于用户的负载均衡框架
² 为了方便通过手机进行多维分析报表的简单修改,对saiku框架进行了修改,适配了手机
² 对saiku的元数据增加了缓存,提高了查询速度
² 修改了saiku对大小写的配置,适配kylin数据库
² 参考kylin官方的案例和性能调优针对构建和查询过程进行优化
五、 总结及问题
- 目前存在的问题
² 多维分析集群查询对hbase的查询内存消耗较大,查询内存会引起gc,从而影响hbase的其他读写服务
² 数据结构发生变化,历史数据需要重新刷,运维成本比较高
² 历史数据发生变化,需要经常进行历史数据的刷新
² 非聚合组的维度进行查询,部分查询较慢
² Saiku前端的灵活性和数据库能力的矛盾
- 下一步的方向
² 提升运维效率,在某些表上进行es的应用,提升报表的实时性,建立起不同等级的数据表不同的数据库的区分原则
² 针对数据的日常刷新,开发简单的运维工具

 浙公网安备 33010602011771号
浙公网安备 33010602011771号