

ELK+zookeeper+kafka+rsyslog集群搭建
前言
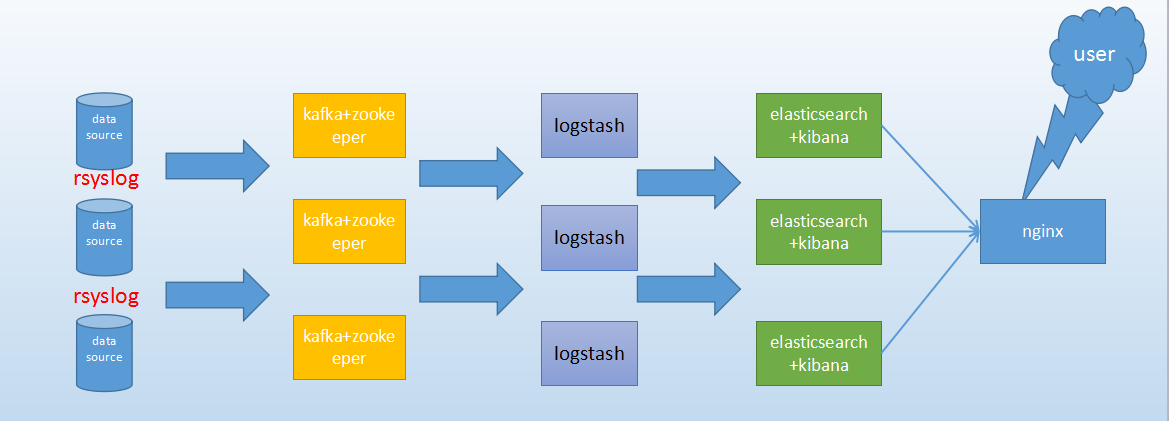
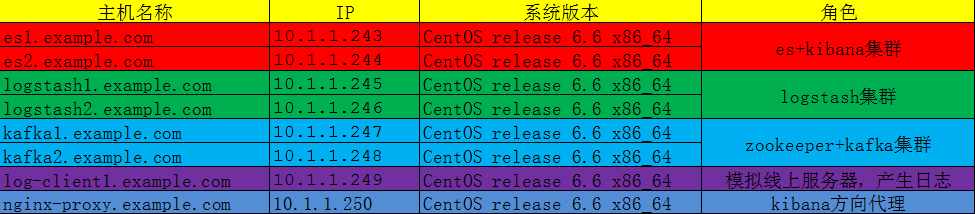
以上软件都可以从官网下载:https://www.elastic.co/downloads或使用我共享网盘下载 ( 链接: https://pan.baidu.com/s/1hsw56tA 密码: w6ey )
1.ES集群安装配置
2.rsyslog客户端配置
3.Kafka(zookeeper)集群配置
4.Kibana部署5.案例:nginx日志收集以及messages日志收集
6.Kibana报表基本使用
关闭防火墙,关闭selinux(生产环境按需关闭或打开)
同步服务器时间,选择公网ntpd服务器或者自建ntpd服务器
[root@es1 ~]# crontab -l #为了方便直接使用公网服务器
#update time
*/5 * * * * /usr/bin/rdate -s time-b.nist.gov &>/dev/null
一、ES集群安装配置
1.安装jvm依赖环境
[root@es1 ~]# rpm -ivh jdk-8u25-x64.rpm #因为5.X版本需要1.8,为了以后升级麻烦直接安装1.8
Preparing... ########################################### [100%]
1:jdk1.8.0_131 ########################################### [100%]
设置Java环境
[root@es1 ~]# cat /etc/profile.d/java.sh #编辑Java环境配置文件
export JAVA_HOME=/usr/java/latest
export CLASSPATH=$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$PATH
[root@es1 ~]# . /etc/profile.d/java.sh
[root@es1 ~]# java -version #确认配置
java version "1.8.0_131"
Java(TM) SE Runtime Environment (build 1.8.0_131-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.131-b11, mixed mode)
2.安装及配置elasticsearch
[root@es1 ~]# tar xf elasticsearch-2.1.0.tar.gz -C /usr/local/
[root@es1 ~]# cd /usr/local/
[root@es1 local]# ln -sv elasticsearch-2.1.0 elasticsearch
"elasticsearch" -> "elasticsearch-2.1.0"
[root@es1 local]# cd elasticsearch
[root@es1 elasticsearch]# vim config/elasticsearch.yml
[root@es1 elasticsearch]# grep "^[a-Z]" config/elasticsearch.yml
cluster.name: pwb-cluster #集群名称,同一集群需配置一致
node.name: pwb-node1 #集群节点名称,集群内唯一
path.data: /Data/es/data #数据目录
path.logs: /Data/es/logs #日志目录
bootstrap.mlockall: true
network.host: 10.1.1.243
http.port: 9200
discovery.zen.ping.unicast.hosts: ["10.1.1.243", "10.1.1.244"]
discovery.zen.minimum_master_nodes: 1
3.创建相关目录
[root@es1 elasticsearch]# mkdir -pv /Data/es/{data,logs}
mkdir: 已创建目录 "/Data"
mkdir: 已创建目录 "/Data/es"
mkdir: 已创建目录 "/Data/es/data"
mkdir: 已创建目录 "/Data/es/logs
4. Elasticsearch为了安全考虑,不允许使用root启动,解决方法新建一个用户,用此用户进行相关的操作
[root@es1 elasticsearch]# useradd elasticsearch
[root@es1 elasticsearch]# chown -R elasticsearch:elasticsearch /Data/es/
[root@es1 elasticsearch]# chown -R elasticsearch:elasticsearch /usr/local/elasticsearch-2.1.0/
5.配置其他环境参数(必须,否则后面启动会报错)
[root@es1 elasticsearch]# echo "elasticsearch hard nofile 65536" >> /etc/security/limits.conf
[root@es1 elasticsearch]# echo "elasticsearch soft nofile 65536" >> /etc/security/limits.conf
[root@es1 elasticsearch]# sed -i 's/1024/2048/g' /etc/security/limits.d/90-nproc.conf
[root@es1 elasticsearch]# echo "vm.max_map_count=262144 " >> /etc/sysctl.conf
[root@es1 elasticsearch]# sysctl -p
[root@es1 elasticsearch]# grep "ES_HEAP_SIZE=" bin/elasticsearch #设置elasticsearch使用内存大小,原则上越大越好,但是不要超过32G
export ES_HEAP_SIZE=100m #测试环境内存有限
其他节点配置同上,各节点配置差异部分:
network.host: 10.1.1.243 #本机IP地址
node.name: pwb-node1 #分配的节点名称
6.启动elasticsearch
[root@es1 elasticsearch]# su - elasticsearch
[elasticsearch@es1 ~]$ cd /usr/local/elasticsearch
[elasticsearch@es1 elasticsearch]$ bin/elasticsearch&

通过屏幕输出可以看到服务启动并通过自动发现方式添加集群内其他节点
检查服务是否正常
[root@es1 ~]# netstat -tnlp
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 944/sshd
tcp 0 0 ::ffff:10.1.1.243:9300 :::* LISTEN 3722/java #ES节点之间通讯使用
tcp 0 0 :::22 :::* LISTEN 944/sshd
tcp 0 0 ::ffff:10.1.1.243:9200 :::* LISTEN 3722/java #ES节点和外部通讯使用
[root@es1 ~]# curl http://10.1.1.243:9200/ #如果出现以下信息,说明安装配置成功啦
{
"name" : "pwb-node1",
"cluster_name" : "pwb-cluster",
"version" : {
"number" : "2.1.0",
"build_hash" : "72cd1f1a3eee09505e036106146dc1949dc5dc87",
"build_timestamp" : "2015-11-18T22:40:03Z",
"build_snapshot" : false,
"lucene_version" : "5.3.1"
},
"tagline" : "You Know, for Search"
}
7.安装elasticsearch常用插件
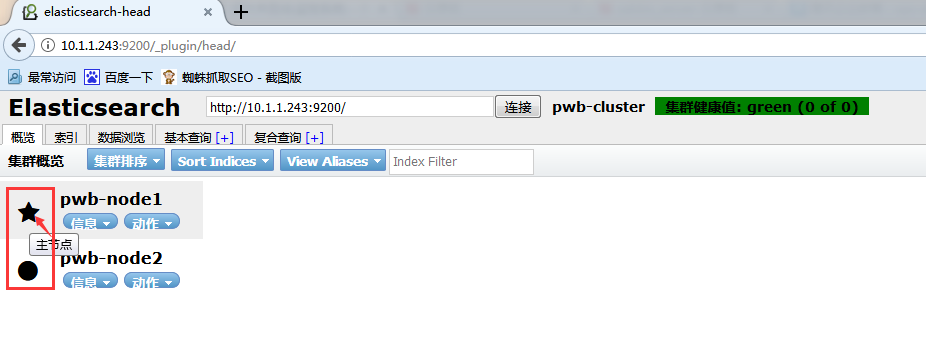
[root@es1 ~]# /usr/local/elasticsearch/bin/plugin install mobz/elasticsearch-head
安装完成后,访问URL http://10.1.1.243:9200/_plugin/head/,由于集群中现在暂时没有数据,所以显示为空(五角星表示主节点,圆点表示数据节点)
其他常用插件安装方式(这里不一一演示,有兴趣可以自己安装)
./bin/plugin install lukas-vlcek/bigdesk #2.0一下版本使用改命令
./bin/plugin install hlstudio/bigdesk #2.0以上版本使用该命令安装
./bin/plugin install lmenezes/elasticsearch-kopf/version
二、Logstash集群安装配置
Logstash需要依赖java环境,所以这里还是需要安装JVM,这里步骤省略
1.安装logstash
[root@logstash1 ~]# tar xf logstash-2.0.0.tar.gz -C /usr/local/
[root@logstash1 ~]# cd /usr/local/
[root@logstash1 local]# ln -sv logstash-2.0.0 logstash
"logstash" -> "logstash-2.0.0"
[root@logstash1 local]# cd logstash
[root@logstash1 logstash]# grep "LS_HEAP_SIZE" bin/logstash.lib.sh
LS_HEAP_SIZE="${LS_HEAP_SIZE:=100m}" #设置使用内存大小
2.测试logstash向elasticsearch写入日志,以系统messages文件为例
(1)编写一个logstash配置文件
[root@logstash1 logstash]# cat conf/messages.conf
input {
file { #数据输入使用input file 插件,从messages文件中读取
path => "/var/log/messages"
}
}
output {
elasticsearch { #数据输出指向ES集群
hosts => ["10.1.1.243:9200","10.1.1.244:9200"] #ES节点主机IP和端口
}
}
[root@logstash1 logstash]# /usr/local/logstash/bin/logstash -f conf/messages.conf --configtest --verbose #语法检测
Configuration OK
[root@logstash1 logstash]# /usr/local/logstash/bin/logstash -f conf/messages.conf #启动
Default settings used: Filter workers: 1
Logstash startup completed
(2)向message写入一些文件,我们安装一些软件
[root@logstash1 log]# yum install httpd -y
查看messages文件的变化
[root@logstash1 log]# tail /var/log/messages
Oct 24 13:44:25 localhost kernel: ata2.00: configured for UDMA/33
Oct 24 13:44:25 localhost kernel: ata2: EH complete
Oct 24 13:49:34 localhost rz[3229]: [root] logstash-2.0.0.tar.gz/ZMODEM: error: zgethdr returned 16
Oct 24 13:49:34 localhost rz[3229]: [root] logstash-2.0.0.tar.gz/ZMODEM: error
Oct 24 13:49:34 localhost rz[3229]: [root] no.name/ZMODEM: got error
Nov 8 22:21:25 localhost rz[3245]: [root] logstash-2.0.0.tar.gz/ZMODEM: 80604867 Bytes, 2501800 BPS
Nov 8 22:24:27 localhost rz[3248]: [root] jdk-8u25-x64.rpm/ZMODEM: 169983496 Bytes, 1830344 BPS
Nov 8 22:50:49 localhost yum[3697]: Installed: apr-util-ldap-1.3.9-3.el6_0.1.x86_64
Nov 8 22:50:50 localhost yum[3697]: Installed: httpd-tools-2.2.15-60.el6.centos.6.x86_64
Nov 8 22:51:07 localhost yum[3697]: Installed: httpd-2.2.15-60.el6.centos.6.x86_64
访问elasticsearch head插件的web页面
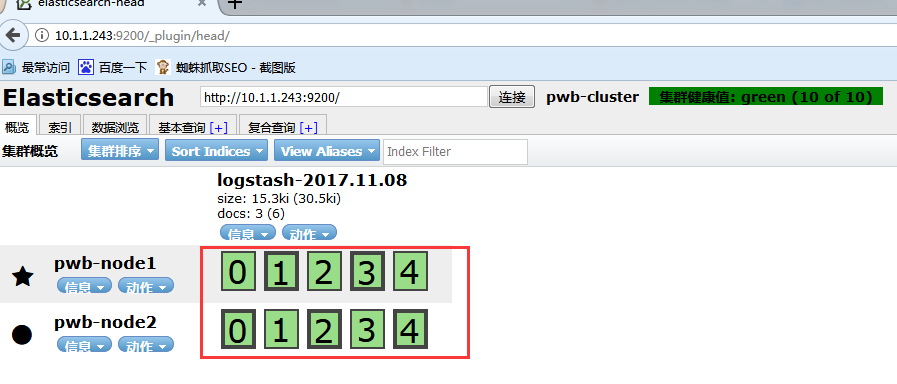
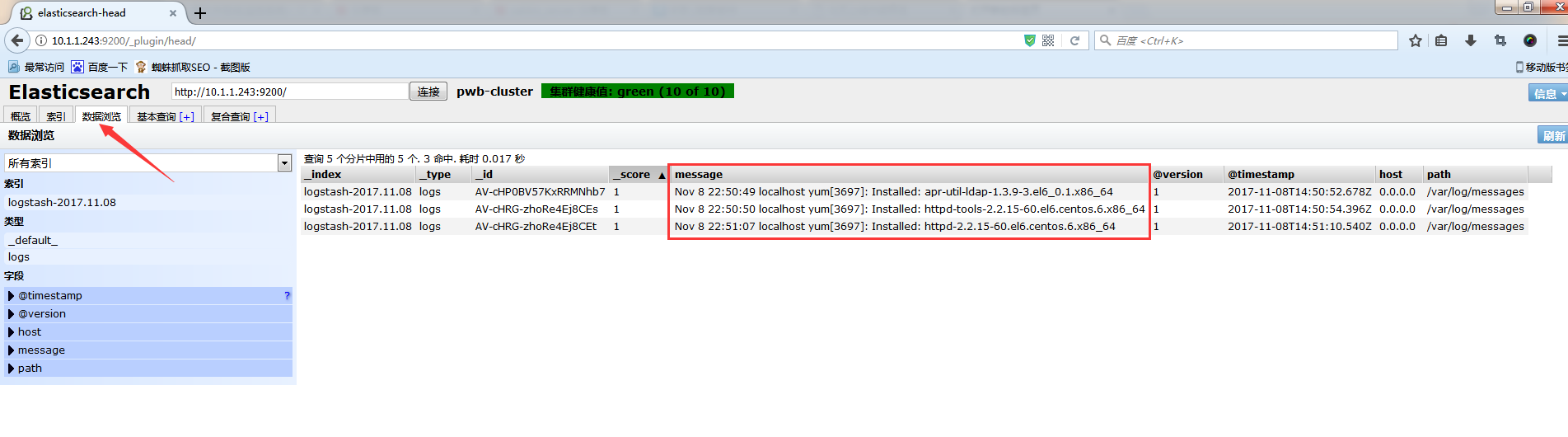
ok.已经看到logstash向elasticsearch集群可以正常写入,logstash配置完成(其他节点配置相同)
三、Kafka+zookeeper集群安装配置
在搭建kafka集群时,需要提前安装zookeeper集群,可以单独安装也可以使用kafka自带zookeeper程序,这里选择kafka自带的zookeeper程序
1.解压安装包
[root@kafka1 ~]# tar xf kafka_2.11-0.11.0.1.tgz -C /usr/local/
[root@kafka1 ~]# cd /usr/local/
[root@kafka1 local]# ln -sv kafka_2.11-0.11.0.1 kafka
"kafka" -> "kafka_2.11-0.11.0.1"
[root@kafka1 local]# cd kafka
2.配置zookeeper集群,修改配置文件
[root@kafka1 kafka]# grep "^[a-Z]" config/zookeeper.properties
dataDir=/Data/zookeeper
clientPort=2181
maxClientCnxns=0
tickTime=2000
initLimit=20
syncLimit=10
server.1=10.1.1.247:2888:3888
server.2=10.1.1.248:2888:3888
#说明:
tickTime: 这个时间是作为 Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。
2888端口:表示的是这个服务器与集群中的 Leader 服务器交换信息的端口;
3888端口:表示的是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的 Leader,而这个端口就是用来执行选举时服务器相互通信的端口
3.创建zookeeper所需要的目录和myid文件
[root@kafka1 kafka]# mkdir -pv /Data/zookeeper
mkdir: 已创建目录 "/Data"
mkdir: 已创建目录 "/Data/zookeeper"
[root@kafka1 kafka]# echo "1" > /Data/zookeeper/myid #myid文件,里面的内容为数字,用于标识主机,如果这个文件没有的话,zookeeper无法启动
4.kafka配置
[root@kafka1 kafka]# grep "^[a-Z]" config/server.properties
broker.id=1 #唯一
listeners=PLAINTEXT://10.1.1.247:9092 #服务器IP地址和端口
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/Data/kafka-logs #不需要提前创建
num.partitions=10 #需要配置较大,分片影响读写速度
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168 #过期时间
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=10.1.1.247:2181,10.1.1.248:2181 #zookeeper服务器IP和端口
zookeeper.connection.timeout.ms=6000
group.initial.rebalance.delay.ms=0
其他节点配置相同,除以下几点:
(1)zookeeper的配置
echo "x" > /Data/zookeeper/myid #唯一
(2)kafka的配置
broker.id=1 #唯一
host.name=本机IP
5.启动zookeeper和kafka
(1)启动zookeeper
[root@kafka1 kafka]# /usr/local/kafka/bin/zookeeper-server-start.sh /usr/local/kafka/config/zookeeper.properties &
后面两台执行相同操作,在启动过程当中会出现以下报错信息
java.net.ConnectException: 拒绝连接
at java.net.PlainSocketImpl.socketConnect(Native Method)
at java.net.AbstractPlainSocketImpl.doConnect(AbstractPlainSocketImpl.java:339)
at java.net.AbstractPlainSocketImpl.connectToAddress(AbstractPlainSocketImpl.java:200)
at java.net.AbstractPlainSocketImpl.connect(AbstractPlainSocketImpl.java:182)
at java.net.SocksSocketImpl.connect(SocksSocketImpl.java:392)
at java.net.Socket.connect(Socket.java:579)
at org.apache.zookeeper.server.quorum.QuorumCnxManager.connectOne(QuorumCnxManager.java:562)
at org.apache.zookeeper.server.quorum.QuorumCnxManager.toSend(QuorumCnxManager.java:538)
at org.apache.zookeeper.server.quorum.FastLeaderElection$Messenger$WorkerSender.process(FastLeaderElection.java:452)
at org.apache.zookeeper.server.quorum.FastLeaderElection$Messenger$WorkerSender.run(FastLeaderElection.java:433)
at java.lang.Thread.run(Thread.java:745)
[2017-11-08 23:44:36,351] INFO Resolved hostname: 10.1.1.248 to address: /10.1.1.248 (org.apache.zookeeper.server.quorum.QuorumPeer)
[2017-11-08 23:44:36,490] WARN Cannot open channel to 2 at election address /10.1.1.248:3888 (org.apache.zookeeper.server.quorum.QuorumCnxManager)
java.net.ConnectException: 拒绝连接
at java.net.PlainSocketImpl.socketConnect(Native Method)
at java.net.AbstractPlainSocketImpl.doConnect(AbstractPlainSocketImpl.java:339)
at java.net.AbstractPlainSocketImpl.connectToAddress(AbstractPlainSocketImpl.java:200)
at java.net.AbstractPlainSocketImpl.connect(AbstractPlainSocketImpl.java:182)
at java.net.SocksSocketImpl.connect(SocksSocketImpl.java:392)
at java.net.Socket.connect(Socket.java:579)
at org.apache.zookeeper.server.quorum.QuorumCnxManager.connectOne(QuorumCnxManager.java:562)
at org.apache.zookeeper.server.quorum.QuorumCnxManager.connectAll(QuorumCnxManager.java:614)
at org.apache.zookeeper.server.quorum.FastLeaderElection.lookForLeader(FastLeaderElection.java:843)
at org.apache.zookeeper.server.quorum.QuorumPeer.run(QuorumPeer.java:913)
由于zookeeper集群在启动的时候,每个结点都试图去连接集群中的其它结点,先启动的肯定连不上后面还没启动的,所以上面日志前面部分的异常是可以忽略的。通过后面部分可以看到,集群在选出一个Leader后,最后稳定了。
其他节点也可能会出现类似的情况,属于正常
zookeeper服务检查
[rootkafka1 ~]# netstat -nlpt | grep -E "2181|2888|3888"
tcp 0 0 :::2181 :::* LISTEN 33644/java
tcp 0 0 ::ffff:10.1.1.247:3888 :::* LISTEN 33644/java
[root@kafka2 ~]# netstat -nlpt | grep -E "2181|2888|3888"
tcp 0 0 :::2181 :::* LISTEN 35016/java
tcp 0 0 ::ffff:10.1.1.248:2888 :::* LISTEN 35016/java #哪台是leader,那么他就拥有2888端口
tcp 0 0 ::ffff:10.1.1.248:3888 :::* LISTEN 35016/java
(2)启动kafka
/usr/local/kafka/bin/kafka-server-start.sh /usr/local/kafka/config/server.properties &
如有以下报错
[2017-11-08 23:52:30,323] ERROR Processor got uncaught exception. (kafka.network.Processor)
java.lang.ExceptionInInitializerError
at kafka.network.RequestChannel$Request.<init>(RequestChannel.scala:124)
at kafka.network.Processor$$anonfun$processCompletedReceives$1.apply(SocketServer.scala:518)
at kafka.network.Processor$$anonfun$processCompletedReceives$1.apply(SocketServer.scala:511)
at scala.collection.Iterator$class.foreach(Iterator.scala:891)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1334)
at scala.collection.IterableLike$class.foreach(IterableLike.scala:72)
at scala.collection.AbstractIterable.foreach(Iterable.scala:54)
at kafka.network.Processor.processCompletedReceives(SocketServer.scala:511)
at kafka.network.Processor.run(SocketServer.scala:436)
at java.lang.Thread.run(Thread.java:745)
Caused by: java.net.UnknownHostException: kafka2.example.com: kafka2.example.com: 未知的名称或服务
at java.net.InetAddress.getLocalHost(InetAddress.java:1473)
at kafka.network.RequestChannel$.<init>(RequestChannel.scala:43)
at kafka.network.RequestChannel$.<clinit>(RequestChannel.scala)
... 10 more
Caused by: java.net.UnknownHostException: kafka2.example.com: 未知的名称或服务
at java.net.Inet6AddressImpl.lookupAllHostAddr(Native Method)
at java.net.InetAddress$1.lookupAllHostAddr(InetAddress.java:901)
at java.net.InetAddress.getAddressesFromNameService(InetAddress.java:1293)
at java.net.InetAddress.getLocalHost(InetAddress.java:1469)
... 12 more
编辑hosts文件,添加127.0.0.1 对当前主机名称的解析
[root@kafka1 ~]# cat /etc/hosts
127.0.0.1 kafka1.example.com localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
启动其他节点上的zookeeper和kafka
启动完成后,进行一下测试
(1)建立一个主题
[root@kafka1 ~]# /usr/local/kafka/bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 2 --partitions 1 --topic summer #注意:factor大小不能超过broker数,否则报错,当前集群broker值值为2
Created topic "summer".
(2)查看有哪些主题已经创建
[root@kafka1 ~]/usr/local/kafka/bin/kafka-topics.sh --list --zookeeper 10.1.1.247:2181 #列出集群中所有topic
summer
(3)查看topic的详情
[root@kafka1 ~]# /usr/local/kafka/bin/kafka-topics.sh --describe --zookeeper 10.1.1.247:2181 --topic summer
Topic:summer PartitionCount:1 ReplicationFactor:2 Configs:
Topic: summer Partition: 0 Leader: 2 Replicas: 2,1 Isr: 2,1
#主题名称:summer
#Partition:只有一个,从0开始
#leader :id为2的broker
#Replicas 副本存在于broker id为2,1的上面
#Isr:活跃状态的broker
(4)发送消息,这里使用的是生产者角色
[rootkafka1 ~]# /bin/bash /usr/local/kafka/bin/kafka-console-producer.sh --broker-list 10.1.1.247:9092 --topic summer
>Hello,MR.Pan #输入一些内容,回车
(5)接收消息,这里使用的是消费者角色
[root@kafka2 kafka]# /usr/local/kafka/bin/kafka-console-consumer.sh --zookeeper 10.1.1.247:2181 --topic summer --from-beginning
Using the ConsoleConsumer with old consumer is deprecated and will be removed in a future major release. Consider using the new consumer by passing [bootstrap-server] instead of [zookeeper].
Hello,MR.Pan
如果能够像上面一样能够接收到生产者发过来的消息,那说明基于kafka的zookeeper集群就成功啦。
六、配置客户端rsyslog
1.查看当前rsyslog版本
[root@log-client1 ~]# rsyslogd -v
rsyslogd 5.8.10, compiled with:
rsyslog对 kafka的支持是 v8.7.0版本后才提供的支持,所有需要升级系统rsyslog版本
2.升级rsyslog
wget http://rpms.adiscon.com/v8-stable/rsyslog.repo -O /etc/yum.repos.d/rsyslog.repo #下载yum源
yum update rsyslog -y #更新rsyslog
yum install rsyslog-kafka -y #安装rsyslog-kafka模块
ll /lib64/rsyslog/omkafka.so #查看模块是否安装完成
/etc/init.d/rsyslog restart #重启服务
查看更新后版本
[root@log-client1 yum.repos.d]#wrsyslogd -v
rsyslogd 8.30.0, compiled with:
3.下面测试将nginx日志通过rsyslog传递给kafka(nginx事先安装完毕)
(1)编辑rsyslog的配置文件
[root@log-client1 yum.repos.d]# cat /etc/rsyslog.d/nginx_kafka.conf
# 加载omkafka和imfile模块
module(load="omkafka")
module(load="imfile")
# nginx template
template(name="nginxAccessTemplate" type="string" string="%hostname%<-+>%syslogtag%<-+>%msg%\n")
# ruleset
ruleset(name="nginx-kafka") {
#日志转发kafka
action (
type="omkafka"
template="nginxAccessTemplate"
confParam=["compression.codec=snappy", "queue.buffering.max.messages=400000"]
partitions.number="4"
topic="test_nginx"
broker=["10.1.1.247:9092","10.1.1.248:9092"]
queue.spoolDirectory="/tmp"
queue.filename="test_nginx_kafka"
queue.size="360000"
queue.maxdiskspace="2G"
queue.highwatermark="216000"
queue.discardmark="350000"
queue.type="LinkedList"
queue.dequeuebatchsize="4096"
queue.timeoutenqueue="0"
queue.maxfilesize="10M"
queue.saveonshutdown="on"
queue.workerThreads="4"
)
}
# 定义消息来源及设置相关的action
input(type="imfile" Tag="nginx,aws" File="/var/log/nginx/access.log" Ruleset="nginx-kafka")
测试conf文件是否语法错误
[root@log-client1 yum.repos.d]# rsyslogd -N 1
rsyslogd: version 8.30.0, config validation run (level 1), master config /etc/rsyslog.conf
rsyslogd: End of config validation run. Bye.
测试没有问题后重启rsyslog,否则配置不生效
[root@log-client1 yum.repos.d]# /etc/init.d/rsyslog restart
启动nginx,添加两个测试页面,进行访问
切换到kafka集群服务器上,查看topic列表
[root@localhost ~]# /usr/local/kafka/bin/kafka-topics.sh --list --zookeeper 10.1.1.247:2181
summer
test_nginx
可以看到除了之前测试创建的summer,又多了一个test_nginx topic,配置成功
七、配logstash将kafka数据传输到elasticsearch
[root@logstash1 ~]# cat /usr/local/logstash/conf/test_nginx.conf
input {
kafka{
zk_connect => "10.1.1.247:2181,10.1.1.248:2181" #kafka集群
group_id => "logstash"
topic_id => "test_nginx"
reset_beginning => false
consumer_threads => 5
decorate_events => true
}
}
output {
elasticsearch {
hosts => ["10.1.1.243:9200","10.1.1.244:9200"] #elasticsearch集群
index => "test-nginx-%{+YYYY-MM-dd}" #数据量大的情况下按天创建索引,后期删除比较方便
}
}
测试语法
[root@logstash1 ~]# /usr/local/logstash/bin/logstash -f /usr/local/logstash/conf/test_nginx.conf -t
Configuration OK
启动服务,其余节点也开启服务
[root@logstash1 log]# /usr/local/logstash/bin/logstash -f /usr/local/logstash/conf/test_nginx.conf
Default settings used: Filter workers: 1
Logstash startup completed
切换到ES集群节点es1.example.com 查看:
[root@es1 ~]# curl -XGET '10.1.1.243:9200/_cat/indices?v&pretty'
health status index pri rep docs.count docs.deleted store.size pri.store.size
green open logstash-2017.11.08 5 1 4 0 40.7kb 20.3kb
green open test-nginx-2017-11 5 1 1 0 12.5kb 6.2kb
可以看到,test-nginx 索引已经有了
在访问head插件的web界面

再次访问测试下,使用强制刷新
访问head插件web界面:

最新的访问两条记录已经出来了
八、Kibana的部署
在ES集群节点上安装kibana
[root@es1 ~]# tar xf kibana-4.2.1-linux-x64.tar.gz -C /usr/local/
[root@es1 ~]# cd /usr/local/
[root@es1 local]# ln -sv kibana-4.2.1-linux-x64/ kibana
"kibana" -> "kibana-4.2.1-linux-x64/"
[root@es1 local]# cd kibana
[root@es1 kibana]# grep "^[a-Z]" config/kibana.yml #配置主机端口已经elasticsearch服务器IP地址和端口
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.url: "http://10.1.1.243:9200"
访问kibana,添加索引:
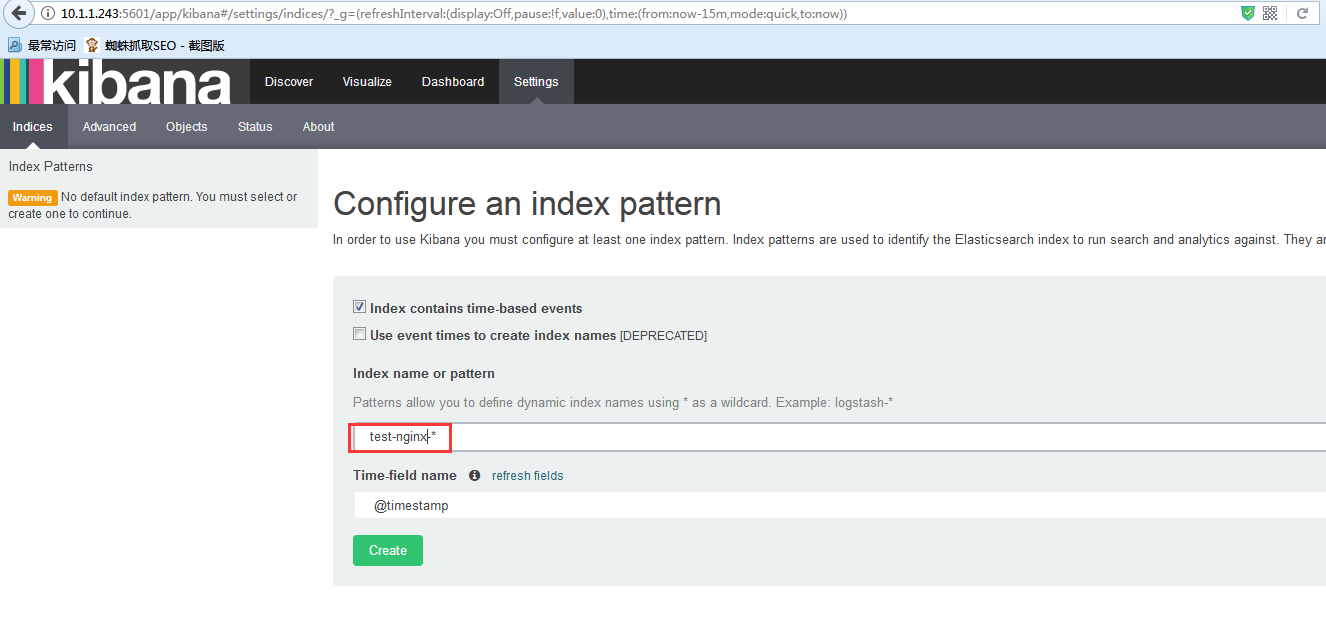
点击Discover,选择索引名称,查询
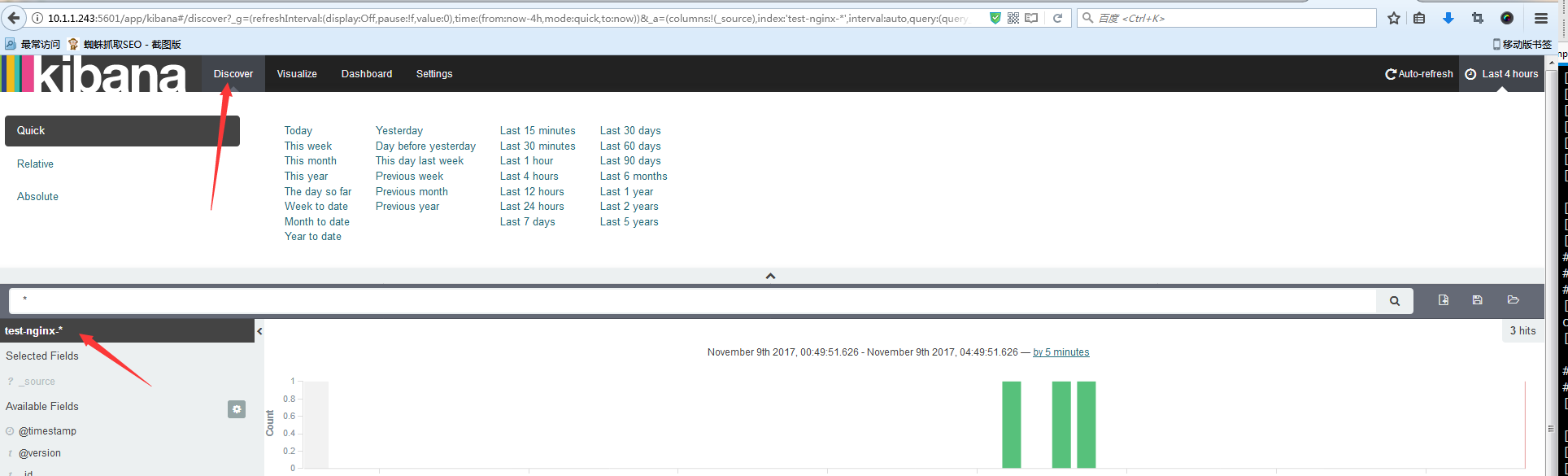
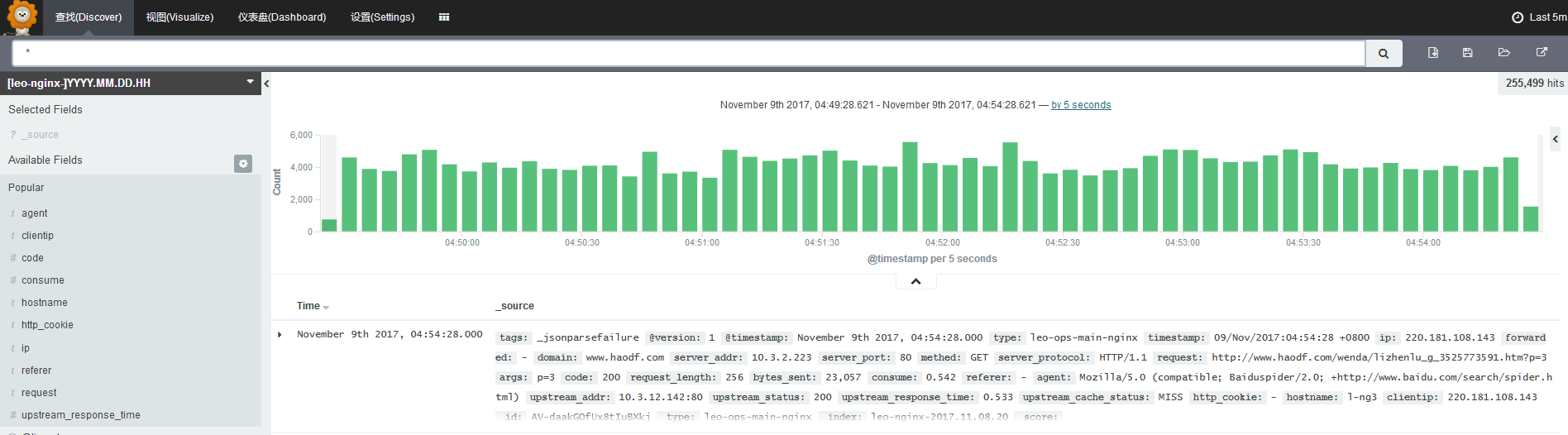
由于测试环境数据太少,下面我使用kibana查询生产环境数据:
默认查询:
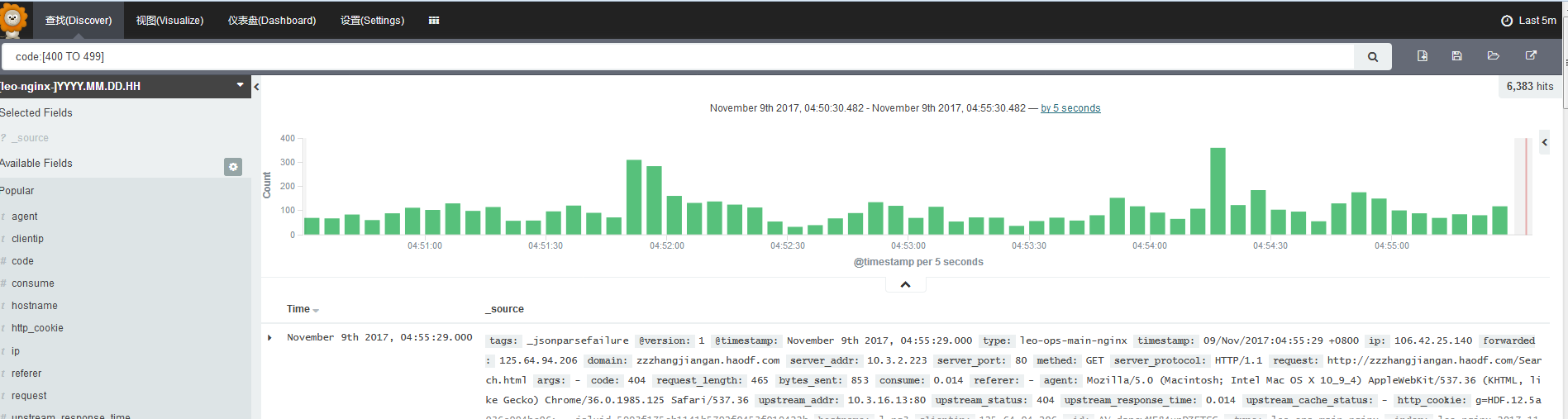
单个条件查询(查询状态码为4XX的访问)
多条件并查询(查询访问状态为4XX并且agent为百度蜘蛛的),多条件查询把AND改为OR就好了

着重说明一下URL查询,在kibana语法中有许多特殊字符,在查询时需要使用\进行转移,否则会报语法错误

视图:
创建一个视图,以饼图为例
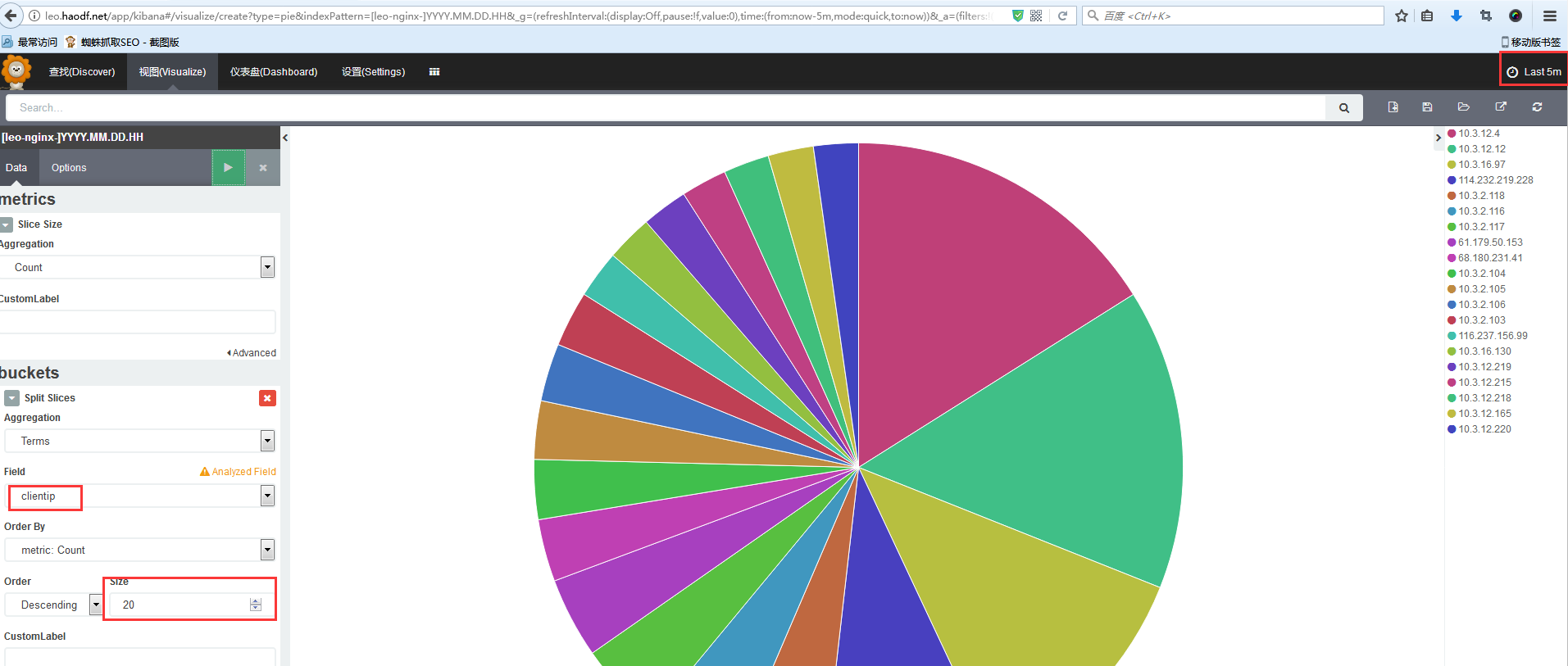
查询网站最后五分钟,排名前20的IP
kibana还有很多常用操作,还有kibana语法,大家可以查官方文档,或者百度和谷歌
nginx反向代理麻烦大家自行搭建测试,这里就不测试了
小结:在搭建的时候碰到很多坑,小弟想和大家分享一下
1.JDK版本不一致
使用yum安装时JDK小版本号不一致,会导致ES集群无法发现其他节点,另外官方也建议使用oracle JDK。
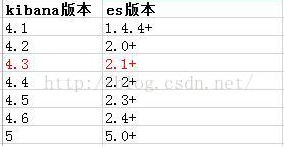
2.ELK版本选择
由于ELK在5.X之前版本比较混乱,很容易出错,这也是大家看到5.X之后ELK版本全部从5开始,错误如下图

百度和谷歌发现都是需要更改index.max_result_window值大小,看报错也是,但是测试发现是版本不匹配导致的,我整理了5,.X之前相关版本的对应关系,下图:
注意事项:
1.所有集群节点应当是奇数个
2.所有服务应配置为系统服务或使用nohup、screen等放入后台,如果使用nohup,注意out.put文件大小, 如果服务有问题,nohup的日志文件会非常大,会把磁盘占满
3.ES服务使用内存越大越好,但是不要超过32G
4.客户端日志收集工具有很多,有兴趣可以自己找资料看看
5.最权威的资料还是官方文档,https://www.elastic.co/guide/index.html 有兴趣可以看一下
写的不好,望各位大神海涵!!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号