

利用深度学习生成医疗报告
作者|Vysakh Nair
编译|VK
来源|Towards Data Science
目录
-
了解问题
-
要求技能
-
数据
-
获取结构化数据
-
准备文本数据-自然语言处理
-
获取图像特征-迁移学习
-
输入管道-数据生成器
-
编-解码器模型-训练,贪婪搜索,束搜索,BLEU
-
注意机制-训练,贪婪搜索,束搜索,BLEU
-
摘要
-
未来工作
-
引用
1.了解问题
图像字幕是一个具有挑战性的人工智能问题,它是指根据图像内容从图像中生成文本描述的过程。例如,请看下图:

一个常见的答案是“一个弹吉他的女人”。作为人类,我们可以用适当的语言,看着一幅图画,描述其中的一切。这很简单。我再给你看一个:
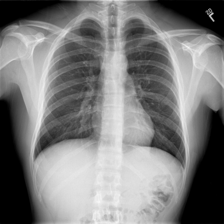
好吧,你怎么形容这个?
对于我们所有的“非放射科医生”,一个常见的答案是“胸部x光”。
对于放射科医生,他们撰写文本报告,叙述在影像学检查中身体各个部位的检查结果,特别是每个部位是正常、异常还是潜在异常。他们可以从一张这样的图像中获得有价值的信息并做出医疗报告。
对于经验不足的放射科医生和病理学家,尤其是那些在医疗质量相对较低的农村地区工作的人来说,撰写医学影像报告是很困难的,而另一方面,对于有经验的放射科医生和病理学家来说,写成像报告可能是乏味和耗时的。
所以,为了解决所有这些问题,如果一台计算机可以像上面这样的胸部x光片作为输入,并像放射科医生那样以文本形式输出结果,那岂不是很棒?

2.基本技能
本文假设你对神经网络、cnn、RNNs、迁移学习、Python编程和Keras库等主题有一定的了解。下面提到的两个模型将用于我们的问题,稍后将在本博客中简要解释:
-
编解码器模型
-
注意机制
对它们有足够的了解会帮助你更好地理解模型。
3.数据
你可以从以下链接获取此问题所需的数据:
- 图像-包含所有的胸部X光片:http://academictorrents.com/details/5a3a439df24931f410fac269b87b050203d9467d
- 报告-包含上述图像的相应报告:http://academictorrents.com/details/66450ba52ba3f83fbf82ef9c91f2bde0e845aba9
图像数据集包含一个人的多个胸部x光片。例如:x光片的侧视图、多个正面视图等。
正如放射科医生使用所有这些图像来编写报告,模型也将使用所有这些图像一起生成相应的结果。数据集中有3955个报告,每个报告都有一个或多个与之关联的图像。
3.1 从XML文件中提取所需的数据
数据集中的报表是XML文件,其中每个文件对应一个单独的。这些文件中包含了与此人相关的图像id和相应的结果。示例如下:

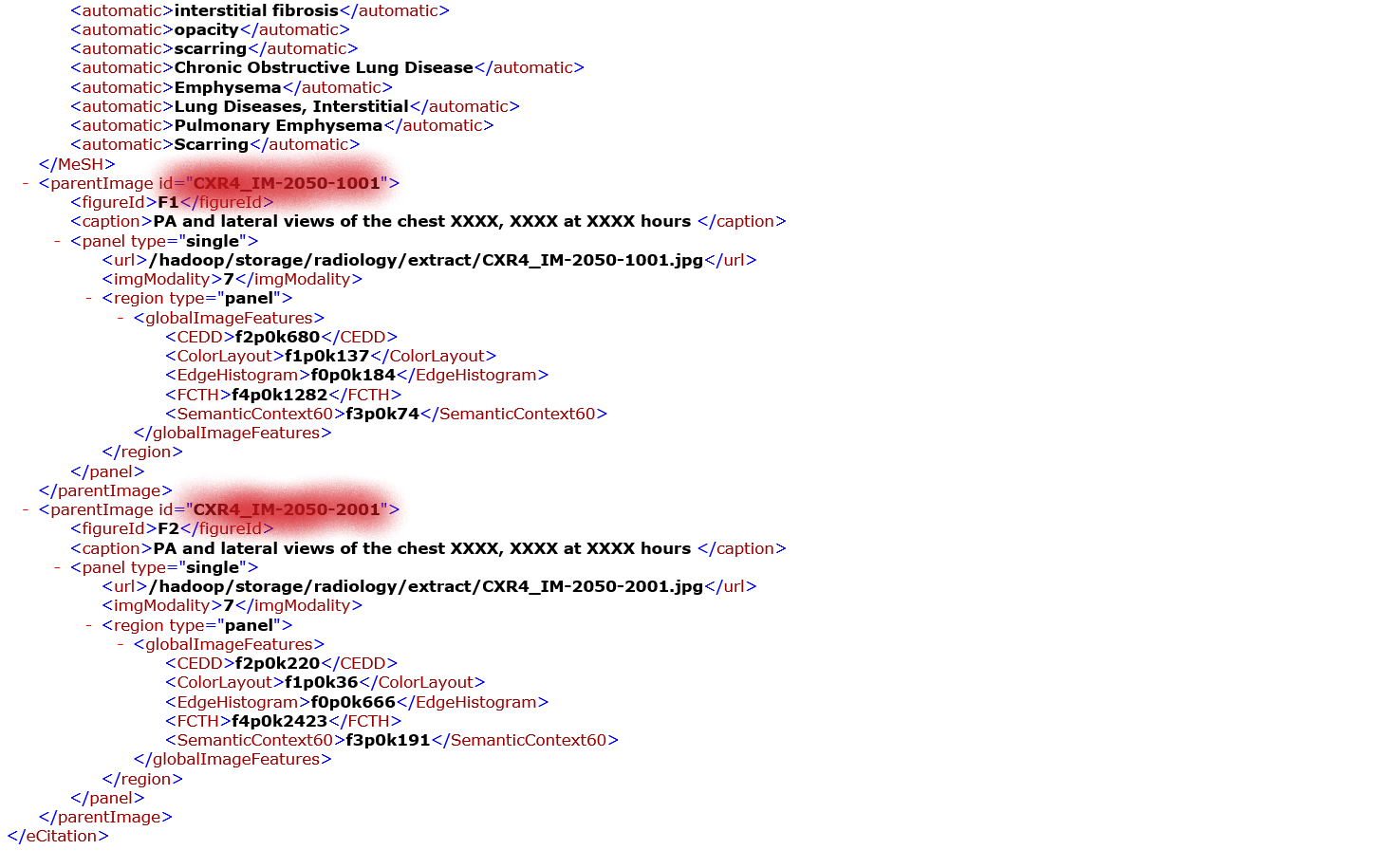
突出显示的信息是你需要从这些文件中提取的内容。这可以在python的XML库的帮助下完成。
注:调查结果也将称为报告。它们将在博客的其他部分互换使用。
import xml.etree.ElementTree as ET
img = []
img_impression = []
img_finding = []
# directory包含报告文件
for filename in tqdm(os.listdir(directory)):
if filename.endswith(".xml"):
f = directory + '/' + filename
tree = ET.parse(f)
root = tree.getroot()
for child in root:
if child.tag == 'MedlineCitation':
for attr in child:
if attr.tag == 'Article':
for i in attr:
if i.tag == 'Abstract':
for name in i:
if name.get('Label') == 'FINDINGS':
finding=name.text
for p_image in root.findall('parentImage'):
img.append(p_image.get('id'))
img_finding.append(finding)
4.获取结构化数据
从XML文件中提取所需的数据后,数据将转换为结构化格式,以便于理解和访问。
如前所述,有多个图像与单个报表关联。因此,我们的模型在生成报告时也需要看到这些图像。但有些报告只有1张图片与之相关,而有些报告有2张,最多的只有4张。
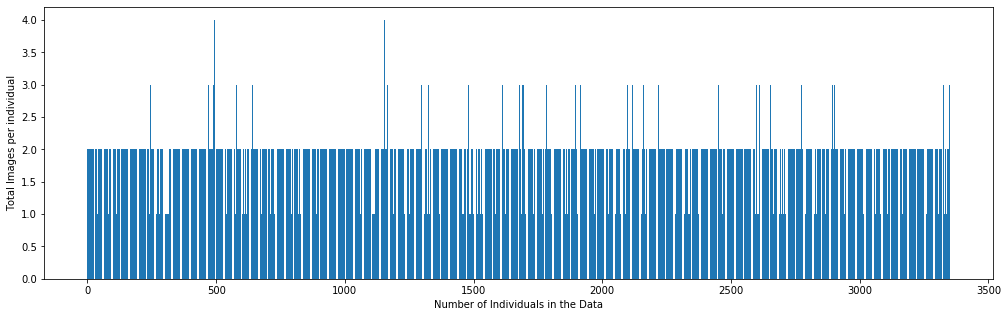
所以问题就出现了,我们一次应该向模型输入多少图像来生成报告?为了使模型输入一致,一次选择一对图像(即两个图像)作为输入。如果一个报表只有一个图像,那么同一个图像将被复制为第二个输入。

现在我们有了一个合适且可理解的结构化数据。图像按其绝对地址的名称保存。这将有助于加载数据。
5.准备文本数据
从XML文件中获得结果后,在我们将其输入模型之前,应该对它们进行适当的清理和准备。下面的图片展示了几个例子,展示了清洗前的发现是什么样子。

我们将按以下方式清理文本:
-
将所有字符转换为小写。
-
执行基本的解压,即将won’t、can’t等词分别转换为will not、can not等。
-
删除文本中的标点符号。注意,句号不会被删除,因为结果包含多个句子,所以我们需要模型通过识别句子以类似的方式生成报告。
-
从文本中删除所有数字。
-
删除长度小于或等于2的所有单词。例如,“is”、“to”等被删除。这些词不能提供太多信息。但是“no”这个词不会被删除,因为它增加了语义信息。在句子中加上“no”会完全改变它的意思。所以我们在执行这些清理步骤时必须小心。你需要确定哪些词应该保留,哪些词应该避免。
-
还发现一些文本包含多个句号或空格,或“X”重复多次。这样的字符也会被删除。
我们将开发的模型将生成一个由两个图像组合而成的报告,该报告将一次生成一个单词。先前生成的单词序列将作为输入提供。
因此,我们需要一个“第一个词”来启动生成过程,并用“最后一个词”来表示报告的结束。为此,我们将使用字符串“startseq”和“endseq”。这些字符串被添加到我们的数据中。现在这样做很重要,因为当我们对文本进行编码时,需要正确地对这些字符串进行编码。
编码文本的主要步骤是创建从单词到唯一整数值的一致映射,称为标识化。为了让我们的计算机能够理解任何文本,我们需要以机器能够理解的方式将单词或句子分解。如果不执行标识化,就无法处理文本数据。
标识化是将一段文本分割成更小的单元(称为标识)的一种方法。标识可以是单词或字符,但在我们的例子中,它将是单词。Keras为此提供了一个内置库。
from tensorflow.keras.preprocessing.text import Tokenizer
tokenizer = Tokenizer(filters='!"#$%&()*+,-/:;<=>?@[\\]^_`{|}~\t\n')
tokenizer.fit_on_texts(reports)
现在,我们已经对文本进行了适当的清理和标识,以备将来使用。所有这些的完整代码都可以在我的GitHub帐户中找到,这个帐户的链接在本文末尾提供。
6.获取图像特征
图像和部分报告是我们模型的输入。我们需要将每个图像转换成一个固定大小的向量,然后将其作为输入传递到模型中。为此,我们将使用迁移学习。
“在迁移学习中,我们首先在基本数据集和任务上训练基础网络,然后我们将学习到的特征重新指定用途,或将其转移到第二个目标网络,以便在目标数据集和任务上进行训练。如果特征是通用的,也就是说既适合基本任务也适合目标任务,而不是特定于基本任务,那此过程将趋于有效。”
VGG16、VGG19或InceptionV3是用于迁移学习的常见cnn。这些都是在像Imagenets这样的数据集上训练的,这些数据集的图像与胸部x光完全不同。所以从逻辑上讲,他们似乎不是我们任务的好选择。那么我们应该使用哪种网络来解决我们的问题呢?
如果你不熟悉,让我介绍你认识CheXNet。CheXNet是一个121层的卷积神经网络,训练于胸片X射线14上,目前是最大的公开胸片X射线数据集,包含10万多张正面视图的14种疾病的X射线图像。然而,我们在这里的目的不是对图像进行分类,而是获取每个图像的特征。因此,不需要该网络的最后一个分类层。
你可以从这里下载CheXNet的训练权重:https://drive.google.com/file/d/19BllaOvs2x5PLV_vlWMy4i8LapLb2j6b/view。
from tensorflow.keras.applications import densenet
chex = densenet.DenseNet121(include_top=False, weights = None, input_shape=(224,224,3), pooling="avg")
X = chex.output
X = Dense(14, activation="sigmoid", name="predictions")(X)
model = Model(inputs=chex.input, outputs=X)
model.load_weights('load_the_downloaded_weights.h5')
chexnet = Model(inputs = model.input, outputs = model.layers[-2].output)
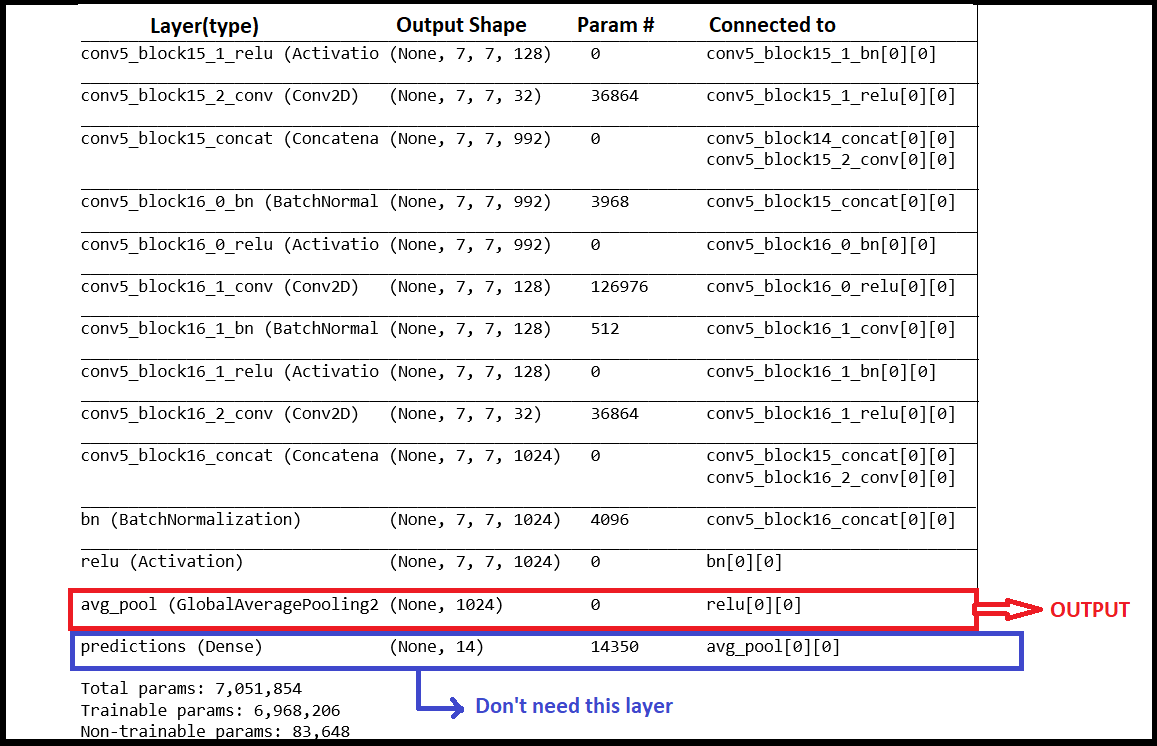
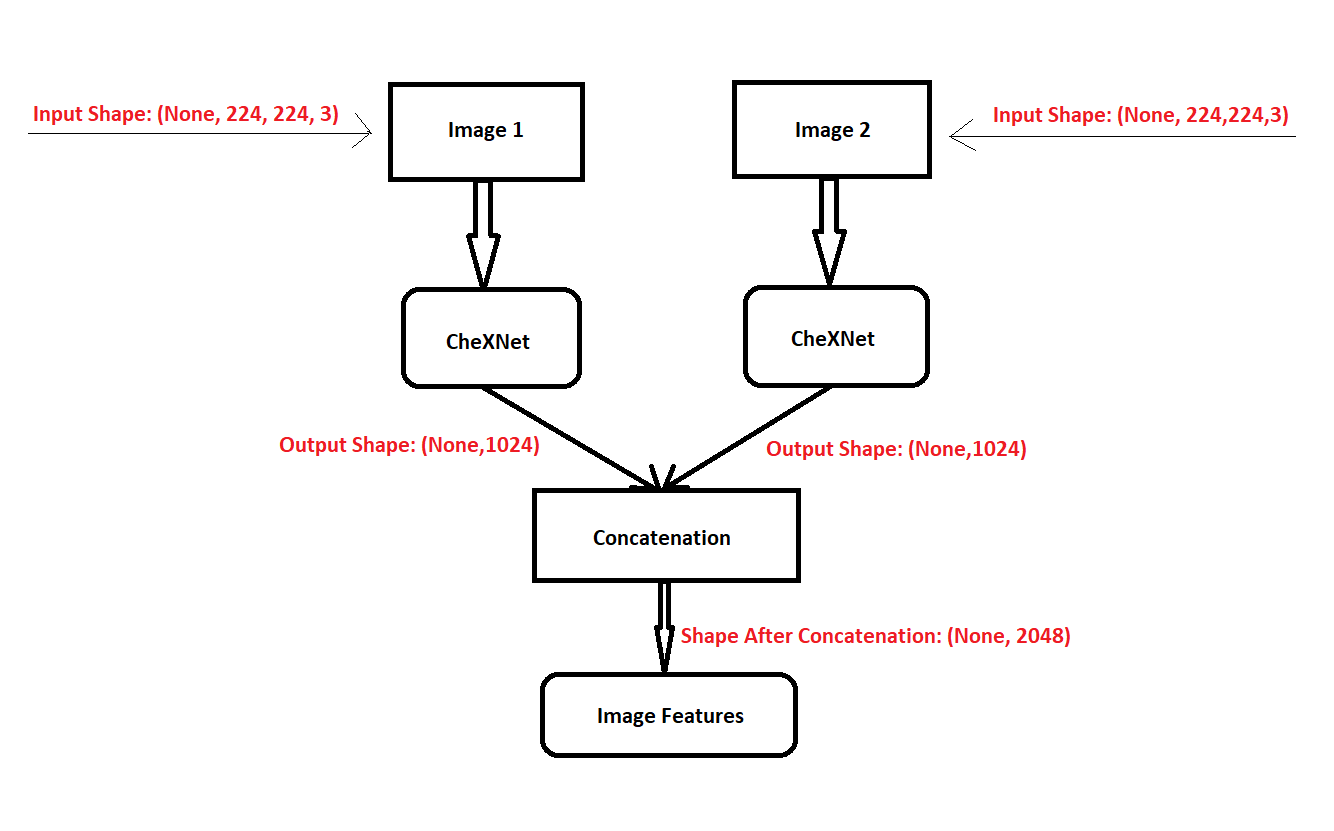
如果你忘了,我们有两个图像作为输入到我们的模型。下面是如何获得特征:
每个图像的大小被调整为 (224,224,3),并通过CheXNet传递,得到1024长度的特征向量。随后,将这两个特征向量串联以获得2048特征向量。
如果你注意到,我们添加了一个平均池层作为最后一层。这是有原因的。因为我们要连接两个图像,所以模型可能会学习一些连接顺序。例如,image1总是在image2之后,反之亦然,但这里不是这样。我们在连接它们时不保持任何顺序。这个问题是通过池来解决的。
代码如下:
def load_image(img_name):
'''加载图片函数'''
image = Image.open(img_name)
image_array = np.asarray(image.convert("RGB"))
image_array = image_array / 255.
image_array = resize(image_array, (224,224))
X = np.expand_dims(image_array, axis=0)
X = np.asarray(X)
return X
Xnet_features = {}
for key, img1, img2, finding in tqdm(dataset.values):
i1 = load_image(img1)
img1_features = chexnet.predict(i1)
i2 = load_image(img2)
img2_features = chexnet.predict(i2)
input_ = np.concatenate((img1_features, img2_features), axis=1)
Xnet_features[key] = input_
这些特征以pickle格式存储在字典中,可供将来使用。
7.输入管道
考虑这样一个场景:你有大量的数据,以至于你不能一次将所有数据都保存在RAM中。购买更多的内存显然不是每个人都可以进行的选择。
解决方案可以是动态地将小批量的数据输入到模型中。这正是数据生成器所做的。它们可以动态生成模型输入,从而形成从存储器到RAM的管道,以便在需要时加载数据。
这种管道的另一个优点是,当这些小批量数据准备输入模型时,可以轻松的应用。
为了我们的问题我们将使用tf.data。
我们首先将数据集分为两部分,一个训练数据集和一个验证数据集。在进行划分时,要确保你有足够的数据点用于训练,并且有足够数量的数据用于验证。我选择的比例允许我在训练集中有2560个数据点,在验证集中有1147个数据点。
现在是时候为我们的数据集创建生成器了。
X_train_img, X_cv_img, y_train_rep, y_cv_rep = train_test_split(dataset['Person_id'], dataset['Report'],
test_size = split_size, random_state=97)
def load_image(id_, report):
'''加载具有相应id的图像特征'''
img_feature = Xnet_Features[id_.decode('utf-8')][0]
return img_feature, report
def create_dataset(img_name_train, report_train):
dataset = tf.data.Dataset.from_tensor_slices((img_name_train, report_train))
# 使用map并行加载numpy文件
dataset = dataset.map(lambda item1, item2: tf.numpy_function(load_image, [item1, item2],
[tf.float32, tf.string]),
num_parallel_calls=tf.data.experimental.AUTOTUNE)
# 随机并batch化
dataset = dataset.shuffle(500).batch(BATCH_SIZE).prefetch(buffer_size=tf.data.experimental.AUTOTUNE)
return dataset
train_dataset = create_dataset(X_train_img, y_train_rep)
cv_dataset = create_dataset(X_cv_img, y_cv_rep)
在这里,我们创建了两个数据生成器,用于训练的train_dataset和用于验证的cv_dataset 。create_dataset函数获取id(对于前面创建的特征,这是字典的键)和预处理的报告,并创建生成器。生成器一次生成batch大小的数据点数量。
如前所述,我们要创建的模型将是一个逐字的模型。该模型以图像特征和部分序列为输入,生成序列中的下一个单词。
例如:让“图像特征”对应的报告为“startseq the cardiac silhouette and mediastinum size are within normal limits endseq”。
然后将输入序列分成11个输入输出对来训练模型:

注意,我们不是通过生成器创建这些输入输出对。生成器一次只向我们提供图像特征的batch处理大小数量及其相应的完整报告。输入输出对在训练过程中稍后生成,稍后将对此进行解释。
8.编解码器模型

sequence-to-sequence模型是一个深度学习模型,它接受一个序列(在我们的例子中,是图像的特征)并输出另一个序列(报告)。
编码器处理输入序列中的每一项,它将捕获的信息编译成一个称为上下文的向量。在处理完整个输入序列后,编码器将上下文发送到解码器,解码器开始逐项生成输出序列。
本例中的编码器是一个CNN,它通过获取图像特征来生成上下文向量。译码器是一个循环神经网络。
Marc Tanti在他的论文Where to put the Image in an Image Caption Generator, 中介绍了init-inject、par-inject、pre-inject和merge等多种体系结构。在创建一个图像标题生成器时,指定了图像应该注入的位置。我们将使用他论文中指定的架构来解决我们的问题。
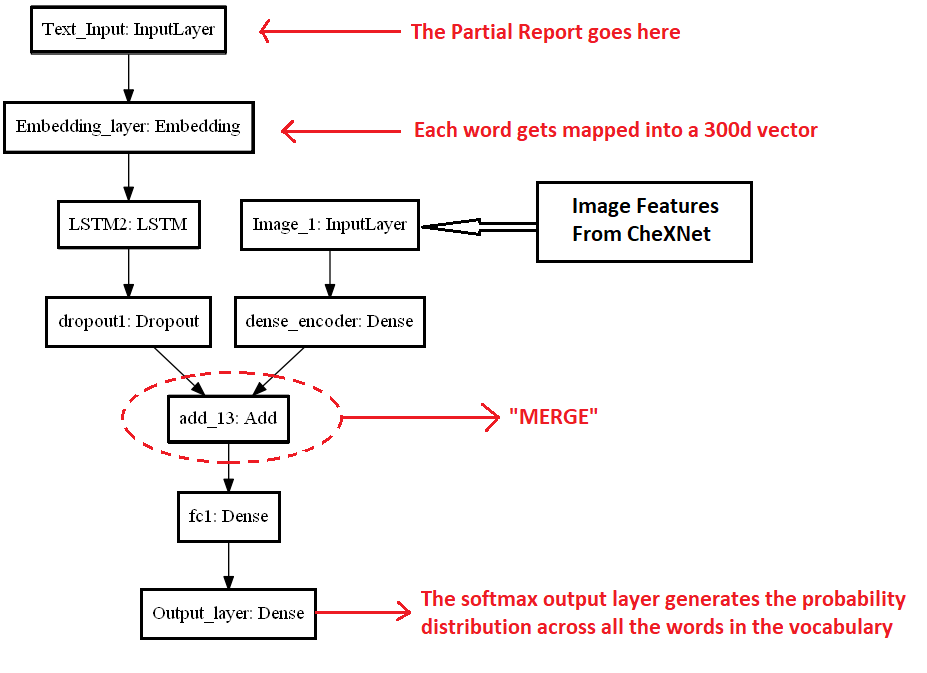
在“Merge”架构中,RNN在任何时候都不暴露于图像向量(或从图像向量派生的向量)。取而代之的是,在RNN进行了整体编码之后,图像被引入到语言模型中。这是一种后期绑定体系结构,它不会随每个时间步修改图像表示。
他的论文中的一些重要结论被用于我们实现的体系结构中。他们是:
-
RNN输出需要正则化,并带有丢失。
-
图像向量不应该有一个非线性的激活函数,或者使用dropout进行正则化。
-
从CheXNet中提取特征时,图像输入向量在输入到神经网络之前必须进行归一化处理。
嵌入层:
词嵌入是一类使用密集向量表示来表示单词和文档的方法。Keras提供了一个嵌入层,可以用于文本数据上的神经网络。它也可以使用在别处学过的词嵌入。在自然语言处理领域,学习、保存词嵌入是很常见的。
在我们的模型中,嵌入层使用预训练的GLOVE模型将每个单词映射到300维表示中。使用预训练的嵌入时,请记住,应该通过设置参数“trainable=False”冻结层的权重,这样权重在训练时不会更新。
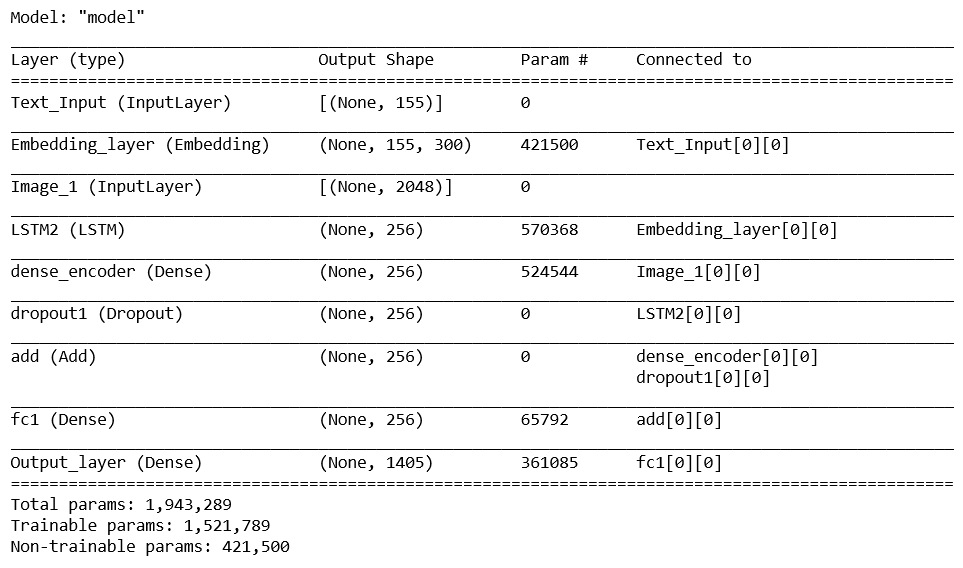
模型代码:
input1 = Input(shape=(2048), name='Image_1')
dense1 = Dense(256, kernel_initializer=tf.keras.initializers.glorot_uniform(seed = 56),
name='dense_encoder')(input1)
input2 = Input(shape=(155), name='Text_Input')
emb_layer = Embedding(input_dim = vocab_size, output_dim = 300, input_length=155, mask_zero=True,
trainable=False, weights=[embedding_matrix], name="Embedding_layer")
emb = emb_layer(input2)
LSTM2 = LSTM(units=256, activation='tanh', recurrent_activation='sigmoid', use_bias=True,
kernel_initializer=tf.keras.initializers.glorot_uniform(seed=23),
recurrent_initializer=tf.keras.initializers.orthogonal(seed=7),
bias_initializer=tf.keras.initializers.zeros(), name="LSTM2")
LSTM2_output = LSTM2(emb)
dropout1 = Dropout(0.5, name='dropout1')(LSTM2_output)
dec = tf.keras.layers.Add()([dense1, dropout1])
fc1 = Dense(256, activation='relu', kernel_initializer=tf.keras.initializers.he_normal(seed = 63),
name='fc1')
fc1_output = fc1(dec)
output_layer = Dense(vocab_size, activation='softmax', name='Output_layer')
output = output_layer(fc1_output)
encoder_decoder = Model(inputs = [input1, input2], outputs = output)
模型摘要:
8.1 训练
损失函数:
为此问题建立了一个掩蔽损失函数。例如:
如果我们有一系列标识[3],[10],[7],[0],[0],[0],[0],[0]
我们在这个序列中只有3个单词,0对应于填充,实际上这不是报告的一部分。但是模型会认为零也是序列的一部分,并开始学习它们。
当模型开始正确预测零时,损失将减少,因为对于模型来说,它是正确学习的。但对于我们来说,只有当模型正确地预测实际单词(非零)时,损失才应该减少。
因此,我们应该屏蔽序列中的零,这样模型就不会关注它们,而只学习报告中需要的单词。
loss_function = tf.keras.losses.CategoricalCrossentropy(from_logits=False, reduction='auto')
def maskedLoss(y_true, y_pred):
#获取掩码
mask = tf.math.logical_not(tf.math.equal(y_true, 0))
#计算loss
loss_ = loss_function(y_true, y_pred)
#转换为loss_ dtype类型
mask = tf.cast(mask, dtype=loss_.dtype)
#给损失函数应用掩码
loss_ = loss_*mask
#获取均值
loss_ = tf.reduce_mean(loss_)
return loss_
输出词是一个one-hot编码,因此分类交叉熵将是我们的损失函数。
optimizer = tf.keras.optimizers.Adam(0.001)
encoder_decoder.compile(optimizer, loss = maskedLoss)
还记得我们的数据生成器吗?现在是时候使用它们了。
这里,生成器提供的batch不是我们用于训练的实际数据batch。请记住,它们不是逐字输入输出对。它们只返回图像及其相应的整个报告。
我们将从生成器中检索每个batch,并将从该batch中手动创建输入输出序列,也就是说,我们将创建我们自己的定制的batch数据以供训练。所以在这里,batch处理大小逻辑上是模型在一个batch中看到的图像对的数量。我们可以根据我们的系统能力改变它。我发现这种方法比其他博客中提到的传统定制生成器要快得多。
由于我们正在创建自己的batch数据用于训练,因此我们将使用“train_on_batch”来训练我们的模型。
epoch_train_loss = []
epoch_val_loss = []
for epoch in range(EPOCH):
print('EPOCH : ',epoch+1)
start = time.time()
batch_loss_tr = 0
batch_loss_vl = 0
for img, report in train_dataset:
r1 = bytes_to_string(report.numpy())
img_input, rep_input, output_word = convert(img.numpy(), r1)
rep_input = pad_sequences(rep_input, maxlen=MAX_INPUT_LEN, padding='post')
results = encoder_decoder.train_on_batch([img_input, rep_input], output_word)
batch_loss_tr += results
train_loss = batch_loss_tr/(X_train_img.shape[0]//BATCH_SIZE)
with train_summary_writer.as_default():
tf.summary.scalar('loss', train_loss, step = epoch)
for img, report in cv_dataset:
r1 = bytes_to_string(report.numpy())
img_input, rep_input, output_word = convert(img.numpy(), r1)
rep_input = pad_sequences(rep_input, maxlen=MAX_INPUT_LEN, padding='post')
results = encoder_decoder.test_on_batch([img_input, rep_input], output_word)
batch_loss_vl += results
val_loss = batch_loss_vl/(X_cv_img.shape[0]//BATCH_SIZE)
with val_summary_writer.as_default():
tf.summary.scalar('loss', val_loss, step = epoch)
epoch_train_loss.append(train_loss)
epoch_val_loss.append(val_loss)
print('Training Loss: {}, Val Loss: {}'.format(train_loss, val_loss))
print('Time Taken for this Epoch : {} sec'.format(time.time()-start))
encoder_decoder.save_weights('Weights/BM7_new_model1_epoch_'+ str(epoch+1) + '.h5')
代码中提到的convert函数将生成器中的数据转换为逐字输入输出对表示。然后将剩余报告填充到报告的最大长度。
Convert 函数:
def convert(images, reports):
'''此函数接受batch数据并将其转换为新数据集'''
imgs = []
in_reports = []
out_reports = []
for i in range(len(images)):
sequence = [tokenizer.word_index[e] for e in reports[i].split() if e in tokenizer.word_index.keys()]
for j in range(1,len(sequence)):
in_seq = sequence[:j]
out_seq = sequence[j]
out_seq = tf.keras.utils.to_categorical(out_seq, num_classes=vocab_size)
imgs.append(images[i])
in_reports.append(in_seq)
out_reports.append(out_seq)
return np.array(imgs), np.array(in_reports), np.array(out_reports)
Adam优化器的学习率为0.001。该模型训练了40个epoch,但在第35个epoch得到了最好的结果。由于随机性,你得到的结果可能会有所不同。
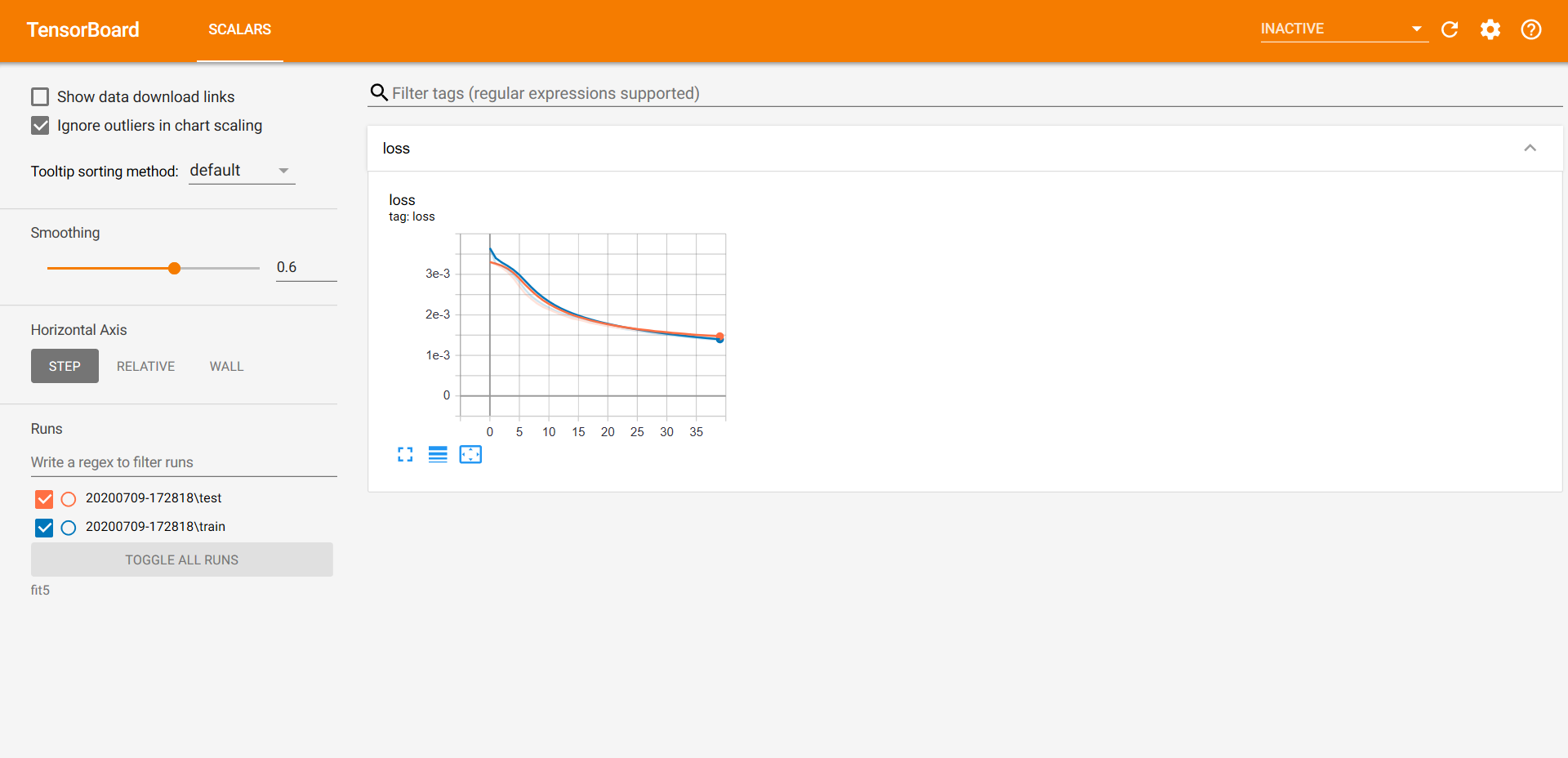
注:以上训练在Tensorflow 2.1中实现。
8.2 推理
现在我们已经训练了我们的模型,是时候准备我们的模型来预测报告了。
为此,我们必须对我们的模型作一些调整。这将在测试期间节省一些时间。
首先,我们将从模型中分离出编码器和解码器部分。由编码器预测的特征将被用作我们的解码器的输入。
# 编码器
encoder_input = encoder_decoder.input[0]
encoder_output = encoder_decoder.get_layer('dense_encoder').output
encoder_model = Model(encoder_input, encoder_output)
# 解码器
text_input = encoder_decoder.input[1]
enc_output = Input(shape=(256,), name='Enc_Output')
text_output = encoder_decoder.get_layer('LSTM2').output
add1 = tf.keras.layers.Add()([text_output, enc_output])
fc_1 = fc1(add1)
decoder_output = output_layer(fc_1)
decoder_model = Model(inputs = [text_input, enc_output], outputs = decoder_output)
通过这样做,我们只需要预测一次编码器的特征,而我们将其用于贪婪搜索和束(beam)搜索算法。
我们将实现这两种生成文本的算法,并看看哪一种算法最有效。
8.3 贪婪搜索算法
贪婪搜索是一种算法范式,它逐块构建解决方案,每次总是选择最好的。
贪婪搜索步骤:
-
编码器输出图像的特征。编码器的工作到此结束。一旦我们有了我们需要的特征,我们就不需要关注编码器了。
-
这个特征向量和起始标识“startseq”(我们的初始输入序列)被作为解码器的第一个输入。
-
译码器预测整个词汇表的概率分布,概率最大的单词将被选为下一个单词。
-
这个预测得到的单词和前一个输入序列将是我们下一个输入序列,并且传递到解码器。
-
继续执行步骤3-4,直到遇到结束标识,即“endseq”。
def greedysearch(img):
image = Xnet_Features[img] # 提取图像的初始chexnet特征
input_ = 'startseq' # 报告的起始标识
image_features = encoder_model.predict(image) # 编码输出
result = []
for i in range(MAX_REP_LEN):
input_tok = [tokenizer.word_index[w] for w in input_.split()]
input_padded = pad_sequences([input_tok], 155, padding='post')
predictions = decoder_model.predict([input_padded, image_features])
arg = np.argmax(predictions)
if arg != tokenizer.word_index['endseq']: # endseq 标识
result.append(tokenizer.index_word[arg])
input_ = input_ + ' ' + tokenizer.index_word[arg]
else:
break
rep = ' '.join(e for e in result)
return rep
让我们检查一下在使用greedysearch生成报告后,我们的模型的性能如何。
BLEU分数-贪婪搜索:
双语评估替补分数,简称BLEU,是衡量生成句到参考句的一个指标。
完美匹配的结果是1.0分,而完全不匹配的结果是0.0分。该方法通过计算候选文本中匹配的n个单词到参考文本中的n个单词,其中uni-gram是每个标识,bigram比较是每个单词对。

在实践中不可能得到完美的分数,因为译文必须与参考文献完全匹配。这甚至连人类的翻译人员都不可能做到。
要了解有关BLEU的更多信息,请单击此处:https://machinelearningmastery.com/calculate-bleu-score-for-text-python/
8.4 束搜索
Beam search(束搜索)是一种在贪婪搜索的基础上扩展并返回最有可能的输出序列列表的算法。每个序列都有一个与之相关的分数。以得分最高的顺序作为最终结果。
在构建序列时,束搜索不是贪婪地选择最有可能的下一步,而是扩展所有可能的下一步并保持k个最有可能的结果,其中k(即束宽度)是用户指定的参数,并通过概率序列控制束数或并行搜索。
束宽度为1的束搜索就是贪婪搜索。常见的束宽度值为5-10,但研究中甚至使用了高达1000或2000以上的值,以从模型中挤出最佳性能。要了解更多有关束搜索的信息,请单击此处。
但请记住,随着束宽度的增加,时间复杂度也会增加。因此,这些比贪婪搜索慢得多。
def beamsearch(image, beam_width):
start = [tokenizer.word_index['startseq']]
sequences = [[start, 0]]
img_features = Xnet_Features[image]
img_features = encoder_model.predict(img_features)
finished_seq = []
for i in range(max_rep_length):
all_candidates = []
new_seq = []
for s in sequences:
text_input = pad_sequences([s[0]], 155, padding='post')
predictions = decoder_model.predict([img_features, text_input])
top_words = np.argsort(predictions[0])[-beam_width:]
seq, score = s
for t in top_words:
candidates = [seq + [t], score - log(predictions[0][t])]
all_candidates.append(candidates)
sequences = sorted(all_candidates, key = lambda l: l[1])[:beam_width]
# 检查波束中每个序列中的'endseq'
count = 0
for seq,score in sequences:
if seq[len(seq)-1] == tokenizer.word_index['endseq']:
score = score/len(seq) # 标准化
finished_seq.append([seq, score])
count+=1
else:
new_seq.append([seq, score])
beam_width -= count
sequences = new_seq
# 如果所有序列在155个时间步之前结束
if not sequences:
break
else:
continue
sequences = finished_seq[-1]
rep = sequences[0]
score = sequences[1]
temp = []
rep.pop(0)
for word in rep:
if word != tokenizer.word_index['endseq']:
temp.append(tokenizer.index_word[word])
else:
break
rep = ' '.join(e for e in temp)
return rep, score
束搜索并不总是能保证更好的结果,但在大多数情况下,它会给你一个更好的结果。
你可以使用上面给出的函数检查束搜索的BLEU分数。但请记住,评估它们需要一段时间(几个小时)。
8.5 示例
现在让我们看看胸部X光片的预测报告:
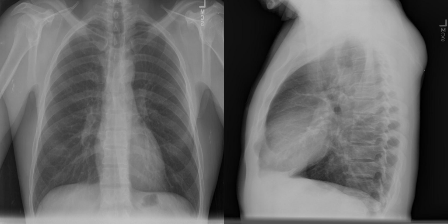
图像对1的原始报告:“心脏正常大小。纵隔不明显。肺部很干净。”
图像对1的预测报告:“心脏正常大小。纵隔不明显。肺部很干净。”
对于这个例子,模型预测的是完全相同的报告。
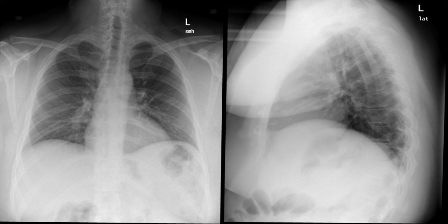
图像对2的原始报告:“心脏大小和肺血管在正常范围内。未发现局灶性浸润性气胸胸腔积液
图像对2的预测报告:“心脏大小和肺血管在正常范围内出现。肺为游离灶性空域病变。未见胸腔积液气胸
虽然不完全相同,但预测结果与最初的报告几乎相似。
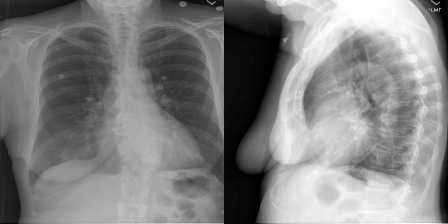
图像对3的原始报告:“肺过度膨胀但清晰。无局灶性浸润性渗出。心脏和纵隔轮廓在正常范围内。发现有钙化的纵隔
图像对3的预测报告:“心脏大小正常。纵隔轮廓在正常范围内。肺部没有任何病灶浸润。没有结节肿块。无明显气胸。无可见胸膜液。这是非常正常的。横膈膜下没有可见的游离腹腔内空气。”
你没想到这个模型能完美地工作,是吗?没有一个模型是完美的,这个也不是完美的。尽管存在从图像对3正确识别的一些细节,但是产生的许多额外细节可能是正确的,也可能是不正确的。
我们创建的模型并不是一个完美的模型,但它确实为我们的图像生成了体面的报告。
现在让我们来看看一个高级模型,看看它是否提高了当前的性能!!
9.注意机制

注意机制是对编解码模型的改进。事实证明,上下文向量是这些类型模型的瓶颈。这使他们很难处理长句。Bahdanau et al.,2014和Luong et al.,2015提出了解决方案。
这些论文介绍并改进了一种叫做“注意机制”的技术,它极大地提高了机器翻译系统的质量。注意允许模型根据需要关注输入序列的相关部分。后来,这一思想被应用于图像标题。
那么,我们如何为图像建立注意力机制呢?

对于文本,我们对输入序列的每个位置都有一个表示。但是对于图像,我们通常使用网络中一个全连接层表示,但是这种表示不包含任何位置信息(想想看,它们是全连接的)。
我们需要查看图像的特定部分(位置)来描述其中的内容。例如,要从x光片上描述一个人的心脏大小,我们只需要观察他的心脏区域,而不是他的手臂或任何其他部位。那么,注意力机制的输入应该是什么呢?
我们使用卷积层(迁移学习)的输出,而不是全连接的表示,因为卷积层的输出具有空间信息。
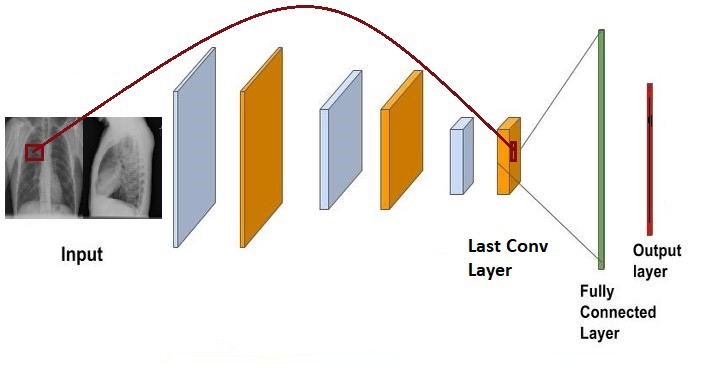
例如,让最后一个卷积层的输出是(7×14×1024)大小的特征。这里,“7×14”是与图像中某些部分相对应的实际位置,1024个是通道。我们关注的不是通道而是图像的位置。因此,这里我们有7*14=98个这样的位置。我们可以把它看作是98个位置,每个位置都有1024维表示。
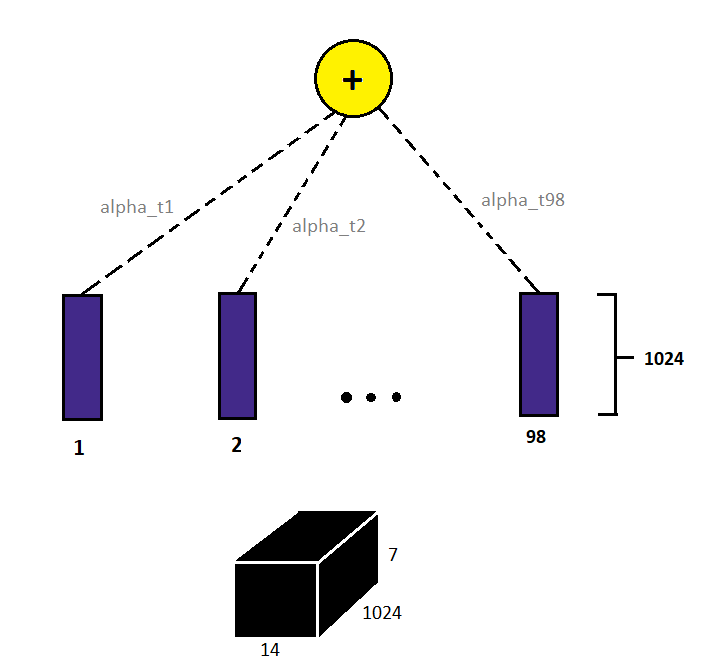
现在我们有98个时间步,每个时间步有1024个维表示。我们现在需要决定模型应该如何关注这98个时间点或位置。
一个简单的方法是给每个位置分配一些权重,然后得到所有这98个位置的加权和。如果一个特定的时间步长对于预测一个输出非常重要,那么这个时间步长将具有更高的权重。让这些重量用字母表示。
现在我们知道了,alpha决定了一个特定地点的重要性。alpha值越高,重要性越高。但是我们如何找到alpha的值呢?没有人会给我们这些值,模型本身应该从数据中学习这些值。为此,我们定义了一个函数:
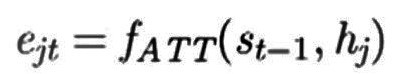
这个量表示第j个输入对于解码第t个输出的重要性。h_j是第j个位置表示,s_t-1是解码器到该点的状态。我们需要这两个量来确定e_jt。f_ATT只是一个函数,我们将在后面定义。
在所有输入中,我们希望这个量(e_jt)的总和为1。这就像是用概率分布来表示输入的重要性。利用softmax将e_jt转换为概率分布。
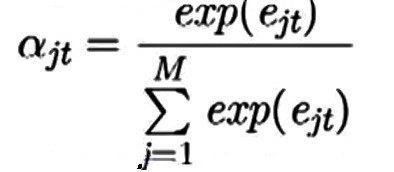
现在我们有了alphas!alphas是我们的权重。alpha_jt表示聚焦于第j个输入以产生第t个输出的概率。
现在是时候定义我们的函数f_ATT了。以下是许多可能的选择之一:
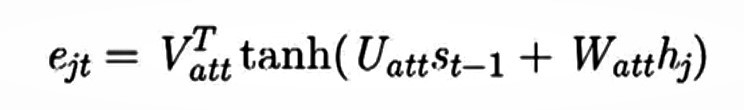
V、 U和W是在训练过程中学习的参数,用于确定e_jt的值。
我们有alphas,我们有输入,现在我们只需要得到加权和,产生新的上下文向量,它将被输入解码器。在实践中,这些模型比编解码器模型工作得更好。
模型实现:
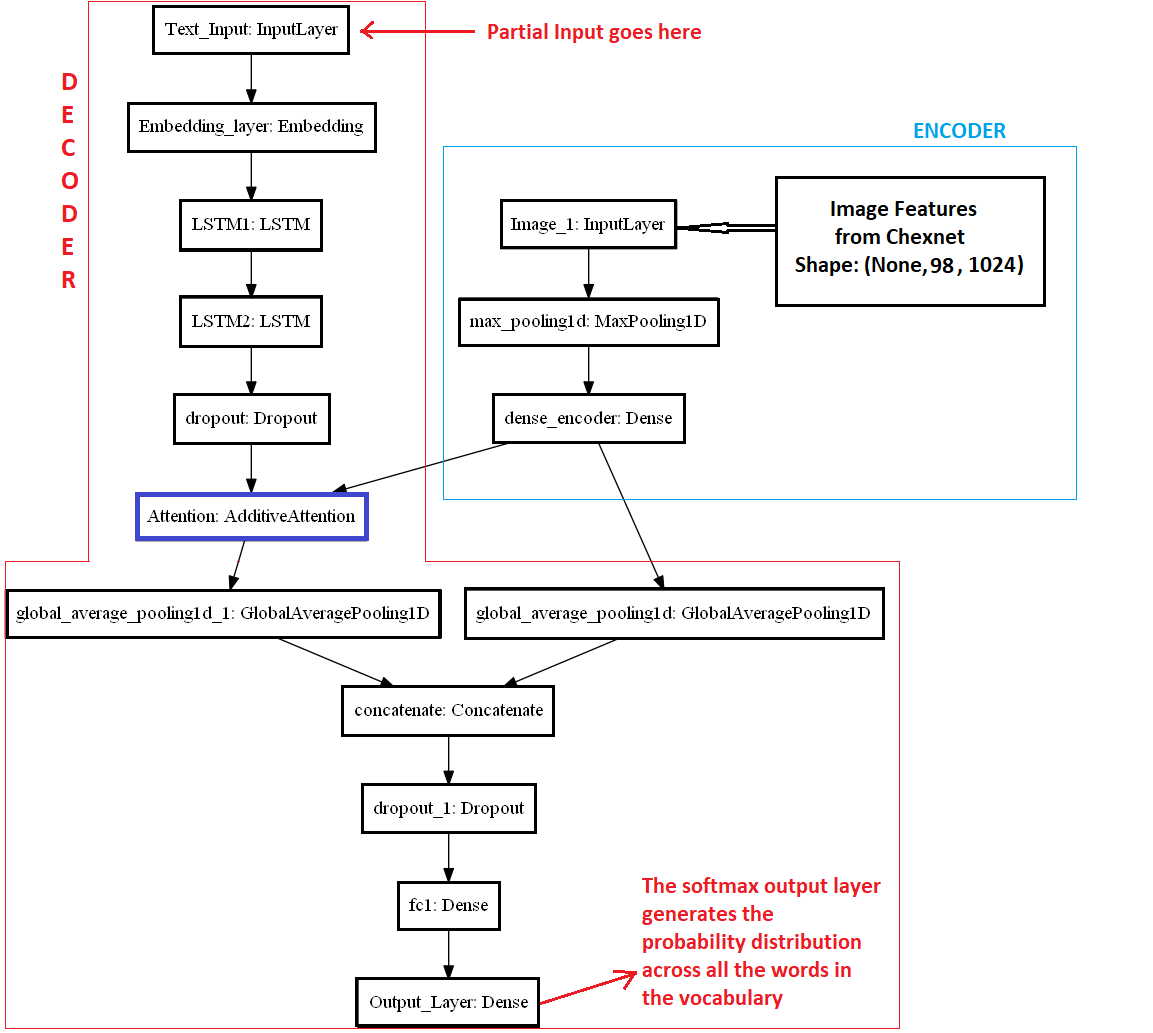
和上面提到的编解码器模型一样,这个模型也将由两部分组成,一个编码器和一个解码器,但这次解码器中会有一个额外的注意力成分,即注意力解码器。为了更好地理解,现在让我们用代码编写:
# 计算e_jts
score = self.Vattn(tf.nn.tanh(self.Uattn(features) + self.Wattn(hidden_with_time_axis)))
# 使用softmax将分数转换为概率分布
attention_weights = tf.nn.softmax(score, axis=1)
# 计算上下文向量(加权和)
context_vector = attention_weights * features
在构建模型时,我们不必从头开始编写这些代码行。keras库已经为这个目的内置了一个注意层。我们将直接使用添加层或其他称为Bahdanau的注意力。你可以从文档本身了解有关该层的更多信息。链接:https://www.tensorflow.org/api_docs/python/tf/keras/layers/AdditiveAttention
这个模型的文本输入将保持不变,但是对于图像特征,这次我们将从CheXNet网络的最后一个conv层获取特征。
合并两幅图像后的最终输出形状为(None,7,14,1024)。所以整形后编码器的输入将是(None,981024)。为什么要重塑图像?好吧,这已经在注意力介绍中解释过了,如果你有任何疑问,一定要把解释再读一遍。
模型:
input1 = Input(shape=(98,1024), name='Image_1')
maxpool1 = tf.keras.layers.MaxPool1D()(input1)
dense1 = Dense(256, kernel_initializer=tf.keras.initializers.glorot_uniform(seed = 56), name='dense_encoder')(maxpool1)
input2 = Input(shape=(155), name='Text_Input')
emb_layer = Embedding(input_dim = vocab_size, output_dim = 300, input_length=155, mask_zero=True, trainable=False,
weights=[embedding_matrix], name="Embedding_layer")
emb = emb_layer(input2)
LSTM1 = LSTM(units=256, activation='tanh', recurrent_activation='sigmoid', use_bias=True,
kernel_initializer=tf.keras.initializers.glorot_uniform(seed=23),
recurrent_initializer=tf.keras.initializers.orthogonal(seed=7),
bias_initializer=tf.keras.initializers.zeros(), return_sequences=True, return_state=True, name="LSTM1")
lstm_output, h_state, c_state = LSTM1(emb)
LSTM2 = LSTM(units=256, activation='tanh', recurrent_activation='sigmoid', use_bias=True,
kernel_initializer=tf.keras.initializers.glorot_uniform(seed=23),
recurrent_initializer=tf.keras.initializers.orthogonal(seed=7),
bias_initializer=tf.keras.initializers.zeros(), return_sequences=True, return_state=True, name="LSTM2")
lstm_output, h_state, c_state = LSTM2(lstm_output)
dropout1 = Dropout(0.5)(lstm_output)
attention_layer = tf.keras.layers.AdditiveAttention(name='Attention')
attention_output = attention_layer([dense1, dropout1], training=True)
dense_glob = tf.keras.layers.GlobalAveragePooling1D()(dense1)
att_glob = tf.keras.layers.GlobalAveragePooling1D()(attention_output)
concat = Concatenate()([dense_glob, att_glob])
dropout2 = Dropout(0.5)(concat)
FC1 = Dense(256, activation='relu', kernel_initializer=tf.keras.initializers.he_normal(seed = 56), name='fc1')
fc1 = FC1(dropout2)
OUTPUT_LAYER = Dense(vocab_size, activation='softmax', name='Output_Layer')
output = OUTPUT_LAYER(fc1)
attention_model = Model(inputs=[input1, input2], outputs = output)
该模型类似于我们之前看到的编解码器模型,但有注意组件和一些小的更新。如果你愿意,你可以尝试自己的改变,它们可能会产生更好的结果。
模型架构:
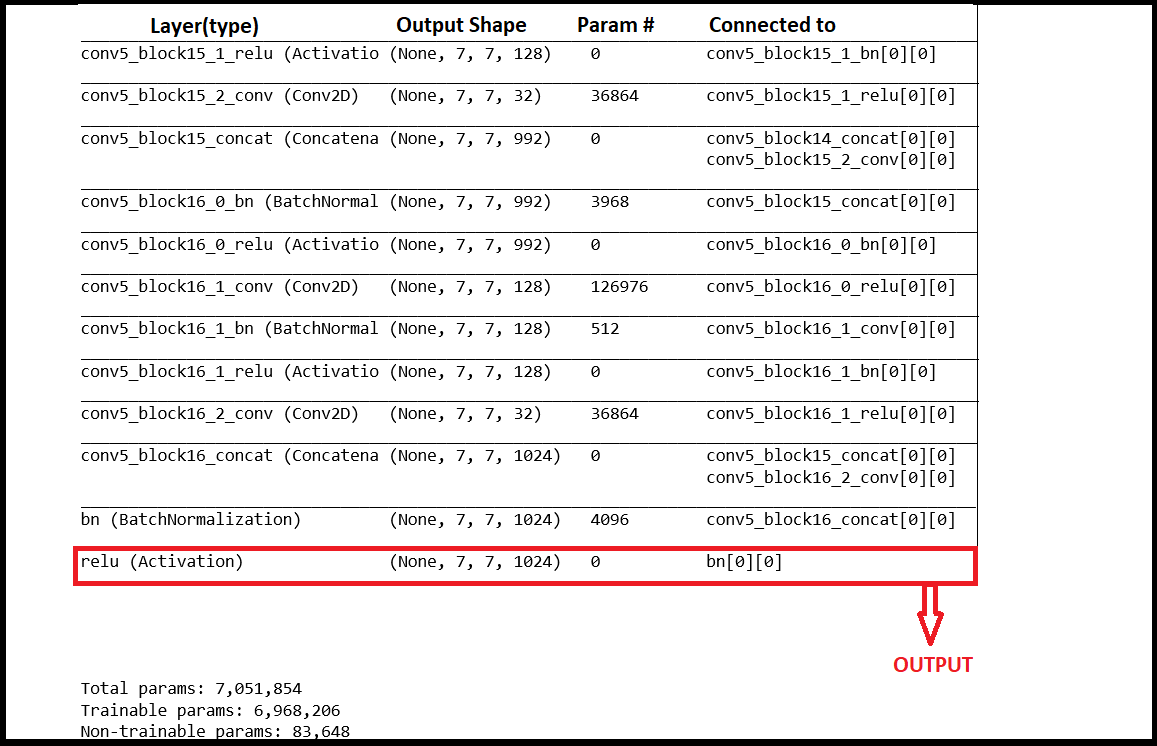
模型摘要:

9.1 训练
训练步骤将与我们的编解码器模型完全相同。我们将使用相同的“convert”函数生成批处理,从而获得逐字输入输出序列,并使用train_on_batch对其进行训练。
与编解码器模型相比,注意力模型需要更多的内存和计算能力。因此,你可能需要减小这个batch的大小。全过程请参考编解码器模型的训练部分。
为了注意机制,使用了adam优化器,学习率为0.0001。这个模型被训练了20个epoch。由于随机性,你得到的结果可能会有所不同。

所有代码都可以从我的GitHub访问。它的链接已经在这个博客的末尾提供了。
9.2 推理
与之前中一样,我们将从模型中分离编码器和解码器部分。
# 编码器
encoder_input = attention_model.input[0]
encoder_output = attention_model.get_layer('dense_encoder').output
encoder_model = Model(encoder_input, encoder_output)
# 有注意力机制的解码器
text_input = attention_model.input[1]
cnn_input = Input(shape=(49,256))
lstm, h_s, c_s = attention_model.get_layer('LSTM2').output
att = attention_layer([cnn_input, lstm])
d_g = tf.keras.layers.GlobalAveragePooling1D()(cnn_input)
a_g = tf.keras.layers.GlobalAveragePooling1D()(att)
con = Concatenate()([d_g, a_g])
fc_1 = FC1(con)
out = OUTPUT_LAYER(fc_1)
decoder_model = Model([cnn_input, text_input], out)
这为我们节省了一些测试时间。
9.3 贪婪搜索
现在,我们已经构建了模型,让我们检查获得的BLEU分数是否确实比以前的模型有所改进:

我们可以看出它比贪婪搜索的编解码模型有更好的性能。因此,它绝对是比前一个改进。
9.4 束搜索
现在让我们看看束搜索的一些分数:

BLEU得分低于贪婪算法,但差距并不大。但值得注意的是,随着束宽度的增加,分数实际上在增加。因此,可能存在束宽度的某个值,其中分数与贪婪算法的分数交叉。
9.5 示例
以下是模型使用贪婪搜索生成的一些报告:

图像对1的原始报告:“心脏大小和肺血管在正常范围内。未发现局灶性浸润性气胸胸腔积液
图像对1的预测报告:“心脏大小和纵隔轮廓在正常范围内。肺是干净的。没有气胸胸腔积液。没有急性骨性发现。”
这些预测与最初的报告几乎相似。

图像对2的原始报告:“心脏大小和肺血管在正常范围内出现。肺为游离灶性空域病变。未见胸腔积液气胸
图像对2的预测报告:“心脏大小和肺血管在正常范围内出现。肺为游离灶性空域病变。未见胸腔积液气胸
预测的报告完全一样!!
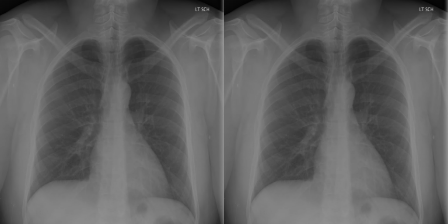
图像对3的原始报告:“心脏正常大小。纵隔不明显。肺部很干净。”
图像对3的预测报告:“心脏正常大小。纵隔不明显。肺部很干净。”
在这个例子中,模型也做得很好。
图像对4的原始报告:“双侧肺清晰。明确无病灶实变气胸胸腔积液。心肺纵隔轮廓不明显。可见骨结构胸部无急性异常
图像对4的预测报告:“心脏大小和纵隔轮廓在正常范围内。肺是干净的。没有气胸胸腔积液
你可以看到这个预测并不真正令人信服。
“但是,这个例子的束搜索预测的是完全相同的报告,即使它产生的BLEU分数比整个测试数据的总和要低!!!”
那么,选择哪一个呢?好吧,这取决于我们。只需选择一个通用性好的方法。
在这里,即使我们的注意力模型也不能准确地预测每一幅图像。如果我们查看原始报告中的单词,则会发现一些复杂的单词,通过一些EDA可以发现它并不经常出现。这些可能是我们在某些情况下没有很好的预测的一些原因。
请记住,我们只是在2560个数据点上训练这个模型。为了学习更复杂的特征,模型需要更多的数据。
10.摘要
现在我们已经结束了这个项目,让我们总结一下我们所做的:
-
我们刚刚看到了图像字幕在医学领域的应用。我们理解这个问题,也理解这种应用的必要性。
-
我们了解了如何为输入管道使用数据生成器。
-
创建了一个编解码器模型,给了我们不错的结果。
-
通过建立一个注意模型来改进基本结果。
11.今后的工作
正如我们提到的,我们没有大的数据集来完成这个任务。较大的数据集将产生更好的结果。
没有对任何模型进行超参数调整。因此,一个更好的超参数调整可能会产生更好的结果。
利用一些更先进的技术,如transformers 或Bert,可能会产生更好的结果。
12.引用
- https://www.appliedaicourse.com/
- https://arxiv.org/abs/1502.03044
- https://www.aclweb.org/anthology/P18-1240/
- https://arxiv.org/abs/1703.09137
- https://arxiv.org/abs/1409.0473
- https://machinelearningmastery.com/develop-a-deep-learning-caption-generation-model-in-python/
这个项目的整个代码可以从我的GitHub访问:https://github.com/vysakh10/Image-Captioning
原文链接:https://towardsdatascience.com/image-captioning-using-deep-learning-fe0d929cf337
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号