数据采集与融合技术 实验1
作业①:
-
要求:用urllib和re库方法定向爬取给定网址(https://www.shanghairanking.cn/rankings/bcsr/2020/0812 )的数据
-
输出信息:
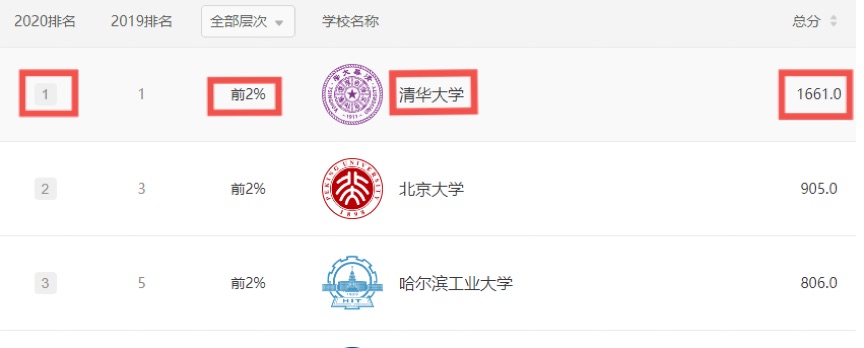
2020排名 全部层次 学校类型 总分 1 前2% 中国人民大学 1069.0 2......
1)、大学学科排名数据爬取
作业1码云链接
-1.打开网页对需要爬取的数据进行检查



-2.首先采用urllib.request方法爬取html内容
def getHTMLTextUrllib(url):
try:
headers = {"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 10.0 x104; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
req=urllib.request.Request(url,headers=headers)
resp=urllib.request.urlopen(req)
data =resp.read()
unicodeData =data.decode()
return unicodeData
except:
return ""
# 使用urllib方法打开url并进行解码获取html内容
-3.对第一步查看到的结点写出所匹配的正则表达式,并进行初步的匹配和检查,进行修改
以下是最终的代码
list = re.findall(r'<td data-v-68e330ae>\n.*?\n.*?',html)# 用正则表达式获取td结点的内容
levellist = []
scorelist = []
for i in range(0,len(list),2):# 层次数据包含在列表中的偶数位置
levellist.append(re.findall(r'前\d+%', list[i])[0])
for i in range(1,len(list),2):# 总分数据包含在列表中的奇数位置
scorelist.append(re.findall(r'\d+\.\d', list[i])[0])
namelist = re.findall(r'"name-cn" data-v-b80b4d60.*?>(.*?) </a>',html)
-4.对先前作业所使用的printUniList函数进行修改后输出
def printUnivList(ulist, num):
#中西文混排时,要使用中文字符空格填充chr(12288)
tplt = "{0:^10}\t{1:{4}^10}\t{2:{4}^10}\t{3:^12}"
print("{0:^9}\t{1:^10}\t{2:{4}^14}\t{3:^2}".format("2020排名", "全部层次", "学校名称", "总分",chr(12288)))
for i in range(num):
print(tplt.format(i+1, levellist[i], namelist[i], scorelist[i],chr(12288)))
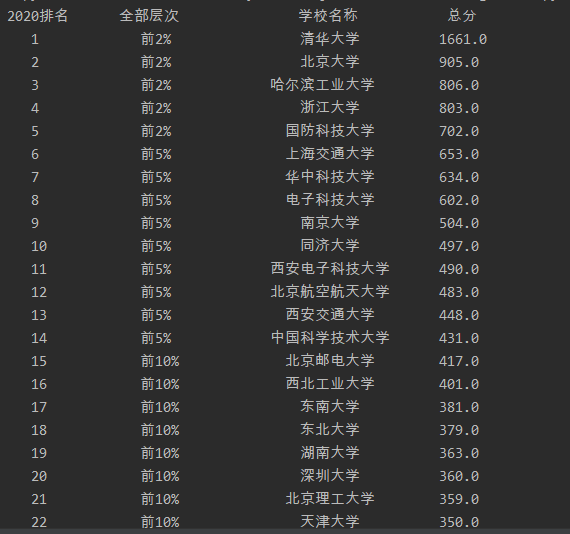
结果如下:
2)、心得体会
作业1其实是要求利用re库对先前的作业进行复现,之前作业所用的是BeautifulSoup库,较为简练;而使用re库进行匹配时需要不断编写和测试自己写的正则表达式,目前对正则表达式还是不够熟练,在这一题上花费了较多的时间,还需要多加练习
作业②:
-
要求:用requests和Beautiful Soup库方法设计爬取https://datacenter.mee.gov.cn/aqiweb2/ AQI实时报。
-
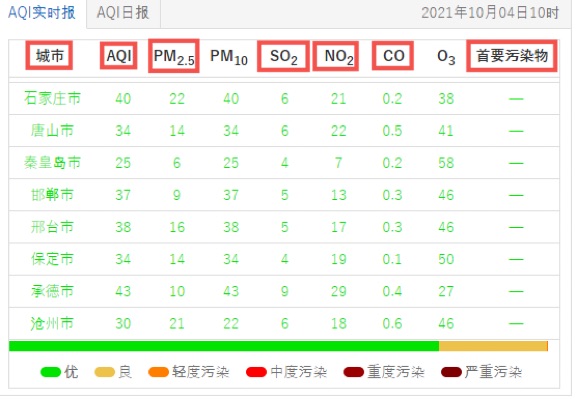
输出信息:
序号 城市 AQI PM2.5 SO2 NO2 CO2 首要污染物 1 北京 55 6 5 1.0 255 —— 2......
1)、AQI实时报爬取
作业2码云链接
-1.打开网页对需爬取的数据进行检查

-2.用requests库获取html信息
# requests获取url的html代码信息
import requests
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r
except:
return ""
-3.分析第一步所查看的结点,对tbody的子结点进行遍历
for tr in soup.find('tbody').children:# 遍历tbody的子结点
if isinstance(tr, bs4.element.Tag):# 需提取的内容均在tr结点当中,进行遍历
for td in tr.children:
tds = td.text.strip()
if (tds != ''):# 若文本内容非空则存入列表
ulist.append(tds)
最后将列表中对应位置的数据存入结果列表
for i in range(0,len(ulist),9):
res.append([ulist[i], ulist[i+1], ulist[i+2], ulist[i+4],ulist[i+5],ulist[i+6],ulist[i+8]])# 检查列表后将相应位置的内容存入结果列表
-4.改写print函数后进行输出
def printUnivList(res,num):
tplt = "{0:^4}\t{1:{8}^4}\t{2:{8}^5}\t{3:{8}^4}\t{4:{8}^5}\t{5:{8}^5}\t{6:{8}^4}\t{7:{8}^4}"
print(tplt.format("序号", "城市", "AQI", "PM2.5", "SO2","NO2","CO","首要污染物",chr(12288)))
for i in range(num):
u = res[i]
print("{0:^4}\t{1:{8}^4}\t{2:{8}^4}\t{3:{8}^4}\t{4:{8}^4}\t{5:{8}^4}\t{6:{8}^4}\t{7:{8}^4}".format(i+1,u[0], u[1], u[2], u[3], u[4],u[5],u[6],chr(12288)))
结果如下:

2)、心得体会
这个作业要求用bs方法进行爬取,而该网站的html内容中需爬取的部分也较为简洁,实现起来不难,其中对tr的子结点进行遍历时出现了一些空的内容,最后加入了判断解决。
作业③:
- 要求:使用urllib和requests爬取(http://news.fzu.edu.cn/) ,并爬取该网站下的所有图片
- 输出信息:将网页内的所有图片文件保存在一个文件夹中
1)、图片爬取
作业3码云链接
-1.首先对网页中的图片进行检查

-2.同第2步调用requests方法获取html内容
-3.利用soup.select,找到所有img结点并利用正则表达式提取src地址
获取img结点
images = soup.select("a")
for i in images:
im = i.find("img")
if (im != None):
imglist.append(im)
遍历列表匹配出src地址
img_url_pattern = r'.+?src="(\S+)"'# 设定正则表达式
for i in imglist:
res = re.findall(img_url_pattern, str(i))[0]# 用正则表达式匹配出包含src地址的结点
if (str(res).endswith("jpg")|str(res).endswith("png")):# 进行判断提取出以.png和.jpg结尾的地址
srclist.append(res)
-4.遍历储存src地址的列表进行下载
for i in range(0,len(srclist)):
address = srclist[i]
downloadurl = "http://news.fzu.edu.cn"+address
file = "C:/Users/86180/Desktop/Data Collection/pics/"+" pic no."+str(i+1)+".jpg"
urllib.request.urlretrieve(downloadurl,filename=file)
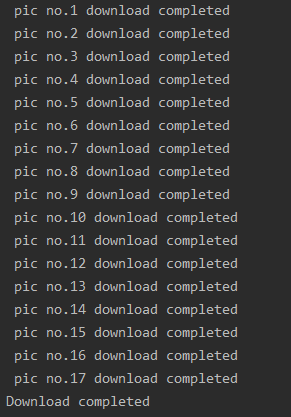
print(" pic no."+str(i+1)+" download completed")
其中过滤了.gif动图文件
最后得到结果:

2)、心得体会
作业3和上次要求爬取书包图片的作业较为类似,稍作修改即可。其中不同的地方是此次网页的下载地址前缀与上次不同,需要加上网址。网页中包含的图片包括png、jpg和动图gif,种类更为多样,可选择所需的进行提取。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号