
大数据概论
Q1:列举Hadoop生态的各个组件及其功能、以及各个组件之间的相互关系,以图呈现并加以文字描述。
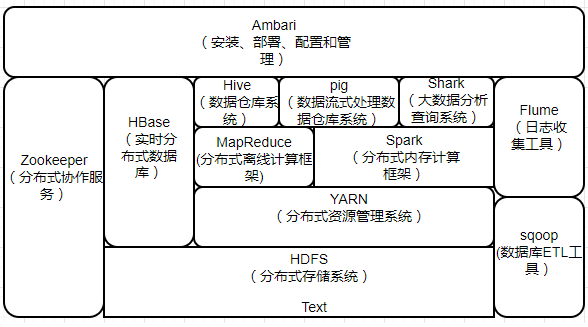
Hadoop生态的主要的核心组件有HDFS和MapReduce,其他还包括ZooKeeper、HBase、Hive、Pig、Mahout、Sqoop、Flume、Ambari等功能组件
HDFS:HDFS具有很好的容错能力,并且兼容廉价的硬件设备,因此,可以以较低的成本利用现有机器实现大流量和大数据量的读写。
MapReduce:一种分布式并行编程模型,用于大规模数据集(大于1TB)的并行运算,它将复杂的、运行于大规模集群上的并行计算过程高度抽象到两个函数:Map和Reduce。
ZooKeeper:解决分布式环境下的数据管理问题:统一命名,状态同步,集群管理,配置同步等。
HBase:针对结构化数据的可伸缩,高可靠,高性能,分布式和面向列的动态模式数据库。hbase中保存的数据可以使用mapreduce来处理,它将数据存储和并行计算完美结合在一起。
Hive:hive定于了一种类似sql的查询语言(hql)将sql转化为mapreduce任务在hadoop上执行。
Pig:定义了一种数据流语言-pig latin,将脚本转换为mapreduce任务在hadoop上执行。通常用于离线分析。
Sqoop:主要用于传统数据库和hadoop之间传输数据。数据的导入和导出本质上是mapreduce程序,充分利用了MR的并行化和容错性。
Flume:cloudera开源的日志收集系统,具有分布式,高可靠,高容错,易于定制和扩展的特点。
Q2:对比Hadoop与Spark的优缺点。
优点:
① Spark对标于Hadoop中的计算模块MR,但是速度和效率比MR要快得多
② Spark可以使用基于HDFS的HBase数据库,也可以使用HDFS的数据文件,还可以通过jdbc连接使用Mysql数据库数据;Spark可以对数据库数据进行修改删除,而HDFS只能对数据进行追加和全表删除
③ Hadoop中中间结果存放在HDFS中,每次MR都需要刷写-调用,而Spark中间结果存放优先存放在内存中,内存不够再存放在磁盘中,不放入HDFS,避免了大量的IO和刷写读取操作;
缺点:
Spark没有提供文件管理系统,所以,它必须和其他的分布式文件系统进行集成才能运作,它只是一个计算分析框架,专门用来对分布式存储的数据进行计算处理,它本身并不能存储数据
Q3:如何实现Hadoop与Spark的统一部署?
Spark可运行于YARN之上,与Hadoop进行统一部署,即“Spark on YARN”,资源管理和调度依赖YARN,分布式存储则依赖HDFS。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号