

hadoop基础(一)
大数据的5v特征
一、Volume:数据量大,包括采集、存储和计算的量都非常大。大数据的起始计量单位至少是P(1000个T)、E(100万个T)或Z(10亿个T)。
二、Variety:种类和来源多样化。包括结构化、半结构化和非结构化数据,具体表现为网络日志、音频、视频、图片、地理位置信息等等,多类型的数据对数据的处理能力提出了更高的要求。
三、Value:数据价值密度相对较低,或者说是浪里淘沙却又弥足珍贵。随着互联网以及物联网的广泛应用,信息感知无处不在,信息海量,但价值密度较低,如何结合业务逻辑并通过强大的机器算法来挖掘数据价值,是大数据时代最需要解决的问题。
四、Velocity:数据增长速度快,处理速度也快,时效性要求高。比如搜索引擎要求几分钟前的新闻能够被用户查询到,个性化推荐算法尽可能要求实时完成推荐。这是大数据区别于传统数据挖掘的显著特征。
五、Veracity:数据的准确性和可信赖度,即数据的质量。
1.Hadoop简介
1.1 组件
Hadoop由4部分组成
1)HDFS:(Hadoop Distribute File System)分布式文件系统,海量数据存储解决方案
2)MapReduce:Hadoop的分布式运算编程框架
3)Yarn:分布式资源调度平台和任务监控平台
4)Commons: HADOOP底层技术支持
主要用来解决:大数据存储,大数据分析. 核心组件:HDFS,MapReduce
1.2 特点
(1) 高可靠性 :Hadoop底层将数据以多个副本的形式存储在不同的机器上,保证数据的安全可靠。
(2) 高扩展性 :当存储hdp集群的存储能力和运算资源不足时,可以横向的扩展机器节点来达到扩容和增强运算能力 。
(3) 高效性 :在MapReduce的思想下能够在节点之间动态地移动运算,且是分布式并行工作的,所以运海量数据非常高效。
(4) 高容错性 : Hadoop能够自动保存数据的多个副本,当有存储数据的节点宕机以后, 会自动的复制副本维持集群中副本的个数 ,并且能够自动将失败的任务重新分配。
(5) 低成本 :hadoop可以运行在廉价的机器上并行工作,达到高效,安全,效率于一身目的。
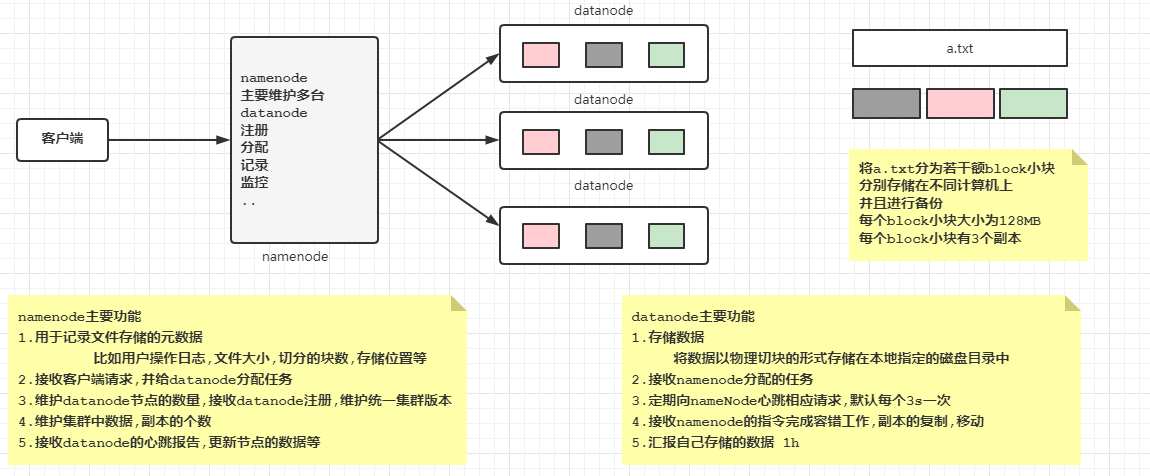
2.HDFS分布式文件系统
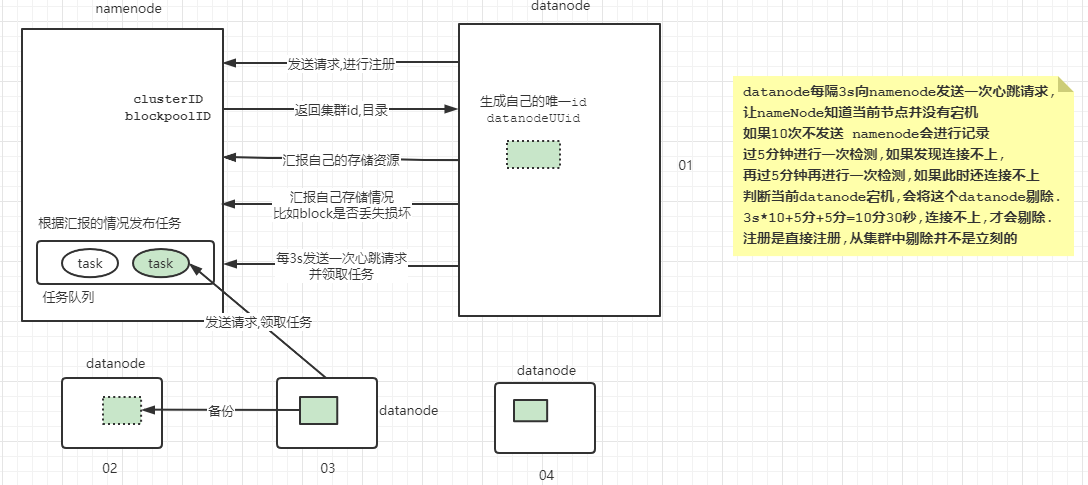
(Hadoop Distribute File System )分布式文件系统,解决了海量数据无法单台机器存储的问题,将海量的数据存储在不同的机器中 ,由HDFS文件系统统一管理和维护, 提供统一的访问目录和API !
2.1 原理简介
存储原理
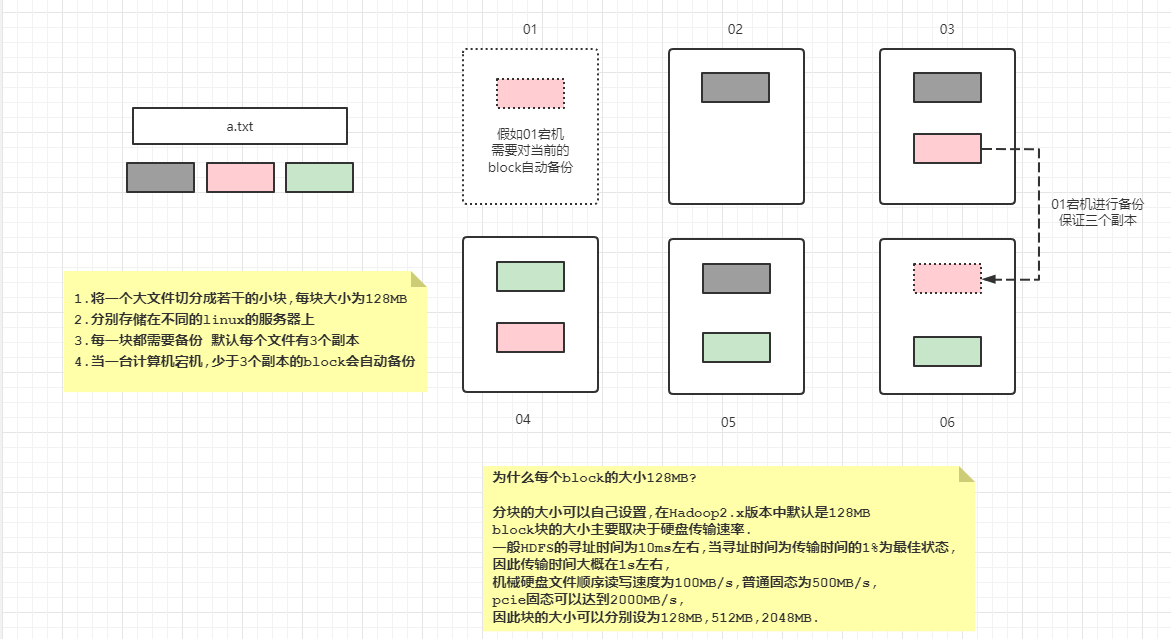
访问原理
2.2 演示案例分析
2.3 安装
2.3.1 安装环境和整体步骤
环境
java环境
集群中的每台机器的ip
主机名
域名映射
关闭防火墙
时间同步
ssh免密
步骤
上传
解压
配置
分发
初始化
启动
2.3.2 安装过程
# 将hadoop-3.1.1.tar.gz 上传
cd /opt/apps
使用rz 命令或xftp上传
# 解压
tar -zxvf hadoop-3.1.1.tar.gz
cd hadoop-3.1.1
rm -rf share/doc
# 配置JAVAHOME
vim etc/hadoop/hadoop-env.sh
# 最后一行插入
export JAVA_HOME=/opt/apps/jdk1.8.0_191
# 配置namenode
vim /opt/apps/hadoop-3.1.1/etc/hadoop/hdfs-site.xml
# 将下面的内容粘贴到<configuration></configuration>标签中
<!-- 集群的namenode的位置 datanode能通过这个地址注册-->
<property>
<name>dfs.namenode.rpc-address</name>
<value>linux01:8020</value>
</property>
<!-- namenode存储元数据的位置 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/hdpdata/name</value>
</property>
<!-- datanode存储数据的位置 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/hdpdata/data</value>
</property>
<!-- secondary namenode机器的位置-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>linux02:50090</value>
</property>
# 进入到apps文件夹中
cd /opt/apps
# 将hadoop文件远程复制linux02 linux03
scp -r hadoop-3.1.1 linux02:$PWD
scp -r hadoop-3.1.1 linux03:$PWD
# 初始化 linux01
cd /opt/apps/hadoop-3.1.1/bin
./hadoop namenode -format
# 初始化后 opt下会多出一个文件夹hdpdata
ll /opt
# 单节点启动
## (linux01)启动namenode
cd /opt/apps/hadoop-3.1.1/sbin
./hadoop-daemon.sh start namenode
## 启动成功后可访问页面http://linux01:9870
## (linux01 linux02 linux03)启动datanode
cd /opt/apps/hadoop-3.1.1/sbin
./hadoop-daemon.sh start datanode
# 一键启停
## 为了方便今后的启动 将sbin目录配置到环境变量中
vi /etc/profile
export JAVA_HOME=/opt/apps/jdk1.8.0_191
export HADOOP_HOME=/opt/apps/hadoop-3.1.1
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
## 保存
source /etc/profile
## 配置集群文件 hadoop的etc/hadoop/目录下workers 告知有哪些机器
vi workers
linux01
linux02
linux03
## 修改hadoop的sbin下的 start-dfs.sh stop-dfs.sh
vi start-dfs.sh
### 在第一行后插入
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
vi stop-dfs.sh
### 在第一行后插入
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
# 配置后 可以在任意目录下
stop-dfs.sh # 停止
start-dfs.sh # 启动
2.4 常用客户端命令
很多指令和linux相同 我们在使用时 只要前面加上hdfs dfs 即可
# 创建目录
hdfs dfs -mkdir -p hdfs://linux01:8020/aaa/bbb/ccc
# 由于默认是在本机上操作 我们如果使用指令每次都需要加上 hdfs://linux01:8020
# 比较麻烦 那么可以进行配置 将默认操作设置为 分布式文件系统上
# 修改hadoop的etc/hadoop下的文件 core-site.xml
# 将下面内容放入到<configuration></configuration>标签中
<property>
<name>fs.defaultFS</name>
<value>hdfs://linux01:8020</value>
</property>
# 这样 我们就不需要每次都加上hdfs://linux01:8020了
hdfs dfs -mkdir -p /zs/li/ww
# 创建文件夹
hdfs dfs -mkdir -p /abc
# 创建文件
hdfs dfs -touchz /abc/a.txt
# 查看
hdfs dfs -ls /
# 将本地文件上传并改名
hdfs dfs -put b.txt /abc/aa.txt
# 将hdfs上的文件下载到本地并改名
hdfs dfs -get /abc/aa.txt /cc.txt
# 修改abc文件夹的的权限
hdfs dfs -chmod 777 /abc
# 删除abc文件夹的 a.txt
hdfs dfs -rm -r /abc/a.txt
# 删除abc文件夹下的所有内容
hdfs dfs -rm -r /abc/*
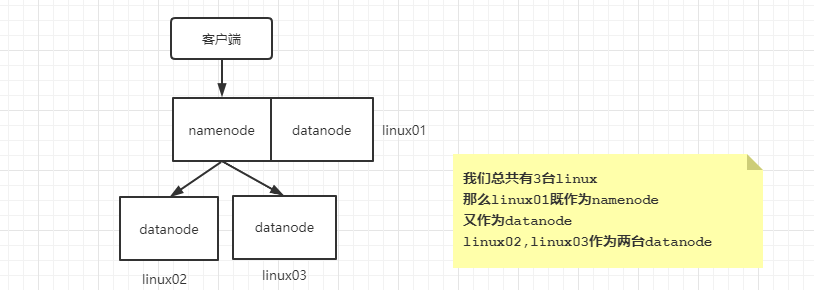
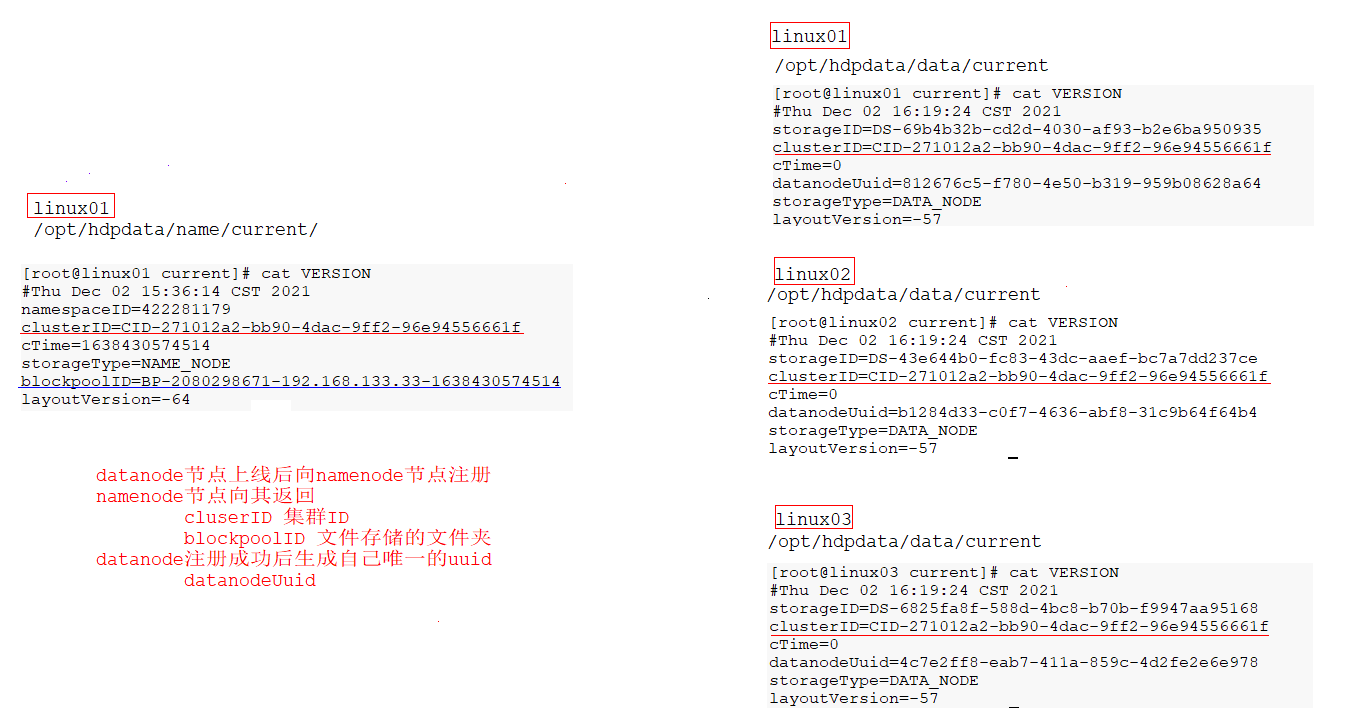
2.5 节点交互原理
我们将JDK压缩上传到文件系统上
tar -zcvf my.tar.gz jdk1.8.0_191
创建一个文件夹
hdfs dfs -mkdir -p /java/se
上传
hdfs dfs -put my.tar.gz /java/se

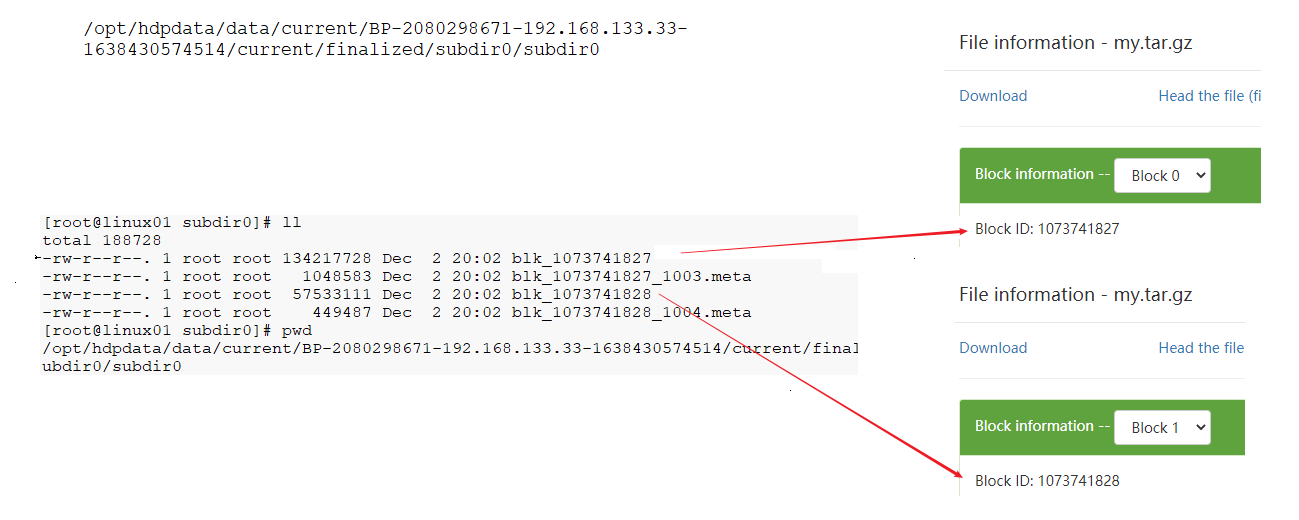
这个文件的总大小为182.87MB 我们说HDFS会进行分块存储 每块大小默认128MB 那么这个文件存储时应该应该分为两块,一个为128MB,一个为54.87MB
文件的存储位置为
/opt/hdpdata/data/current/BP-2080298671-192.168.133.33-1638430574514/current/finalized/subdir0/subdir0
linux01 linux02 linux03 都是相同位置


 浙公网安备 33010602011771号
浙公网安备 33010602011771号