OO第三单元总结回顾
OO第三单元总结回顾
-
JML(Java Modeling Language)是用于对Java程序进行规格化设计的一种表示语言。
-
JML的两种主要用法分别是开展规格化设计和针对已有代码实现书写其对应规格从而提高代码可维护性。我们在本单元中通过设计一个模拟社交网络,来学习JML和程序规格化设计,并理解JML在Java程序规格化设计中的作用。
1.设计策略
-
在实现JML要求的规格时,我觉得自己的工作就像一个翻译,负责将JML规格转换成可以执行的Java代码
-
比如,我会根据JML中的前置条件(pre-condition)设计不同的分支结构,根据JML的后置条件来具体确定分支结构中的内容
-
而这两者中往往蕴含大量的量化表达式:
\forall表达式,\exits表达式,\sum表达式,\max表达式,\min表达式等等 -
尽管JML和程序代码之间有很强的关联性,但是将一种量化表达式和一种代码结构捆绑起来仍然是不严谨、不合适的,这是因为代码实现的逻辑和JML描述逻辑的侧重点不同
-
举个例子,在第一次作业中我们需要实现一个连通性查询的函数,在JML描述里,看起来只需要存在一条长度不小于2的路径连接两者即可说明两者连通,但是在实际代码编写中,我们更关心的是如何找到这样的一条路径以及什么时候我们有理由表示找不到这样的路径
-
上面的例子总结成一句话,就是JML关心程序、函数执行的结果(What),而代码实现更注重过程(How)

所以,在实现规格的过程中,我都是先通读一个或几个函数的JML规格,在理解的基础上选择最合适的实现方式,这样既可以提高效率,也可以在一开始选择合适的设计,尽量避免重构。
2.测试方法和策略
课程介绍了一种针对不变式的检查。不变式本质上是对表示对象是否有效的判定。
- 不变式成立→对象有效→对象方法能够满足规格要求
测试时,编写一个public boolean repOK()方法,如果不变式成立,则返回值为true,反之为false。
- 如果一个对象的
rep不能支撑规格数据内容,则该对象不可能有效 - 如果一个对象的表示不变式成立,意味着对象一定有效
- 用户可以随时调用一个对象的
repOK检查一个对象的表示状态是否有效,即c.repOK()<==>invariant(c) - 测试程序时可以通过调用
repOK来判断程序是否出现了问题 - 在实现一个类时,
repOK应该与不变式在早于任何其他方法之前实现
课程还介绍了基于规格的测试,可以分为准备数据、准备场景和自动化
- 准备数据需要对前置条件进行划分,并区分出后置条件涉及到的数据,明确用以判断状态是否正确的参考数据
- 准备场景需要模拟使用者对象与被测对象的交互,往往是通过条用被测对象提供的方法来实现,测试场景一般比单一的方法调用更容易发现错误
- 自动化可以借助一些工具如
Junit实现,自动化测试有利于做回归测试。
3.架构设计
结构设计自顶而下是MyNetwork-MyGroup-MyPerson-MyMessage。
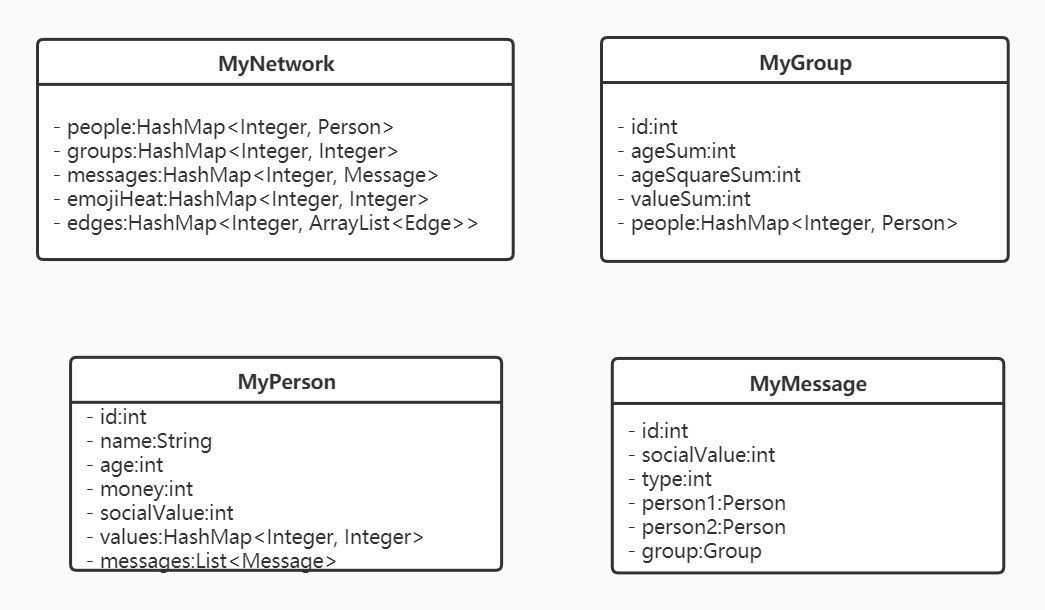
- 最高层
MyNetwork是整个社交网络类,管理所有社交网络中的人和组,在将人添加到一个组中时,需要对组内valueSum,ageSum,ageSquareSum,edges进行维护 MyGroup是对社交网络中所有成员的划分,类似于群聊。MyPerson具有values容器,存储和该用户有relation的其他用户的id,messages容器中存放最近收到的Message。MyMessage是消息类,向下还派生出NoticeMessage,RedEnvelopMessage,EmojiMessage类。
在我的代码实现中,对于图的维护主要体现在采用并查集查询连通性时需要维护一个森林。
- 在添加新的
Relation时,需要判断两个人的祖先节点是否相同 - 相同则不作处理
- 而如果不同则需要将一个节点的祖先节点的祖先设置为另一个节点的祖先节点
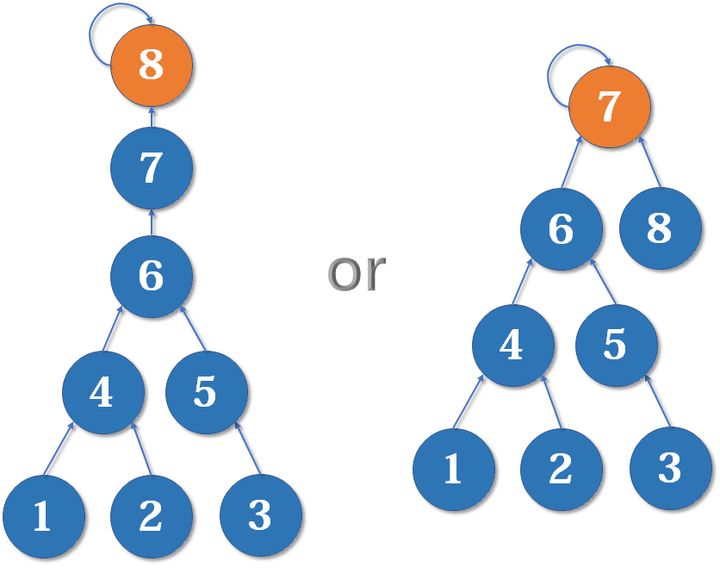
- 为了避免出现树退化成伪链表,需要记录每个节点的高度,在合并两棵树时,优先将高度小的树合并入高度大的树的根节点之下,这样可以有效防止退化
4.经验总结
- 社交网络信息量巨大,所以选择合适的容器在本单元尤为重要
- 我们为了管理
Person、Message、Emoji这些类,为它们定义了各自独一无二的id,于是很自然地想到对于这些数据的管理可以使用Java中的HashMap容器,将独一无二的id作为Key将相应类型的变量作为Value - 在小数据样本下,使用
HashMap可以使查询效率达到完美的O(1),而当样本容量过大时,取决于散列算法的不同,碰撞率会不同程度地上升,在这种情况下可能需要设计新的容器类型或存储算法来对数据做进一步管理
-
在遍历容器时,我曾经遇到过在
for(Person p:persons)中调用remove或add引起ConcurrentModifycationException,原因是在遍历的时候都会对当前迭代器中的modCount与当前遍历的集合类实例中的modCount进行比较,如果不同就会抛出ConcurrentModifycationException这个异常,而remove和add方法会造成modCount++ -
正确的遍历方式应该是使用迭代器
Iterator进行遍历,在删除时调用Iterator.remove()
在三次作业强测和互测中,由于课下控制了每个函数的复杂度并进行了一定强度的性能测试,我都没有出现性能上的问题。下面是我的两条经验:
-
将复杂度分散
- 以第二次作业中计算
Group内ValueSum为例,最直接的方法自然是找出所有Group内Relation计算其总和,由于需要双层循环遍历整个Group,时间复杂度为O(N^2) - 而分散复杂度的设计就是将O(N^2)分散在每个
Group中的Person和每条Group中的Relation上 - 首先定义一个能够实时变化的
valuSum成员变量,在将一个Person加入Group时,遍历所有连通Person的人将两者的value加入到valueSum - 在新增一条
Relation时,判断Relation双方是否同属于某一个Group,如果是则更新其valueSum - 经过分散复杂度,计算
valueSum方法的复杂度下降到O(1),而之前复杂度均为O(1)的addPerson和addRelation方法的复杂度仅仅上升到O(N)和O(M) *,复杂度成功降低
- 以第二次作业中计算
-
重视算法
- DFS,BFS,并查集、迪杰斯特拉......在保证正确性的前提下,也应该对算法的巧妙之处和局限性进行思考,选择最佳算法,除此之外,即使是相同的算法,不同人也有不同的实现方式,这也可能带来性能上的差异
*注:N为总人数,M为总组数

 浙公网安备 33010602011771号
浙公网安备 33010602011771号