
TensorFlow对象检测-1.0和2.0:训练,导出,优化(TensorRT),推断(Jetson Nano)
作者|Abhishek
编译|Flin
来源|analyticsvidhya
第1部分
从在自定义数据集中训练检测器到使用TensorFlow 1.15在Jetson纳米板或云上进行推理的详细步骤
完整代码可在GitHub上获得
-
TensorFlow对象检测API V2的教程可作为jupyter notebook使用
-
TensorFlow对象检测API V1的教程可作为jupyter notebook使用
一些常见的困难包括
-
使用对象检测API库查找兼容的TensorFlow(和相关的cuda)版本
-
将自定义数据转换为tf记录格式
-
混淆了tf1.0和tf2.0的流程
-
手动更新模型配置文件以进行训练
-
运行训练过程并解决配置文件中的问题
-
将模型从一种格式导出到另一种格式以进行推理
-
混合了不同的模型格式类型——检查点、冻结图、saved_model (" .pb ")、tensorRT推断图等等
-
在训练模型上运行推理
-
将训练后的模型转换为量化格式,以便部署在诸如Jetson Nano的板上
-
构建引擎和部署引擎之间的tensorRT版本和cuda计算能力不匹配
这个清单永无止境……
为克服上述一些问题,我们在Monk Object Detection Toolkit中的Tensorflow 对象检测 API的两个版本上添加了一个低代码的pythonic包装器

使用它,开发人员和研究人员可以轻松地
-
使用TF推送定制训练数据集
-
使用pythonic API配置所有参数的模型文件
-
根据使用的网络和cuda版本的可用性,在TF1.0和TF2.0之间进行选择
-
根据自己的数据集训练、导出、优化、推断
-
使用TensorRT优化模型并导出到云服务器或Jetson Nano等嵌入式板
传统流程概述
下面提到的是使用TF训练和部署定制探测器的过程。在描述过程流程的同时,还强调了一个人在使一切正常工作时所面临的问题;还提到了tf1.0和2.0版本的对象检测库的区别
过程A:TensorFlow与目标检测装置的兼容性

-
要使用对象检测 2.0,请使用TensorFlow 2.3.0。版本2.0.0和2.1.0通常会导致“ tensorflow_core.keras.utils”. 2.2.0版在使用“CollectiveAllReduceExtended”模块进行训练时会导致错误。
-
使用TensorFlow 2.3.0时,需要Cuda 10.1。
-
要使用对象检测 1.0,请使用TensorFlow版本1.15.0或1.15.2。
-
使用TensorFlow 1.15时,需要Cuda 10.0。
-
TFLite转换仍然存在某些错误(将在以后的博客中讨论)
过程B:设置数据集

-
TensorFlow提供数据集工具以将数据转换为可接受的TF记录格式
-
但是这些示例仅适用于最常用的数据集,例如COCO,Pascal VOC,OpenImages,Pets-Dataset等。用户需要根据选择的示例笔记本,按照COCO、VOC、OID等格式重新格式化和排列数据集
-
另一种方法是更新示例代码以便提取自定义数据集,这本身就是一个艰难的过程
-
为了使自定义数据集的加载变得容易,我们修改了示例并添加了进一步的解析器以支持多种数据注释类型,并将其直接转换为TF-Records。
过程C:更新配置并开始训练过程

-
Monk的对象检测API 1.0包装器支持大约23个模型,对象检测API 2.0支持大约26个模型
-
一旦选择了模型并下载了权重,就必须手动更新配置文件。
-
API 1.0和2.0的配置文件格式不同,需要以稍微不同的方式进行手动更改
-
tf1.0中的某些配置存在基本特征提取参数的问题。
-
在对配置文件应用更新后,整个工作区必须按照TF Obj github site站点上的教程指定的方式进行安排。
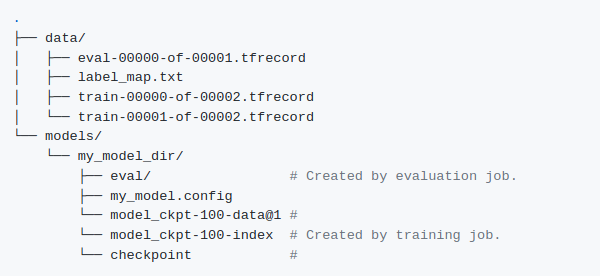
-
重新安排后,可以开始训练。同样,针对TF 1.0和TF 2.0模型的训练是不同的。
-
通过“Monk对象检测”,我们添加了pythonic函数来更新配置文件,并且不再需要为工作空间使用严格的文件夹结构。两种TF版本的训练过程几乎都与Monk的包装程序相同。
过程D:导出经过训练的模型以进行推理

-
两种对象检测API均以检查点 (“.ckpt”) 格式提供训练有素的模型。
-
为了在TF 1.0中进行推理,通常使用冻结图形格式。
-
为了在TF 2.0中进行推理,通常使用保存的模型格式。
-
特别是对于初学者来说,转换模型的过程在两个API中都不相同,通常很难弄清楚
-
为了简化流程,我们添加了解析器,以使外部包装器格式保持相同,这意味着我们能同时使用TF 1.0 API和TF 2.0 API。
过程E:TensorRT推论的模型优化

-
导出的模型最终使用TensorRT转换为优化版本。
-
支持的优化包括浮点32位和16位(FP32,FP16)和整数8位(INT8)量化。
-
从tf1.0和tf2.0转换导出模型的量化过程是完全不同的。
-
TensorRT的版本存在其他问题。这意味着,使用TensorRT版本5.1.5优化的模型无法在使用TensorRT版本5.1.6的部署计算机上运行。一个非常具体的问题是使用TensorFlow 1.15.0的对象检测1.0。这个TensorFlow带有tensorRT 5.1.5,而Jetpacks中没有这样的版本。
-
TensorRT的另一个问题是cuda计算功能。意思是,除非采取适当措施,否则在具有7.0版计算能力的GPU(V100 Nvidia GPU)上优化的模型不能在具有5.3版计算能力的GPU(Jetson纳米板)上运行。
-
此博客通过训练和优化对象检测模型澄清了所有疑问
过程F:在Jetson Nano板上设置所有东西
- 由于两个API都需要不同的TensorFlow版本,因此安装过程有所不同,Jetpack版本,CUDA版本以及TF 1.0在涉及tensorRT版本时都需要进一步注意。
让我们从版本1.0开始,每次使用一个对象检测API模块。

TF对象检测API 1.0
过程A:在开发机器上安装
将要安装的库
-
先决条件:numpy,scipy,pandas,pillow,OpenCV-python
-
带TensorRT 5.1.5的TensorFlow-GPU V1.15.0;如果在Nano板上部署则不需要
-
带TensorRT 6.0.1的TensorFlow-GPU V1.15.2;如果在Nano板上进行部署,则需要
-
使用Monk Object Detection Toolkit的TF 对象检测 API 1.0
(确保CUDA 10.0和CUDNN 7随系统一起安装了NVidia驱动程序)
当模型要部署在Jetson Nano板上时,请按照以下说明配置你的开发(训练)机器
安装必备的Python库
$ git clone https://github.com/Tessellate-Imaging/Monk_Object_Detection.git
$ cd Monk_Object_Detection/12_tf_obj_1/installation
$ chmod +x install_cuda10_tensorrt6_part1.sh && ./install_cuda10_tensorrt6_part1.sh
安装TensorRT 6.0.1
# Go to https://developer.nvidia.com/tensorrt
# Download
# - nv-tensorrt-repo-ubuntu1804-cuda10.0-trt6.0.1.5-ga-20190913_1-1_amd64.deb (For Ubuntu18.04)
# - nv-tensorrt-repo-ubuntu1604-cuda10.0-trt6.0.1.5-ga-20190913_1-1_amd64.deb (For Ubuntu16.04)
# Run the following commands to install trt (in a terminal)
$ sudo dpkg -i nv-tensorrt-repo-ubuntu1804-cuda10.0-trt6.0.1.5-ga-20190913_1-1_amd64.deb
$ sudo apt-key add <key value will be mentioned as the output of previous command>
$ sudo apt-get update
$ sudo apt-get install tensorrt
$ sudo apt-get install uff-converter-tf
$ sudo apt-get install python3-libnvinfer-dev
安装Bazel 0.26.1并从GitHub克隆TensorFlow
# Install bazel version 0.26.1
# Download bazel deb package from https://github.com/bazelbuild/bazel/releases/tag/0.26.1
$ sudo dpkg -i bazel_0.26.1-linux-x86_64.deb
# Clone Tensorflow and switch to tensorflow 1.15.2
$ git clone https://github.com/tensorflow/tensorflow.git
$ cd tensorflow
$ git checkout v1.15.2
配置TensorFlow
# Configure tensorflow
$ ./configure
- Do you wish to build TensorFlow with XLA JIT support? [Y/n]: Y
- Do you wish to build TensorFlow with OpenCL SYCL support? [y/N]: N
- Do you wish to build TensorFlow with ROCm support? [y/N]: N
- Do you wish to build TensorFlow with CUDA support? [y/N]: Y
- Do you wish to build TensorFlow with TensorRT support? [y/N]: Y
- And press enter (set default) for all other config questions asked by the setup
构建并安装TensorFlow(在AWS P3.2x实例上大约需要5个小时)
# Build tensorflow using bazel
$ bazel build --config=opt --config=cuda //tensorflow/tools/pip_package:build_pip_package
# Once built create a wheel file for python installation and run pip installer
$ bazel-bin/tensorflow/tools/pip_package/build_pip_package tensorflow_pkg
$ cd tensorflow_pkg && pip install tensorflow*.whl
最后构建对象检测API 1.0
# Compile Object Detection API v1
$ cd Monk_Object_Detection/12_tf_obj_1/installation
$ chmod +x install_cuda10_tensorrt6_part2.sh && ./install_cuda10_tensorrt6_part2.sh
当不打算在Jetson Nano Board上部署模型时,请按照以下说明配置你的开发(训练)机器
安装所有必需的库并编译对象检测API 1.0
$ git clone https://github.com/Tessellate-Imaging/Monk_Object_Detection.git
$ cd Monk_Object_Detection/12_tf_obj_1/installation
$ chmod +x install_cuda10.sh && ./install_cuda10.sh
安装TensorRT 5.1.5作为预构建的TensorFlow 1.15.0支持
# Go to https://developer.nvidia.com/tensorrt
# Download
# - nv-tensorrt-repo-ubuntu1804-cuda10.0-trt5.1.5.0-ga-20190427_1-1_amd64.deb (For Ubuntu18.04)
# - nv-tensorrt-repo-ubuntu1604-cuda10.0-trt5.1.5.0-ga-20190427_1-1_amd64.deb(For Ubuntu16.04)
# Run the following commands to install trt (in a terminal)
$ sudo dpkg -i nv-tensorrt-repo-ubuntu1804-cuda10.0-trt5.1.5.0-ga-20190427_1-1_amd64.deb
$ sudo apt-key add <key value will be mentioned as the output of previous command>
$ sudo apt-get update
$ sudo apt-get install tensorrt
$ sudo apt-get install uff-converter-tf
$ sudo apt-get install python3-libnvinfer-dev
使用google colab时,请遵循以下说明(TensorRT在colab上可能无法正常运行)
# Switch to TF 1.0 version (Run the following line)
$ %tensorflow_version 1.x
# Now reset the runetime if prompted by colab
# Run the following commands
$ git clone https://github.com/Tessellate-Imaging/Monk_Object_Detection.git
$ cd Monk_Object_Detection/12_tf_obj_1/installation
$ chmod +x install_colab.sh && ./install_colab.sh
过程B:建立数据集
Monk对象检测解析器要求数据集采用COCO或Pascal VOC格式。对于本教程,让我们坚持使用Pascal VOC格式
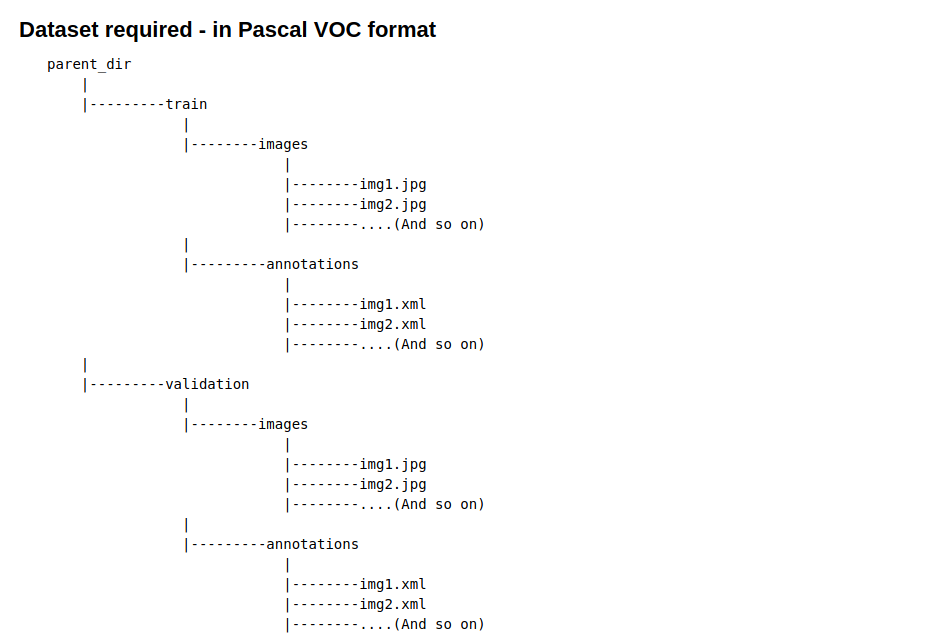
要将数据集从任何格式转换为Pascal VOC,请查看以下详细教程
在这个例子中,船检测数据集取自一个关于使用retinanet进行对象检测的旧博客
- 船检测数据集:https://www.tejashwi.io/object-detection-with-fizyr-retinanet/
- 博客:https://www.tejashwi.io/object-detection-with-fizyr-retinanet/
在这个jupyter notebook中提到了使用这些数据的步骤
过程C:更新配置并启动训练过程
加载训练引擎
from train_detector import Detector
gtf = Detector();
在TF 1.15模型库中加载所有可用模型
目前,它支持24种不同型号的SSD和Faster RCNN

加载训练验证数据集
将注释转换为VOC格式后加载数据集
根据可用的GPU设置批次大小。在本教程中,使用了带v100gpu(16gbvram)的AWS ec2p3.2x计算机,批次大小为24非常适合。
train_img_dir = "ship/images/Train";
train_anno_dir = "ship/voc/";
class_list_file = "ship/classes.txt";
gtf.set_train_dataset(train_img_dir, train_anno_dir, class_list_file, batch_size=24)
运行解析器将数据集转换为tfrecords
Tf Record文件将存储在data_tfrecord文件夹中
gtf.create_tfrecord(data_output_dir="data_tfrecord")
选择并加载模型
下载模型后,Monk会根据所选参数自动更新配置文件
在本教程中,我们使用了SSD MobileNet V1,它可以接收形状为320x320x3 RGB图像的输入图像
gtf.set_model_params(model_name="ssd_mobilenet_v1")
设置其他训练和优化器参数
set_hyper_params(num_train_steps=10000,
lr=0.004,
lr_decay_rate=0.945,
output_dir="output_dir/",
sample_1_of_n_eval_examples=1,
sample_1_of_n_eval_on_train_examples=5,
checkpoint_dir=False,
run_once=False,
max_eval_retries=0,
num_workers=4,
checkpoint_after_every=500)
设置存储导出参数的目录
gtf.export_params(output_directory="export_dir");
设置tensorRT优化参数
TensorRT优化器创建一个计划,然后构建它。构建计划是为了优化它正在构建的GPU的模型。
如前所述,在具有不同cuda计算能力的GPU上优化的模型无法在jetson nano上运行,因此Monk库确保该计划在开发机(云或colab)上编译,而该计划则在运行时在部署机(jetson nano)上构建
使用INT8优化时,无法执行此功能,计划的编制和构建都必须在同一台机器上,并且Jetson纳米板与8位整数运算不太兼容
gtf.TensorRT_Optimization_Params(conversion_type="FP16", trt_dir="trt_fp16_dir")
训练探测器
检测器训练运行一个执行sys.exit()函数的会话,因此在其上运行的包装程序将关闭python系统。
为了解决此问题,提供了一个名为train.py的脚本,该脚本可以在jupyter notebook或终端命令上运行
根据参数设置,训练好的模型将保存在名为“ output_dir”的文件夹中。
# Run in a terminal
$ python Monk_Object_Detection/12_tf_obj_1/lib/train.py
# or run this command on a jupyter notebook
%run Monk_Object_Detection/12_tf_obj_1/lib/train.py
过程D:导出经过训练的模型以进行推理
导出训练有素的检查点模型
export函数运行一个执行sys.exit()函数的会话,因此在其上运行的包装器将关闭python系统。
为了解决此问题,提供了一个名为export.py的脚本,该脚本可以在jupyter notebook或终端命令上运行
根据参数设置,导出的模型将保存在名为“ export_dir”的文件夹中。
# Run in a terminal
$ python Monk_Object_Detection/12_tf_obj_1/lib/export.py
# or run this command on a jupyter notebook
%run Monk_Object_Detection/12_tf_obj_1/lib/export.py
过程E:TensorRT推论的模型优化
优化导出模型
优化函数运行一个执行sys.exit()函数的会话,因此在其上运行的包装程序将关闭python系统。
为了解决此问题,提供了一个名为optimize.py的脚本,该脚本可以在jupyter notebook电脑或终端命令上运行
根据参数设置,优化的模型将保存在名为“ trt_fp16_dir”的文件夹中。
# Run in a terminal
$ python Monk_Object_Detection/12_tf_obj_1/lib/optimize.py
# or run this command on a jupyter notebook
%run Monk_Object_Detection/12_tf_obj_1/lib/optimize.py
过程F-1:在开发机器上运行推理
加载推理机
from infer_detector import Infer
gtf = Infer();
载入模型
首先加载导出的模型并运行步骤,然后通过加载优化的模型重复相同的步骤(步骤保持不变)
# To load exported model
gtf.set_model_params('export_dir/frozen_inference_graph.pb', "ship/classes.txt")
# To load optimized model
gtf.set_model_params('trt_fp16_dir/trt_graph.pb', "ship/classes.txt")
对单个图像进行推断
scores, bboxes, labels = gtf.infer_on_image('ship/test/img1.jpg', thresh=0.1);

使用两个模型运行速度测试分析
gtf.benchmark_for_speed('ship/test/img1.jpg')
在AWS P3.2x V100 GPU上使用导出的模型(未优化)进行分析
Average Image loading time : 0.0091 sec
Average Inference time : 0.0103 sec
Result extraction time : 0.0801 sec
total_repetitions : 100
total_time : 1.0321 sec
images_per_sec : 96
latency_mean : 10.3218 ms
latency_median : 10.3234 ms
latency_min : 9.4773 ms
在AWS P3.2x V100 GPU上使用优化模型进行分析
处理后优化使速度提高约2.5倍
Average Image loading time : 0.0092 sec
Average Inference time : 0.0042 sec
Result extraction time : 0.0807 sec
total_repetitions : 100
total_time : 0.4241 sec
images_per_sec : 235
latency_mean : 4.2412 ms
latency_median : 4.2438 ms
latency_min : 4.0156 ms
过程F-3:在Jetson Nano板上安装步骤
步骤1:更新Apt
$ sudo apt-get update
$ sudo apt-get upgrade
步骤2:安装系统库
$ sudo apt-get install nano git cmake libatlas-base-dev gfortran libhdf5-serial-dev hdf5-tools nano locate libfreetype6-dev python3-setuptools protobuf-compiler libprotobuf-dev openssl libssl-dev libcurl4-openssl-dev cython3 libxml2-dev libxslt1-dev python3-pip
$ sudo apt-get install libopenblas-dev libprotobuf-dev libleveldb-dev libsnappy-dev libhdf5-serial-dev protobuf-compiler libgflags-dev libgoogle-glog-dev liblmdb-dev
$ sudo pip3 install virtualenv virtualenvwrapper
步骤3:更新bashrc文件
将这些行添加到〜/ .bashrc文件
export VIRTUALENVWRAPPER_PYTHON=/usr/bin/python3
export WORKON_HOME=$HOME/.virtualenvs
export VIRTUALENVWRAPPER_VIRTUALENV=/usr/local/bin/virtualenv
source /usr/local/bin/virtualenvwrapper.sh
export PATH=/usr/local/cuda-10.0/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda-10.0/lib64\
${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
运行以下命令
$ source ~/.bashrc
步骤4:创建虚拟环境并安装所有必需的python库,安装numpy大约需要15分钟
$ mkvirtualenv -p /usr/bin/python3.6 tf2
$ pip install numpy==1.19.1
安装scipy大约需要40分钟
$ pip install scipy==1.5.1
安装Jetson Nano TensorFlow-1.15。再花15分钟
$ pip install scikit-build protobuf cython -vvvv
$ pip install grpcio absl-py py-cpuinfo psutil portpicker six mock requests gast h5py astor termcolor protobuf keras-applications keras-preprocessing wrapt google-pasta -vvvv
$ pip install https://developer.download.nvidia.com/compute/redist/jp/v43/tensorflow-gpu/tensorflow_gpu-1.15.0+nv19.12-cp36-cp36m-linux_aarch64.whl -vvvv
安装OpenCV需要1.5个小时
$ mkdir opencv && cd opencv
$ wget -O opencv.zip https://github.com/opencv/opencv/archive/4.1.2.zip
$ unzip opencv.zip
$ mv opencv-4.1.2 opencv
$ cd opencv && mkdir build && cd build
$ cmake -D CMAKE_BUILD_TYPE=RELEASE -D WITH_CUDA=OFF -D WITH_CUBLAS=OFF -D WITH_LIBV4L=ON -D BUILD_opencv_python3=ON -D BUILD_opencv_python2=OFF -D BUILD_opencv_java=OFF -D WITH_GSTREAMER=ON -D WITH_GTK=ON -D BUILD_TESTS=OFF -D BUILD_PERF_TESTS=OFF -D BUILD_EXAMPLES=OFF -D OPENCV_ENABLE_NONFREE=OFF ..
$ make -j3
$ sudo make install
$ cd ~/.virtualenvs/tf2/lib/python3.6/site-packages
$ ln -s /usr/local/lib/python3.6/site-packages/cv2/python-3.6/cv2.cpython-36m-aarch64-linux-gnu.so cv2.so
最后克隆Monk对象检测库并安装TF对象检测API
$ git clone https://github.com/Tessellate-Imaging/Monk_Object_Detection.git
$ cd Monk_Object_Detection/12_tf_obj_1/installation/
$ chmod +x install_nano.sh && ./install_nano.sh
过程F-4:关于Jetson Nano的推论
将优化的权重文件夹复制/下载到jetson nano工作目录(克隆Monk库)
从Monk_Object_Detection库复制示例图像
$ cp -r Monk_Object_Detection/example_notebooks/sample_dataset/ship .
加载推理引擎和模型(此步骤大约需要4到5分钟)
from infer_detector import Infer
gtf = Infer();
gtf.set_model_params('trt_fp16_dir/trt_graph.pb', "ship/classes.txt")
现在,如前所述,TensorRT负责计划并在运行时构建(优化)计划,因此第一次运行大约需要3-4分钟
scores, bboxes, labels = gtf.infer_on_image('ship/test/img5.jpg', thresh=0.5, img_size=300);
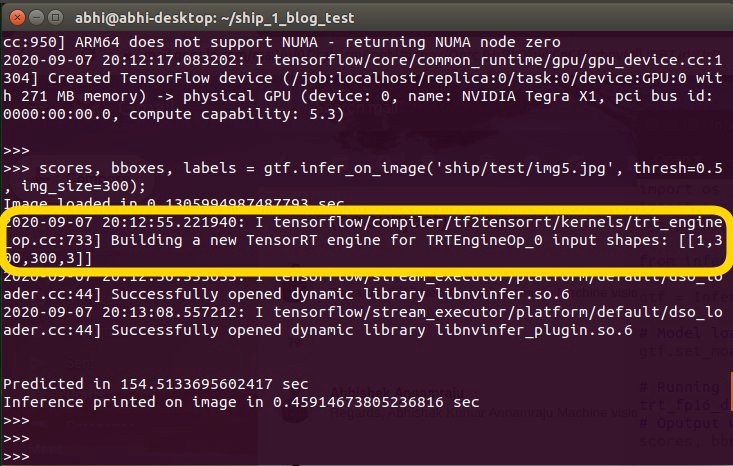
突出显示的区域显示了Jetson Nano的TesnorRT建立(优化)计划(模型)(作者拥有的图像)
再次运行它不会花费太多时间。
Benchmark板基准分析
gtf.benchmark_for_speed('ship/test/img1.jpg')
# With Jetson Nano power mode - 5W ModeAverage Image loading time : 0.0275 sec
Average Inference time : 0.0621 sec
total_repetitions : 100
total_time : 6.2172sec
images_per_sec : 16
latency_mean : 67.1722 ms
latency_median : 60.7875 ms
latency_min : 57.4391 ms
# With Jetson Nano power mode - MAXN ModeAverage Image loading time : 0.0173 sec
Average Inference time : 0.0426 sec
total_repetitions : 100
total_time : 4.2624 sec
images_per_sec : 23
latency_mean : 42.6243 ms
latency_median : 41.9758 ms
latency_min : 40.9001 ms
jupyter notebook提供TensorFlow对象检测API 1.0的完整代码
从谷歌驱动器下载所有预先训练的权重
第2部分
从在自定义数据集上训练检测器到在Jetson纳米板或云上使用TensorFlow 2.3进行推理的详细步骤

TF对象检测API 2.0
过程A:在开发机器上安装
要安装的库
前提条件:numpy,scipy,pandas,pandas,pillow,OpenCV-python
带TensorRT 6.0.1的TensorFlow-GPU V2.3.0
使用Monk Object Detection Toolkit的TF Object Detection API 2.0
将进行TensorRT安装
后续部分(确保CUDA 10.0和CUDNN 7随系统一起安装了NVidia驱动程序)
在开发(训练)机器中运行以下步骤
$ git clone https://github.com/Tessellate-Imaging/Monk_Object_Detection.git
#For Cuda 10 systems
$ cd Monk_Object_Detection/13_tf_obj_1/installation && chmod +x install_cuda10.sh && ./install_cuda10.sh
#For Google colab
$ cd Monk_Object_Detection/13_tf_obj_1/installation && chmod +x install_colab.sh && ./install_colab.sh
过程B:建立数据集
这与第1部分中的相同。Monk对象检测解析器要求数据集采用COCO或Pascal VOC格式。对于本教程,让我们坚持使用Pascal VOC格式
要将你的数据集从任何格式转换为Pascal VOC,请查看以下详细教程
在此示例中,船检测数据集是从一篇对象检测的旧博客中获取的
此jupyter notebook中提到了使用数据的步骤
过程C:更新配置并开始训练过程
加载训练引擎
from train_detector import Detector
gtf = Detector();
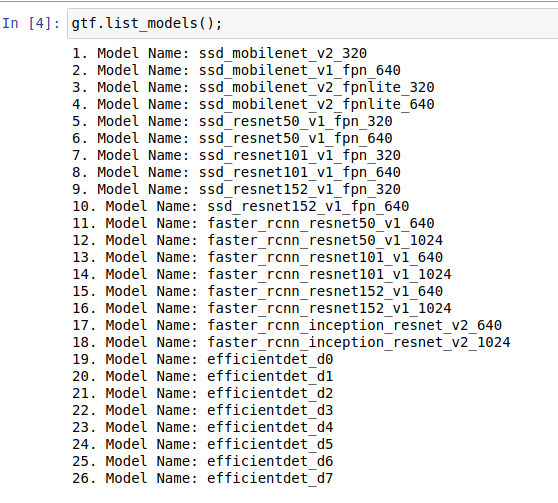
在TF 2.0 Model Zoo中加载所有可用的模型
目前,它支持26种SSD,Faster RCNN和EfficientDet不同的型号
即将添加对Centernet模型的支持,原始管道在训练中有错误
加载训练和验证数据集
将注释转换为VOC格式后加载数据集
根据可用的GPU设置批处理大小。在本教程中,使用了具有V100 GPU(16 GB VRAM)的AWS EC2 P3.2x计算机,批次大小为24非常适合。
train_img_dir = "ship/images/Train";
train_anno_dir = "ship/voc/";
class_list_file = "ship/classes.txt";
gtf.set_train_dataset(train_img_dir, train_anno_dir, class_list_file, batch_size=24)
运行解析器将数据集转换为tfrecords
Tf Record文件将存储在data_tfrecord文件夹中
gtf.create_tfrecord(data_output_dir="data_tfrecord")
选择并加载模型
下载模型后,Monk会根据所选参数自动更新配置文件
在本教程中,我们使用了SSD MobileNet V2,它可以接收形状为320x320x3 RGB图像的输入图像
- SSD MobileNet V2:https://resources.wolframcloud.com/NeuralNetRepository/resources/SSD-MobileNet-V2-Trained-on-MS-COCO-Data
gtf.set_model_params(model_name="ssd_mobilenet_v2_320")
设置其他训练和优化器参数
set_hyper_params(num_train_steps=10000,
lr=0.004,
lr_decay_rate=0.945,
output_dir="output_dir/",
sample_1_of_n_eval_examples=1,
sample_1_of_n_eval_on_train_examples=5,
checkpoint_dir=False,
run_once=False,
max_eval_retries=0,
num_workers=4,
checkpoint_after_every=500)
设置目录,将存储导出的参数
gtf.export_params(output_directory="export_dir");
设置tensorRT优化参数
TensorRT优化器创建一个计划,然后构建它。构建计划是为了优化它正在构建的GPU的模型。
如前所述,在具有不同cuda计算能力的GPU上优化的模型无法在jetson nano上运行,因此Monk库确保该计划在开发机(云或colab)上编译,而该计划则在运行时在部署机(jetson nano)上构建
使用INT8优化时,无法执行此功能,计划的编制和构建都必须在同一台机器上,并且Jetson纳米板与8位整数运算不太兼容
gtf.TensorRT_Optimization_Params(conversion_type="FP16", trt_dir="trt_fp16_dir")
训练探测器
检测器训练运行一个执行sys.exit()函数的会话,因此在其上运行的包装程序将关闭python系统。
为了解决此问题,提供了一个名为train.py的脚本,该脚本可以在jupyter notebook或终端命令上运行
根据参数设置,训练好的模型将保存在名为“ output_dir”的文件夹中。
# For terminal users
$ python Monk_Object_Detection/13_tf_obj_2/lib/train.py
# For jupyter notebook or colab users
%run Monk_Object_Detection/13_tf_obj_2/lib/train.py
过程D:导出经过训练的模型以进行推理
导出训练有素的检查点模型
export函数运行一个执行sys.exit()函数的会话,因此在其上运行的包装器将关闭python系统。
为了解决此问题,提供了一个名为export.py的脚本,该脚本可以在jupyter notebook或终端命令上运行
根据参数设置,导出的模型将保存在名为“ export_dir”的文件夹中。
# For terminal users
$ python Monk_Object_Detection/13_tf_obj_2/lib/export.py
# For jupyter notebook and colab users
%run Monk_Object_Detection/13_tf_obj_2/lib/export.py
过程E:TensorRT推论的模型优化
安装TensorRT版本6.0.1
转到Nvidia TensorRT页面并下载基于OS和CUDA的TRT6软件包。
下面提到的是适用于Ubuntu OS和Cuda 10.1的步骤
# Optimizing For TensorRT - Feature Not tested on colab
# This requires TensorRT 6.0.1 to be installed
# Go to https://developer.nvidia.com/tensorrt
# Download
# - nv-tensorrt-repo-ubuntu1804-cuda10.1-trt6.0.1.5-ga-20190913_1-1_amd64.deb (For Ubuntu18.04)
# - nv-tensorrt-repo-ubuntu1604-cuda10.1-trt6.0.1.5-ga-20190913_1-1_amd64.deb (For Ubuntu16.04)
# Run the following commands to install trt (in a terminal)
$ sudo dpkg -i nv-tensorrt-repo-ubuntu1804-cuda10.1-trt6.0.1.5-ga-20190913_1-1_amd64.deb
$ sudo apt-key add /var/nv-tensorrt-repo-cuda10.1-trt6.0.1.5-ga-20190913/7fa2af80.pub
$ sudo apt-get update
$ sudo apt-get install tensorrt
$ sudo apt-get install uff-converter-tf
$ sudo apt-get install python3-libnvinfer-dev
优化导出模型
优化函数运行一个执行sys.exit()函数的会话,因此在其上运行的包装程序将关闭python系统。
为了解决此问题,提供了一个名为optimize.py的脚本,该脚本可以在jupyter notebook电脑或终端命令上运行
根据参数设置,优化的模型将保存在名为“ trt_fp16_dir”的文件夹中。
# For terminal users
$ python Monk_Object_Detection/13_tf_obj_2/lib/optimize.py
# For jupyter notebook and colab users
%run Monk_Object_Detection/13_tf_obj_2/lib/optimize.py
过程F-1:在开发机器上运行推理
加载推理机
from infer_detector import Infer
gtf = Infer();
载入模型
首先加载导出的模型并运行步骤;稍后通过加载优化的模型重复相同的步骤(步骤保持不变)
# To load exported model
gtf.set_model_params(exported_model_dir = 'export_dir')
# To load optimized model
gtf.set_model_params(exported_model_dir = 'trt_fp16_dir')
对单个图像进行推断
scores, bboxes, labels = gtf.infer_on_image('ship/test/img1.jpg', thresh=0.1);

样本推断结果
使用两个模型运行速度测试分析
gtf.benchmark_for_speed('ship/test/img1.jpg')
在AWS P3.2x V100 GPU上使用导出的模型(未优化)进行分析
Average Image loading time : 0.0110 sec
Average Inference time : 0.0097 sec
Result extraction time : 0.0352 sec
total_repetitions : 100
total_time : 0.9794 sec
images_per_sec : 102
latency_mean : 9.7949 ms
latency_median : 9.7095 ms
latency_min : 9.1238 ms
在AWS P3.2x V100 GPU上使用优化模型进行分析
约1.5倍的速度加快处理后期优化
Average Image loading time : 0.0108 sec
Average Inference time : 0.0062 sec
Result extraction time : 0.0350 sec
total_repetitions : 100
total_time : 0.6241 sec
images_per_sec : 160
latency_mean : 6.2422 ms
latency_median : 6.2302 ms
latency_min : 5.9401 ms
过程F-2:在Jetson Nano板上设置所有东西
步骤1:下载Jetpack 4.3 SD卡映像 https://developer.nvidia.com/jetpack-43-archive
步骤2:将此图片写入SD卡。你可以使用 https://www.balena.io/etcher/
步骤3:将你的SD卡插入Nano板并启动系统,然后完成安装步骤
获取有关Nvidia的“ Jetson Nano入门”页面的更多详细信息
过程F-3:在Jetson Nano板上安装步骤
步骤1:更新Apt
$ sudo apt-get update
$ sudo apt-get upgrade
步骤2:安装系统库
$ sudo apt-get install nano git cmake libatlas-base-dev gfortran libhdf5-serial-dev hdf5-tools nano locate libfreetype6-dev python3-setuptools protobuf-compiler libprotobuf-dev openssl libssl-dev libcurl4-openssl-dev cython3 libxml2-dev libxslt1-dev python3-pip
$ sudo apt-get install libopenblas-dev libprotobuf-dev libleveldb-dev libsnappy-dev libhdf5-serial-dev protobuf-compiler libgflags-dev libgoogle-glog-dev liblmdb-dev
$ sudo pip3 install virtualenv virtualenvwrapper
步骤3:更新bashrc文件
将这些行添加到〜/ .bashrc文件
export VIRTUALENVWRAPPER_PYTHON=/usr/bin/python3
export WORKON_HOME=$HOME/.virtualenvs
export VIRTUALENVWRAPPER_VIRTUALENV=/usr/local/bin/virtualenv
source /usr/local/bin/virtualenvwrapper.sh
export PATH=/usr/local/cuda-10.0/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda-10.0/lib64\
${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
运行以下命令
$ source ~/.bashrc
步骤4:创建虚拟环境并安装所有必需的python库
安装numpy大约需要15分钟
$ mkvirtualenv -p /usr/bin/python3.6 tf2
$ pip install numpy==1.19.1
安装scipy大约需要40分钟
$ pip install scipy==1.5.1
安装Jetson Nano TensorFlow-2.0.0需再花费15分钟
$ pip install scikit-build protobuf cython -vvvv
$ pip install grpcio absl-py py-cpuinfo psutil portpicker six mock requests gast h5py astor termcolor protobuf keras-applications keras-preprocessing wrapt google-pasta -vvvv
$ pip install https://developer.download.nvidia.com/compute/redist/jp/v43/tensorflow-gpu/tensorflow_gpu-2.0.0+nv19.12-cp36-cp36m-linux_aarch64.whl -vvvv
安装OpenCV需要1.5个小时
$ mkdir opencv && cd opencv
$ wget -O opencv.zip https://github.com/opencv/opencv/archive/4.1.2.zip
$ unzip opencv.zip
$ mv opencv-4.1.2 opencv
$ cd opencv && mkdir build && cd build
$ cmake -D CMAKE_BUILD_TYPE=RELEASE -D WITH_CUDA=OFF -D WITH_CUBLAS=OFF -D WITH_LIBV4L=ON -D BUILD_opencv_python3=ON -D BUILD_opencv_python2=OFF -D BUILD_opencv_java=OFF -D WITH_GSTREAMER=ON -D WITH_GTK=ON -D BUILD_TESTS=OFF -D BUILD_PERF_TESTS=OFF -D BUILD_EXAMPLES=OFF -D OPENCV_ENABLE_NONFREE=OFF ..
$ make -j3
$ sudo make install
$ cd ~/.virtualenvs/tf2/lib/python3.6/site-packages
$ ln -s /usr/local/lib/python3.6/site-packages/cv2/python-3.6/cv2.cpython-36m-aarch64-linux-gnu.so cv2.so
最后克隆Monk Object Detection库
注意:不要像在开发机器中那样运行13_tf_obj_2的安装。用tf2.0安装tf对象检测有一些问题。推理代码不需要对象检测API工具。
$ git clone https://github.com/Tessellate-Imaging/Monk_Object_Detection.git
过程F-4:关于Jetson Nano的推论
将优化的权重文件夹复制/下载到jetson nano工作目录(Monk库为克隆目录)
从Monk_Object_Detection库复制示例图像
$ cp -r Monk_Object_Detection/example_notebooks/sample_dataset/ship .
加载推理引擎和模型(此步骤大约需要4到5分钟)
from infer_detector_nano import Infer
gtf = Infer();
gtf.set_model_params(exported_model_dir = 'trt_fp16_dir')
现在,如前所述,TensorRT采用计划并在运行时构建(优化)它,因此第一次运行大约需要3-4分钟
scores, bboxes, labels = gtf.infer_on_image('ship/test/img1.jpg', thresh=0.1);
# Oputput will be saved as output.jpg
gtf.draw_on_image(self, bbox_thickness=3, text_size=1, text_thickness=2)

突出显示的区域显示了Jetson Nano的TesnorRT建立(优化)计划(模型)(作者拥有的图像)
再次运行它不会花费太多时间。
Benchmark板基准分析
gtf.benchmark_for_speed('ship/test/img1.jpg')
# With Jetson Nano power mode - 5W ModeAverage Image loading time : 0.0486 sec
Average Inference time : 0.1182 sec
total_repetitions : 100
total_time : 11.8244 sec
images_per_sec : 8
latency_mean : 118.2443 ms
latency_median : 117.8019 ms
latency_min : 111.0002 ms
# With Jetson Nano power mode - MAXN ModeAverage Image loading time : 0.0319 sec
Average Inference time : 0.0785 sec
total_repetitions : 100
total_time : 7.853 sec
images_per_sec : 12
latency_mean : 78.5399 ms
latency_median : 78.1973 ms
latency_min : 76.2658 ms
jupyter notebook提供TensorFlow对象检测API 2.0的完整代码
从谷歌驱动器下载所有预先训练的权重
TensorFlow对象检测API V 2.0的所有工作到此结束

感谢阅读!祝你编码愉快!!
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号