
基于小黄鸡问答数据和Jieba的一个简单的问答系统
在看了一些简单的资料后,动手写一个简单的问答代码
一个问答系统流程(知乎,CSDN等获悉):(图片来自知乎)
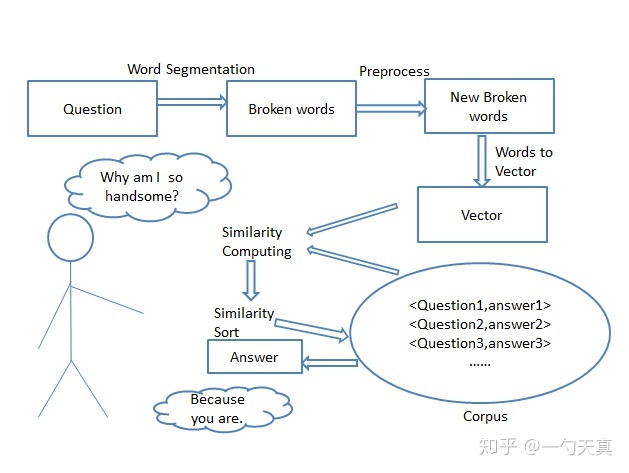
首先用户给出一个问题,然后我们对问题进行分词,其次进行预处理,量化,接着和语料库(存在着大量的问题和答案信息)中的问题进行相似度计算,最后对相似度进行排序,返回相似度最高的问题所对应的答案。优于小黄鸡数据集中问题短,符号少,且问题答案总是相邻,所以不用过多的预处理。
而我们要获得的是分词后不重复且有用的词:
#获得不重复分词 def get_word_all(ques_dic): temp1 = [] for i in range(0,len(ques_dic)): if ques_dic[i] and (ques_dic[i]!='M') and (ques_dic[i] != '\n') and (ques_dic[i] != ' '): temp1.append(ques_dic[i]) return temp1
其实向量化方法很多,而我们想法是两个问题比较时,以两个问题的公共词库为向量空间,类似于Bodean Vector,根据出现与否,转化为(0,1,1,0,...)的向量:
#向量获得 def get_word_vector(word1, word2): cut1 = jieba.cut(word1) cut2 = jieba.cut(word2) list_word1 = (','.join(cut1)).split(',') list_word2 = (','.join(cut2)).split(',') # 列出所有的词,取并集 key_word_temp = list(set(list_word1 + list_word2)) key_word = get_word_all(key_word_temp) #print(key_word) # 给定形状和类型的用0填充的矩阵存储向量 word_vector1 = np.zeros(len(key_word)) word_vector2 = np.zeros(len(key_word)) # 计算词频 # 依次确定向量的每个位置的值 for i in range(len(key_word)): # 遍历key_word中每个词在句子中的出现次数 for j in range(len(list_word1)): if key_word[i] == list_word1[j]: word_vector1[i] += 1 for k in range(len(list_word2)): if key_word[i] == list_word2[k]: word_vector2[i] += 1 # # 输出向量 # print(word_vector1) #print(word_vector2) vector={ 'ques_in':word_vector1, 'ques':word_vector2 } #result = self.cos_dist(word_vector1, word_vector2) return vector
然后计算余弦相似度:
#计算相似度 def Sim_get(vector): #余弦相似度 sim = float(np.dot(vector['ques_in'], vector['ques']) / (np.linalg.norm(vector['ques_in']) * np.linalg.norm(vector['ques']))) return sim
接着把相似度放入list中,找到相似度最大的那一个问题,进行答案匹配即可:
#获取相似度最高的答案 def get_ans(input_ques): sim_list = [] for i in range(1,10): Qes=linecache.getline("m.txt",2*i) # 读取问题行 #print(Qes) #seg_list_ans = jieba.lcut(Qes, cut_all=False) #ques_word = get_word_all(seg_list) #seg_list = jieba.lcut(Qes, cut_all=False) # 问题进行分词 #print(ques_word) Similarity = Sim_get(get_word_vector(input_ques, Qes)) sim_list.append(Similarity) #print(Similarity) pos,num = max_num(sim_list) #print(pos) if num >= 0.2: Ans = linecache.getline("m.txt", 2 * (pos + 1)+1)# 读取答案行 print("答案是:") print(Ans) else: print("未找到合适的答案,请您添加答案:\n") new_ans(input_ques)
当然,我们考虑到没有答案或者问题相似度过低时,可以自己添加答案:
#新问题添加新答案 def new_ans(ques): file = open("E:\py_projects\jieba_leearn\m.txt",'r', encoding='UTF-8') content = file.read() file.close() #print(type(content)) ques_add = ques+'\n' ans_add = input("请您输入你的答案:\n")+'\n' content = 'E\n'+ques_add+ans_add+content # print(type(content)) file1 = open("E:\py_projects\jieba_leearn\m.txt", "w",encoding='UTF-8') file1.write(content) file1.close() print(" 添加成功!\n")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号