spark环境搭建
spark环境搭建
spark下载地址:http://archive.apache.org/dist/spark/
Scala下载地址:https://scala-lang.org/download/2.11.8.html
这里的spark版本用的是:spark-2.4.0-bin-hadoop2.6.tgz
这里的Scala用的是:scala-2.11.8.tgz
1. 安装Scala
1.1 上传解压Scala
(1) 上传安装包scala-2.11.8.tgz到虚拟机中
(2) 进入上传的安装包目录,解压sqoop安装包到指定目录,如:
tar -zxvf scala-2.11.8.tgz -C /opt/module/
解压后,进入解压后的目录把名字修改为sqoop
mv scala-2.11.8 scala
1.2 设置Scala环境变量
命令:
vi /root/.bash_profile
加入下面内容:
export SCALA_HOME=/opt/module/scala
export PATH=$PATH:$SCALA_HOME/bin
使设置立即生效:
source /root/.bash_profile
验证scala
scala -version
2. 安装spark
2.1 上传解压spark
(1) 上传安装包spark-2.4.0-bin-hadoop2.6.tgz到虚拟机中
(2) 进入上传的安装包目录,解压sqoop安装包到指定目录,如:
tar -zxvf spark-2.4.0-bin-hadoop2.6.tgz -C /opt/module/
解压后,进入解压后的目录把名字修改为sqoop
mv spark-2.4.0-bin-hadoop2.6 spark
2.2 设置spark环境变量
命令:
vi /root/.bash_profile
加入下面内容:
export SPARK_HOME=/opt/module/spark
export PATH=$PATH:$SPARK_HOME/bin
export PATH=$PATH:$SPARK_HOME/sbin
使设置立即生效:
source /root/.bash_profile
2.3 修改配置文件
(1)把/opt/module/spark/conf/下的spark-env.sh.template文件修改为spark-env.sh
[root@master conf]# mv spark-env.sh.template spark-env.sh
(2)修改spark-env.sh配置文件
命令:
vi spark-env.sh
添加如下内容:
export JAVA_HOME=/opt/module/jdk1.8.0_281
export HADOOP_CONF_DIR=/opt/module/hadoop/etc/hadoop
export SPARK_MASTER_HOST=master
export SPARK_MASTER_PORT=7077
export SPARK_WORKER_CORES=1
export SPARK_WORKER_MEMORY=1g
export SPARK_DIST_CLASSPATH=$(/opt/module/hadoop/bin/hadoop classpath)
export SPARK_MASTER_IP=192.168.1.110
(3) 修改slaves配置文件,添加Worker的主机列表
把/opt/module/spark/conf/下的slaves.template文件修改为slaves
[root@master conf]# mv slaves.template slaves
修改slaves文件
命令:
vi slaves
添加如下内容:
# 里面的内容原来为localhost,添加自己有的几个节点
master
slave01
slave02
(4) 把/opt/module/spark/sbin下的start-all.sh和stop-all.sh这两个文件重命名
[root@master sbin]# mv start-all.sh start-spark-all.sh
[root@master sbin]# mv stop-all.sh stop-spark-all.sh
3. 分发到其他节点
(1)把Scala分发给其他节点
slave01节点:
scp -r /opt/module/scala/ root@slave01:/opt/module/scala/
slave02节点:
scp -r /opt/module/scala/ root@slave02:/opt/module/scala/
(2)把spark分发给其他节点
slave01节点:
scp -r /opt/module/spark/ root@slave01:/opt/module/spark/
slave02节点:
scp -r /opt/module/spark/ root@slave02:/opt/module/spark/
(3)把环境变量分发到其他节点
slave01节点:
rsync -av /root/.bash_profile root@slave01:/root/.bash_profile
slave02节点:
rsync -av /root/.bash_profile root@slave02:/root/.bash_profile
4. 启动spark集群
在spark master节点启动spark集群
[root@master spark]# sbin/start-spark-all.sh
master节点如图所示:
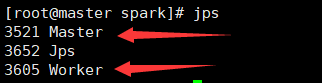
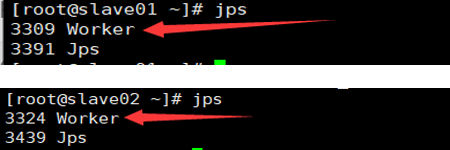
slave01、slave02节点如图所示:
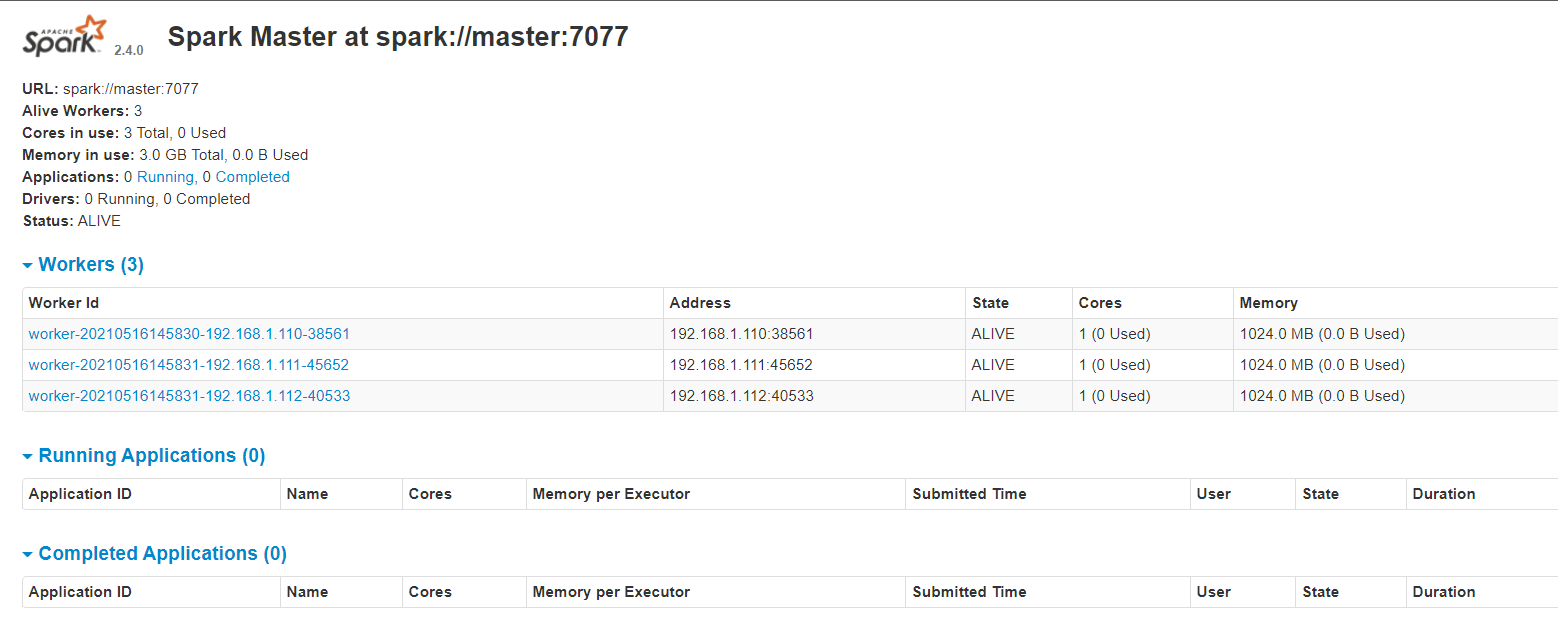
查看webUI:
在网页上输入网址:http://192.168.1.110:8080/
如图所示:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号