
情感分析教程
作者|Zijing Zhu
编译|VK
来源|Towards Datas Science

据估计,世界上80%的数据是非结构化的。因此,从非结构化数据中提取信息是数据分析的重要组成部分。
文本挖掘是从非结构化文本数据中获取有价值的信息的过程,情感分析是文本挖掘的应用之一。它使用自然语言处理和机器学习技术从文本数据中理解和分类情绪。在商业环境中,情绪分析广泛应用于了解客户评论、从电子邮件中检测垃圾邮件等。
本文是本教程的第一部分,介绍了使用Python进行情绪分析的具体技术。为了更好地说明程序,我将以我的一个项目为例,对WTI原油期货价格进行新闻情绪分析。我将介绍重要的步骤以及相应的Python代码。
一些背景资料
原油期货价格短期内有较大波动。任何产品的长期均衡都是由供求状况决定的,而价格的短期波动则反映了市场对该产品的信心和预期。在本项目中,我利用与原油相关的新闻文章来捕捉不断更新的市场信心和预期,并通过对新闻文章进行情绪分析来预测未来原油价格的变化。以下是完成此分析的步骤:
1、收集资料:网络抓取新闻文章
2、文本数据预处理(本文)
3、文本矢量化:TFIDF
4、用logistic回归进行情绪分析
5、使用python flask web app在Heroku部署模型
我将讨论第二部分,即本文中文本数据的预处理。如果你对其他部分感兴趣,请继续阅读。
文本数据预处理
我使用NLTK、Spacy和一些正则表达式中的工具来预处理新闻文章。要导入库并使用Spacy中的预构建模型,可以使用以下代码:
import spacy
import nltk
# 初始化spacy'en'模型
nlp = spacy.load(‘en’, disable=[‘parser’, ‘ner’])
之后,我用Pandas读入数据:
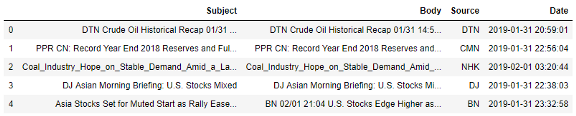
“Subject”和“Body”是我将应用文本预处理过程的列。我按照标准的文本挖掘过程对新闻文章进行预处理,以从新闻内容中提取有用的特征,包括标识化、删除停用词和词形还原。
标识化
文本数据预处理的第一步是将每个句子分解成单独的单词,这称为标识化。使用单个单词而不是句子会破坏单词之间的联系。然而,这却是一种常用的方法。计算机通过检查文章中出现的单词和这些单词出现的次数来分析文本数据是比较高效和方便的,并且足以得出有价值的结果。
以我的数据集中的第一篇新闻文章为例:
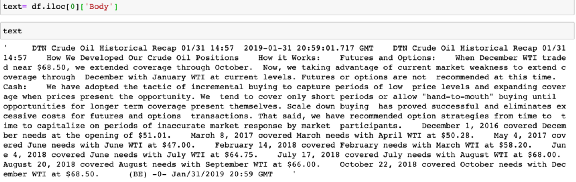
可以使用NLTK tokenizer:
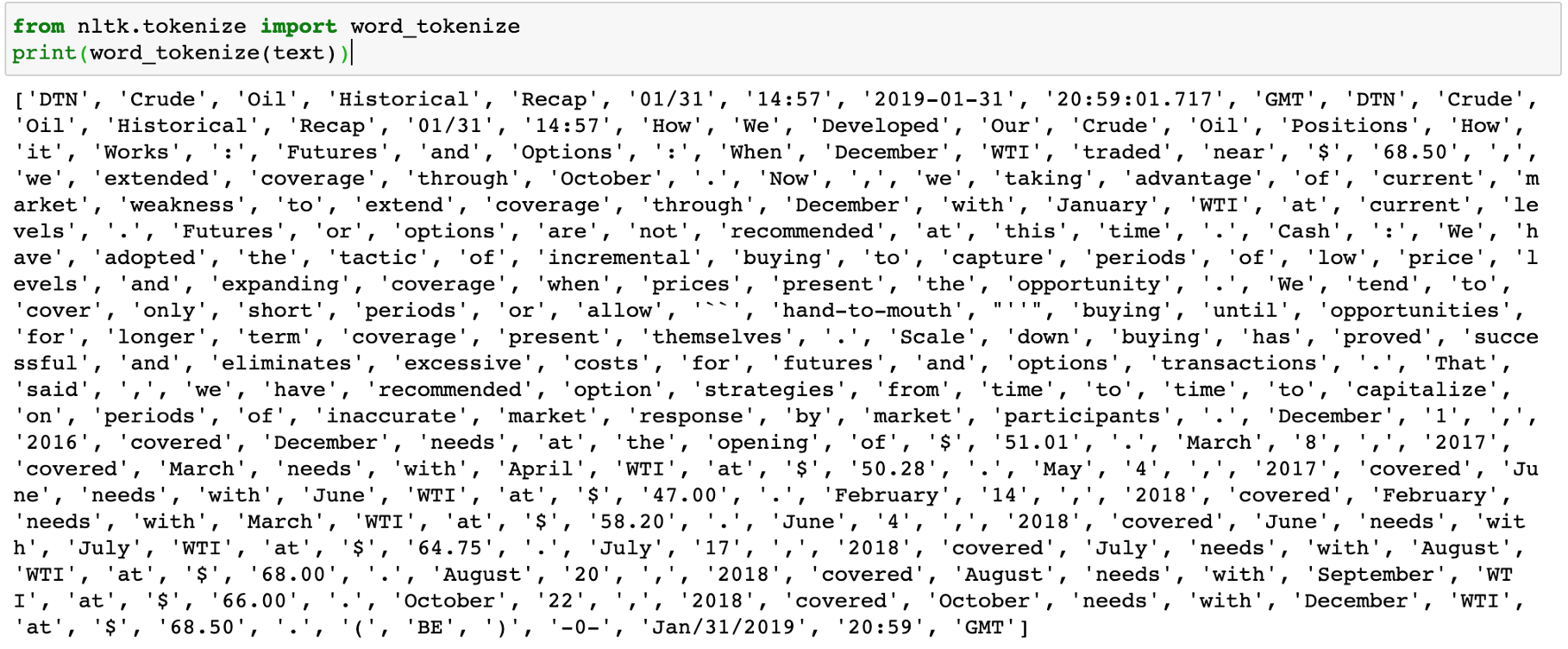
或者可以使用Spacy,记住nlp是上面定义的Spacy引擎:

标识化之后,每一篇新闻文章都将转换成一个单词、符号、数字和标点符号的列表。你可以指定是否也要将每个单词都转换为小写。下一步是删除无用信息。例如,符号、数字、标点符号。我将使用spacy和regex组合来删除它们。
import re
#标识化和删除标点
words = [str(token) for token in nlp(text) if not token.is_punct]
#删除数字和其他符号,但“@”除外--用于删除电子邮件
words = [re.sub(r"[^A-Za-z@]", "", word) for word in words]
#删除网站和电子邮件地址
words = [re.sub(r”\S+com”, “”, word) for word in words]
words = [re.sub(r”\S+@\S+”, “”, word) for word in words]
#删除空白
words = [word for word in words if word!=’ ‘]
应用上述转换后,原始新闻文章如下所示:

停用词
经过一番改造,新闻文章干净多了,但我们还是看到了一些我们不希望看到的词,比如“and”、“we”等,下一步就是去掉无用的词,即停用词。
停用词是在许多文章中经常出现但没有意义的词。stopword的例子有“I”、“the”、“a”、“of”。这些字眼如果删除,将不会影响对文章的理解。要删除stopwords,我们可以从NLTK库导入stopwords。
此外,我还列出了其他在经济分析中广泛使用的停用词列表,包括日期和时间,更一般的没有经济意义的单词,等等。以下是我如何构建停用词列表的方法:
#导入其他停用词列表
with open(‘StopWords_GenericLong.txt’, ‘r’) as f:
x_gl = f.readlines()
with open(‘StopWords_Names.txt’, ‘r’) as f:
x_n = f.readlines()
with open(‘StopWords_DatesandNumbers.txt’, ‘r’) as f:
x_d = f.readlines()
#导入nltk停用词
stopwords = nltk.corpus.stopwords.words(‘english’)
#合并所有停用词
[stopwords.append(x.rstrip()) for x in x_gl][stopwords.append(x.rstrip()) for x in x_n][stopwords.append(x.rstrip()) for x in x_d]
#将所有停用词改为小写
stopwords_lower = [s.lower() for s in stopwords]
然后从新闻文章中排除停用词:
words = [word.lower() for word in words if word.lower() not in stopwords_lower]
应用于上一个示例,其外观如下:

词形还原
除去停止字,以及符号、数字和标点符号后,我们要把每一篇新闻文章的单词进行词形还原。我们必须去掉语法时态并将每个单词转换成其原始形式。
例如,如果我们想计算一篇新闻文章中出现“open”一词的次数,我们需要计算“open”、“opens”、“opened”的出现次数。因此,词形还原是文本转换的一个重要步骤。另一种将单词转换成原始形式的方法叫做词干提取。它们之间的区别是:

词形还原是把一个词引入它原来的词形中,词干提取是把一个词的词根提取出来(可能直接去掉前缀后缀)。我选择词形还原而不是词干提取,因为词干提取后,有些词变得很难理解。从解释的角度来说,词形还原比词干提取好。
上面的引理很容易实现。在词形还原之后,每一篇新闻文章都将转换成一个词的列表,这些词都是原来的形式。新闻文章现在改成这样:

总结
让我们总结一下函数中的步骤,并在所有文章中应用该函数:
def text_preprocessing(str_input):
#标识化,删除标点,词形还原
words=[token.lemma_ for token in nlp(str_input) if not token.is_punct]
#删除符号、网站、电子邮件地址
words = [re.sub(r”[^A-Za-z@]”, “”, word) for word in words]
words = [re.sub(r”\S+com”, “”, word) for word in words]
words = [re.sub(r”\S+@\S+”, “”, word) for word in words]
words = [word for word in words if word!=’ ‘]
words = [word for word in words if len(word)!=0]
#删除停用字
words=[word.lower() for word in words if word.lower() not in stopwords_lower]
#将列表合并为一个字符串
string = " ".join(words)
return string
在这里,文本预处理与前面的所有预处理步骤相结合:

在将其推广到所有新闻文章之前,重要的是将其应用于随机新闻文章,并查看其工作原理,遵循以下代码:
import random
index = random.randint(0, df.shape[0])
text_preprocessing(df.iloc[index][‘Body’])
如果你想为此特定项目排除一些额外的单词,或者你想删除一些多余的信息,你可以在应用于所有新闻文章之前修改函数。这是一篇随机选取的新闻文章,在标识化前后,去掉了停用词和词形还原。
预处理前的新闻文章:

预处理后的新闻文章

如果可以,你可以将所有文章都应用于以下函数:
df[‘news_cleaned’]=df[‘Body’].apply(text_preprocessing)
df[‘subject_cleaned’]=df[‘Subject’].apply(text_preprocessing)
结论
文本预处理是文本挖掘和情感分析的重要组成部分。有很多方法可以对非结构化数据进行预处理,使其可读,便于计算机将来分析。下一步,我将讨论用于将文本数据转换为稀疏矩阵,以便它们可以用作定量分析的输入。
如果你的分析很简单,并且不需要在预处理文本数据时进行大量定制,那么vectorizers通常具有内嵌函数来执行基本步骤,比如标识化、删除stopwords。或者你可以编写自己的函数,并在向量化器中指定自定义函数,这样就可以同时对数据进行预处理和向量化。
如果你希望这样做,那么你的函数需要返回一个经过标记化的单词列表,而不是一个长字符串。但是,就个人而言,我更喜欢在向量化之前先对文本数据进行预处理。通过这种方式,我一直在监视函数的性能,而且它实际上会更快,特别是当你有一个大的数据集时。
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号