切片声明 切片在内存中的组织方式 reslice
小结:
3、
2、
type User struct {
Age int
Name string
}
func run() {
var users = []User{
{Age: 10, Name: "abc" },
{Age: 60, Name: "def" },
}
for k, v := range users {
if v.Age < 20 {
users[k].Age = 30
}
}
print()
}
func run1() {
var users = []User{
{Age: 10, Name: "abc" },
{Age: 60, Name: "def" },
}
for k, v := range users {
if v.Age < 70 {
users[k].Age = 70
}
}
}
1、
在业务代码中的使用
func combinationSum(candidates []int, target int) (ans [][]int) {
comb := []int{}
var dfs func(target, idx int)
dfs = func(target, idx int) {
if idx == len(candidates) {
return
}
if target == 0 {
ans = append(ans, append([]int(nil), comb...))
return
}
// 直接跳过
dfs(target, idx+1)
// 选择当前数
if target-candidates[idx] >= 0 {
comb = append(comb, candidates[idx])
dfs(target-candidates[idx], idx)
comb = comb[:len(comb)-1]
}
}
dfs(target, 0)
return
}组合总和 - 组合总和 - 力扣(LeetCode) https://leetcode.cn/problems/combination-sum/solution/zu-he-zong-he-by-leetcode-solution/
Go 语言切片面试真题 8 连问 https://mp.weixin.qq.com/s/h4pQcLADBav2ig5TmHrbcg
01. 数组和切片有什么区别?
Go语言中数组是固定长度的,不能动态扩容,在编译期就会确定大小,声明方式如下:
var buffer [255]int
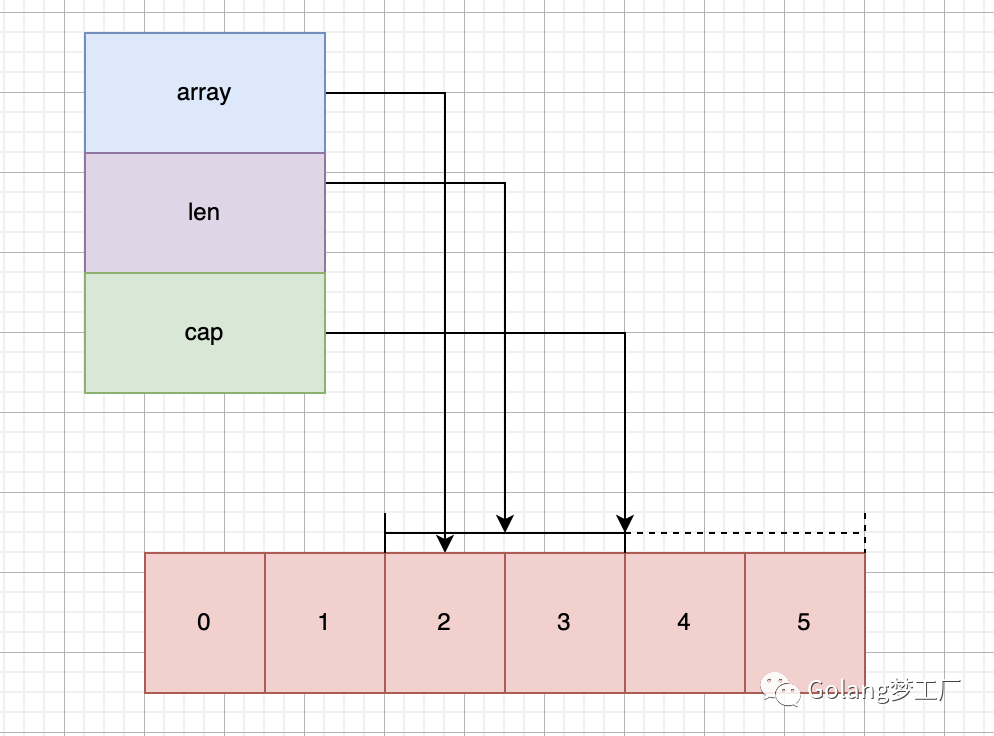
buffer := [255]int{0}切片是对数组的抽象,因为数组的长度是不可变的,在某些场景下使用起来就不是很方便,所以Go语言提供了一种灵活,功能强悍的内置类型切片("动态数组"),与数组相比切片的长度是不固定的,可以追加元素。切片是一种数据结构,切片不是数组,切片描述的是一块数组,切片结构如下:
我们可以直接声明一个未指定大小的数组来定义切片,也可以使用make()函数来创建切片,声明方式如下:
var slice []int // 直接声明
slice := []int{1,2,3,4,5} // 字面量方式
slice := make([]int, 5, 10) // make创建
slice := array[1:5] // 截取下标的方式
slice := *new([]int) // new一个切片可以使用append追加元素,当cap不足时进行动态扩容。
02. 拷贝大切片一定比拷贝小切片代价大吗?
这道题比较有意思,原文地址:Are large slices more expensive than smaller ones?
这道题本质是考察对切片本质的理解,Go语言中只有值传递,所以我们以传递切片为例子:
func main() {
param1 := make([]int, 100)
param2 := make([]int, 100000000)
smallSlice(param1)
largeSlice(param2)
}
func smallSlice(params []int) {
// ....
}
func largeSlice(params []int) {
// ....
}切片param2要比param1大1000000个数量级,在进行值拷贝的时候,是否需要更昂贵的操作呢?
实际上不会,因为切片本质内部结构如下:
type SliceHeader struct {
Data uintptr
Len int
Cap int
}切片中的第一个字是指向切片底层数组的指针,这是切片的存储空间,第二个字段是切片的长度,第三个字段是容量。将一个切片变量分配给另一个变量只会复制三个机器字,大切片跟小切片的区别无非就是 Len 和 Cap的值比小切片的这两个值大一些,如果发生拷贝,本质上就是拷贝上面的三个字段。
03. 切片的深浅拷贝
深浅拷贝都是进行复制,区别在于复制出来的新对象与原来的对象在它们发生改变时,是否会相互影响,本质区别就是复制出来的对象与原对象是否会指向同一个地址。在Go语言,切片拷贝有三种方式:
- 使用
=操作符拷贝切片,这种就是浅拷贝 - 使用
[:]下标的方式复制切片,这种也是浅拷贝 - 使用
Go语言的内置函数copy()进行切片拷贝,这种就是深拷贝,
04. 零切片、空切片、nil切片是什么
为什么问题中这么多种切片呢?因为在Go语言中切片的创建方式有五种,不同方式创建出来的切片也不一样;
- 零切片
我们把切片内部数组的元素都是零值或者底层数组的内容就全是 nil的切片叫做零切片,使用make创建的、长度、容量都不为0的切片就是零值切片:
slice := make([]int,5) // 0 0 0 0 0
slice := make([]*int,5) // nil nil nil nil nilnil切片
nil切片的长度和容量都为0,并且和nil比较的结果为true,采用直接创建切片的方式、new创建切片的方式都可以创建nil切片:
var slice []int
var slice = *new([]int)- 空切片
空切片的长度和容量也都为0,但是和nil的比较结果为false,因为所有的空切片的数据指针都指向同一个地址 0xc42003bda0;使用字面量、make可以创建空切片:
var slice = []int{}
var slice = make([]int, 0)空切片指向的 zerobase 内存地址是一个神奇的地址,从 Go 语言的源代码中可以看到它的定义:
// base address for all 0-byte allocations
var zerobase uintptr
// 分配对象内存
func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer {
...
if size == 0 {
return unsafe.Pointer(&zerobase)
}
...
}05. 切片的扩容策略
这个问题是一个高频考点,我们通过源码来解析一下切片的扩容策略,切片的扩容都是调用growslice方法,截取部分重要源代码:
// runtime/slice.go
// et:表示slice的一个元素;old:表示旧的slice;cap:表示新切片需要的容量;
func growslice(et *_type, old slice, cap int) slice {
if cap < old.cap {
panic(errorString("growslice: cap out of range"))
}
if et.size == 0 {
// append should not create a slice with nil pointer but non-zero len.
// We assume that append doesn't need to preserve old.array in this case.
return slice{unsafe.Pointer(&zerobase), old.len, cap}
}
newcap := old.cap
// 两倍扩容
doublecap := newcap + newcap
// 新切片需要的容量大于两倍扩容的容量,则直接按照新切片需要的容量扩容
if cap > doublecap {
newcap = cap
} else {
// 原 slice 容量小于 1024 的时候,新 slice 容量按2倍扩容
if old.cap < 1024 {
newcap = doublecap
} else { // 原 slice 容量超过 1024,新 slice 容量变成原来的1.25倍。
// Check 0 < newcap to detect overflow
// and prevent an infinite loop.
for 0 < newcap && newcap < cap {
newcap += newcap / 4
}
// Set newcap to the requested cap when
// the newcap calculation overflowed.
if newcap <= 0 {
newcap = cap
}
}
}
// 后半部分还对 newcap 作了一个内存对齐,这个和内存分配策略相关。进行内存对齐之后,新 slice 的容量是要 大于等于 老 slice 容量的 2倍或者1.25倍。
var overflow bool
var lenmem, newlenmem, capmem uintptr
// Specialize for common values of et.size.
// For 1 we don't need any division/multiplication.
// For sys.PtrSize, compiler will optimize division/multiplication into a shift by a constant.
// For powers of 2, use a variable shift.
switch {
case et.size == 1:
lenmem = uintptr(old.len)
newlenmem = uintptr(cap)
capmem = roundupsize(uintptr(newcap))
overflow = uintptr(newcap) > maxAlloc
newcap = int(capmem)
case et.size == sys.PtrSize:
lenmem = uintptr(old.len) * sys.PtrSize
newlenmem = uintptr(cap) * sys.PtrSize
capmem = roundupsize(uintptr(newcap) * sys.PtrSize)
overflow = uintptr(newcap) > maxAlloc/sys.PtrSize
newcap = int(capmem / sys.PtrSize)
case isPowerOfTwo(et.size):
var shift uintptr
if sys.PtrSize == 8 {
// Mask shift for better code generation.
shift = uintptr(sys.Ctz64(uint64(et.size))) & 63
} else {
shift = uintptr(sys.Ctz32(uint32(et.size))) & 31
}
lenmem = uintptr(old.len) << shift
newlenmem = uintptr(cap) << shift
capmem = roundupsize(uintptr(newcap) << shift)
overflow = uintptr(newcap) > (maxAlloc >> shift)
newcap = int(capmem >> shift)
default:
lenmem = uintptr(old.len) * et.size
newlenmem = uintptr(cap) * et.size
capmem, overflow = math.MulUintptr(et.size, uintptr(newcap))
capmem = roundupsize(capmem)
newcap = int(capmem / et.size)
}
}通过源代码可以总结切片扩容策略:
切片在扩容时会进行内存对齐,这个和内存分配策略相关。进行内存对齐之后,新 slice 的容量是要 大于等于老
slice容量的2倍或者1.25倍,当原slice容量小于1024的时候,新slice容量变成原来的2倍;原slice容量超过1024,新slice容量变成原来的1.25倍。
07. 参数传递切片和切片指针有什么区别?
我们都知道切片底层就是一个结构体,里面有三个元素:
type SliceHeader struct {
Data uintptr
Len int
Cap int
}分别表示切片底层数据的地址,切片长度,切片容量。
当切片作为参数传递时,其实就是一个结构体的传递,因为Go语言参数传递只有值传递,传递一个切片就会浅拷贝原切片,但因为底层数据的地址没有变,所以在函数内对切片的修改,也将会影响到函数外的切片,举例:
func modifySlice(s []string) {
s[0] = "song"
s[1] = "Golang"
fmt.Println("out slice: ", s)
}
func main() {
s := []string{"asong", "Golang梦工厂"}
modifySlice(s)
fmt.Println("inner slice: ", s)
}
// 运行结果
out slice: [song Golang]
inner slice: [song Golang]不过这也有一个特例,先看一个例子:
func appendSlice(s []string) {
s = append(s, "快关注!!")
fmt.Println("out slice: ", s)
}
func main() {
s := []string{"asong", "Golang梦工厂"}
appendSlice(s)
fmt.Println("inner slice: ", s)
}
// 运行结果
out slice: [asong Golang梦工厂 快关注!!]
inner slice: [asong Golang梦工厂]因为切片发生了扩容,函数外的切片指向了一个新的底层数组,所以函数内外不会相互影响,因此可以得出一个结论,当参数直接传递切片时,如果指向底层数组的指针被覆盖或者修改(copy、重分配、append触发扩容),此时函数内部对数据的修改将不再影响到外部的切片,代表长度的len和容量cap也均不会被修改。
参数传递切片指针就很容易理解了,如果你想修改切片中元素的值,并且更改切片的容量和底层数组,则应该按指针传递。
08. range遍历切片有什么要注意的?
Go语言提供了range关键字用于for 循环中迭代数组(array)、切片(slice)、通道(channel)或集合(map)的元素,有两种使用方式:
for k,v := range _ { }
for k := range _ { }第一种是遍历下标和对应值,第二种是只遍历下标,使用range遍历切片时会先拷贝一份,然后在遍历拷贝数据:
s := []int{1, 2}
for k, v := range s {
}
会被编译器认为是
for_temp := s
len_temp := len(for_temp)
for index_temp := 0; index_temp < len_temp; index_temp++ {
value_temp := for_temp[index_temp]
_ = index_temp
value := value_temp
}不知道这个知识点的情况下很容易踩坑,例如下面这个例子:
package main
import (
"fmt"
)
type user struct {
name string
age uint64
}
func main() {
u := []user{
{"asong",23},
{"song",19},
{"asong2020",18},
}
for _,v := range u{
if v.age != 18{
v.age = 20
}
}
fmt.Println(u)
}
// 运行结果
[{asong 23} {song 19} {asong2020 18}]因为使用range遍历切片u,变量v是拷贝切片中的数据,修改拷贝数据不会对原切片有影响。
之前写了一个对for-range踩坑总结,可以读一下:面试官:go中for-range使用过吗?这几个问题你能解释一下原因吗?
1. 指针数据坑
range到底有什么坑呢,我们先来运行一个例子吧。
package main
import (
"fmt"
)
type user struct {
name string
age uint64
}
func main() {
u := []user{
{"asong",23},
{"song",19},
{"asong2020",18},
}
n := make([]*user,0,len(u))
for _,v := range u{
n = append(n, &v)
}
fmt.Println(n)
for _,v := range n{
fmt.Println(v)
}
}这个例子的目的是,通过u这个slice构造成新的slice。我们预期应该是显示uslice的内容,但是运行结果如下:
[0xc0000a6040 0xc0000a6040 0xc0000a6040]
&{asong2020 18}
&{asong2020 18}
&{asong2020 18}这里我们看到n这个slice打印出来的三个同样的数据,并且他们的内存地址相同。这是什么原因呢?先别着急,再来看这一段代码,我给他改正确他,对比之后我们再来分析,你们才会恍然大悟。
package main
import (
"fmt"
)
type user struct {
name string
age uint64
}
func main() {
u := []user{
{"asong",23},
{"song",19},
{"asong2020",18},
}
n := make([]*user,0,len(u))
for _,v := range u{
o := v
n = append(n, &o)
}
fmt.Println(n)
for _,v := range n{
fmt.Println(v)
}
}细心的你们看到,我改动了哪一部分代码了嘛?对,没错,我就加了一句话,他就成功了,我在for range里面引入了一个中间变量,每次迭代都重新声明一个变量o,赋值后再将v的地址添加n切片中,这样成功解决了刚才的问题。
现在来解释一下原因:在for range中,变量v是用来保存迭代切片所得的值,因为v只被声明了一次,每次迭代的值都是赋值给v,该变量的内存地址始终未变,这样讲他的地址追加到新的切片中,该切片保存的都是同一个地址,这肯定无法达到预期效果的。这里还需要注意一点,变量v的地址也并不是指向原来切片u[2]的,因我在使用range迭代的时候,变量v的数据是切片的拷贝数据,所以直接copy了结构体数据。
上面的问题还有一种解决方法,直接引用数据的内存,这个方法比较好,不需要开辟新的内存空间,看代码:
......略
for k,_ := range u{
n = append(n, &u[k])
}
......略2. 迭代修改变量问题
还是刚才的例子,我们做一点改动,现在我们要对切片中保存的每个用户的年龄进行修改,因为我们都是永远18岁,嘎嘎嘎~~~。
package main
import (
"fmt"
)
type user struct {
name string
age uint64
}
func main() {
u := []user{
{"asong",23},
{"song",19},
{"asong2020",18},
}
for _,v := range u{
if v.age != 18{
v.age = 20
}
}
fmt.Println(u)
}来看一下运行结果:
[{asong 23} {song 19} {asong2020 18}]哎呀,怎么回事。怎么没有更改呢。其实道理都是一样,还记得,我在上文说的一个知识点嘛。对,就是这个,想起来了吧。v变量是拷贝切片中的数据,修改拷贝数据怎么会对原切片有影响呢,还是这个问题,copy这个知识点很重要,一不注意,就会出现问题。知道问题了,我们现在来把这个问题解决吧。
package main
import (
"fmt"
)
type user struct {
name string
age uint64
}
func main() {
u := []user{
{"asong",23},
{"song",19},
{"asong2020",18},
}
for k,v := range u{
if v.age != 18{
u[k].age = 18
}
}
fmt.Println(u)
}可以看到,我们直接对切片的值进行修改,这样就修改成功了。所以这里还是要注意一下的,防止以后出现bug。
3. 是否会造成死循环
来看一段代码:
func main() {
v := []int{1, 2, 3}
for i := range v {
v = append(v, i)
}
}这一段代码会造成死循环吗?答案:当然不会,前面都说了range会对切片做拷贝,新增的数据并不在拷贝内容中,并不会发生死循环。这种题一般会在面试中问,可以留意下的。
你不知道的range用法
delete
没看错,删除,在range迭代时,可以删除map中的数据,第一次见到这么使用的,我刚听到确实不太相信,所以我就去查了一下官方文档,确实有这个写法:
for key := range m {
if key.expired() {
delete(m, key)
}
}看看官方的解释:
The iteration order over maps is not specified and is not guaranteed to be the same from one iteration to the next. If map entries that have not yet been reached are removed during iteration, the corresponding iteration values will not be produced. If map entries are created during iteration, that entry may be produced during the iteration or may be skipped. The choice may vary for each entry created and from one iteration to the next. If the map is nil, the number of iterations is 0.
翻译:
未指定`map`的迭代顺序,并且不能保证每次迭代之间都相同。 如果在迭代过程中删除了尚未到达的映射条目,则不会生成相应的迭代值。 如果映射条目是在迭代过程中创建的,则该条目可能在迭代过程中产生或可以被跳过。 对于创建的每个条目以及从一个迭代到下一个迭代,选择可能有所不同。 如果映射为nil,则迭代次数为0。看这个代码:
func main() {
d := map[string]string{
"asong": "帅",
"song": "太帅了",
}
for k := range d{
if k == "asong"{
delete(d,k)
}
}
fmt.Println(d)
}
# 运行结果
map[song:太帅了]从运行结果我们可以看出,key为asong的这位帅哥被从帅哥map中删掉了,哇哦,可气呀。这个方法,相信很多小伙伴都不知道,今天教给你们了,以后可以用起来了。
add
上面是删除,那肯定会有新增呀,直接看代码吧。
func main() {
d := map[string]string{
"asong": "帅",
"song": "太帅了",
}
for k,v := range d{
d[v] = k
fmt.Println(d)
}
}这里我把打印放到了range里,你们思考一下,新增的元素,在遍历时能够遍历到呢。我们来验证一下。
func main() {
var addTomap = func() {
var t = map[string]string{
"asong": "太帅",
"song": "好帅",
"asong1": "非常帅",
}
for k := range t {
t["song2020"] = "真帅"
fmt.Printf("%s%s ", k, t[k])
}
}
for i := 0; i < 10; i++ {
addTomap()
fmt.Println()
}
}运行结果:
asong太帅 song好帅 asong1非常帅 song2020真帅
asong太帅 song好帅 asong1非常帅
asong太帅 song好帅 asong1非常帅 song2020真帅
asong1非常帅 song2020真帅 asong太帅 song好帅
asong太帅 song好帅 asong1非常帅 song2020真帅
asong太帅 song好帅 asong1非常帅 song2020真帅
asong太帅 song好帅 asong1非常帅
asong1非常帅 song2020真帅 asong太帅 song好帅
asong太帅 song好帅 asong1非常帅 song2020真帅
asong太帅 song好帅 asong1非常帅 song2020真帅从运行结果,我们可以看出来,每一次的结果并不是确定的。这是为什么呢?这就来揭秘,map内部实现是一个链式hash表,为了保证无顺序,初始化时会随机一个遍历开始的位置,所以新增的元素被遍历到就变的不确定了,同样删除也是一个道理,但是删除元素后边就不会出现,所以一定不会被遍历到。
数组是具有相同 唯一类型 的一组已编号且长度固定的数据项序列(这是一种同构的数据结构),[5]int和[10]int是属于不同类型的。数组的编译时值初始化是按照数组顺序完成的(如下)。
切片声明方式,
声明切片的格式是: var identifier []type(不需要说明长度)。
一个切片在未初始化之前默认为 nil,长度为 0。
切片的初始化格式是:var slice1 []type = arr1[start:end]。
一个由数字 1、2、3 组成的切片可以这么生成:s := [3]int{1,2,3}[:](注: 应先用s := [3]int{1, 2, 3}生成数组, 再使用s[:]转成切片) 甚至更简单的 s := []int{1,2,3}。
切片也可以用类似数组的方式初始化:var x = []int{2, 3, 5, 7, 11}。这样就创建了一个长度为 5 的数组并且创建了一个相关切片。
Go 切片:用法和本质 - Go 语言博客 https://blog.go-zh.org/go-slices-usage-and-internals
可能的“陷阱”
正如前面所说,切片操作并不会复制底层的数组。整个数组将被保存在内存中,直到它不再被引用。 有时候可能会因为一个小的内存引用导致保存所有的数据。
例如, FindDigits 函数加载整个文件到内存,然后搜索第一个连续的数字,最后结果以切片方式返回。
var digitRegexp = regexp.MustCompile("[0-9]+")
func FindDigits(filename string) []byte {
b, _ := ioutil.ReadFile(filename)
return digitRegexp.Find(b)
}这段代码的行为和描述类似,返回的 []byte 指向保存整个文件的数组。因为切片引用了原始的数组, 导致 GC 不能释放数组的空间;只用到少数几个字节却导致整个文件的内容都一直保存在内存里。
要修复整个问题,可以将感兴趣的数据复制到一个新的切片中:
func CopyDigits(filename string) []byte {
b, _ := ioutil.ReadFile(filename)
b = digitRegexp.Find(b)
c := make([]byte, len(b))
copy(c, b)
return c
}可以使用 append 实现一个更简洁的版本。这留给读者作为练习。
package main
import (
"fmt"
"reflect"
)
func main() {
x := [3]int{1, 2, 3}
func (arr [3]int) {
arr[0] = 7
fmt.Println(arr)
}(x)
fmt.Println(x)
y := [3]int{1, 2, 3}
func (arr *[3]int) {
arr[0] = 7
fmt.Println(arr)
fmt.Println(*arr)
}(&y)
fmt.Println(y)
z := []int{1, 2, 3}
func (arr []int) {
arr[0] = 7
fmt.Println(arr)
}(z)
fmt.Println(z)
fmt.Println( "reflect.TypeOf(x,y,z:" , reflect.TypeOf(x), reflect.TypeOf(y), reflect.TypeOf(z))
}
1、数组,值类型
2、数组地址,修改了数组
3、切片,引用类型,修改了数组
[7 2 3]
[1 2 3]
&[7 2 3]
[7 2 3]
[7 2 3]
[7 2 3]
[7 2 3]
reflect.TypeOf(x,y,z: [3]int [3]int []int
the-way-to-go_ZH_CN/07.2.md at master · unknwon/the-way-to-go_ZH_CN https://github.com/unknwon/the-way-to-go_ZH_CN/blob/master/eBook/07.2.md
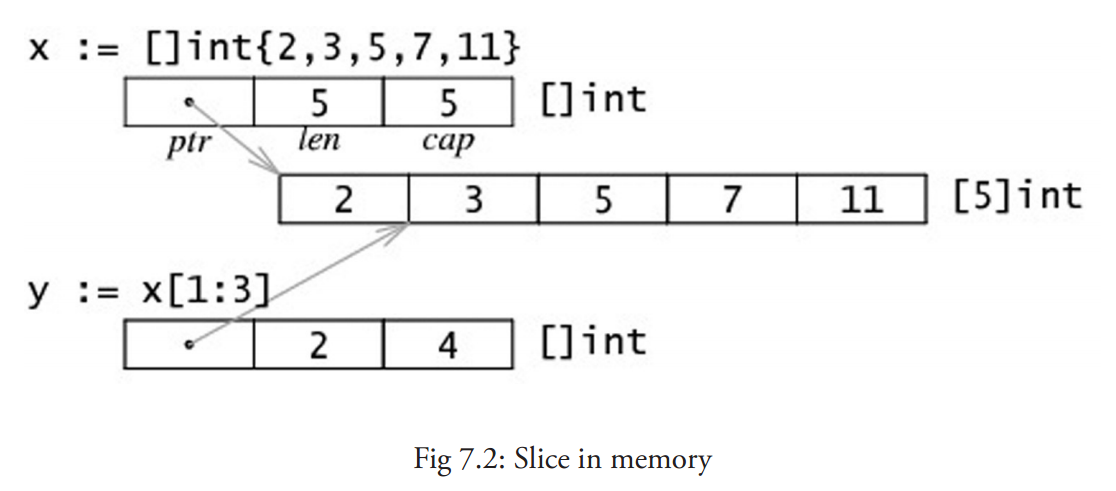
切片(slice)是对数组一个连续片段的引用,切片在内存中的组织方式实际上是一个有 3 个域的结构体:指向相关数组的指针,切片长度以及切片容量。
你真的懂 golang reslice 吗 | HHF技术博客 https://www.haohongfan.com/post/2020-10-20-golang-slice/
分片截取也叫reslice
如果你知道这些, 那么 slice 的使用基本上不会出现问题.
下面这些问题你考虑过吗 ?
- a1, a2 是如何共享底层数组的?
- a1[low:high]是如何实现的?
继续来看这段代码的汇编:
|
|
- 第4行: 将 AX 栈顶指针下移 8 字节, 指向了 a1 的 data 指向的地址空间里
- 第5-10行: 将 [3,4,5,6,7,8] 放入到 a1 的 data 指向的地址空间里
- 第11行: AX 指针后移 16 个字节. 也就是指向元素 5 的位置
- 第12行: 将 SP 指针下移 32 字节指向即将返回的 slice (其实就是 a2 ), 同时将 AX 放入到 SP. 注意 AX 放入 SP 里的是一个指针, 也就造成了a1, a2是共享同一块内存空间的
- 第13行: 将 SP 指针下移 40 字节指向了 a2 的 len, 同时 把 4 放入到 SP, 也就是 len(a2) = 4
- 第14行: 将 SP 指针下移 48 字节指向了 a2 的 cap, 同时 把 4 放入到 SP, 也就是 cap(a2) = 4
下图是 slice 的 栈图, 可以配合着上面的汇编一块看.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号