数据采集与融合 实验2
作业①:
- 要求:在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在
数据库。
- 输出信息:
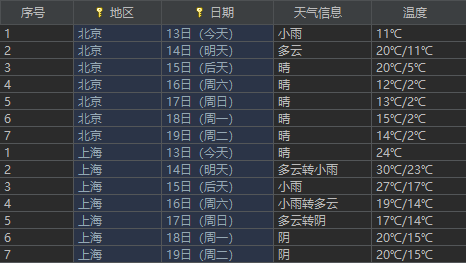
序号 地区 日期 天气信息 温度 1 北京 7日(今天) 晴间多云,北部山区有阵雨或雷阵雨转晴转多云 31℃/17℃ 2 北京 8日(明天) 多云转晴,北部地区有分阵雨或雷阵雨转晴 34℃/20℃ 3 北京 9日(后天) 晴转多云 36℃/22℃ 4.....
1)、中国气象网天气预报爬取
-1.新建一个weather类,在初始化函数中传入citycode,并编写函数采用urllib.request方法爬取html内容
初始化函数:
def __init__(self):
self.cityCode = {"北京": "101010100", "上海": "101020100"}
利用urllib爬取
def getHTMLTextUrllib(url):
try:
headers = {"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 10.0 x104; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
req=urllib.request.Request(url,headers=headers)
resp=urllib.request.urlopen(req)
data =resp.read()
unicodeData =data.decode()
return unicodeData
except:
return ""
# 使用urllib方法打开url并进行解码获取html内容
其中已经对data进行解码,方便后续处理
-2.检查待爬取网站的Html结点信息,在weather类中编写一个功能为爬取的函数利用BeautifulSoup查找出含所需数据的结点
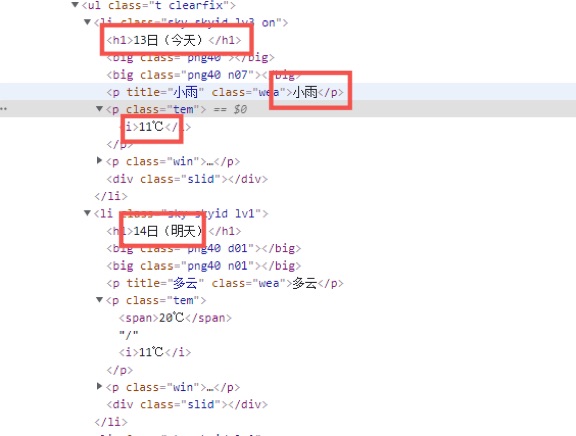
代码如下
soup = BeautifulSoup(html, "html.parser")
lis = soup.select("ul[class='t clearfix'] li")# 用BeautifulSoup方法遍历查找到包含数据的结点
datelist = []
for li in lis:
try:
date = li.select('h1')[0].text
weather = li.select('p[class="wea"]')[0].text
temp = li.select("p[class='tem']")[0].text.strip()
-3.编写WeatheDB类对数据库进行操作
-(1)其中插入数据和打印数据的函数如下
def insert(self, index, city, date, weather, temp):
try:
# 利用指针将数据插入数据库对应表中
self.cursor.execute("insert into weathers (序号,地区,日期,天气信息,温度) values (?,?,?,?,?)",
(index,city, date, weather, temp))
except Exception as err:
print(err)
def show(self):
# 打印表格
self.cursor.execute("select * from weathers")
rows = self.cursor.fetchall()
tplt = "{0:^10}\t{1:^10}\t{2:{5}^10}\t{3:{5}^10}\t{4:^20}"
print("{0:^8}\t{1:^12}\t{2:{5}^10}\t{3:{5}^18}\t{4:^1}".format("index","city", "date", "weather", "temp",chr(12288)))
for row in rows:
print(tplt.format(row[0],row[1],row[2],row[3],row[4],chr(12288)))
-4.在weather类中编写process类调用WeatherDB并调用函数进行爬取
def process(self,cities):
self.db = WeatherDB()# 创建数据库对象
self.db.openDB()# 打开数据库
for city in cities:
self.forecastCity(city)# 循环遍历,逐一爬取和存储天气预报数据
self.db.show()# 打印数据库中数据
self.db.closeDB()
最后在数据库中查看表格 结果如下:
2)、心得体会
作业1较为简单,需要提取的信息很清晰,在老师给的代码的基础上进行一些修改即可。心得;主要是熟悉了对数据库的使用
作业②:
-
要求:用requests和自选提取信息方法定向爬取股票相关信息,并存储在数据库中。
-
候选网站:
东方财富网:https://www.eastmoney.com/
新浪股票:http://finance.sina.com.cn/stock/ -
输出信息:
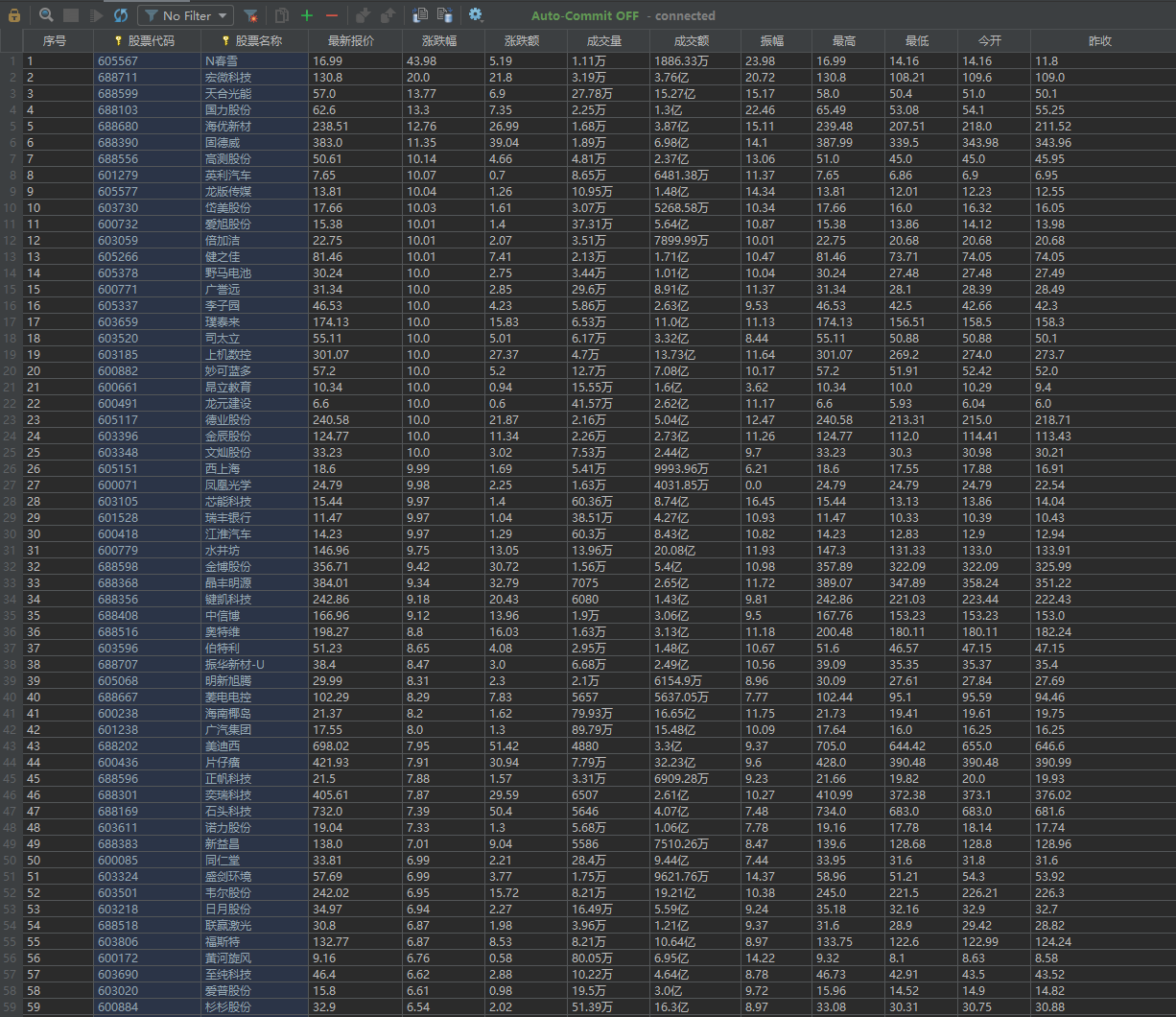
序号 股票代码 股票名称 最新报价 涨跌幅 涨跌额 成交量 成交额 振幅 最高 最低 今开 昨收 1 688093 N世华 28.47 62.22% 10.92 26.13万 7.6亿 22.3% 32.0 28.08 30.2 17.55 2.....
1)、股票信息爬取
-1.打开网页对需爬取的数据进行检查,发现页面上的数据并不是table格式,在源代码中搜索想要的数据并不能直接找到。
所以检查页面,进行抓包分析

如图,在该url中发现需爬取的数据
-2.在header中提取url,新建一个stock类,在其中编写函数用requests库获取html信息
# requests获取url的html代码信息
def gethtml(page):
url = "http://18.push2.eastmoney.com/api/qt/clist/get?" \
"cb=jQuery112406262007410118722_1634103430542" \
"&pn="+str(page)+"&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&" \
"invt=2&fid=f3&fs=m:1+t:2,m:1+t:23&fields" \
"=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17" \
",f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1634103430613"
r = requests.get(url)
return r.content
-3.在Stock类中编写爬取函数利用json方法,对数据进行提取
-3.1将提取出的html内容解码后设置正则表达式将解码后的data的括号外内容去除,提取出json字符串
pat = "jQuery112406262007410118722_1634103430542\((.*?)\)"
str1 = re.compile(pat,re.S).findall(str)[0]
将json字符串转为对象后利用jsonpath查找出diff下所有object,即包含所需数据的各个结点,存入列表
jsondata = json.loads(str1)# 将json字符串转化为python对象
list = jsonpath.jsonpath(jsondata,'$.data.diff.')[0]
-3.2定义函数,将过大的值转换为以“亿”或“万”结尾
def formatCorrect(self,num):
if num > 100000000:
num = round(num / 100000000, 2)
num = str(num) + '亿'
elif num > 10000:
num = round(num / 10000, 2)
num = str(num) + '万'
return num
再定义flag函数对翻页的序号进行处理
def flag(self,page):
if page == 1:
return 0
else:
return 20*(page-1)
-4.编写StockDB类,操作数据库
其中插入数据库函数如下
def insert(self,index,code, name, new, uad, uadp, da, dp, s, he, le, t, y):
# 设置需插入表中的变量
try:
self.cursor.execute("insert into stocks (序号,股票代码, 股票名称, 最新报价, 涨跌幅,"
"涨跌额, 成交量, 成交额, 振幅, 最高, 最低, 今开, 昨收) values (?,?,?,?,?,?,?,?,?,?,?,?,?)",
(index, code, name, new, uad, uadp, da, dp, s, he, le, t, y))# f12 f14 f2 f3 f4 f5 f6 f7 f15 f16 f17 f18
except Exception as err:
print(err)
-5.最后在爬取方法中遍历列表,插入数据,并编写process函数对数据库进行调用
for i in range(len(list)):
index = i+1+self.flag(page)
code = jsonpath.jsonpath(list[i],"$.[f12]")[0]
name = jsonpath.jsonpath(list[i],"$.[f14]")[0]
new = jsonpath.jsonpath(list[i],"$.[f2]")[0]
uad = jsonpath.jsonpath(list[i],"$.[f3]")[0]
uadp = jsonpath.jsonpath(list[i],"$.[f4]")[0]
da = jsonpath.jsonpath(list[i],"$.[f5]")[0]
dp = jsonpath.jsonpath(list[i],"$.[f6]")[0]
s = jsonpath.jsonpath(list[i],"$.[f7]")[0]
he = jsonpath.jsonpath(list[i],"$.[f15]")[0]
le = jsonpath.jsonpath(list[i],"$.[f16]")[0]
t = jsonpath.jsonpath(list[i],"$.[f17]")[0]
y = jsonpath.jsonpath(list[i],"$.[f18]")[0]
dealamount = self.formatCorrect(da)
dealprice = self.formatCorrect(dp)
self.db.insert(index,code, name, new, uad, uadp, dealamount, dealprice, s, he, le, t, y)
process函数:
def process(self,pages):
self.db = StockDB()# 创建数据库对象
self.db.openDB()# 打开数据库
for i in range(1,pages+1):
self.getOnePageStock(i)# 循环遍历,逐一爬取和存储股票数据
# self.db.show()
self.db.closeDB()# 关闭数据库
结果如下:
2)、心得体会
在作业2上我花费了较多的时间,一开始的时候对f12不够熟悉,后来在匹配性要用以前的正则进行匹配,发现较为繁琐,最后在老师和曾庆聪同学的悉心指导下熟悉了json的使用,自己稍加摸索,很快就解决了问题。
心得:体会到了分析抓包的重要性,学习了json
作业③:
- 要求:爬取中国大学2021主榜(https://www.shanghairanking.cn/rankings/bcur/2021)
所有院校信息,并存储在数据库中,同时将浏览器F12调试分析的过程录制Gif加入至博客中。
- 输出信息:
排名 学校 总分 1 清华大学 969.2
1)、图片爬取
-1.F12查看网页抓包
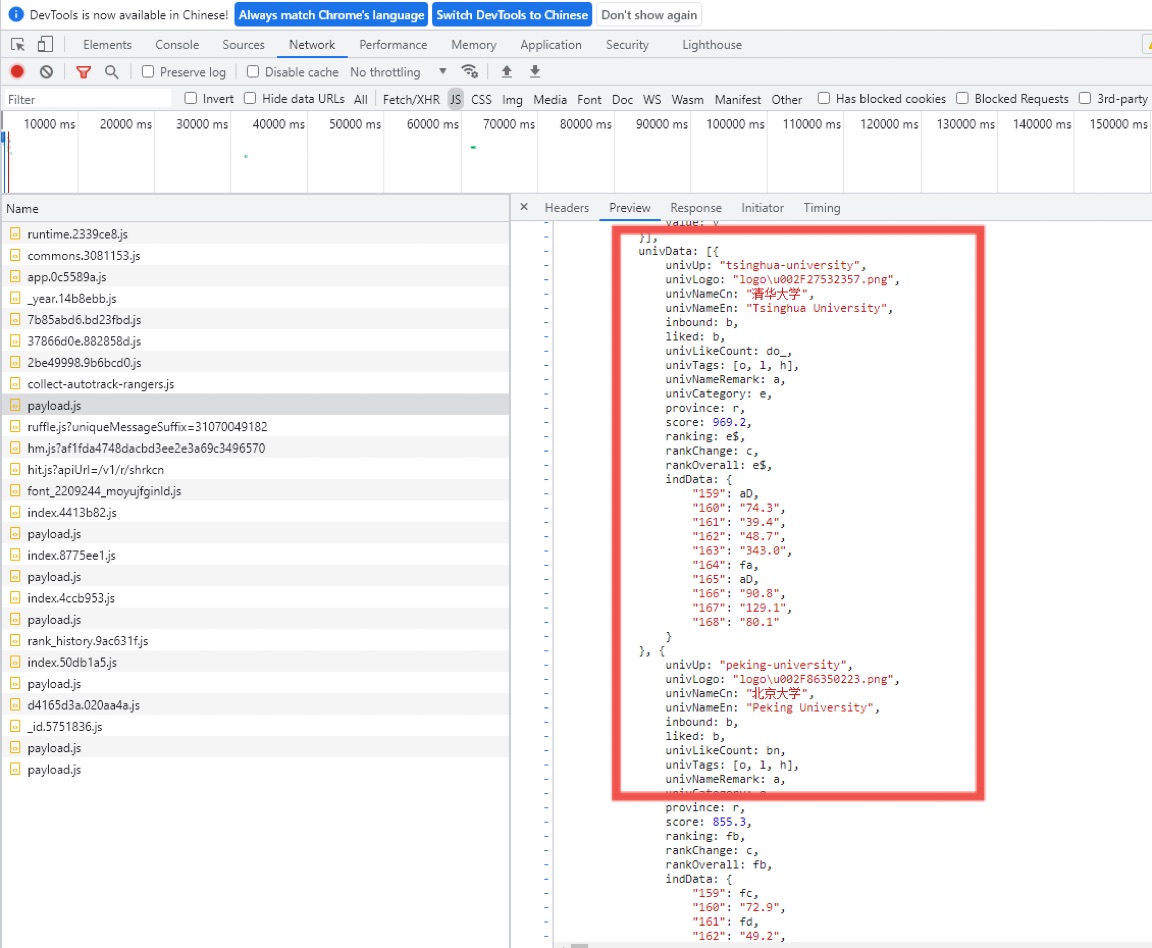
提出待爬取url

-2.新建一个college类,在其中编写一个简单的函数直接调用requests方法获取html的内容content
def gethtml(self):
url = "https://www.shanghairanking.cn/_nuxt/static/1632381606/rankings/bcur/2021/payload.js"
r = requests.get(url)
return r.content
-3.对第一步所查看的抓包中所包含的数据进行分析,然后用正则表达式提取出数据
其中三个属性正则表达式以及匹配部分代码如下
rankreg = r"ranking:(.*?),"
ranklist = re.compile(rankreg,re.S).findall(str)
dict1["h"] = 211
namereg = r"univNameCn:\"(.*?)\""
namelist = re.compile(namereg,re.S).findall(str)
scorereg = r"score:(.*?),"
scorelist = re.compile(scorereg,re.S).findall(str)
目前大致的框架已经写出来了,而对抓包的数据进行分析发现rank不会直接输出排名数据,score也有部分如此
如图:
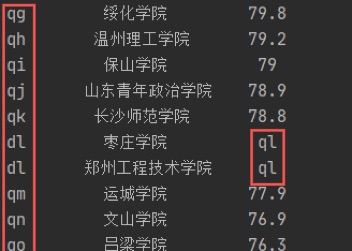
在分析了js的内容后发现头和尾有匹配出这些字母的键值对,所以再利用正则表达式提取出键和值存入字典
keyreg = r"function\((.*?)\)"
key = re.compile(keyreg,re.S).findall(str)[0].replace('"',"").split(",")
valuereg = r"\"\",(.*?)\)\)\)"
value = re.compile(valuereg,re.S).findall(str)[0].replace('"',"").split(",")
dict1 = dict(zip(key,value))
随后即可遍历各个列表进行插入数据库操作
for i in range(len(namelist)):
name = namelist[i]
rank = dict1[ranklist[i]]# 利用字典查找出对应的排名
score = scorelist[i]
# 判断score是否为数字字符串
if not self.is_number(score) :
# 若不是则需利用字典进行映射
score = dict1[score]
# 循环遍历插入数据
self.db.insert(rank,name,score)
其中is_number是在college类中判断score数据是否为数字字符串的函数:
def is_number(self,s):
try:
float(s)
return True
except ValueError:
pass
try:
import unicodedata
unicodedata.numeric(s)
return True
except (TypeError, ValueError):
pass
return False
这个函数是偷懒直接用了网上找的
最后输出时发现第rank的211名键值对应会出错

最后在创建完字典后直接赋值解决了
dict1["h"] = 211

-4.编写数据库类操作数据库
其中插入数据和输出数据函数代码如下
def insert(self, rank, name, score):
try:
# 利用指针将数据插入数据库对应表中
self.cursor.execute("insert into college (排名, 学校, 总分) values (?,?,?)",
(rank, name, score))
except Exception as err:
print(err)
def show(self):
# 打印表格
self.cursor.execute("select * from college")
rows = self.cursor.fetchall()
tplt = "{0:^10}\t{1:{3}^9}\t{2:^7}"
print("{0:^8}\t{1:^12}\t{2:^15}".format("排名", "学校", "总分", chr(12288)))
for row in rows:
print(tplt.format(row[0], row[1], row[2], chr(12288))
-5.最后在College类中编写process函数调用并操作数据库
process函数:
def process(self):
self.db = CollegeDB()# 创建数据库对象
self.db.openDB()# 打开数据库
self.gettable()# 调用函数插入数据
self.db.show()# 打印数据到控制台
self.db.closeDB()# 关闭数据库
最后控制台输出:
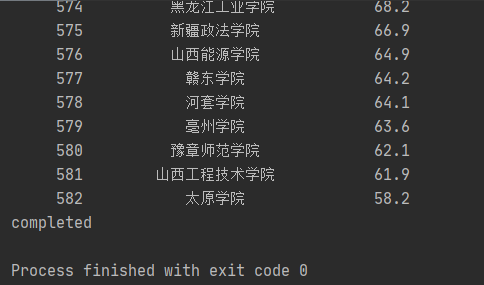
在数据库中查看结果如图:

作业3码云链接
解析抓包的gif:
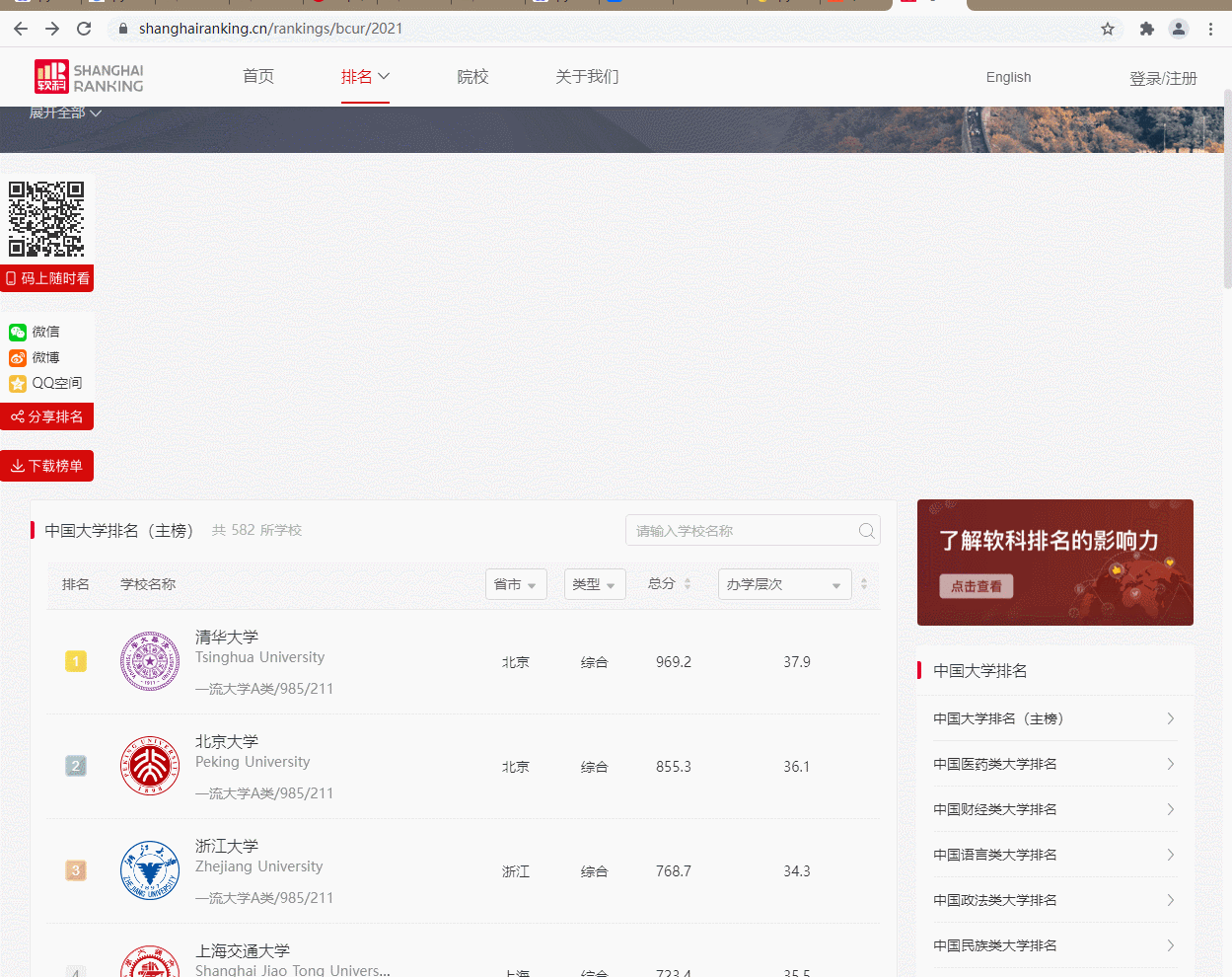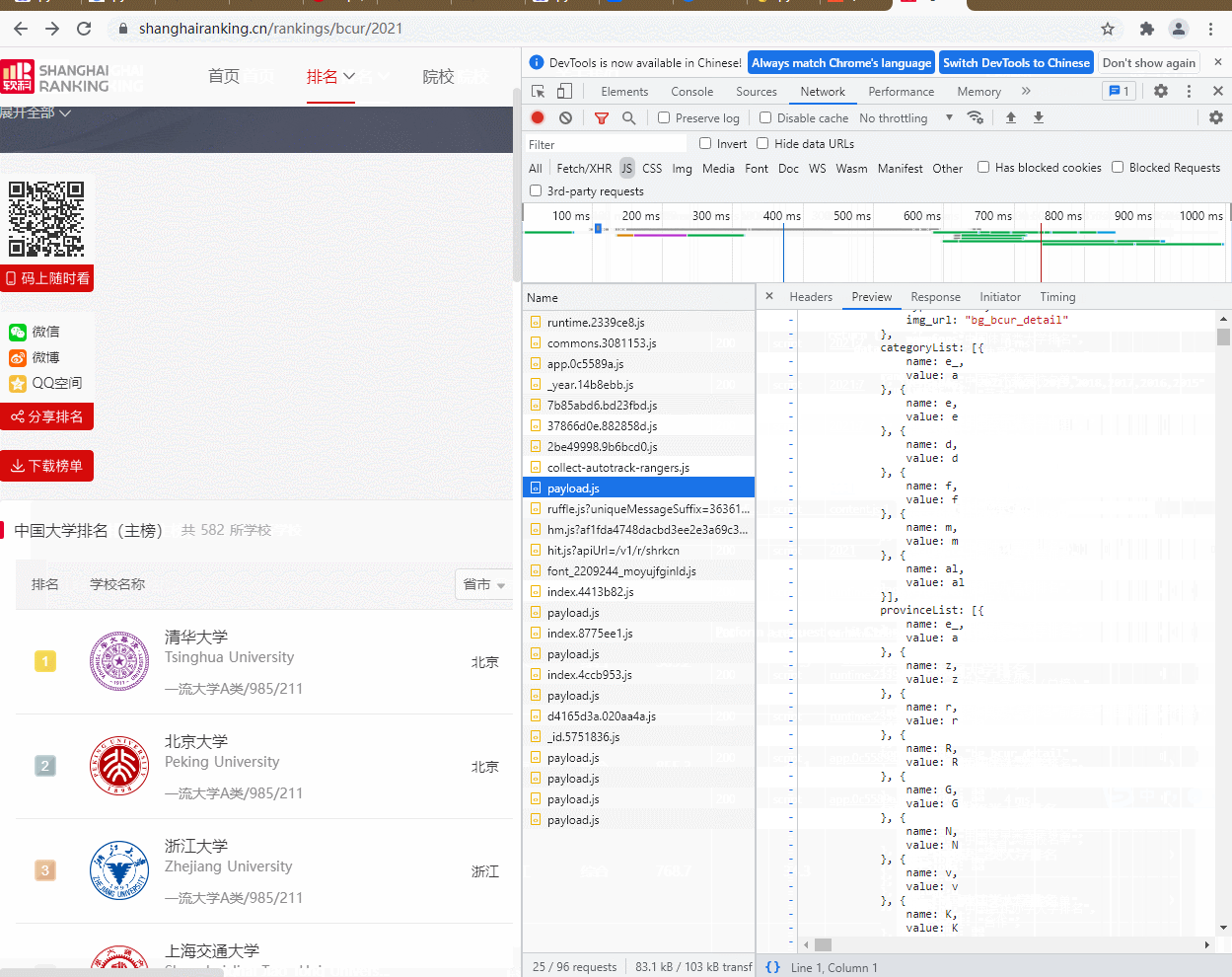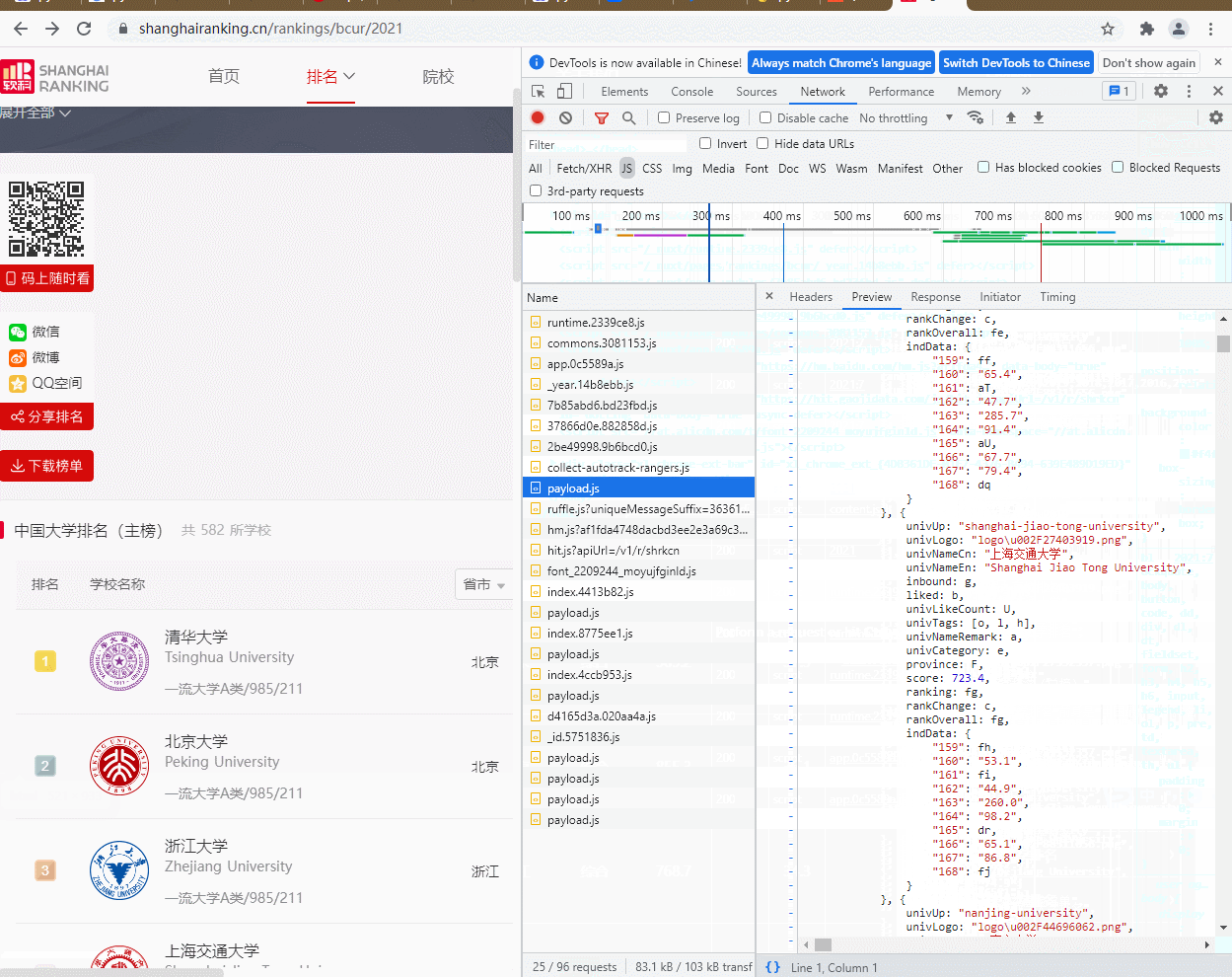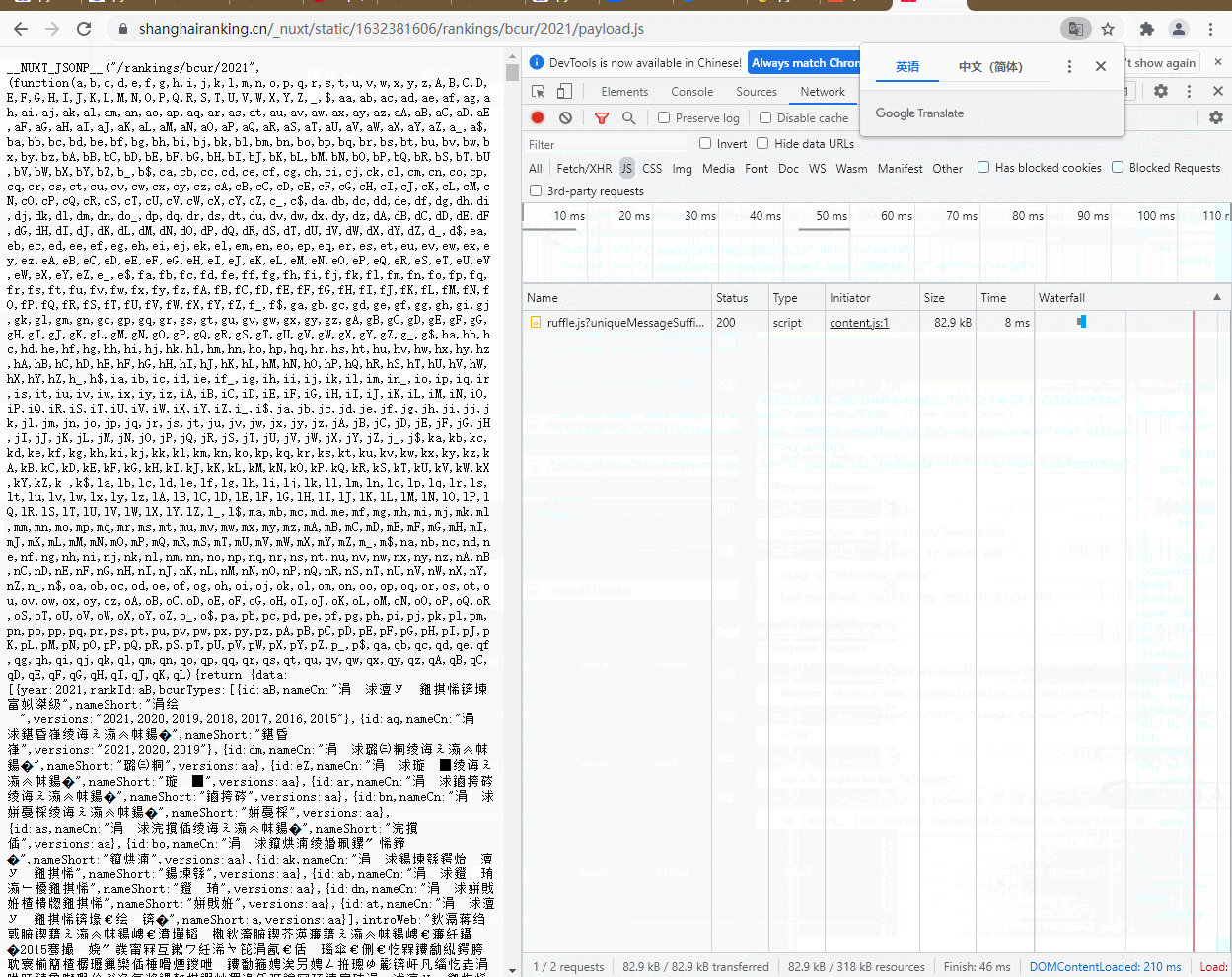
2)、心得体会
作业3的网页已经爬过许多次,这次是对其的抓包解析后爬取。最主要的还是利用正则表达式分析。而在其js中也包含了键值对,学习使用了利用字典匹配键值对。在其中调试的过程中也联系了对数据库的操作

 浙公网安备 33010602011771号
浙公网安备 33010602011771号