
使用RetinaNet构建的人脸口罩探测器
作者|GUEST
编译|VK
来源|Analytics Vidhya
介绍

目标检测是计算机视觉中一个非常重要的领域,对于自动驾驶、视频监控、医疗应用和许多其他领域都是必要的。
我们正在与一场规模空前的传染病作斗争。全世界的研究人员都在试图开发一种疫苗或治疗COVID-19的方法,而医生们却在努力阻止这场传染病席卷全世界。另一方面,许多国家发现了社会距离的疏远,使用口罩和手套可以稍微遏制这种局面。
我最近有一个想法,用我的深度学习知识来帮助目前的情况。在这篇文章中,我将向你介绍RetinaNet的实现,背景知识不多。
我们将使用RetinaNet建立一个“口罩探测器”来帮助我们应对这场持续的传染病。你可以推断出同样的想法来为你的智能家居构建一个支持人工智能的解决方案。这个人工智能的解决方案只对戴着口罩和手套的人敞开大门。
随着无人机的成本随着时间的推移而降低,我们看到空中数据的生成出现了一个大的峰值。因此,你可以使用这个RetinaNet模型在航空图像甚至卫星图像中检测不同的对象,如汽车(自行车、汽车等)或行人,以解决不同的业务问题。
所以,你看目标检测模型的应用是无穷无尽的。
目录
- 什么是RetinaNet
- RetinaNet的需求
- RetinaNet的架构
- 骨干网
- 对象分类子网
- 对象回归子网
- Focal Loss
- 利用RetinaNet模型建立口罩检测器
- 收集数据
- 创建数据集
- 模特训练
- 模型测试
- 最后说明
什么是RetinaNet
RetinaNet是一种最好的单目标检测模型,已被证明能很好地处理密集和小尺度的物体。由于这个原因,它已经成为一个流行的目标检测模型。
RetinaNet的需求
RetinaNet是由Facebook人工智能研究所(Facebook-AI-Research)引入的,旨在解决密集检测问题。在处理极端前景-背景类时,需要弥补YOLO和SSD等单步目标检测器的不平衡和不一致。
RetinaNet的架构
从本质上讲,RetinaNet是一个复合网络,由以下部分组成:
-
主干网络(自底向上的路径和具有横向连接的自上而下的路径)
-
目标分类子网
-
目标回归子网
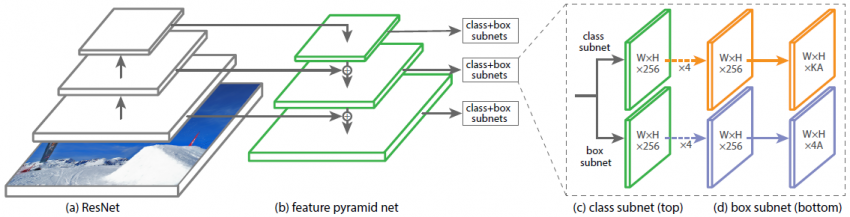
为了更好地理解,让我们分别了解架构的每个组件
1.主干网络
-
自底向上路径:自底向上路径(例如,ResNet)用于特征提取。因此,它计算不同比例的特征图,而不考虑输入图像的大小。
-
具有横向连接的自上而下的路径:在自上而下的路径上,从更高的金字塔级别对空间上较粗糙的特征图进行上采样,横向连接将具有相同空间大小的自顶向下和自底向上的层合并在一起。较高层次的特征图往往具有较小的分辨率,但语义上更强。因此,更适合于检测较大的物体;相反,来自较低级特征图的网格单元具有高分辨率,因此更擅长检测较小的对象。因此,结合自上而下的路径及其与自底向上的路径的横向连接,不需要太多额外的计算,因此生成的特征图的每个级别在语义和空间上都可以很强。 因此,该体系结构是规模不变的,并且可以在速度和准确性方面提供更好的性能。
2.目标分类子网
每个FPN层都附加一个全卷积网络(FCN)进行对象分类。如图所示,该子网包含3*3个卷积层,256个滤波器,然后是3*3个卷积层,K*A滤波器,因此输出的feature map大小为W*H*KA,其中W和H与输入特征图的宽度和高度成比例,K和A分别为对象类和锚盒的数量。
最后利用Sigmoid层(而不是softmax)进行目标分类。
而最后一个卷积层之所以有KA滤波器是因为,如果从最后一个卷积层得到的特征图中的每个位置都有很多锚盒候选区域,那么每个锚盒都有可能被分类为K个类。所以输出的特征图大小将是KA通道或过滤器。
3.目标回归子网
回归子网与分类子网并行附着在FPN的每个特征图上。回归子网的设计与分类子网相同,只是最后一个卷积层大小为3*3,有4个filter,输出的特征图大小为W*H*4A。
最后一个卷积层有4个过滤器的原因是,为了定位类对象,回归子网络为每个锚定盒产生4个数字,这些数字预测锚定盒和真实框锚盒之间的相对偏移量(根据中心坐标、宽度和高度)。因此,回归子网的输出特征图具有4A滤波器或通道。
Focal Loss
Focal Loss(FL)是Cross-Entropy Loss(CE)的改进版本,它通过为困难的或容易错误分类的示例(即具有嘈杂纹理或部分对象或我们感兴趣的对象的背景)分配更多权重来尝试处理类不平衡问题 ,并简化简单的示例(即背景对象)。
因此,“Focal Loss”减少了简单示例带来的损失贡献,并提高了纠正错误分类的示例的重要性。 焦点损失只是交叉熵损失函数的扩展,它将降低简单示例的权重,并将训练重点放在困难样本上。
所以为了实现这些研究人员提出了
1- pt代表交叉熵损失,可调聚焦参数≥0。 RetinaNet物体检测方法使用焦距损失的α平衡变体,其中α= 0.25,γ= 2效果最佳。
所以Focal Loss可以定义为
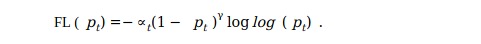
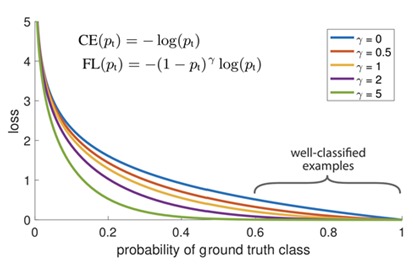
请参见图,对于γ∈[0,5]的几个值,我们将注意到Focal Loss的以下特性:
-
当示例分类错误且pt小时,调制因子接近1并且不影响损失。
-
当pt→1时,因子变为0,并且可以很好地权衡分类良好的示例的损失。
-
Focal loss γ平滑地调整了简单示例的权重。 随着γ的增加,调制因子的作用也同样增加。 (经过大量实验和试验,研究人员发现γ= 2最有效)
注:什么时候γ=0,FL相当于CE。图中所示为蓝色曲线
直观地看,调制因子减小了简单例的损耗贡献,扩展了例的低损耗范围。
现在让我们看看用Python实现RetinaNet来构建口罩检测器。
利用RetinaNet模型建立口罩检测器
收集数据
任何深度学习模型都需要大量的训练数据才能在测试数据上产生良好的结果。
创建数据集
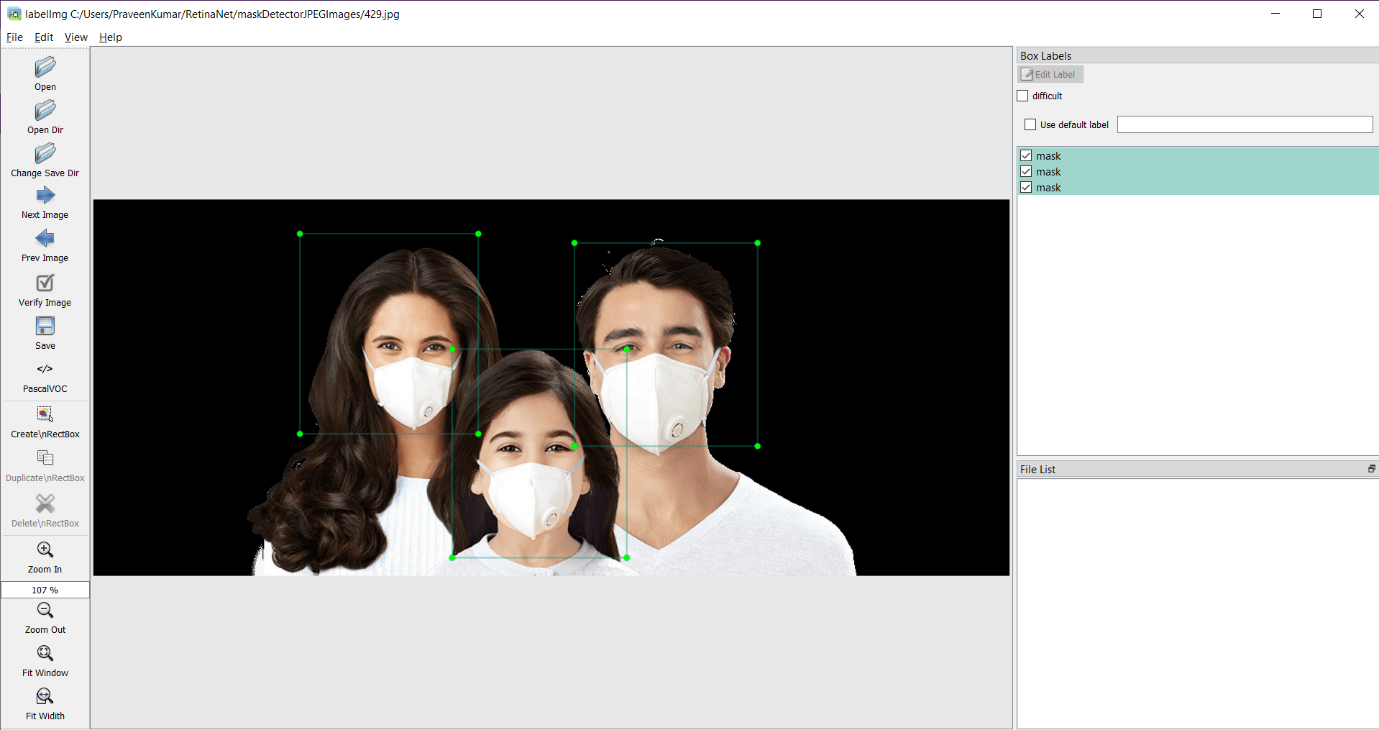
我们开始使用LabelImg工具创建数据集和验证。这个优秀的注释工具可以让你快速地注释对象的边界框,从而训练机器学习模型。
你可以在anaconda命令提示符下使用下面的命令安装它
pip install labelImg
你可以使用下面的labelmg工具对每个JPEG文件进行注释,它将生成带有每个边界框坐标的XML文件。我们将使用这些xml文件来训练我们的模型。
模型训练
第1步:克隆并安装keras-retinanet
import os
print(os.getcwd())
git clone https://github.com/fizyr/keras-retinanet.git
%cd keras-retinanet/
!pip install .
!python setup.py build_ext --inplace
第2步:导入所有必要库
import numpy as np
import shutil
import pandas as pd
import os, sys, random
import xml.etree.ElementTree as ET
import pandas as pd
from os import listdir
from os.path import isfile, join
import matplotlib.pyplot as plt
from PIL import Image
import requests
import urllib
from keras_retinanet.utils.visualization import draw_box, draw_caption , label_color
from keras_retinanet.utils.image import preprocess_image, resize_image
第3步:导入JPEG和xml数据
pngPath='C:/Users/PraveenKumar/RetinaNet//maskDetectorJPEGImages/'
annotPath='C:/Users/PraveenKumar/RetinaNet//maskDetectorXMLfiles/'
data=pd.DataFrame(columns=['fileName','xmin','ymin','xmax','ymax','class'])
os.getcwd()
##读所有文件
allfiles = [f for f in listdir(annotPath) if isfile(join(annotPath, f))]
#读取所有pdf文件的图像,然后在文本存储在临时文件夹
for file in allfiles:
#print(file)
if (file.split(".")[1]=='xml'):
fileName='C:/Users/PraveenKumar/RetinaNet/maskDetectorJPEGImages/'+file.replace(".xml",'.jpg')
tree = ET.parse(annotPath+file)
root = tree.getroot()
for obj in root.iter('object'):
cls_name = obj.find('name').text
xml_box = obj.find('bndbox')
xmin = xml_box.find('xmin').text
ymin = xml_box.find('ymin').text
xmax = xml_box.find('xmax').text
ymax = xml_box.find('ymax').text
#通过添加字典在空数据框架中追加行
data = data.append({'fileName': fileName, 'xmin': xmin, 'ymin':ymin,'xmax':xmax,'ymax':ymax,'class':cls_name}, ignore_index=True)
data.shape
第4步:编写一个函数来显示训练数据集上的边界框
# 随机选取图像
filepath = df.sample()['fileName'].values[0]
# 获取此图像的所有行
df2 = df[df['fileName'] == filepath]
im = np.array(Image.open(filepath))
# 如果有PNG的话,它会有alpha通道
im = im[:,:,:3]
for idx, row in df2.iterrows():
box = [
row['xmin'],
row['ymin'],
row['xmax'],
row['ymax'],
]
print(box)
draw_box(im, box, color=(255, 0, 0))
plt.axis('off')
plt.imshow(im)
plt.show()
show_image_with_boxes(data)

#检查少量数据记录
data.head()

#定义标签并将其写入文件
classes = ['mask','noMask']
with open('../maskDetectorClasses.csv', 'w') as f:
for i, class_name in enumerate(classes):
f.write(f'{class_name},{i}\n')
if not os.path.exists('snapshots'):
os.mkdir('snapshots')
注意:最好从一个预训练过的模型开始,而不是从头开始训练模型。我们将使用已经在Coco数据集上预训练过的ResNet50模型。
URL_MODEL = 'https://github.com/fizyr/keras-retinanet/releases/download/0.5.1/resnet50_coco_best_v2.1.0.h5'
urllib.request.urlretrieve(URL_MODEL, PRETRAINED_MODEL)
第5步:训练RetinaNet模型
注意:如果你使用google colab,你可以使用下面的代码片段来训练你的模型。
#把你的训练数据路径和文件放在训练数据的标签上
!keras_retinanet/bin/train.py --freeze-backbone \ --random-transform \ --weights {PRETRAINED_MODEL} \ --batch-size 8 \ --steps 500 \ --epochs 15 \ csv maskDetectorData.csv maskDetectorClasses.csv
但若你正在使用本地Jupyter Notebook或其他IDE进行训练,则可以在命令提示符下执行命令
python keras_retinanet/bin/train.py --freeze-backbone
--random-transform \
--weights {PRETRAINED_MODEL}
--batch-size 8
--steps 500
--epochs 15
csv maskDetectorData.csv maskDetectorClasses.csv
让我们分析一下train.py的每个参数.
-
freeze-backbone:冻结主干层,当我们使用小数据集时特别有用,以避免过拟合
-
random-transform:随机变换数据集以获得数据增强
-
weights:使用一个预先训练好的模型(您自己的模型或者Fizyr发布的模型)初始化模型
-
batch-size:训练批量大小,值越高,学习曲线越平滑
-
step:迭代的步数
-
epochs:迭代的次数
-
csv:上面的脚本生成的注释文件
第6步:载入训练模型
from glob import glob
model_paths = glob('snapshots/resnet50_csv_0*.h5')
latest_path = sorted(model_paths)[-1]
print("path:", latest_path)
from keras_retinanet import models
model = models.load_model(latest_path, backbone_name='resnet50')
model = models.convert_model(model)
label_map = {}
for line in open('../maskDetectorClasses.csv'):
row = line.rstrip().split(',')
label_map[int(row[1])] = row[0]
模型测试:
第7步:利用训练模型进行预测
#写一个函数,从你的数据集中随机选择一个图像,并预测使用训练模型。
def show_image_with_predictions(df, threshold=0.6):
# 随机选择一个图像
row = df.sample()
filepath = row['fileName'].values[0]
print("filepath:", filepath)
# 获取此图像的所有行
df2 = df[df['fileName'] == filepath]
im = np.array(Image.open(filepath))
print("im.shape:", im.shape)
# 如果有一个PNG,它会有alpha通道
im = im[:,:,:3]
# 画出真实盒子
for idx, row in df2.iterrows():
box = [
row['xmin'],
row['ymin'],
row['xmax'],
row['ymax'],
]
print(box)
draw_box(im, box, color=(255, 0, 0))
### 画出预测 ###
# 获取预测
imp = preprocess_image(im)
imp, scale = resize_image(im)
boxes, scores, labels = model.predict_on_batch(
np.expand_dims(imp, axis=0)
)
# 标准化框坐标
boxes /= scale
# 循环得到每个预测
for box, score, label in zip(boxes[0], scores[0], labels[0]):
# 分数是排序的,所以一旦我们看到分数低于阈值,我们就可以退出
if score < threshold:
break
box = box.astype(np.int32)
color = label_color(label)
draw_box(im, box, color=color)
class_name = label_map
caption = f"{class_name} {score:.3f}"
draw_caption(im, box, caption)
score, label=score, label
plt.axis('off')
plt.imshow(im)
plt.show()
return score, label
plt.rcParams['figure.figsize'] = [20, 10]
#可以根据你的业务需求随意更改阈值
label=show_image_with_predictions(data, threshold=0.6)

#可以根据你的业务需求随意更改阈值
label=show_image_with_predictions(data, threshold=0.6)

#可以根据你的业务需求随意更改阈值
label=show_image_with_predictions(data, threshold=0.6)

#可以根据你的业务需求随意更改阈值
label=show_image_with_predictions(data, threshold=0.6)

#可以根据你的业务需求随意更改阈值
label=show_image_with_predictions(data, threshold=0.6)

#可以根据你的业务需求随意更改阈值
score, label=show_image_with_predictions(data, threshold=0.6)

#可以根据你的业务需求随意更改阈值
score, label=show_image_with_predictions(data, threshold=0.6)

#可以根据你的业务需求随意更改阈值
score, label=show_image_with_predictions(data, threshold=0.6)

参考文献
- http://arxiv.org/abs/1605.06409.
- https://arxiv.org/pdf/1708.02002.pdf
- https://developers.arcgis.com/python/guide/how-retinanet-works/
- https://github.com/fizyr/keras-retinanet
- https://www.freecodecamp.org/news/object-detection-in-colab-with-fizyr-retinanet-efed36ac4af3/
- https://deeplearningcourses.com/
- https://blog.zenggyu.com/en/post/2018-12-05/retinanet-explained-and-demystified/
最后说明
总而言之,我们完成了使用RetinaNet制作口罩检测器的整个过程。 我们创建了一个数据集,训练了一个模型并进行了测试(这是我的Notebook和数据集的Github存储库):https://github.com/Praveen76/Face-mask-detector-using-RetinaNet-model
RetinaNet是一个功能强大的模型,使用Feature Pyramid Networks&ResNet作为其骨干。 我能够通过非常有限的数据集和极少的迭代(每个迭代有500个步长,共6次迭代)获得口罩检测器的良好结果。当然你也可以更改阈值。
注意:
-
确保你训练你的模型至少20次迭代,以获得好的结果。
-
一个好的想法是提交使用RetinaNet模型构建口罩检测器的方法。 人们总是可以根据业务需求调整模型,数据和方法。
一般来说,RetinaNet是开始目标检测项目的一个很好的选择,特别是如果你需要快速获得良好的结果。
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号