
用Python从头开始构建神经网络
作者|Rashida Nasrin Sucky
编译|VK
来源|Medium

神经网络已经被开发用来模拟人脑。虽然我们还没有做到这一点,但神经网络在机器学习方面是非常有效的。它在上世纪80年代和90年代很流行,最近越来越流行。计算机的速度足以在合理的时间内运行一个大型神经网络。在本文中,我将讨论如何实现一个神经网络。
我建议你仔细阅读“神经网络的思想”部分。但如果你不太清楚,不要担心。可以转到实现部分。我把它分解成更小的碎片帮助理解。
神经网络的工作原理
在一个简单的神经网络中,神经元是基本的计算单元。它们获取输入特征并将其作为输出。以下是基本神经网络的外观:

这里,“layer1”是输入特征。“Layer1”进入另一个节点layer2,最后输出预测的类或假设。layer2是隐藏层。可以使用多个隐藏层。
你必须根据你的数据集和精度要求来设计你的神经网络。
前向传播
从第1层移动到第3层的过程称为前向传播。前向传播的步骤:
-
为每个输入特征初始化系数θ。比方说,我们有100个训练例子。这意味着100行数据。在这种情况下,如果假设有10个输入特征,我们的输入矩阵的大小是100x10。现在确定\(θ_1\)的大小。行数需要与输入特征的数量相同。在这个例子中,是10。列数应该是你选择的隐藏层的大小。
-
将输入特征X乘以相应的θ,然后添加一个偏置项。通过激活函数传递结果。
有几个激活函数可用,如sigmoid,tanh,relu,softmax,swish
我将使用一个sigmoid激活函数来演示神经网络。
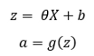
这里,“a”代表隐藏层或第2层,b表示偏置。
g(z)是sigmoid激活函数:

-
为隐藏层初始化\(\theta_2\)。大小将是隐藏层的长度乘以输出类的数量。在这个例子中,下一层是输出层,因为我们没有更多的隐藏层。
-
然后我们需要按照以前一样的流程。将θ和隐藏层相乘,通过sigmoid激活层得到预测输出。
反向传播
反向传播是从输出层移动到第二层的过程。在这个过程中,我们计算了误差。
- 首先,从原始输出y减去预测输出,这就是我们的\(\delta_3\)。
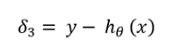
- 现在,计算\(\theta_2\)的梯度。将\(\delta_3\)乘以\(\theta_2\)。乘以“\(a^2\)”乘以“\(1-a^2\)”。在下面的公式中,“a”上的上标2表示第2层。请不要把它误解为平方。
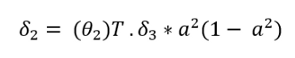
- 用训练样本数m计算没有正则化版本的梯度\(\delta\)。
训练网络
修正\(\delta\)。将输入特征乘以\(\delta_2\)乘以学习速率得到\(\theta_1\)。请注意\(\theta_1\)的维度。

重复前向传播和反向传播的过程,并不断更新参数,直到达到最佳成本。这是成本函数的公式。只是提醒一下,成本函数表明,预测离原始输出变量有多远。

如果你注意到的话,这个成本函数公式几乎和逻辑回归成本函数一样。
神经网络的实现
我将使用Andrew Ng在Coursera的机器学习课程的数据集。请从以下链接下载数据集:
https://github.com/rashida048/Machine-Learning-With-Python/blob/master/ex3d1.xlsx
下面是一个逐步实现的神经网络。我鼓励你自己运行每一行代码并打印输出以更好地理解它。
- 首先导入必要的包和数据集。
import pandas as pd
import numpy as np
xls = pd.ExcelFile('ex3d1.xlsx')
df = pd.read_excel(xls, 'X', header = None)
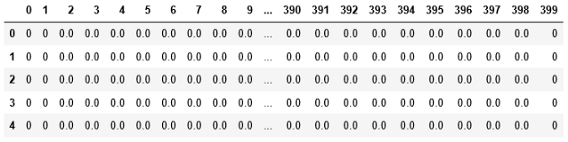
这是数据集的前五行。这些是数字的像素值。
在这个数据集中,输入和输出变量被组织在单独的excel表格中。让我们导入输出变量:
y = pd.read_excel(xls, 'y', header=None)

这也是数据集的前五行。输出变量是从1到10的数字。这个项目的目标是使用存储在'df'中的输入变量来预测数字。
- 求输入输出变量的维数
df.shape
y.shape
输入变量或df的形状为5000 x 400,输出变量或y的形状为5000 x 1。
- 定义神经网络
为了简单起见,我们将只使用一个由25个神经元组成的隐藏层。
hidden_layer = 25
得到输出类。
y_arr = y[0].unique()#输出:
array([10, 1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=int64)
正如你在上面看到的,有10个输出类。
- 初始化θ和偏置
我们将随机初始化层1和层2的θ。因为我们有三层,所以会有\(\theta_1\)和\(\theta_2\)。
\(\theta_1\)的维度:第1层的大小x第2层的大小
\(\theta_2\)的维度:第2层的大小x第3层的大小
从步骤2开始,“df”的形状为5000 x 400。这意味着有400个输入特征。所以,第1层的大小是400。当我们指定隐藏层大小为25时,层2的大小为25。我们有10个输出类。所以,第3层的大小是10。
\(\theta_1\)的维度:400 x 25
\(\theta_2\)的维度:25×10
同样,会有两个随机初始化的偏置b1和b2。
\(b_1\)的维度:第2层的大小(本例中为25)
\(b_1\)的维度:第3层的大小(本例中为10)
定义一个随机初始化theta的函数:
def randInitializeWeights(Lin, Lout):
epi = (6**1/2) / (Lin + Lout)**0.5
w = np.random.rand(Lout, Lin)*(2*epi) -epi
return w
使用此函数初始化theta
hidden_layer = 25
output =10
theta1 = randInitializeWeights(len(df.T), hidden_layer)
theta2 = randInitializeWeights(hidden_layer, output)
theta = [theta1, theta2]
现在,初始化我们上面讨论过的偏置项:
b1 = np.random.randn(25,)
b2 = np.random.randn(10,)
- 实现前向传播
使用前向传播部分中的公式。

为了方便起见,定义一个函数来乘以θ和X
def z_calc(X, theta):
return np.dot(X, theta.T)
我们也将多次使用激活函数。同样定义一个函数
def sigmoid(z):
return 1/(1+ np.exp(-z))
现在我将逐步演示正向传播。首先,计算z项:
z1 =z_calc(df, theta1) + b1
现在通过激活函数传递这个z1,得到隐藏层
a1 = sigmoid(z1)
a1是隐藏层。a1的形状是5000 x 25。重复相同的过程来计算第3层或输出层
z2 = z_calc(a1, theta2) + b2
a2 = sigmoid(z2)
a2的形状是5000 x 10。10列代表10个类。a2是我们的第3层或最终输出。如果在这个例子中有更多的隐藏层,在从一个层到另一个层的过程中会有更多的重复步骤。这种利用输入特征计算输出层的过程称为前向传播。
l = 3 #层数
b = [b1, b2]
def hypothesis(df, theta):
a = []
z = []
for i in range (0, l-1):
z1 = z_calc(df, theta[i]) + b[i]
out = sigmoid(z1)
a.append(out)
z.append(z1)
df = out
return out, a, z
- 实现反向传播
这是反向计算梯度和更新θ的过程。在此之前,我们需要修改'y'。我们在“y”有10个类。但我们需要将每个类在其列中分开。例如,针对第10类的列。我们将为10替换1,为其余类替换0。这样我们将为每个类创建一个单独的列。
y1 = np.zeros([len(df), len(y_arr)])
y1 = pd.DataFrame(y1)
for i in range(0, len(y_arr)):
for j in range(0, len(y1)):
if y[0][j] == y_arr[i]:
y1.iloc[j, i] = 1
else:
y1.iloc[j, i] = 0
y1.head()
之前我一步一步地演示了向前传播,然后把所有的都放在一个函数中,我将对反向传播做同样的事情。使用上述反向传播部分的梯度公式,首先计算\(\delta_3\)。我们将使用前向传播实现中的z1、z2、a1和a2。
del3 = y1-a2
现在使用以下公式计算delta2:
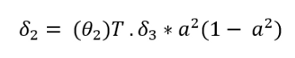
这里是delta2:
del2 = np.dot(del3, theta2) * a1*(1 - a1)
在这里我们需要学习一个新的概念。这是一个sigmoid梯度。sigmoid梯度的公式为:

如果你注意到了,这和delta公式中的a(1-a)完全相同。因为a是sigmoid(z)。我们来写一个关于sigmoid梯度的函数:
def sigmoid_grad(z):
return sigmoid(z)*(1 - sigmoid(z))
最后,使用以下公式更新θ:
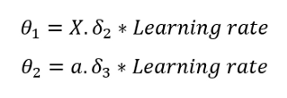
我们需要选择一个学习率。我选了0.003。我鼓励你尝试使用其他学习率,看看它的表现:
theta1 = np.dot(del2.T, pd.DataFrame(a1)) * 0.003
theta2 = np.dot(del3.T, pd.DataFrame(a2)) * 0.003
这就是θ需要更新的方式。这个过程称为反向传播,因为它向后移动。在编写反向传播函数之前,我们需要定义成本函数。因为我会把成本的计算也包括在反向传播方法中。但它是可以添加到前向传播中,或者可以在训练网络时将其分开的。
def cost_function(y, y_calc, l):
return (np.sum(np.sum(-np.log(y_calc)*y - np.log(1-y_calc)*(1-y))))/m
这里m是训练实例的数量。综合起来的代码:
m = len(df)
def backpropagation(df, theta, y1, alpha):
out, a, z = hypothesis(df, theta)
delta = []
delta.append(y1-a[-1])
i = l - 2
while i > 0:
delta.append(np.dot(delta[-i], theta[-i])*sigmoid_grad(z[-(i+1)]))
i -= 1
theta[0] = np.dot(delta[-1].T, df) * alpha
for i in range(1, len(theta)):
theta[i] = np.dot(delta[-(i+1)].T, pd.DataFrame(a[0])) * alpha
out, a, z = hypothesis(df, theta)
cost = cost_function(y1, a[-1], 1)
return theta, cost
- 训练网络
我将用20个epoch训练网络。我在这个代码片段中再次初始化theta。
theta1 = randInitializeWeights(len(df.T), hidden_layer)
theta2 = randInitializeWeights(hidden_layer, output)
theta = [theta1, theta2]
cost_list = []
for i in range(20):
theta, cost= backpropagation(df, theta, y1, 0.003)
cost_list.append(cost)
cost_list
我使用了0.003的学习率并运行了20个epoch。但是请看文章末提供的GitHub链接。我有试着用不同的学习率和不同的epoch数训练模型。
我们得到了每个epoch计算的成本,以及最终更新的θ。用最后的θ来预测输出。
- 预测输出并计算精度
只需使用假设函数并传递更新后的θ来预测输出:
out, a, z = hypothesis(df, theta)
现在计算一下准确率,
accuracy= 0
for i in range(0, len(out)):
for j in range(0, len(out[i])):
if out[i][j] >= 0.5 and y1.iloc[i, j] == 1:
accuracy += 1
accuracy/len(df)
准确率为100%。完美,对吧?但我们并不是一直都能得到100%的准确率。有时获得70%的准确率是很好的,这取决于数据集。
恭喜!你刚刚开发了一个完整的神经网络!
以下是完整工作代码的GitHub链接:
https://github.com/rashida048/Machine-Learning-With-Python/blob/master/NeuralNetworkFinal.ipynb
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号