

神经机器翻译的直观解释
作者|Renu Khandelwal
编译|VK
来源|Towards Data Science
什么是神经机器翻译?
神经机器翻译是一种将一种语言翻译成另一种语言的技术。一个例子是把英语转换成印地语。让我们想想,如果你在一个印度村庄,那里的大多数人都不懂英语。你打算毫不费力地与村民沟通。在这种情况下,你可以使用神经机器翻译。
神经机器翻译的任务是使用深层神经网络从一个源语言(如英语)的一系列单词转换成一个序列的目标语言(如西班牙语)。
神经机器翻译的特点是什么?
- 能够在多个时间步中持久存储顺序数据
NMT使用连续的数据,这些数据需要在几个时间步中进行持久保存。人工神经网络(ANN)不会将数据保存在几个时间步长上。循环神经网络(RNN),如LSTM(长短时记忆)或GRU(门控递归单元),能够在多个时间步长中持久保存数据
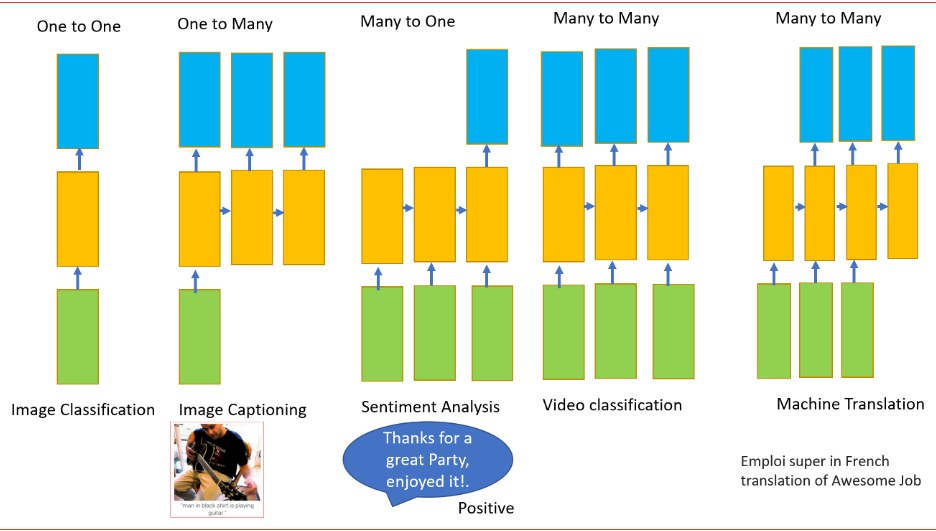
- 处理可变长度的输入和输出向量的能力
ANN和CNN需要一个固定的输入向量,在这个向量上应用一个函数来产生一个固定大小的输出。NMT将一种语言翻译成另一种语言,源语言和目标语言的单词序列的长度是可变的。

RNN与LSTM或GRU一样如何帮助进行顺序数据处理?
RNN是一种神经网络,结构中具有循环来保存信息。它们对序列中的每个元素执行相同的任务,并且输出元素依赖于以前的元素或状态。这正是我们处理顺序数据所需要的。
RNN可以有一个或多个输入以及一个或多个输出。这是处理顺序数据(即变量输入和变量输出)的另一个要求
为什么我们不能用RNN进行神经机器翻译?
在人工神经网络中,我们不需要在网络的不同层之间共享权重,因此,我们不需要对梯度求和。RNN的共享权重,我们需要在每个时间步中得出W的梯度,如下所示。
在时间步t=0计算h的梯度涉及W的许多因素,因为我们需要通过每个RNN单元反向传播。即使我们不要权重矩阵,并且一次又一次地乘以相同的标量值,但是时间步如果特别大,比如说100个时间步,这将是一个挑战。
如果最大奇异值大于1,则梯度将爆炸,称为爆炸梯度。
如果最大奇异值小于1,则梯度将消失,称为消失梯度。
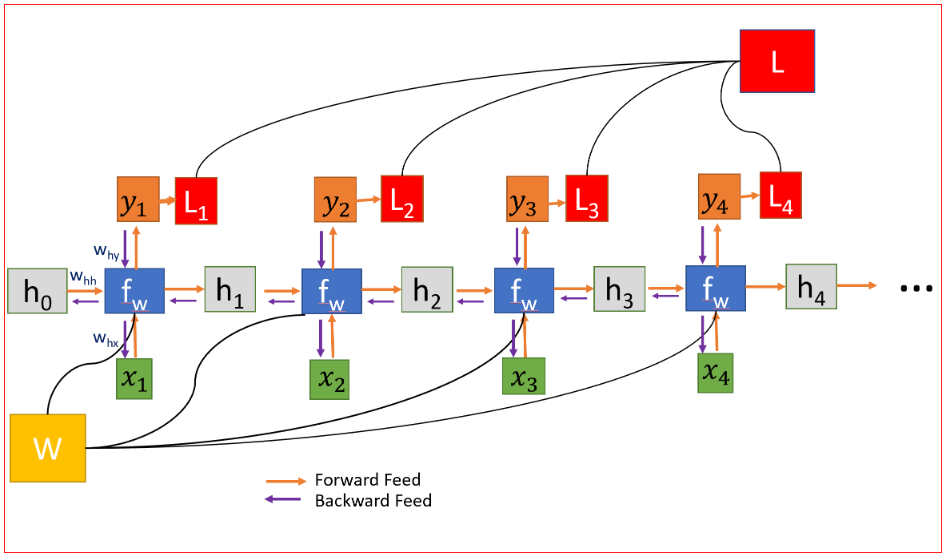
权重在所有层中共享,导致梯度爆炸或消失
对于梯度爆炸问题,我们可以使用梯度剪裁,其中我们可以预先设置一个阈值,如果梯度值大于阈值,我们可以剪裁它。
为了解决消失梯度问题,常用的方法是使用长短期记忆(LSTM)或门控循环单元(GRU)。
什么是LSTM和GRU?
LSTM是长短时记忆网络(Long Short Term Memory),GRU是门控循环单元(Gated Recurrent Unit)。他们能够快速学习长期依赖性。LSTM可以学习跨越1000步的时间间隔。这是通过一种高效的基于梯度的算法实现的。
LSTM和GRU在很长一段时间内记住信息。他们通过决定要记住什么和忘记什么来做到这一点。
LSTM使用4个门,你可以将它们认为是否需要记住以前的状态。单元状态在LSTMs中起着关键作用。LSTM可以使用4个调节门来决定是否要从单元状态添加或删除信息。这些门的作用就像水龙头,决定了应该通过多少信息。

GRU是求解消失梯度问题的LSTM的一个简单变种
它使用两个门:重置门和更新门,这与LSTM中的三个步骤不同。GRU没有内部记忆
重置门决定如何将新输入与前一个时间步的记忆相结合。更新门决定了应该保留多少以前的记忆。
GRU的参数更少,因此它们的计算效率更高,并且比LSTM需要的数据更少
如何使用LSTM或GRU进行神经机器翻译?
我们使用以LSTM或GRU为基本块的编解码器框架创建Seq2Seq模型
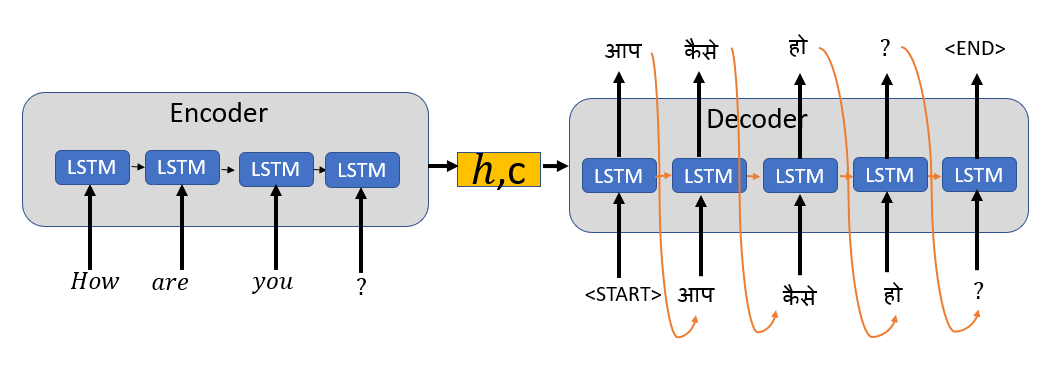
序列到序列(seq2seq)模型将源序列映射到目标序列。源序列是机器翻译系统的输入语言,目标序列是输出语言。
Encoder(编码器):从源语言中读取单词的输入序列,并将该信息编码为实值向量,也称为隐状态向量或上下文向量。该向量将输入序列的“意义”编码为单个向量。编码器输出被丢弃,只有隐状态或内部状态作为初始输入传递给解码器
Decoder(解码器):将来自编码器的上下文向量作为输入,并将字符串标记的开始<start>作为初始输入,以生成输出序列。
编码器逐字读取输入序列,类似地解码器逐字生成输出序列。
在训练和推理阶段,解码器的工作方式不同,而在训练和推理阶段,编码器的工作方式相同
解码器的训练阶段

我们使用Teacher forcing(强制教学)来快速有效地训练解码器。
Teacher forcing就像教师在学生接受新概念的训练时纠正学生一样。由于教师在训练过程中给予学生正确的输入,学生将更快、更有效地学习新概念。
Teacher forcing算法通过在训练过程中提供前一时间戳的实际输出而不是前一时间的预测输出作为输入来训练解码器。
我们添加一个标记<START>来表示目标序列的开始,并添加一个标记<END>作为目标序列的最后一个单词。<END>标记稍后在推断阶段用作停止条件,以表示输出序列的结束。
解码器的推理阶段
在推断或预测阶段,我们没有实际的输出序列或单词。在推理阶段,我们将上一个时间步的预测输出作为输入和隐藏状态一起传递给解码器。
解码器预测阶段的第一时间步将具有来自编码器和<START>标记的最终状态作为输入。
对于随后的时间步骤,解码器的输入将是前一解码器的隐藏状态以及前一解码器的输出。
当达到最大目标序列长度或<END>标记时,预测阶段停止。
注:这只是Seq2Seq的直观解释。我们为输入语言单词和目标语言单词创建单词嵌入。嵌入提供了单词及其相关含义的向量表示。
如何提高seq2seq模型的性能?
- 大型训练数据集
- 超参数调节
- 注意力机制
什么是注意力机制?
编码器将上下文向量传递给解码器。上下文向量是总结整个输入序列的单个向量。
注意力机制的基本思想是避免试图为每个句子学习单一的向量表示。注意力机制根据注意权值来关注输入序列的某些输入向量。这允许解码器网络“聚焦”于编码器输出的不同部分。它使用一组注意权重对解码器自身输出的每个时间步执行此操作。
原文链接:https://towardsdatascience.com/intuitive-explanation-of-neural-machine-translation-129789e3c59f
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号