
Java并发专题:线程本地变量ThreadLocal
先看一下大体结构
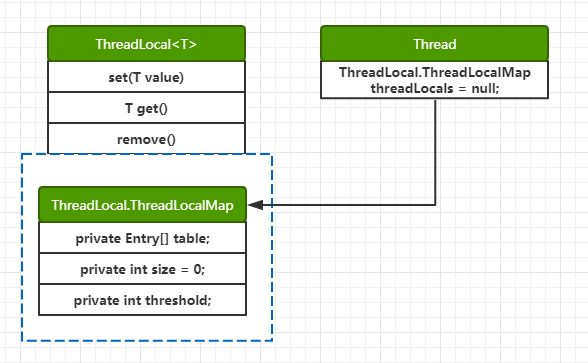
ThreadLocal(线程本地变量),作用是让每个线程都维护一份独立的变量副本,解决了变量并发访问冲突的问题。表面上看,变量是存储在ThreadLocal里面的,实则不然:
1. ThreadLocal只是个“工具类”,对外暴露了get、set、remove接口;
2. 内部实现:变量其实是保存在当前线程Thread类里,准确来说是保存在Thread类中由ThreadLocal实现的ThreadLocal.ThreadLocalMap成员变量里;
先易后难,先看入口方法
set
public void set(T value) {
// 获取当前线程
Thread t = Thread.currentThread();
// 尝试获取当前线程内部的ThreadLocalMap
ThreadLocalMap map = getMap(t);
// map不为空,就正常set值
if (map != null)
map.set(this, value);
else
// 否则就初始化Map
createMap(t, value);
}
ThreadLocalMap getMap(Thread t) {
// 可以看出,ThreadLocalMap是存储在线程对象里的
return t.threadLocals;
}
void createMap(Thread t, T firstValue) {
// new个ThreadLocalMap,key和value分别为当前ThreadLocal对象已经传入的值
t.threadLocals = new ThreadLocalMap(this, firstValue);
}
get
public T get() {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
// 如果map不为空,就尝试获取;
if (map != null) {
// 以当前ThreadLocal对象为key,获取对应的值
ThreadLocalMap.Entry e = map.getEntry(this);
// 不为空就返回,否则返回默认值
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
// 否则初始化并返回默认值
return setInitialValue();
}
private T setInitialValue() {
// 获得默认值
T value = initialValue();
// 以下过程和set方法一样
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
return value;
}
// 这里可以看出,这个方法可以由子类实现,默认返回null
protected T initialValue() {
return null;
}
remove
public void remove() {
// 尝试获取ThreadLocalMap
ThreadLocalMap m = getMap(Thread.currentThread());
if (m != null)
// map不为空,则移除key为当前ThreadLocal对象的Entry
m.remove(this);
}
小结论:ThreadLocalMap存储在Thread对象里,但却是在ThreadLocal对象里进行初始化,ThreadLocal对外暴露的接口实际上都是交给ThreadLocalMap进行处理,所以ThreadLocalMap是核心部分。
=======================================================
ThreadLocalMap里有个Entry对象
static class Entry extends WeakReference<ThreadLocal<?>> {
/** 和当前ThreadLocal有关联的值 */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
这个Entry是弱引用的,扩展一下:
强引用:在代码里普遍存在,比如Object obj = new Object();。当内存空间不足,Java虚拟机宁愿抛出OutOfMemoryError错误使程序异常终止,也不会靠随意回收具有"强引用"的对象来解决内存不足问题。
软引用:如果内存空间足够,垃圾回收器就不会回收它,如果内存空间不足了,就会回收这些对象的内存。软引用可用来实现内存敏感的高速缓存。
弱引用:被弱引用关联的对象只能生存到下一次垃圾收集发生之前。在垃圾回收过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。
虚引用:如果一个对象仅持有虚引用,那么它就和没有任何引用一样,在任何时候都可能被垃圾回收。虚引用主要用来跟踪对象被垃圾回收的活动。也就是说,持有虚引用的对象能在这个对象被回收时收到一个系统通知。
既然是弱引用,那么就会有个问题:如果key被回收了,就存在一个null-value键值对,这个value既无法被访问到,同时如果线程生命周期很长(比如线程池里),那么这些null key的强引用关系:Thread --> ThreadLocalMap-->Entry-->Value导致Value不会回收,造成内存泄漏。
官方团队也加入了解决办法,当调用set、get、remove方法的时候会去扫描key为null的Entry并清除(Entry=null)。但是这个并不是100%保证不出问题,如果这个Entry过期了,但是线程没有调用set、get或者remove,这个null key的Entry依然会存在,依然是内存泄漏了。所以还是要规范,不用了就调用remove清除。
一个例子就是线程池使用ThreadLocal
import java.util.*;
import java.util.concurrent.*;
public class Main {
private static ThreadLocal<Integer> local = new ThreadLocal<>();
public static void main(String[] args) throws Exception {
ThreadPoolExecutor executor = new ThreadPoolExecutor(3, 3, 60L, TimeUnit.SECONDS, new ArrayBlockingQueue<>(10));
for (int i = 0; i < 10; i++){
executor.execute(()->{
String name = Thread.currentThread().getName();
// 正常来说,每个线程先读取得到的值应该是一样的初始值(同一变量的副本)。如果读到了其它线程修改之后的值,则证明出问题了。
Integer init = local.get();
// 修改自己变量的值
local.set(new Random().nextInt(100));
// 读取修改之后的值
Integer data = local.get();
System.out.println(name + " | init:" + init + " | data:" + data);
});
}
executor.shutdown();
}
}
输出:(结果显而易见,由于没有清理自己的变量,导致当前线程复用到其它任务的时候,仍然保留着上一家的数据,如果先读取就会出错)
pool-1-thread-3 | init:null | data:84 pool-1-thread-1 | init:null | data:33 pool-1-thread-2 | init:null | data:85 pool-1-thread-1 | init:33 | data:96 pool-1-thread-3 | init:84 | data:82 pool-1-thread-1 | init:96 | data:83 pool-1-thread-2 | init:85 | data:51 pool-1-thread-1 | init:83 | data:48 pool-1-thread-3 | init:82 | data:17 pool-1-thread-2 | init:51 | data:58
正确做法
import java.util.*;
import java.util.concurrent.*;
public class Main {
private static ThreadLocal<Integer> local = new ThreadLocal<>();
public static void main(String[] args) throws Exception {
ThreadPoolExecutor executor = new ThreadPoolExecutor(3, 3, 60L, TimeUnit.SECONDS, new ArrayBlockingQueue<>(10));
for (int i = 0; i < 10; i++){
executor.execute(()->{
try {
String name = Thread.currentThread().getName();
// 正常来说,每个线程先读取得到的值应该是一样的初始值(同一变量的副本)。如果读到了其它线程修改之后的值,则证明出问题了。
Integer init = local.get();
// 修改自己变量的值
local.set(new Random().nextInt(100));
// 读取修改之后的值
Integer data = local.get();
System.out.println(name + " | init:" + init + " | data:" + data);
} finally {
// 最终清除数据
local.remove();
}
});
}
executor.shutdown();
}
}
输出:
pool-1-thread-1 | init:null | data:6 pool-1-thread-1 | init:null | data:93 pool-1-thread-2 | init:null | data:93 pool-1-thread-3 | init:null | data:41 pool-1-thread-2 | init:null | data:37 pool-1-thread-1 | init:null | data:54 pool-1-thread-2 | init:null | data:61 pool-1-thread-3 | init:null | data:76 pool-1-thread-2 | init:null | data:95 pool-1-thread-1 | init:null | data:68
所以,千万记得remove啊
源码
private final int threadLocalHashCode = nextHashCode();
private static int nextHashCode() {
return nextHashCode.getAndAdd(HASH_INCREMENT); // HASH_INCREMENT = 0x61c88647
}
0x61c88647是斐波那契散列乘数,它的优点是通过它散列(hash)出来的结果分布会比较均匀,可以很大程度上避免hash冲突。
set
private void set(ThreadLocal<?> key, Object value) {
// 指向当前数组
Entry[] tab = table;
// 当前数组长度
int len = tab.length;
// 计算下标
int i = key.threadLocalHashCode & (len-1);
// 遍历table
for (Entry e = tab[i]; // 从计算的下标开始
e != null; // 直到遇到空槽
e = tab[i = nextIndex(i, len)]) { // 指向下一个位置的元素
// 获取当前位置的key
ThreadLocal<?> k = e.get();
// 如果传入的key已存在,则覆盖旧值
if (k == key) {
e.value = value;
return;
}
// 如果当前位置i的key为null,
if (k == null) {
// 此方法:1. 用指定key-value的新Entry替换set操作期间遇到的过期Entry(key==null)2. 如果遇到已存在的key,则用新值覆盖旧值。3. 清除两个空槽之间过期的Entry
replaceStaleEntry(key, value, i);
return;
}
}
// 如果前面没找到已存在的key,则新创建一个Entry放在此位置
tab[i] = new Entry(key, value);
int sz = ++size;
// 1. 启发式地扫描并清除过期的Entry。2. 如果没有需要清除的并且需要扩容,则进行扩容
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
}
set方法做的事情:从计算得到的下标开始,遇到空槽为止进行扫描。遇到相同的key则覆盖;遇到key为null的Entry则直接new一个新Entry替换无效Entry;否则在下标处new一个新的Entry。最后扫描并清理无效槽位,如果满足扩容条件即扩容。
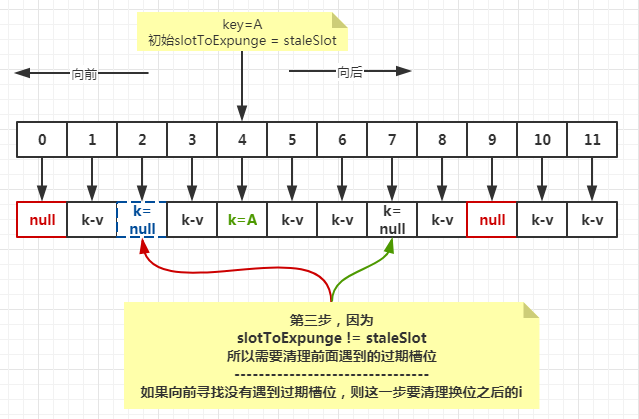
已经确认,只有set的时候可能调用replaceStaleEntry方法,而这种情况下当前位置i(staleSolt)是个过期位置(key==null)
private void replaceStaleEntry(ThreadLocal<?> key, Object value, int staleSlot) {
// 指向当前table
Entry[] tab = table;
// table长度
int len = tab.length;
// 指向每一个遍历的数组对象
Entry e;
// 记录需要删除的槽位。开始的时候等于传入的位置。
int slotToExpunge = staleSlot;
// 向前找直到槽位为空,如果遇到key为空的Entry,则仅仅记录下最后一个。
for (int i = prevIndex(staleSlot, len); // 找到当前位置的前一位:((i - 1 >= 0) ? i - 1 : len - 1)
(e = tab[i]) != null; // 结束条件是当前位置为null(空槽)
i = prevIndex(i, len)) // 继续寻找前一位
if (e.get() == null)
// 如果当前位置的key是null,则记录下此位置
slotToExpunge = i;
// 查找key或者空槽,以最先出现的为准
for (int i = nextIndex(staleSlot, len); // 当前位置的下一个开始:((i + 1 < len) ? i + 1 : 0)
(e = tab[i]) != null; // 遇到空槽结束
i = nextIndex(i, len)) { // 下一个
// 当前key
ThreadLocal<?> k = e.get();
// 如果当前key和传入的key相同,那么我们需要将它与过期槽位的内容进行交换,以保持哈希表的顺序。
// 然后可以将新过期的槽或上面遇到的任何其他过期槽的位置发送到expungeStaleEntry,以删除或重新散列运行中的所有其他Entry。
if (k == key) {
e.value = value;
// 当前位置
tab[i] = tab[staleSlot];
tab[staleSlot] = e;
// 如果slotToExpunge == staleSlot,则证明上一步向前找的过程中没有遇到key==null的Entry。此种情况,把slotToExpunge记录为当前位置i
if (slotToExpunge == staleSlot)
slotToExpunge = i;
cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
return;
}
// 1. 当前key为null,则此位置是个过期Entry
// 2. 如果此时slotToExpunge == staleSlot,则证明上一步向前找的过程中没有遇到key==null的Entry、并且向后找的过程也没有遇到相同的key(因为前面如果遇到了相同key,则已经退出了循环)
// 满足两个条件,则将当前过期槽位的位置记录下来
if (k == null && slotToExpunge == staleSlot)
slotToExpunge = i;
}
// 如果相同的key没有找到,则把新的Entry放在过期的槽位
tab[staleSlot].value = null;
tab[staleSlot] = new Entry(key, value);
// 如果还存在其它过期槽位,删除之
if (slotToExpunge != staleSlot)
cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
}
图解
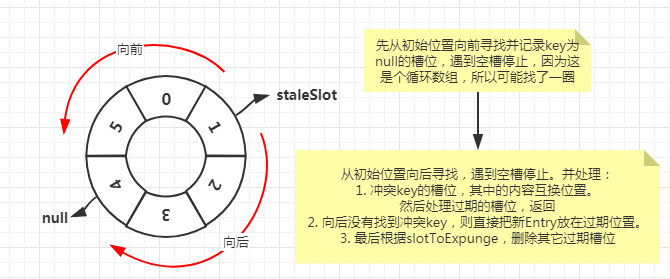
情况示例一:向前寻找有个过期槽位,向后寻找没有冲突key。
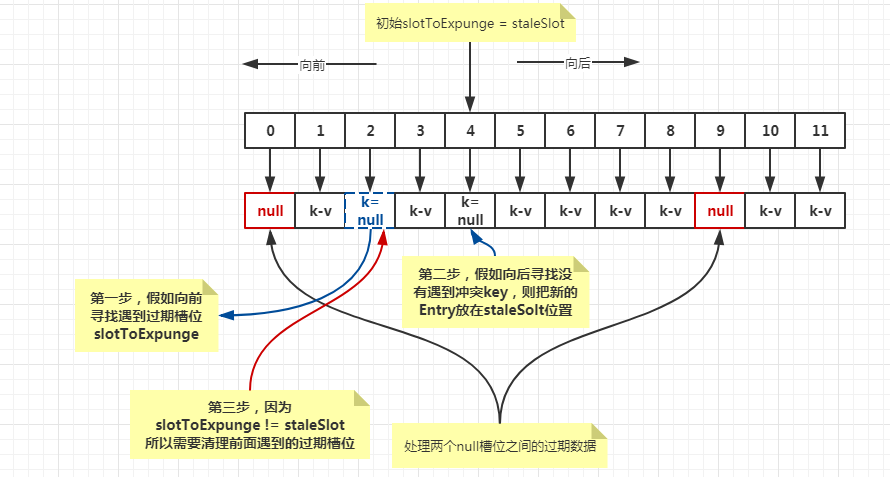
情况示例二: 向前寻找有个过期槽位,向后寻找发现冲突key。
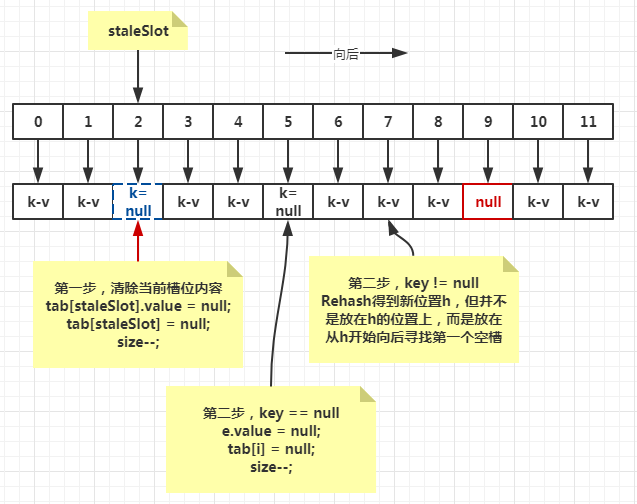
再来看expungeStaleEntry,顾名思义,删除过期的Entry。
// 在staleSlot和下一个空槽之间:1. 重新哈希任何可能碰撞的Entry。2. 删除过期的Entry。
private int expungeStaleEntry(int staleSlot) {
Entry[] tab = table;
int len = tab.length;
// 删除位于staleSlot的Entry
tab[staleSlot].value = null;
tab[staleSlot] = null;
size--;
// Rehash 直到遇到空槽
Entry e;
int i;
// 从staleSlot的下一个开始遍历
for (i = nextIndex(staleSlot, len);
(e = tab[i]) != null;
i = nextIndex(i, len)) {
// 当前槽位的key
ThreadLocal<?> k = e.get();
// key为null,删除之
if (k == null) {
e.value = null;
tab[i] = null;
size--;
} else {
// rehash
int h = k.threadLocalHashCode & (len - 1);
// 如果新计算出的位置不等于当前位置,则:
if (h != i) {
// 1. 先把当前位置置为空
tab[i] = null;
// Unlike Knuth 6.4 Algorithm R, we must scan until
// null because multiple entries could have been stale.
// 2. 从h开始找直到遇到空槽。然后把其中的内容移到找到的空槽里。
while (tab[h] != null)
h = nextIndex(h, len);
tab[h] = e;
}
}
}
// 返回空槽的位置
return i;
}
图解
看cleanSomeSlots
// 启发式地扫描并清除过期的Entry。
private boolean cleanSomeSlots(int i, int n) {
boolean removed = false;
Entry[] tab = table;
int len = tab.length;
do {
// 从位置i的下一个开始搜索
i = nextIndex(i, len);
Entry e = tab[i];
// 如果遇到过期Entry,清除
if (e != null && e.get() == null) {
n = len;
removed = true;
i = expungeStaleEntry(i);
}
} while ( (n >>>= 1) != 0);
// 只要有过期Entry被移除就会返回true
return removed;
}
.
最后看下扩容
private void rehash() {
// 这个方法从0开始遍历table,遇到key==null的就执行expungeStaleEntry方法
expungeStaleEntries();
// Use lower threshold for doubling to avoid hysteresis
if (size >= threshold - threshold / 4)
// 如果当前size达到扩容阈值的75%,则扩容
resize();
}
private void resize() {
// 旧table
Entry[] oldTab = table;
// 旧容量
int oldLen = oldTab.length;
// 新容量=旧容量*2(旧容量的2倍)
int newLen = oldLen * 2;
// 按照新容量new个新的Entry数组
Entry[] newTab = new Entry[newLen];
int count = 0;
// 遍历旧table
for (int j = 0; j < oldLen; ++j) {
Entry e = oldTab[j];
if (e != null) {
ThreadLocal<?> k = e.get();
// 遇到过期Entry,处理之
if (k == null) {
e.value = null; // Help the GC
} else {
// 正常的Entry做Rehash操作,放到计算得到的新位置h之后的第一个空槽里
int h = k.threadLocalHashCode & (newLen - 1);
while (newTab[h] != null)
h = nextIndex(h, newLen);
newTab[h] = e;
count++;
}
}
}
// 设置新的阈值
setThreshold(newLen);
size = count;
table = newTab;
}
扩容很简单:达到扩容阈值的75%,即扩容,新容量是老容量的2倍,遇到过期的Entry删除,其它Entry做Rehash操作放到新位置。
以上是set核心方法,下面来看get涉及的方法getEntry
private Entry getEntry(ThreadLocal<?> key) {
// 计算下标
int i = key.threadLocalHashCode & (table.length - 1);
Entry e = table[i];
// 有值则返回
if (e != null && e.get() == key)
return e;
else
// 没有匹配的则进行清理工作(这个方法也体现了,调用get方法不一定会进行清理过期Entry工作)
return getEntryAfterMiss(key, i, e);
}
private Entry getEntryAfterMiss(ThreadLocal<?> key, int i, Entry e) {
Entry[] tab = table;
int len = tab.length;
// 从给定的位置i开始遍历
while (e != null) {
ThreadLocal<?> k = e.get();
// 如果key的地址相同,证明不需要清理,直接返回即可
if (k == key)
return e;
// 如果key是null,则清理
if (k == null)
expungeStaleEntry(i);
else
// 否则移到下一个
i = nextIndex(i, len);
e = tab[i];
}
return null;
}
最后是remove
private void remove(ThreadLocal<?> key) {
// 当前table
Entry[] tab = table;
// 当前长度
int len = tab.length;
// 根据key计算下标
int i = key.threadLocalHashCode & (len-1);
// 从计算得到的位置开始清理,直到遇到空槽停止
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
// 如果找到目标key,清理后返回
if (e.get() == key) {
e.clear();
expungeStaleEntry(i);
return;
}
}
}
最后两个问题(我在读的过程中也充满了疑惑)
源码里replaceStaleEntry有个向前找向后找的过程,如果循环之内的条件一直不满足,则只能依靠循环条件((e = tab[i]) != null)来结束循环;
类似的expungeStaleEntry中Rehash过程有个寻找新位置的过程,结束条件也是while (tab[h] != null)。
我就想了,如果没有空槽呢?岂不是死循环了。
而实际上是不会存在这种情况的,因为扩容啊,每次达到扩容阈值的75%就扩容了,所以空槽是肯定一直存在的。
我们了解到底层的Map是一个Entry数组,那么问题来了:通常我们使用ThreadLocal都是存储当前线程的私有变量,也就是只存一个值,为什么还需要一个可以存多个值的Entry数组呢?
ThreadLocal可以定义多个,每个都有自己的线程私有变量。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号