
Dubbo学习总结(2)——Dubbo架构详解
一、前言
部门去年年中开始各种改造,第一步是模块服务化,这边初选dubbo试用在一些非重要模块上,慢慢引入到一些稍微重要的功能上,半年时间,学习过程及线上使用遇到的些问题在此总结下。
整理这篇文章差不多花了两天半时间,请尊重劳动成果,如转载请注明出处http://blog.csdn.net/u012562943/article/details/49025303
二、什么是dubbo
Dubbo是阿里巴巴提供的开源的SOA服务化治理的技术框架,据说只是剖出来的一部分开源的,但一些基本的需求已经可以满足的,而且扩展性也非常好(至今没领悟到扩展性怎么做到的),通过spring bean的方式管理配置及实例,较容易上手且对应用无侵入。更多介绍可戳http://alibaba.github.io/dubbo-doc-static/Home-zh.htm。
三、如何使用dubbo
1.服务化应用基本框架
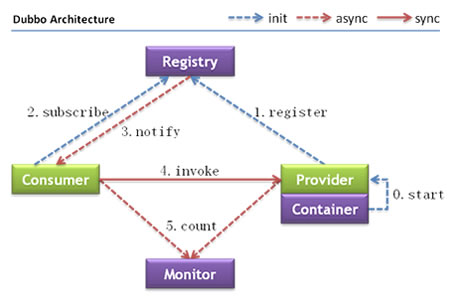
如上图所示,一个抽象出来的基本框架,consumer和provider是框架中必然存在的,Registry做为全局配置信息管理模块,推荐生产环境使用Registry,可实时推送现存活的服务提供者,Monitor一般用于监控和统计RPC调用情况、成功率、失败率等情况,让开发及运维了解线上运行情况。
应用执行过程大致如下:
- 服务提供者启动,根据协议信息绑定到配置的IP和端口上,如果已有服务绑定过相同IP和端口的则跳过
- 注册服务信息至注册中心
- 客户端启动,根据接口和协议信息订阅注册中心中注册的服务,注册中心将存活的服务地址通知到客户端,当有服务信息变更时客户端可以通过定时通知得到变更信息
- 在客户端需要调用服务时,从内存中拿到上次通知的所有存活服务地址,根据路由信息和负载均衡机制选择最终调用的服务地址,发起调用
- 通过filter分别在客户端发送请求前和服务端接收请求后,通过异步记录一些需要的信息传递到monitor做监控或者统计
那么Dubbo具体是如何实现RPC的整个过程的呢?对应RPC模型,Dubbo相应的组件又是如何实现和交互的?下图展示了Dubbo整个设计思路。
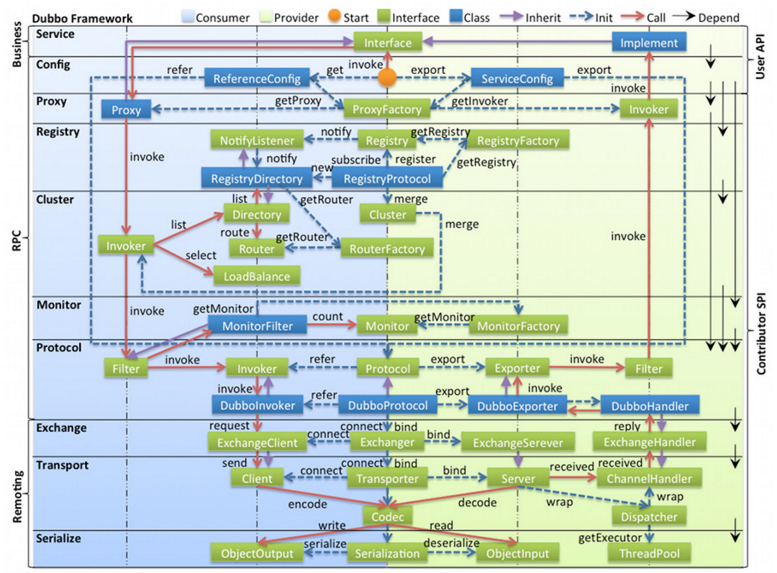
以上图片引自Dubbo官方用户手册
图例说明:
- 图中左边淡蓝背景的为服务消费方使用的接口,右边淡绿色背景的为服务提供方使用的接口,位于中轴线上的为双方都用到的接口。
- 图中从下至上分为十层,各层均为单向依赖,右边的黑色箭头代表层之间的依赖关系,每一层都可以剥离上层被复用,其中,Service 和 Config 层为 API,其它各层均为 SPI。
- 图中绿色小块的为扩展接口,蓝色小块为实现类,图中只显示用于关联各层的实现类。
- 图中蓝色虚线为初始化过程,即启动时组装链,红色实线为方法调用过程,即运行时调时链,紫色三角箭头为继承,可以把子类看作父类的同一个节点,线上的文字为调用的方法。
接下来我们对应RPC架构模型的组件谈谈Dubbo的设计。
export和import
Dubbo服务端接口export(导出)是将接口信息注册到注册中心Registry的过程。而客户端import(导入)远程接口是通过从注册中心Registry订阅远程服务接口,收到通知后拉取到本地的过程。
注册和订阅的过程,不需要修改服务端本地的类和方法,只需保证客户端和服务端共同引用一个包含接口的jar包。服务端和客户端分别编写简单的dubbo接口配置xml文件(或注解的方式),容器启动时就自动注册和订阅了。
2.服务接口定义
一般单独有一个jar包,维护服务接口定义、RPC参数类型、RPC返回类型、接口异常、接口用到的常量,该jar包中不处理任何业务逻辑。
比如命名api-0.1.jar,在api-0.1.jar中定义接口
- public interface UserService
- {
- public RpcResponseDto isValidUser(RpcAccountRequestDto requestDto) throws new RpcBusinessException, RpcSystemException;
- }
并在api-0.1.jar中定义RpcResponseDto,RpcAccountRequestDto,RpcBusinessException,RpcSystemException。
服务端通过引用该jar包实现接口并暴露服务,客户端引用该jar包引用接口的代理实例。
3.注册中心
开源的dubbo已支持4种组件作为注册中心,我们部门使用推荐的zookeeper做为注册中心,由于就瓶颈来说不会出现在注册中心,风险较低,未做特别的研究或比较。
- zookeeper,推荐集群中部署奇数个节点,由于zookeeper挂掉一半的机器集群就不可用,所以部署4台和3台的集群都是在挂掉2台后集群不可用
- redis
- multicast,广播受到网络结构的影响,一般本地不想搭注册中心的话使用这种调用
- dubbo简易注册中心
对于zookeeper客户端,dubbo在2.2.0之后默认使用zkclient,2.3.0之后提供可选配置Curator,提到这个点的原因主要是因为zkclient发现一些问题:①服务器在修改服务器时间后zkClient会抛出日志错误之类的异常然后容器(我们使用resin)挂掉了,也不能确定就是zkClient的问题,接入dubbo之前无该问题②dubbo使用zkclient不传入连接zookeeper等待超时时间,使用默认的Integer.MAX_VALUE,这样在zookeeper连不上的情况下不报错也无法启动;目前我们准备寻找其他解决方案,比如使用curator试下,还没正式投入。
4.服务端
服务端接收到客户端的请求后,反序列化数据,通过DubboHandler协议处理请求,找到注册的本地Exporter,触发invoke(),经过过滤器处理后,调用Invoker代理层,触发真正的本地接口调用,返回数据序列化后发送给客户端。
以上内容以RPC模型为基础,分析总结了Dubbo实现RPC的大体流程,后续我还会分别针对某些组件展开讨论Dubbo的设计实现。
5.客户端
看上图Config层的橙色小圆点,红色实线剪头为调用链。客户端invoke远程API(Interface),实际是调用了Proxy层的RpcProxy,proxy又调用集群组件Cluster,从集群中筛选出一个Invoker作为调用者发起调用。
我们看到,在Cluster层中筛选的过程调用了Directory(实现类为RegistryDirectory)、Router、LoadBalance,分别通过Directory实现了服务的高可用,通过Router实现了智能路由功能,通过LoadBalance实现了负载均衡。
从集群模块中筛选出一个Invoker后执行invoke()方法执行方法调用,到了Protocol协议层,经过Filter组件做拦截过滤处理,如用户名、密码验证等可在此处理。过滤通过后,调用Protocol实现类如DubboProtocol或HessianProtocol等的invoke()方法。
具体的协议实现类(如DubboProtocol)会请求ExchangeClient组件,它封装了具体的数据通讯细节,是底层数据通信的代理层。因此它自然会调用底层的通信组件(默认是Netty)实现Client建立连接、Server绑定端口和数据传输(request、return)的功能。
数据传输前需要数据序列化,服务端接收到数据需要反序列化,这些都靠序列化组件实现。Codec是序列化组件的代理层,具体序列化协议,默认是Hessian,还可选择Kryo,Thrift(被Dubbo改造,与原Thrift不兼容),dubbo, hessian2, java, json等,具体参见Dubbo用户手册。
6.监控中心
- <dubbo:monitor protocol="registry" /> <!--通过注册中心获取monitor地址后建立连接-->
- <dubbo:monitor address="dubbo://127.0.0.1:7070/com.alibaba.dubbo.monitor.MonitorService" /> <!--绕过注册中心直连monitor,同consumer直连-->
7.服务路由
8.负载均衡
- Random,随机,按权重配置随机概率,调用量越大分布越均匀,默认是这种方式
- RoundRobin,轮询,按权重设置轮询比例,如果存在比较慢的机器容易在这台机器的请求阻塞较多
- LeastActive,最少活跃调用数,不支持权重,只能根据自动识别的活跃数分配,不能灵活调配
- ConsistentHash,一致性hash,对相同参数的请求路由到一个服务提供者上,如果有类似灰度发布需求可采用
9.dubbo过滤器
- dubbo初始化过程加载META-INF/dubbo/internal/,META-INF/dubbo/,META-INF/services/三个路径(classloaderresource)下面的com.alibaba.dubbo.rpc.Filter文件
- 文件配置每行Name=FullClassName,必须是实现Filter接口
- @Activate标注扩展能被自动激活
- @Activate如果group(provider|consumer)匹配才被加载
- @Activate的value字段标明过滤条件,不写则所有条件下都会被加载,写了则只有dubbo URL中包含该参数名且参数值不为空才被加载
http://alibaba.github.io/dubbo-doc-static/User+Guide-zh.htm#UserGuide-zh-%3Cdubbo%3Amonitor%2F%3E
可关注以上链接内容,dubbo提供较多的辅助功能特性,大多目前我们暂时未使用到,后续我们这边关注到的两个特性可能会再引进来使用:- 结果缓存,省得自己再去写一个缓存,对缓存没有特殊要求的话直接使用dubbo的好了
- 分组合并,对RPC接口不同的实现方式分别调用然后合并结果的一种调用模式,比如我们要查用户是否合法,一种我们要查是否在黑名单,同时我们还要关注登录信息是否异常,然后合并结果
11.协议
在通信过程中,不同的服务等级一般对应着不同的服务质量,那么选择合适的协议便是一件非常重要的事情。你可以根据你应用的创建来选择。例如,使用RMI协议,一般会受到防火墙的限制,所以对于外部与内部进行通信的场景,就不要使用RMI协议,而是基于HTTP协议或者Hessian协议。Dubbo支持8种左右的协议,如下所示:
- (1) dubbo:// Dubbo协议
- (2) rmi:// RMI协议
- (3) hessian:// Hessian协议
- (4) http:// HTTP协议
- (5) webservice:// WebService协议
- (6) thrift:// Thrift协议
- (7) memcached:// Memcached协议
- (8)redis:// Redis协议
- 在通信过程中,不同的服务等级一般对应着不同的服务质量,那么选择合适的协议便是一件非常重要的事情。你可以根据你应用的创建来选择。
- 例如,使用RMI协议,一般会受到防火墙的限制,所以对于外部与内部进行通信的场景,就不要使用RMI协议,而是基于HTTP协议或者Hessian协议。
部分协议的特点和使用场景如下:
1、dubbo协议
Dubbo缺省协议采用单一长连接和NIO异步通讯,适合于小数据量大并发的服务调用,以及服务消费者机器数远大于服务提供者机器数的情况。

缺省协议,使用基于mina1.1.7+hessian3.2.1的tbremoting交互。 连接个数:单连接 连接方式:长连接 传输协议:TCP 传输方式:NIO异步传输 序列化:Hessian二进制序列化 适用范围:传入传出参数数据包较小(建议小于100K),消费者比提供者个数多,单一消费者无法压满提供者,尽量不要用dubbo协议传输大文件或超大字符串。 适用场景:常规远程服务方法调用
为什么要消费者比提供者个数多: 因dubbo协议采用单一长连接, 假设网络为千兆网卡(1024Mbit=128MByte), 根据测试经验数据每条连接最多只能压满7MByte(不同的环境可能不一样,供参考), 理论上1个服务提供者需要20个服务消费者才能压满网卡。 为什么不能传大包: 因dubbo协议采用单一长连接, 如果每次请求的数据包大小为500KByte,假设网络为千兆网卡(1024Mbit=128MByte),每条连接最大7MByte(不同的环境可能不一样,供参考), 单个服务提供者的TPS(每秒处理事务数)最大为:128MByte / 500KByte = 262。 单个消费者调用单个服务提供者的TPS(每秒处理事务数)最大为:7MByte / 500KByte = 14。 如果能接受,可以考虑使用,否则网络将成为瓶颈。 为什么采用异步单一长连接: 因为服务的现状大都是服务提供者少,通常只有几台机器, 而服务的消费者多,可能整个网站都在访问该服务, 比如Morgan的提供者只有6台提供者,却有上百台消费者,每天有1.5亿次调用, 如果采用常规的hessian服务,服务提供者很容易就被压跨, 通过单一连接,保证单一消费者不会压死提供者, 长连接,减少连接握手验证等, 并使用异步IO,复用线程池,防止C10K问题。
2、RMI
RMI协议采用JDK标准的java.rmi.*实现,采用阻塞式短连接和JDK标准序列化方式
Java标准的远程调用协议。 连接个数:多连接 连接方式:短连接 传输协议:TCP 传输方式:同步传输 序列化:Java标准二进制序列化 适用范围:传入传出参数数据包大小混合,消费者与提供者个数差不多,可传文件。 适用场景:常规远程服务方法调用,与原生RMI服务互操作
3、hessian
Hessian协议用于集成Hessian的服务,Hessian底层采用Http通讯,采用Servlet暴露服务,Dubbo缺省内嵌Jetty作为服务器实现
基于Hessian的远程调用协议。 连接个数:多连接 连接方式:短连接 传输协议:HTTP 传输方式:同步传输 序列化:Hessian二进制序列化 适用范围:传入传出参数数据包较大,提供者比消费者个数多,提供者压力较大,可传文件。 适用场景:页面传输,文件传输,或与原生hessian服务互操作
4、http
采用Spring的HttpInvoker实现
基于http表单的远程调用协议。 连接个数:多连接 连接方式:短连接 传输协议:HTTP 传输方式:同步传输 序列化:表单序列化(JSON) 适用范围:传入传出参数数据包大小混合,提供者比消费者个数多,可用浏览器查看,可用表单或URL传入参数,暂不支持传文件。 适用场景:需同时给应用程序和浏览器JS使用的服务。
5、webservice
基于CXF的frontend-simple和transports-http实现
基于WebService的远程调用协议。 连接个数:多连接 连接方式:短连接 传输协议:HTTP 传输方式:同步传输 序列化:SOAP文本序列化 适用场景:系统集成,跨语言调用。
6、thrif
Thrift是Facebook捐给Apache的一个RPC框架,当前 dubbo 支持的 thrift 协议是对 thrift 原生协议的扩展,在原生协议的基础上添加了一些额外的头信息,比如service name,magic number等。
12.序列化方式
在Dubbo RPC中,同时支持多种序列化方式:
(1)dubbo序列化,阿里尚不成熟的java序列化实现。
(2)hessian2序列化:hessian是一种跨语言的高效二进制的序列化方式,但这里实际不是原生的hessian2序列化,而是阿里修改过的hessian lite,它是dubbo RPC默认启用的序列化方式。
(3)json序列化:目前有两种实现,一种是采用的阿里的fastjson库,另一种是采用dubbo中自已实现的简单json库,一般情况下,json这种文本序列化性能不如二进制序列化。
(4)java序列化:主要是采用JDK自带的java序列化实现,性能很不理想。
另外还有专门针对Java语言的Kryo,FST,及跨语言的Protostuff、ProtoBuf,Thrift,Avro等。
四、前车之鉴
1.服务版本号
- 引用只会找相应版本的服务
- <dubbo:serviceinterface=“com.xxx.XxxService” ref=“xxxService” version=“1.0” />
- <dubbo:referenceid=“xxxService” interface=“com.xxx.XxxService” version=“1.0”/>
- 为了今后更换接口定义发布在线时,可不停机发布,使用版本号
2.暴露一个内网一个外网IP问题
为了在测试环境提供一个内网访问的地址和一个办公区访问的地址。
上面这种方案是一开始使用的方案,后面发现dubbo在启动过程无论是否配路由还是会一个个去连接,虽然不影响启动,但是由于存在超时所以会影响启动时间,而且每台机器还得特别配置指定IP,后面使用另外一套方案:
- 服务不配置ip,绑定到0.0.0.0,自动获取保证获取到是内网IP注册到注册中心即可,如果不是想要的IP,可以在/etc/hosts中通过绑定Hostname指定IP
- 内网访问方式通过注册中心或者直连指定内网IP和端口
- 外网访问方式通过直连指定外网IP和端口
3.dubbo reference注解问题
4.服务超时问题
- 客户端耗时大,也就是超时异常时的client elapsed xxx,这个是从创建Future对象开始到使用channel发出请求的这段时间,中间没有复杂操作,只要CPU没问题基本不会出现大耗时,顶多1ms属于正常
- IOThread繁忙,默认情况下,dubbo协议一个客户端与一个服务提供者会建立一个共享长连接,如果某个客户端处于特别繁忙而且一直往一个服务提供者塞请求,可能造成IOThread阻塞,一般非常特殊的情况才会出现
- 服务端工作线程池中线程全部繁忙,接收消息后塞入队列等待,如果等待时间比预想长会引起超时
- 网络抖动,如果上述情况都排除了,还出现在请求发出后,服务接收请求前超过预想时间,只能归类到网络抖动了,需要SA一起查看问题
- 服务自身耗时大,这个需要应用自身做好耗时统计,当出现这种情况的时候需要用数据来说明问题及规划优化方案,建议采用缓存埋点的方式统计服务中各个执行阶段的耗时情况,最终如果超过预想时间则把缓存统计的耗时情况打日志,减少日志量,且能够得到更明确的信息
5.服务保护
-
考虑服务的dubbo线程池类型(fix线程池的话考虑线程池大小)、数据库连接池、dubbo连接数限制是否都合适
-
考虑服务超时时间和重试的关系,设置合适的值
-
一定时间内服务异常数较大,则可考虑使用failfast让客户端请求直接返回或者让客户端不再请求
6.zkclient的问题
7.注册中心的分组group和服务的不同实现group
五、dubbo如何工作的
1.如何跟进源码
2.服务提供者
- ServiceBean
- ProtocolFilterWrapper
- RegistryProtocol
- DubboProtocol
- DubboProtocol$ExchangeHandler
3.客户端
- ReferenceBean
- InvokerInvocationHandler
- ProtocolFIlterWrapper
- RegistryProtocol
- DubboProtocol
- ClusterInvoker
- DubboInvoker

 浙公网安备 33010602011771号
浙公网安备 33010602011771号