

机器学习中的AUC-ROC曲线
作者|ANIRUDDHA BHANDARI
编译|VK
来源|Analytics Vidhya
AUC-ROC曲线
你已经建立了你的机器学习模型-那么接下来呢?你需要对它进行评估,并验证它有多好(或有多坏),这样你就可以决定是否实现它。这时就可以引入AUC-ROC曲线了。
这个名字可能有点夸张,但它只是说我们正在计算“Receiver Characteristic Operator”(ROC)的“Area Under the Curve”(AUC)。
别担心,我们会详细了解这些术语的含义,一切都将是小菜一碟!

现在,只需知道AUC-ROC曲线可以帮助我们可视化机器学习分类器的性能。虽然它只适用于二值分类问题,但我们将在最后看到如何扩展它来评估多类分类问题。
我们还将讨论敏感性(sensitivity )和特异性(specificity )等主题,因为这些是AUC-ROC曲线背后的关键主题。
目录
-
什么是敏感性和特异性?
-
预测概率
-
AUC-ROC曲线是什么?
-
AUC-ROC曲线是如何工作的?
-
Python中的AUC-ROC
-
用于多类分类的AUC-ROC
什么是敏感性和特异性?
混淆矩阵:
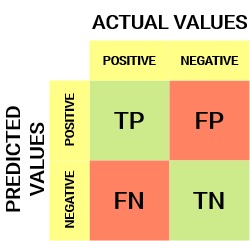
从混淆矩阵中,我们可以得到一些在前面的文章中没有讨论过的重要度量。让我们在这里谈谈他们。
敏感度/真正例率/召回率
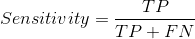
敏感度告诉我们什么比例的正例得到了正确的分类。
一个简单的例子是确定模型正确检测到的实际病人的比例。
假反例率
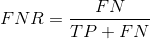
假反例率(FNR)告诉我们什么比例的正例被分类器错误分类。
更高的TPR和更低的FNR是可取的,因为我们希望正确地分类正类。
特异性/真反例率
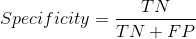
特异性告诉我们什么比例的反例类得到了正确的分类。
以敏感性为例,特异性意味着确定模型正确识别的健康人群比例。
假正例率
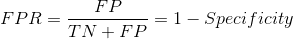
FPR告诉我们哪些负类被分类器错误分类。
更高的TNR和更低的FPR是可取的,因为我们想正确地分类负类。
在这些指标中,敏感性和特异性可能是最重要的,我们稍后将看到如何使用它们来构建评估指标。
但在此之前,我们先来了解一下为什么预测概率比直接预测目标类要好。
预测概率
机器学习分类模型可以直接预测数据点的实际类别或预测其属于不同类别的概率。
后者使我们对结果有更多的控制权。我们可以确定自己的阈值来解释分类器的结果。这更为谨慎!
为数据点设置不同的分类阈值会无意中改变模型的敏感性和特异性。
其中一个阈值可能会比其他阈值给出更好的结果,这取决于我们的目标是降低假反例还是假正例的数量。
请看下表:

度量值随阈值的变化而变化。我们可以生成不同的混淆矩阵,并比较上一节中讨论的各种度量。
但这样做并不明智。相反,我们所能做的是在这些度量之间生成一个图,这样我们就可以很容易地看到哪个阈值给了我们一个更好的结果。
AUC-ROC曲线正好解决了这个问题!
AUC-ROC曲线是什么?
ROC曲线是二值分类问题的一个评价指标。它是一个概率曲线,在不同的阈值下绘制TPR与FPR的关系图,从本质上把“信号”与“噪声”分开。
曲线下面积(AUC)是分类器区分类的能力的度量,用作ROC曲线的总结。
AUC越高,模型在区分正类和负类方面的性能越好。

当AUC=1时,分类器能够正确区分所有的正类点和负类点。然而,如果AUC为0,那么分类器将预测所有的否定为肯定,所有的肯定为否定。
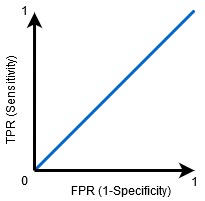
当0.5<AUC<1时,分类器很有可能区分正类值和负类值。这是因为与假反例和假正例相比,分类器能够检测更多的真正例和真反例。
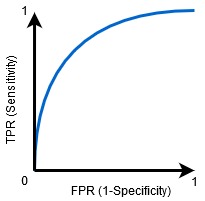
当AUC=0.5时,分类器无法区分正类点和负类点。这意味着分类器要么预测所有数据点的随机类,要么预测常量类。
因此,分类器的AUC值越高,其区分正类和负类的能力就越好。
AUC-ROC曲线是如何工作的
在ROC曲线中,较高的X轴值表示假正例数高于真反例数。而Y轴值越高,则表示真正例数比假反例数高。
因此,阈值的选择取决于在假正例和假反例之间进行平衡的能力。
让我们深入一点,了解不同阈值下ROC曲线的形状,以及特异性和敏感性的变化。
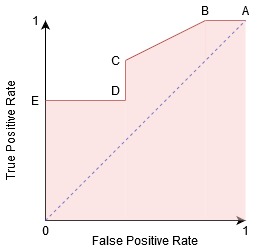
我们可以尝试通过为每个对应于阈值的点生成混淆矩阵来理解此图,并讨论分类器的性能:
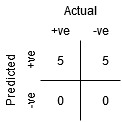
A点是敏感性最高,特异性最低的地方。这意味着所有的正类点被正确分类,所有的负类点被错误分类。
事实上,蓝线上的任何一点都对应于真正例率等于假正例率的情况。
这条线上的所有点都对应于属于正类的正确分类点的比例大于属于负类的错误分类点的比例的情况。
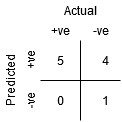
虽然B点与A点具有相同的敏感性,但具有较高的特异性。这意味着错误的负类点数量比上一个阈值要低。这表明此阈值比前一阈值好。
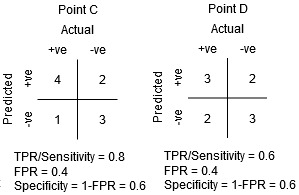
在C点和D点之间,在相同特异度下,C点的敏感性高于D点。这意味着,对于相同数量的错误分类的负类点,分类器预测的正类点数量更高。因此,C点的阈值优于D点。
现在,取决于我们要为分类器容忍多少错误的分类点,我们将在B点和C点之间进行选择,以预测你是否可以在PUBG中击败我。
“错误的希望比恐惧更危险。”——J.R.R.托尔金

E点是特异性最高的地方。也就是说没有假正例被模型分类。该模型能对所有的负类点进行正确的分类!如果我们的问题是给用户提供完美的歌曲推荐,我们会选择这一点。
按照这个逻辑,你能猜出一个完美的分类器对应的点在图上的什么位置吗?
对!它将位于ROC图的左上角,对应于笛卡尔平面中的坐标(0,1)。在这里,敏感性和特异性都将是最高的,分类器将正确地分类所有的正类点和负类点。
Python中的AUC-ROC曲线
现在,要么我们可以手动测试每个阈值的敏感性和特异性,要么让sklearn为我们做这项工作。我们选择sklearn
让我们使用sklearn make_classification 方法创建任意数据:
我将在此数据集上测试两个分类器的性能:
Sklearn有一个非常有效的方法roc_curve(),它可以在几秒钟内计算分类器的roc!它返回FPR、TPR和阈值:
可以使用sklearn的roc_auc_score()方法计算AUC得分:
0.9761029411764707 0.9233769727403157
我们还可以使用matplotlib绘制这两种算法的ROC曲线:

结果表明,Logistic回归ROC曲线的AUC明显高于KNN-ROC曲线。因此,我们可以说logistic回归在分类数据集中的正类方面做得更好。
用于多类分类的AUC-ROC
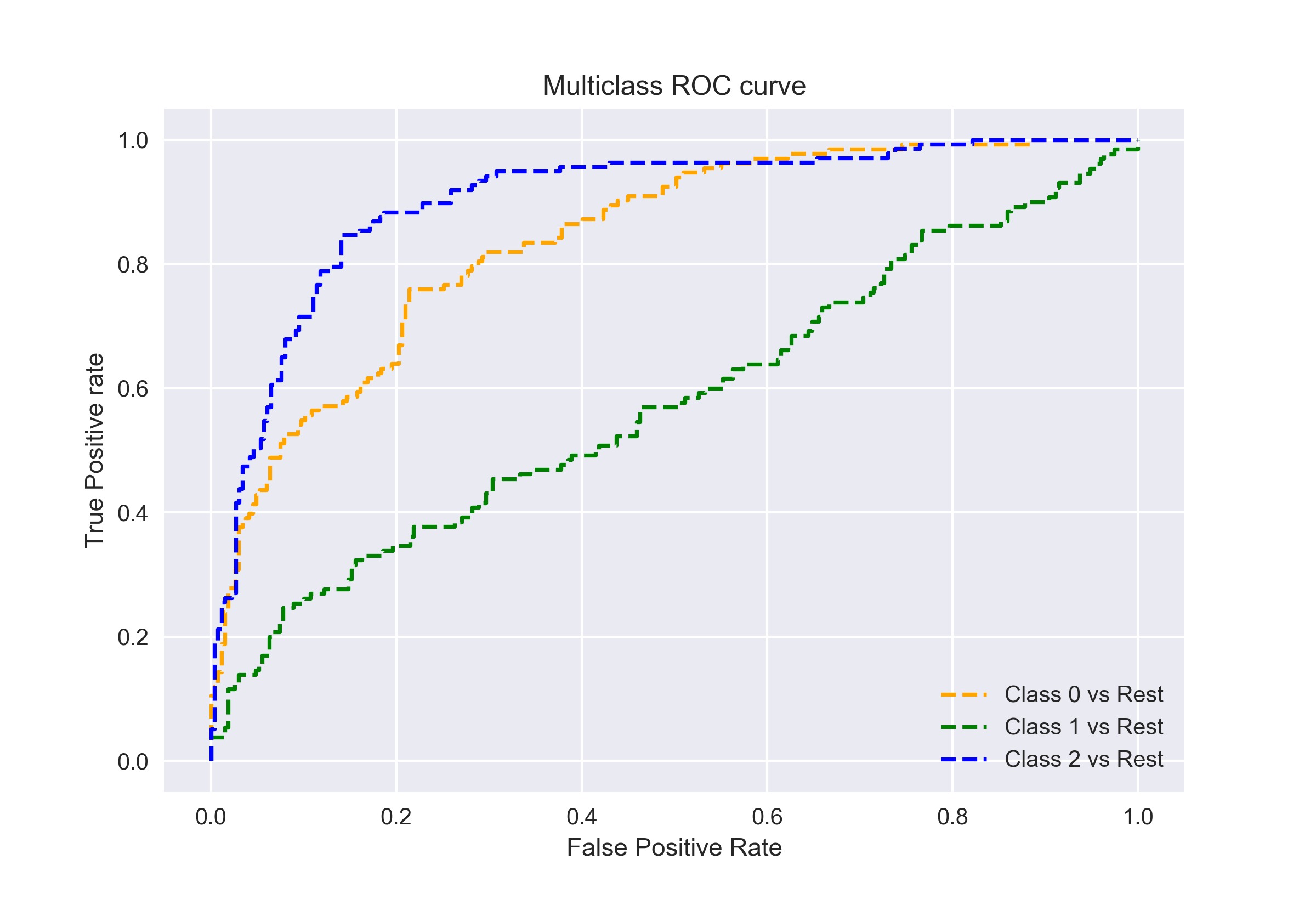
就像我之前说过的,AUC-ROC曲线只适用于二元分类问题。但是,我们可以通过一对多技术将其扩展到多类分类问题。
因此,如果我们有三个类0、1和2,那么class 0的ROC将如此生成,正例为类0,反例为非类0,也就是类1和类2。以此类推。
多类分类模型的ROC曲线可以确定如下:
结尾
我希望你发现本文有助于理解AUC-ROC曲线度量在衡量分类器性能方面的强大功能。你会在工业界,甚至在数据科学经常用到这个。最好熟悉一下!
原文链接:https://www.analyticsvidhya.com/blog/2020/06/auc-roc-curve-machine-learning/
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号