数据采集与融合技术 实验3
作业①:
-
要求:指定一个网站,爬取这个网站中的所有的所有图片,例如中国气象网(http://www.weather.com.cn)。分别使用单线程和多线程的方式爬取。(限定爬取图片数量为学号后3位)
-
输出信息:
将下载的Url信息在控制台输出,并将下载的图片存储在images子文件夹中,并给出截图
1)、中国气象网图片爬取
- 单线程爬取图片
-1.设置起始url和请求头,并用requests库进行解析
start_url = "http://www.weather.com.cn"
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36 Edg/94.0.992.38"}
# 用requests库解析url
r = requests.get(start_url, headers=header)
r.raise_for_status()
r.encoding = r.apparent_encoding
data = r.text
用BeautifulSoup方法解析data
soup = BeautifulSoup(data, "html.parser")
# select查询出带href属性的a结点
a = soup.select("a[href]")
其中经检查,a结点的href属性包含页面中的链接信息,如图:

-2.利用Beautifulsoup匹配出链接存入列表中后,设置函数进入链接利用正则表达式匹配出链接下所有的src数据
其中匹配src的函数代码如下
def searchsrc(link):
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36 Edg/94.0.992.38"}
# request方法解析link
r = requests.get(link, headers=header)
r.raise_for_status()
r.encoding = r.apparent_encoding
data = r.text
soup = BeautifulSoup(data, "html.parser")
title = soup.select("img")
# 正则匹配src地址
reg = r'.+?src="(\S+)"'
srclist = []
for i in title:
src = re.findall(reg, str(i))
srclist.append(src[0]) if src else ""
return srclist
-3.编写Download函数对爬取出的src进行下载
def download(link):
global num
file = "E:/pics/" + "No." + str(num+1) + ".jpg" # file指先在指定文件夹里建立相关的文件夹才能爬取成功
print("第" + str(num+1) + "张爬取成功")
num += 1
urllib.request.urlretrieve(url=link, filename=file)
-4.在最后的调用中对爬取数量进行限制
for link in links:
# 设置爬取数量
if num >= 413:
break
try:
pics = searchsrc(link)
for i in pics:
download(i)
if num >= 413:
break
except Exception as err:
print(err)
控制台输出url结果如下:

最后在文件夹中查看结果如下:
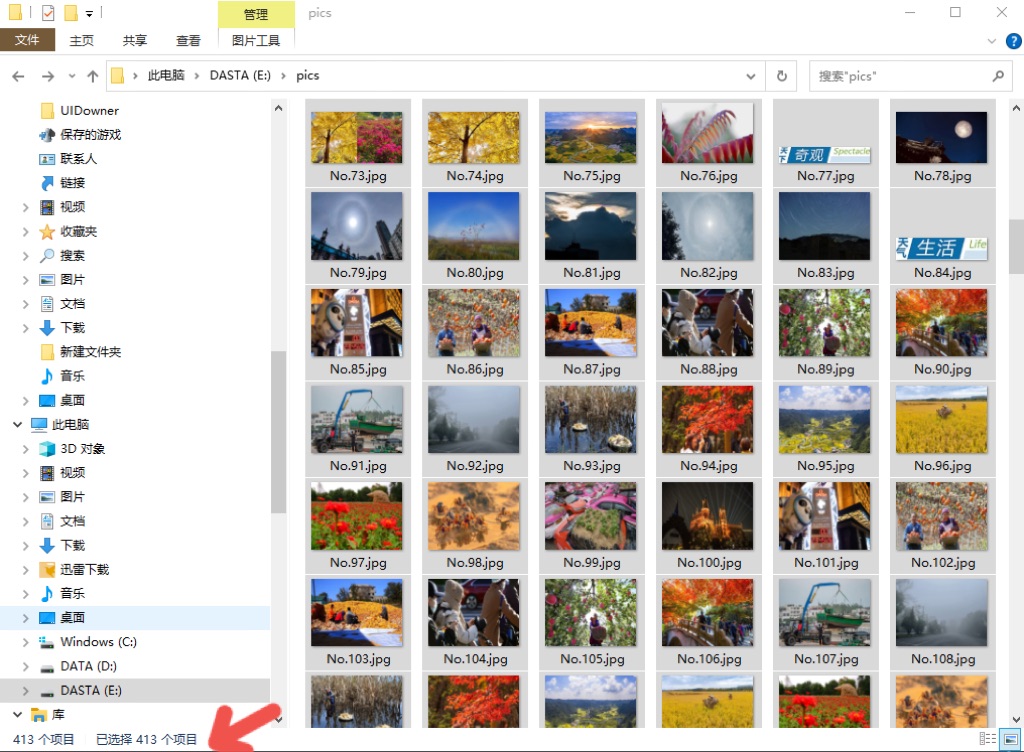
- 多线程爬取图片
-首先在单线程代码上修改为多线程。在控制台输出报错:远程主机中断连接,排查后发现应该是页面中的部分链接爬取失败。
-使用书上的代码,并将爬取链接的方式又beautifulsoup改为用正则匹配,这样过滤掉了一些有问题的链接
其中在主函数中设置线程,匹配src地址:
for image in images:
try:
src=image["src"]
url=urllib.request.urljoin(start_url,src)
# print(url)
if url not in urls:
# 设置if判断过滤.cn结尾的地址
if not str(url).endswith('.cn'):
if count == 413:
break
# print(url)
count = count+1
# 调用threading类设置target为download函数
T=threading.Thread(target=download,args=(url,count))
# 设置线程为后台线程
T.setDaemon(False)
T.start()
# 在threads队列中加入线程
threads.append(T)
在download函数中写入本地文件:
def download(url,count):
try:
# 提取出图片结尾,如:.jpg,.png等
if(url[len(url)-4]=="."):
ext=url[len(url)-4:]
else:
ext=""
req=urllib.request.Request(url,headers=headers)
data=urllib.request.urlopen(req,timeout=100)
data=data.read()
# 写入本地文件
fobj=open("E:\images\\"+str(count)+ext,"wb")
fobj.write(data)
fobj.close()
print("downloaded "+str(count)+ext+"from "+str(url)+"\n")
except Exception as err:
print(err)
正则匹配过滤页面中链接(爬取前20个链接):
a = '<a href="(.*?)" '
links = re.findall(re.compile(a), str(soup))
# 遍历links过滤出url地址
for i in range(len(links)):
if i < 20:
links1.append(links[i]) if links[i] != "javascript:void(0);" else ""
控制台输出结果如下:
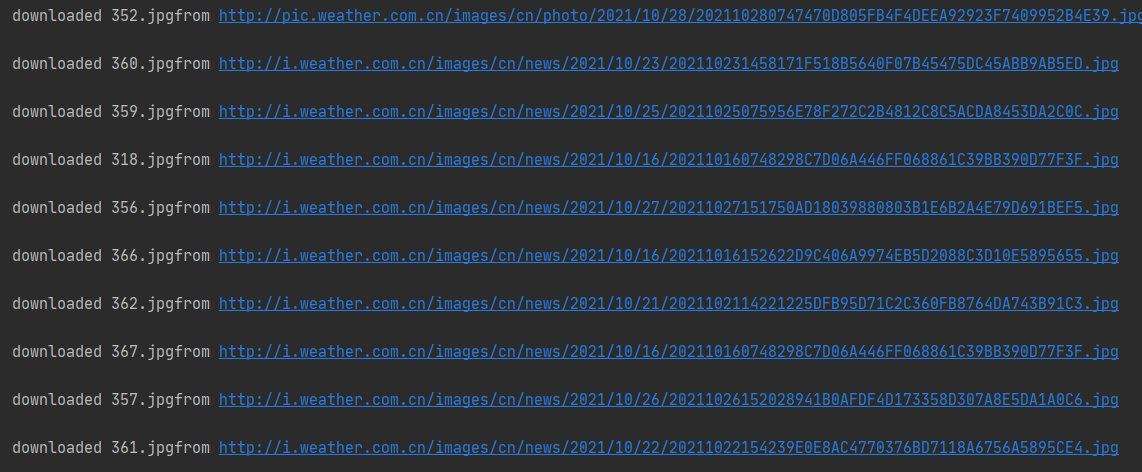
文件夹中结果如下:

2)、心得体会
作业1的单线程较为简单,和之前做过的作业类似,很快就完成了。对多线程的使用还是不够熟练,期间调试遇到了很多问题,其中在爬取时出现主机强迫关闭连接的报错信息:

最后发现是所爬取的页面图片总数不足,修改爬取链接的数量后解决
作业②:
-
要求:使用scrapy框架复现作业①。
-
输出信息:
同作业①
1)、scrapy复现
-1.编写items.py,settings.py
items.py:
设置需传递给管道类的item
src = scrapy.Field()
name = scrapy.Field()
settings.py:
解除限制:
ROBOTSTXT_OBEY = False
打开pipeline:
ITEM_PIPELINES = {
'weatherpics.pipelines.WeatherpicsPipeline':300,
}
-2.myspider.py
parse函数:
在parse函数中对www.weather.com.cn页面中的各个链接进行提取
a = soup.select("a[href]")
item = WeatherpicsItem()
links = []
for link in a:
links.append(link["href"]) if link["href"] != 'javascript:void(0)' else ""
如作业1中,编写searchsrc函数,利用正则表达式对各个页面中所包含的src地址进行提取:
def searchsrc(self,link):
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36 Edg/94.0.992.38"}
r = requests.get(link, headers=header)
r.raise_for_status()
r.encoding = r.apparent_encoding
data = r.text
soup = BeautifulSoup(data, "html.parser")
title = soup.select("img")
reg = r'.+?src="(\S+)"'
srclist = []
for i in title:
src = re.findall(reg, str(i))
srclist.append(src[0]) if src else ""
return srclist
最后在parse函数中调用,并传递给pipeline:
for link in links:
if num >= 413:
break
try:
pics = self.searchsrc(link)
for i in pics:
item['src'] = i
item['name'] = "E:/wtpics/" + "No." + str(num+1) + ".jpg"
num += 1
if num > 413:
break
yield item
-3.pipeline.py
在pipeline.py中调用urlretrieve方法进行图片下载保存
def process_item(self, item, spider):
link = item['src']
file = item['name']
urlretrieve(url=link, filename=file)
print(str(file)+" download completed.")
return item
结果如下:
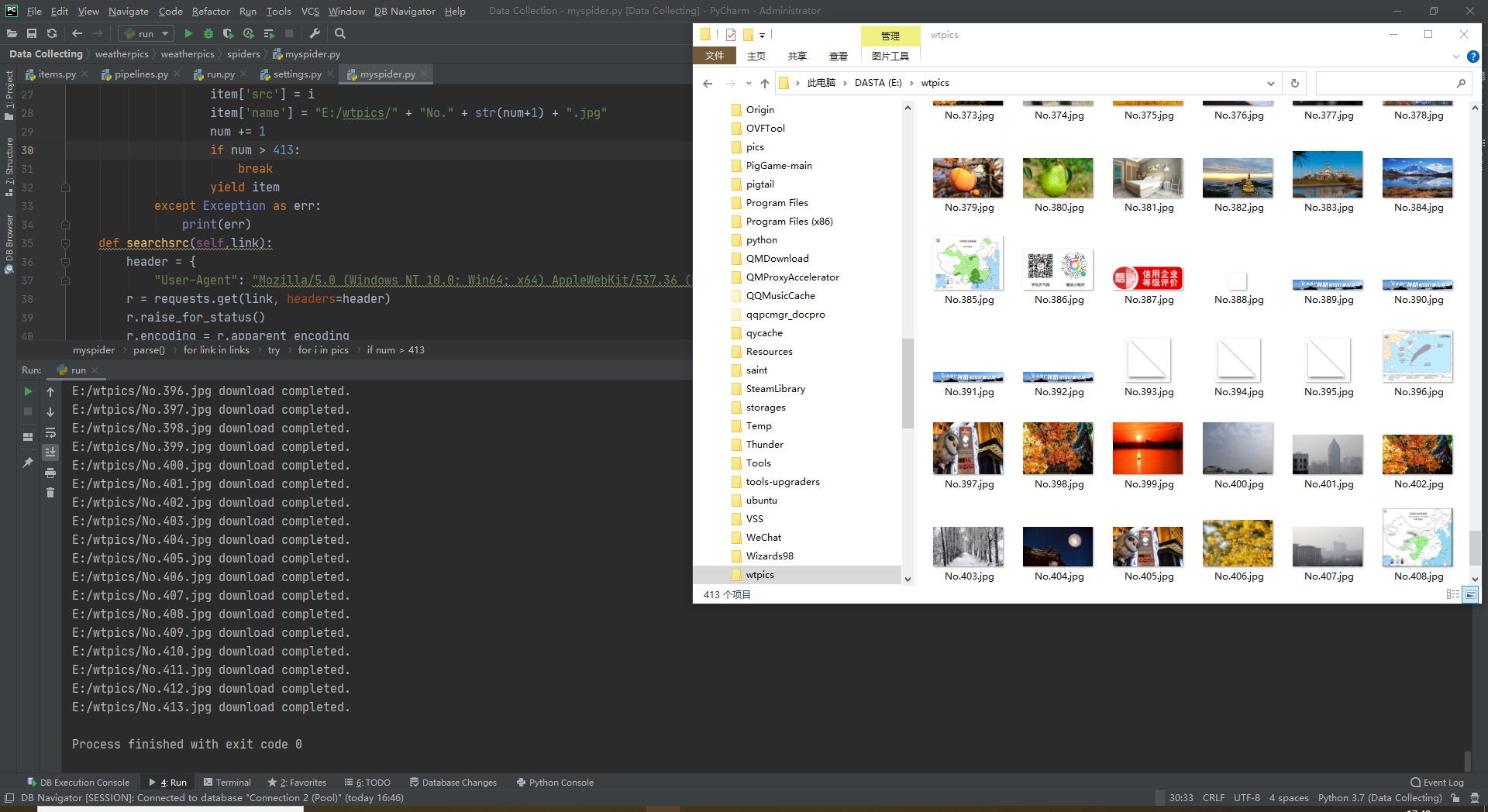
2)、心得体会
在作业2上主要考察的是对scrapy框架的熟练运用,解决起来也比较顺利,在pipeline中下载图片时一开始是想要用pipeline自带的方法imagepipeline进行下载,但是发现其控制台输出信息较为混乱,最后还是用了熟悉的urlretrieve进行下载。
作业③:
-
要求:爬取豆瓣电影数据使用scrapy和xpath,并将内容存储到数据库,同时将图片存储在
imgs路径下。
-
输出信息:
序号 电影名称 导演 演员 简介 电影评分 电影封面 1 肖申克的救赎 弗兰克·德拉邦特 蒂姆·罗宾斯 希望让人自由 9.7 ./imgs/xsk.jpg 2...
1)、豆瓣电影榜单爬取
-1.查看网页,发现排行页面显示主演信息不全(以及部分导演信息)

于是考虑进入每个电影的链接中,爬取出完整的演员信息

-2.编写settings类,items类
在settings类中先打开管道
ITEM_PIPELINES = {
'douban.pipelines.DoubanPipeline': 300,
}
解除限制:
ROBOTSTXT_OBEY = False
item类:
title = scrapy.Field()
score = scrapy.Field()
content = scrapy.Field()
rank = scrapy.Field()
src = scrapy.Field()
director = scrapy.Field()
actors = scrapy.Field()
-3.编写myspider.py
parse函数:
解析html
dammit = UnicodeDammit(response.body, ["utf-8", "gbk"])
data = dammit.unicode_markup
selector = scrapy.Selector(text=data)
在排行榜页面,爬取简介,电影名称和进入详细信息页面的链接
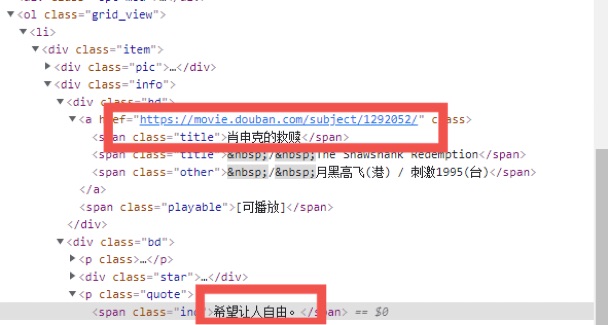
如图,需爬取的数据都在class='item'下,对该结点进行遍历:
for li in selector.xpath("//div[@class='item']"):
item['title'] = li.xpath("./div[@class='info']/"
"div[@class='hd']/a/span[@class='title']/text()").extract_first()
item['content'] = li.xpath("./div[@class='info']/div[@class='bd']/p[position()=2]/span/text()").extract_first()
# xpath提取出每个电影的后续链接
link = li.xpath("./div[@class='info']/div[@class='hd']/a/@href").extract_first()
# 设置request请求头
爬取到link之后用requests方法解析该链接的html(老师说再用scrapy解析会比较复杂):
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36 Edg/95.0.1020.30',
}
r = requests.get(link, headers=header)
r.raise_for_status()
# 设置解码格式为utf8防止出现乱码
r.encoding = 'utf8'
没有设置r.encoding为'utf8'时,爬取会出现乱码
其中需爬取的演员,导演等内容均在div[info]的span结点下,利用xpath进行爬取,并赋值给item:
在网页检查需爬取数据:

dir = info.xpath(
"./span[@class='pl']/following-sibling::span[1]/a[@rel='v:directedBy']/text()").extract()
item['director'] = "/".join(dir)
actor = info.xpath(
"./span[@class='pl']/following-sibling::span[1]/a[@rel='v:starring']/text()").extract()
item['actors'] = "/".join(actor)
item['score'] = selector2.xpath("//strong[@class='ll rating_num']/text()").extract_first()
item['src'] = selector2.xpath("//a[@class='nbgnbg']/img/@src").extract_first()
item['rank'] = selector2.xpath("//span[@class='top250-no']/text()").extract_first().split(".")[1]
yield item
在parse函数的最后设置翻页处理:
page = selector.xpath("//div[@class='paginator']/span[@class='thispage']/following-sibling::a[1]/@href").extract_first()
link_nextpage = "https://movie.douban.com/top250"+page
if page:
url = response.urljoin(link_nextpage)
yield scrapy.Request(url=url, callback=self.parse, dont_filter=True)
-4.编写pipeline.py
在pipeline中主要是进行将数据存入数据库中以及下载电影封面
连接mysql数据库:
def open_spider(self,spider):
try:
# 连接mysql数据库
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root",
password = "hts2953936", database = "mydb", charset = "utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)# 设置cursor
self.cursor.execute("delete from doubanmovie_copy2")
self.opened = True
except Exception as err:
self.opened = False
process_item函数:
调用urlretrieve函数下载电影封面
picpath = "E:/imgs/"+ str(item['title']) +".jpg"
# 调用urlretrieve函数下载图片
urlretrieve(url=item['src'],filename=picpath)
print(str(picpath)+" download completed")
mysql语句将数据插入数据库
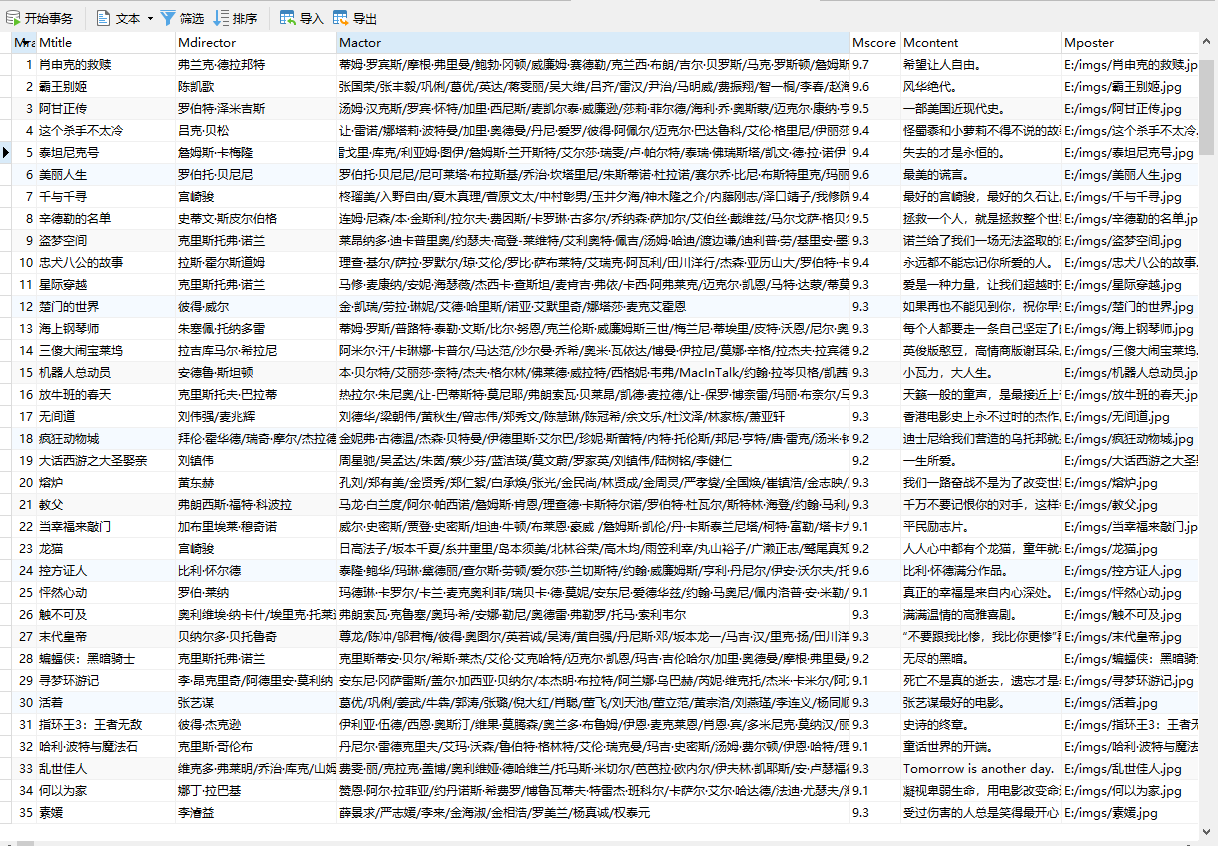
print("insert into doubanmovie_copy2 (Mrank,Mtitle,Mdirector,Mactor,Mscore,Mcontent,Mposter) values (%s,%s,%s,%s,%s,%s,%s)",
(item["rank"],item["title"], item['director'], item["actors"], item['score'], item['content'],str(picpath)))
if self.opened:
self.cursor.execute(
"insert into doubanmovie_copy2 (Mrank,Mtitle,Mdirector,Mactor,Mscore,Mcontent,Mposter) values (%s,%s,%s,%s,%s,%s,%s)",
(item["rank"],item["title"], item['director'], item["actors"], item['score'], item['content'],str(picpath)))
在插入数据库时遇到了一些困难:
(1)一开始插入时发现多条数据插入报错,原因是建表时varchar()字段设置的不够大,最后将几个较长的属性改为text格式解决
(2)插入Mrank是一开始设置插入%d字段报错,最后发现插入数据库时会自动修正对应的数据类型解决了。
(3)全部插入后发现缺少了第76和第137条数据,检查后发现是actors字段和content字段后含有单引号,最后改变values字段解决了
-4.编写run,运行
from scrapy import cmdline
cmdline.execute("scrapy crawl myspider -s LOG_ENABLED=True".split())
控制台输出如下:

图片爬取到文件夹中:
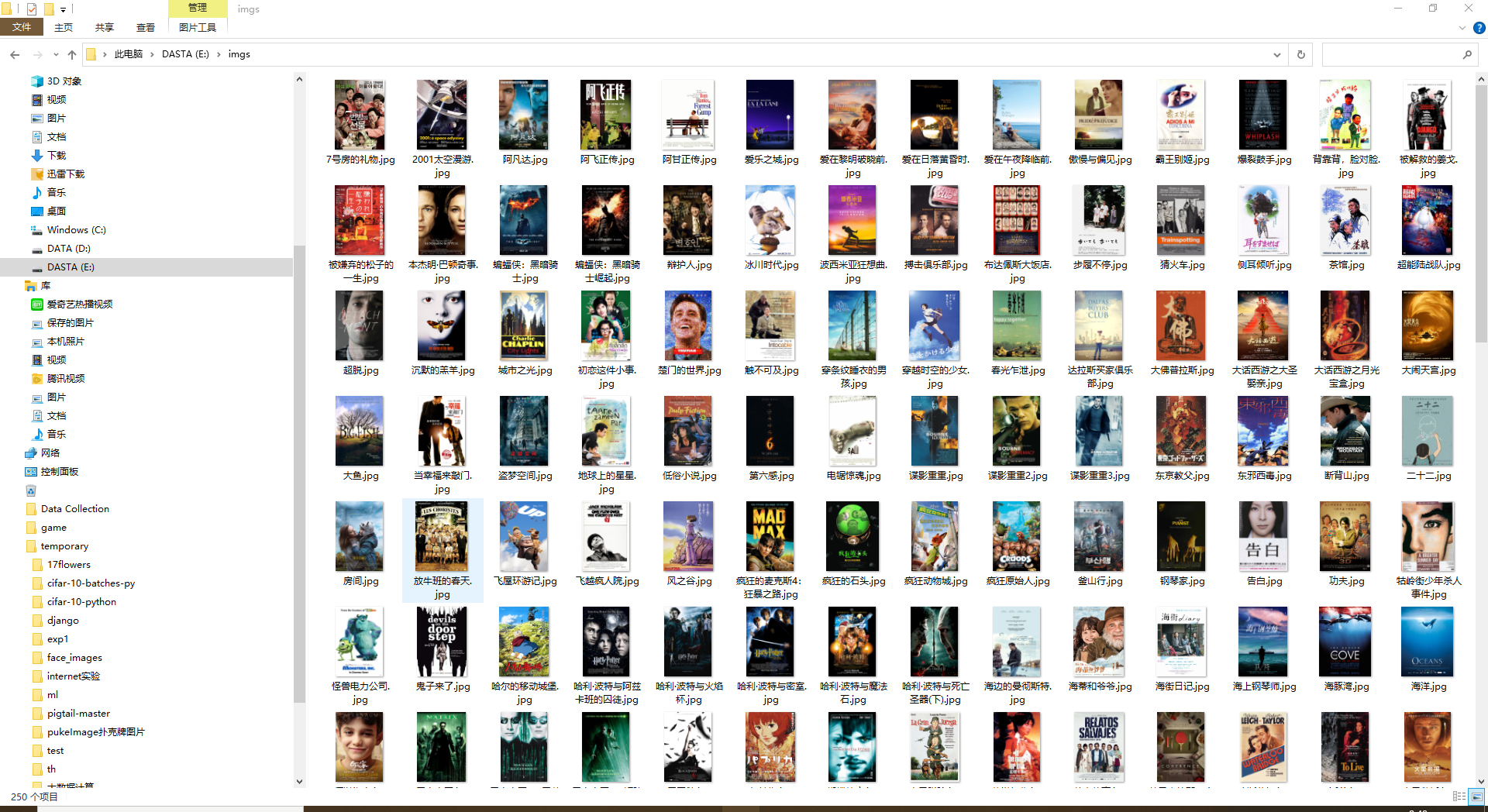
数据存入数据库中,在navicat查看:
全部数据爬取成功:
2)、心得体会
做作业3时为了爬取到完整的演员信息,需要爬取到每个电影的链接后再对链接进行解析。在解析网页的时候,除了没有指定编码格式爬取到乱码之外,没有遇到很大的困难,主要是卡在插入数据库这一块上,对于数据库的操作还不够熟练。因为需要多次调试,豆瓣经常检测到ip异常行为:

这次作业又比较特殊,需要爬取到页面中的link再进行解析,储存到本地来调试的方法行不通了,所以以后还是要将代码好好完善后再进行调试。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号