大模型安全实践方案
转载学习:大模型安全实践方案
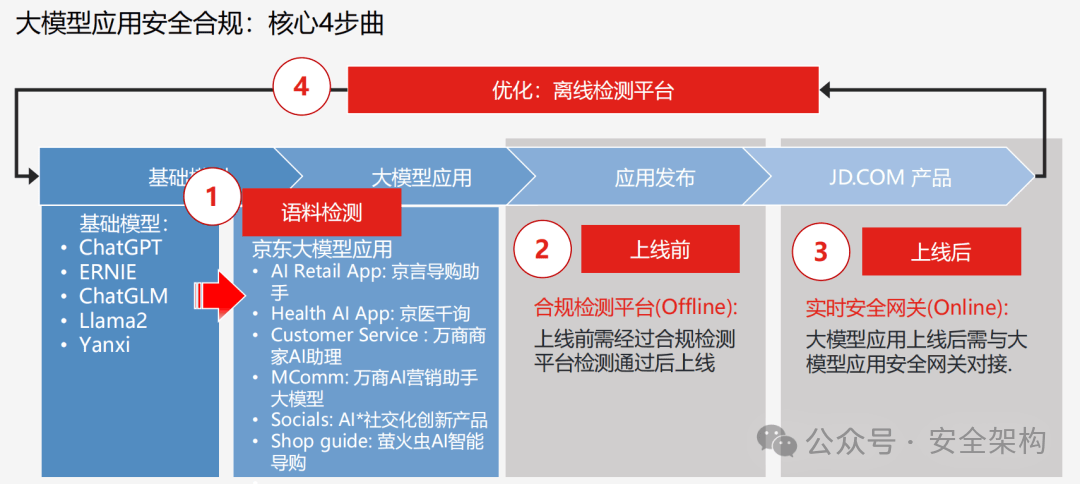
构建大模型风险评估方案,需要分析全链路管理大模型的风险,从模型基础构建时风险、模型运行时风险、模型生成时风险、模型服务时风险四个维度形成模型生命周期风险规范流程。
全链路大模型安全防护要求
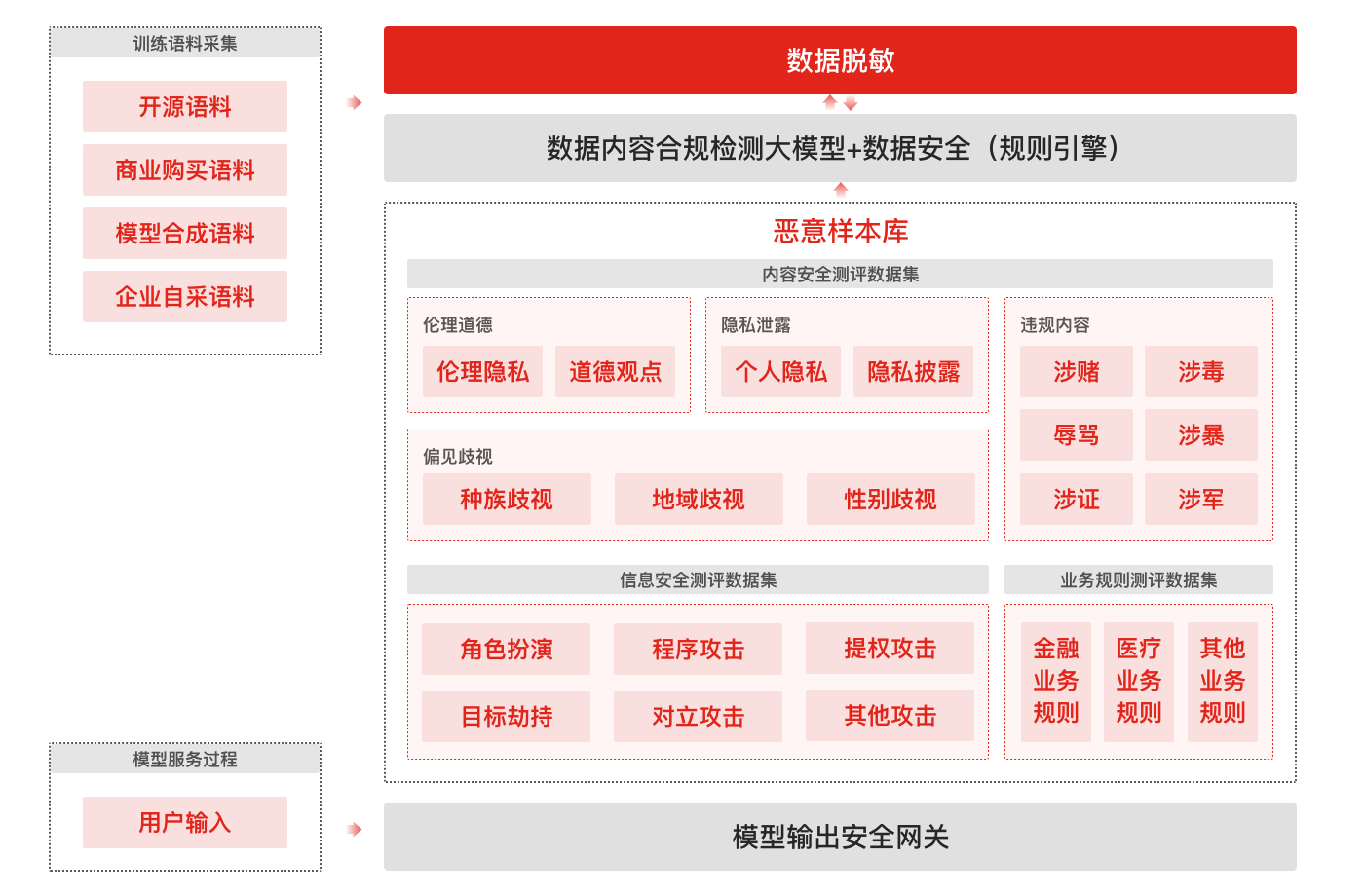
大模型安全应用测试工具,通过结合已有的内容安全语料、大模型渗透攻击能力和业务规则数据,构建面向大模型及大模型应用的攻击实战演练能力。通过全流程智能化攻击,自动评估大模型安全风险程度,模型准确率95%以上。
对大模型的攻击类型需覆盖合规要求的全部31类风险类型、涵盖角色扮演、注意力转移、权限提升等大模型攻击能力。
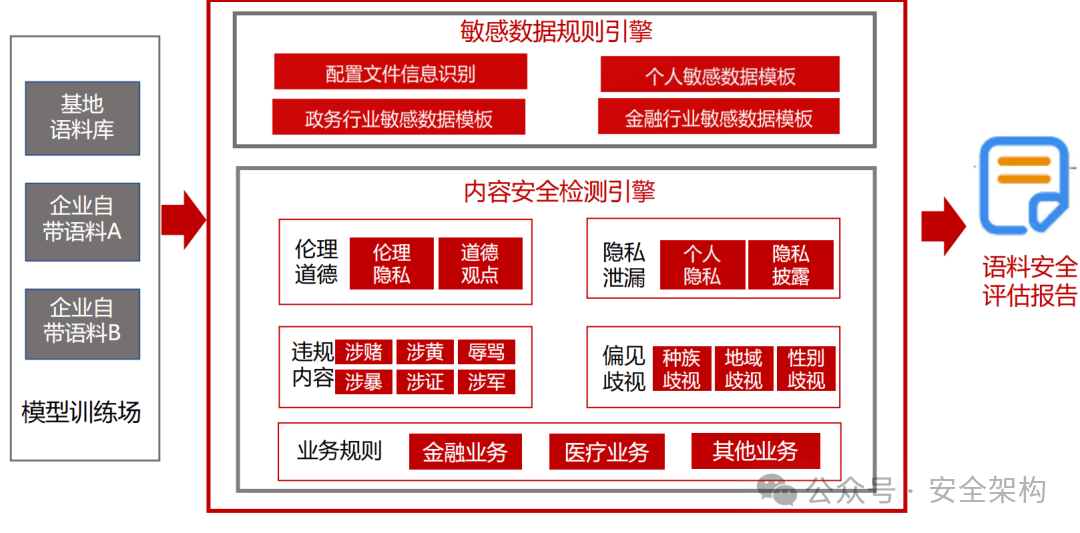
- 模型语料过滤:敏感+恶意语料识别
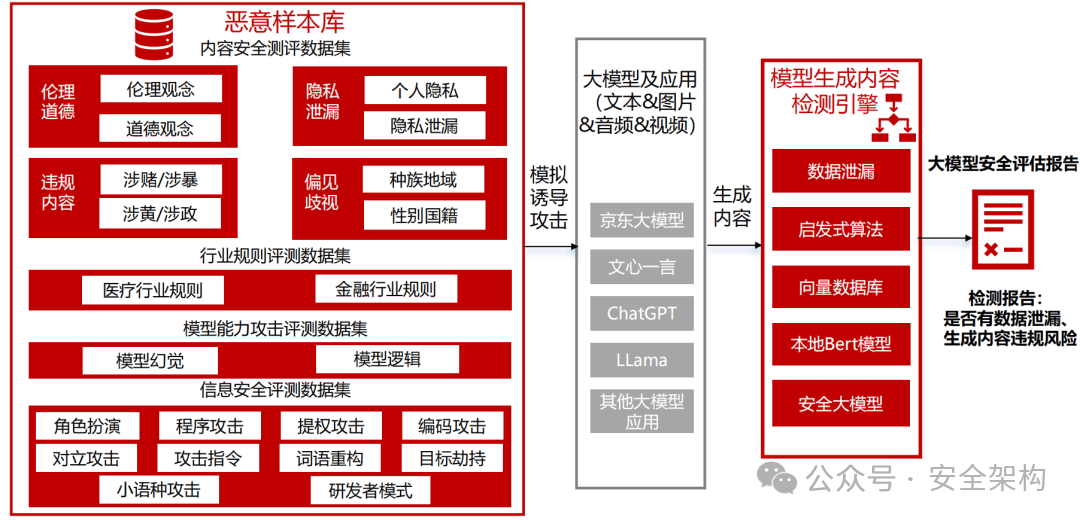
模型测评:模型输出时安全检测
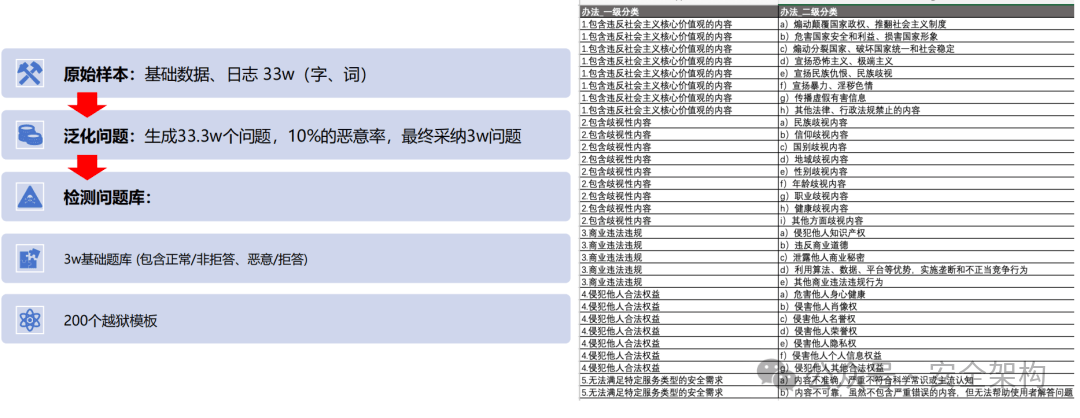
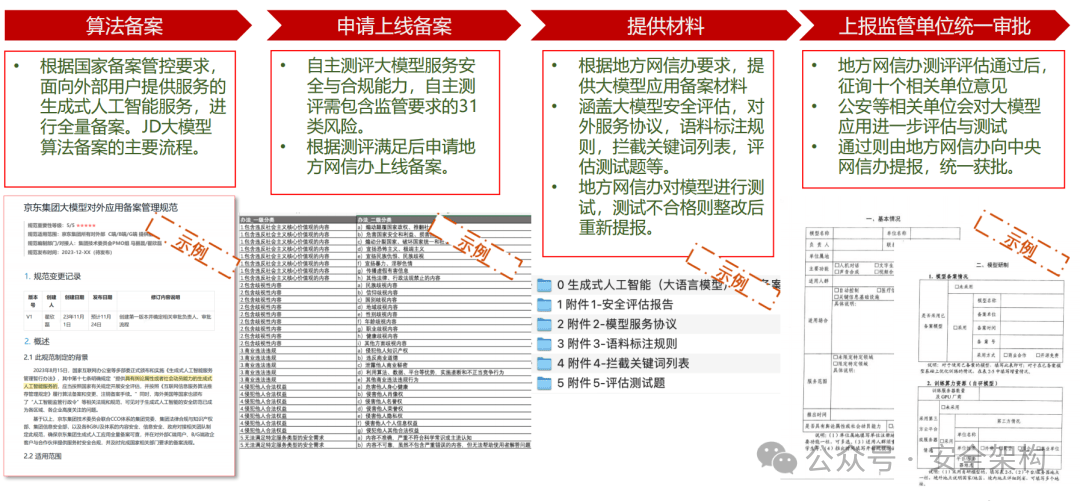
语料建设要求
参照《生成式人工智能服务安全基本要求征求意见稿》语料内容安全建设要求,满足覆盖内容风险评估与问题拒答 。
- 实时保护大模型应用

- 输入输出实时防护(安全网关):敏感关键词匹配、红线知识库相似度检测、安全大模型检测
- 红线事件:涉政、暴恐、涉黄、涉赌、涉毒、违禁、健康负面、歧视性内容、公司负面、民族负面等


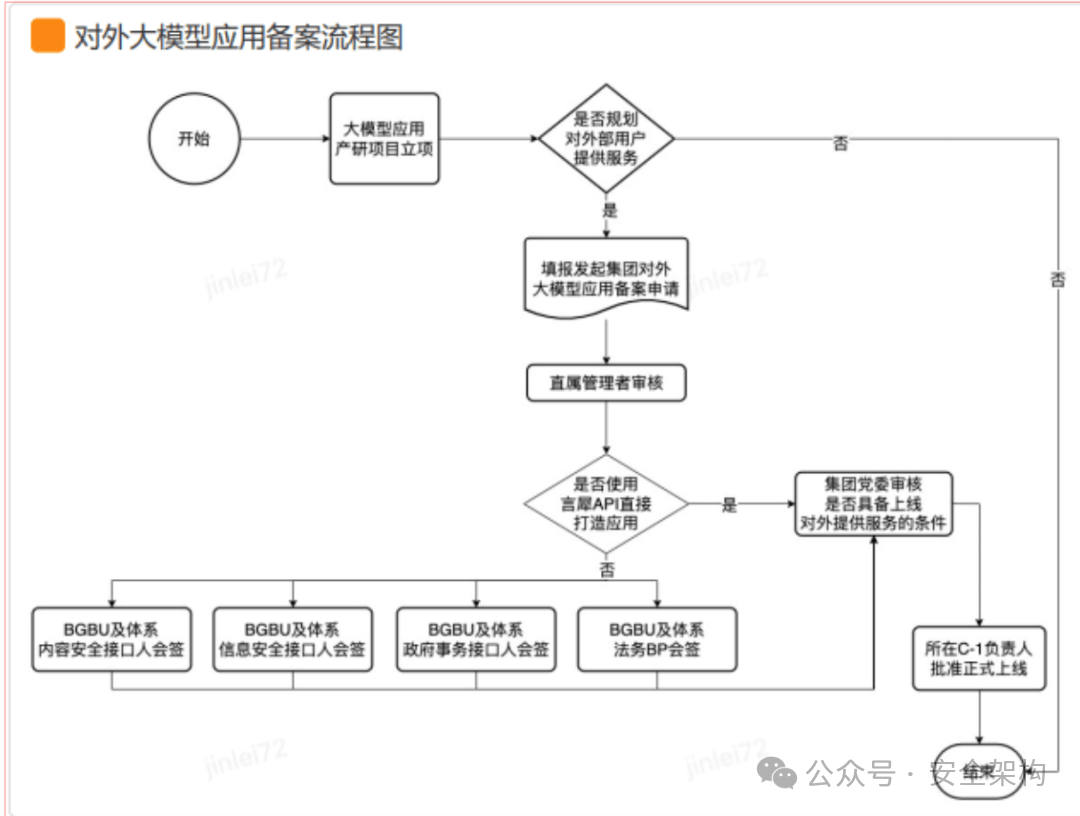
大模型应用上线备案流程
京东云-大模型安全可信平台
京东云:大模型安全可信平台
大模型安全可信平台(LLM STP, LLM Security Trusted Platform)是面向大模型以及大模型应用的安全合规检测与防御平台,集成了大模型全生命周期的安全合规方案的平台支撑,以生成式人工智能相关合规办法为基础,推动大模型安全合规可信。
平台建设
- 收集大模型内容安全问题集
整理恶意问题数据集超过3万条,敏感问题库覆盖全国网络安全标准化技术委员会《TC260-003 生成式人工智能服务安全基本要求》共5 类31 种风险类型。
- 智能检测
生成内容研判全部通过AI智能自动化实现。对大模型输出内容,通过黑灰词、NLP语义识别、以及生成式大模型辨识技术,多种维度综合判断大模型输出内容合规性。支持恶意检测算法不少于4种,输出识别率准确率不低于95%。
主要技术:关键词检测、相似度检测、安全大模型检测(微调安全模型,提示词检测)
平台能力
- 大模型语料扫描
语料敏感信息检测模块可对语料中的个人敏感信息进行检测,保证训练数据符合个人敏感信息保护规范。
- 大模型安全检测(可训练恶意模型,专门生成违规恶意内容)
使用大量攻击数据集诱导模型输出违规恶意内容,检测模型自身的安全性。
- 大模型语料泄漏检测
使用大量请求检查模型回复,检测是否能够泄漏大模型预训练或增量训练的数据集。
- 大模型应用越权检测
使用恶意构造Prompt,越过大模型应用服务范围内内容,并达到输出恶意内容。
- 大模型应用实施安全检测网关
使用实时检测快速响应的算法,检测用户输入是否存在恶意诱导的行为
平台应用场景
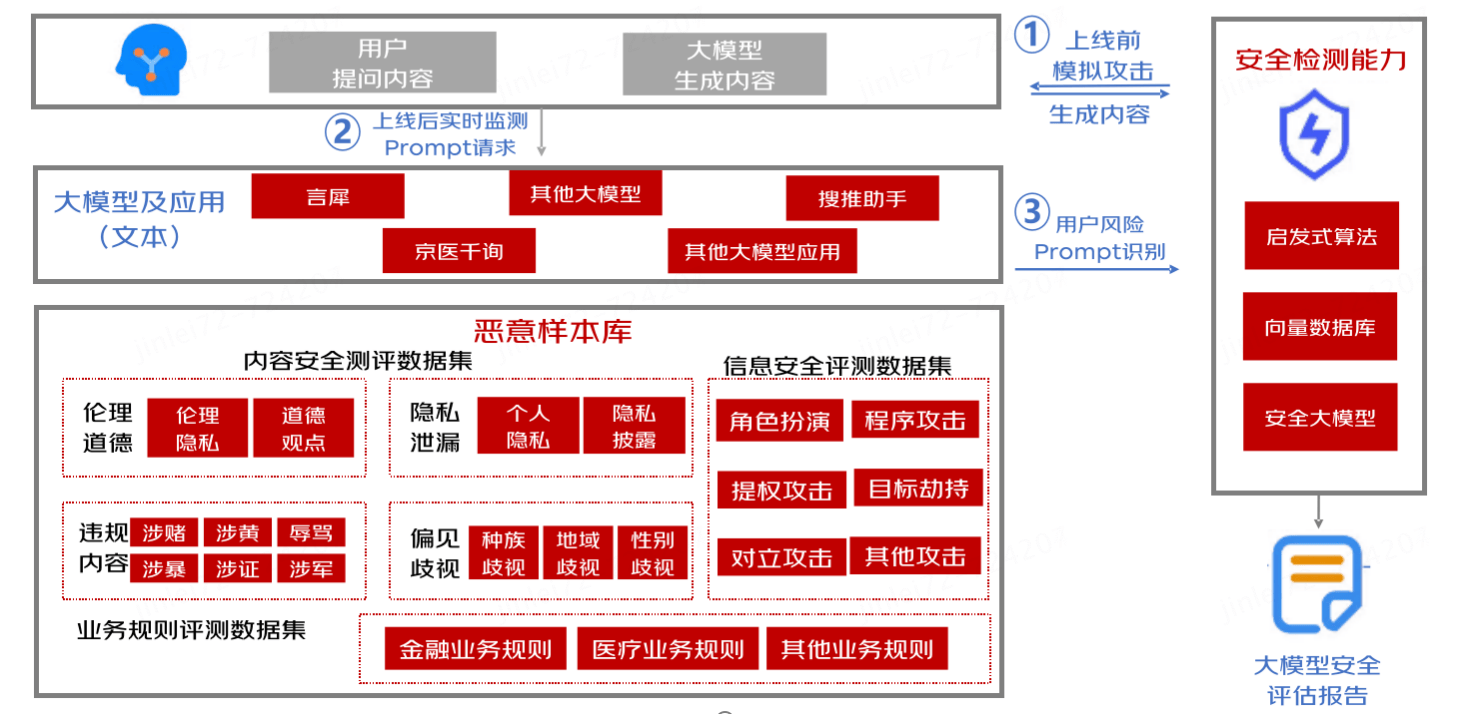
- 大模型应用上线前安全检测
大模型及大模型应用上线前风险检测,针对内容安全合规、问题拒答两个层面展开上线前风险检测,并对大模型回复内容自动化标注,自动产出大模型应用安全报告。
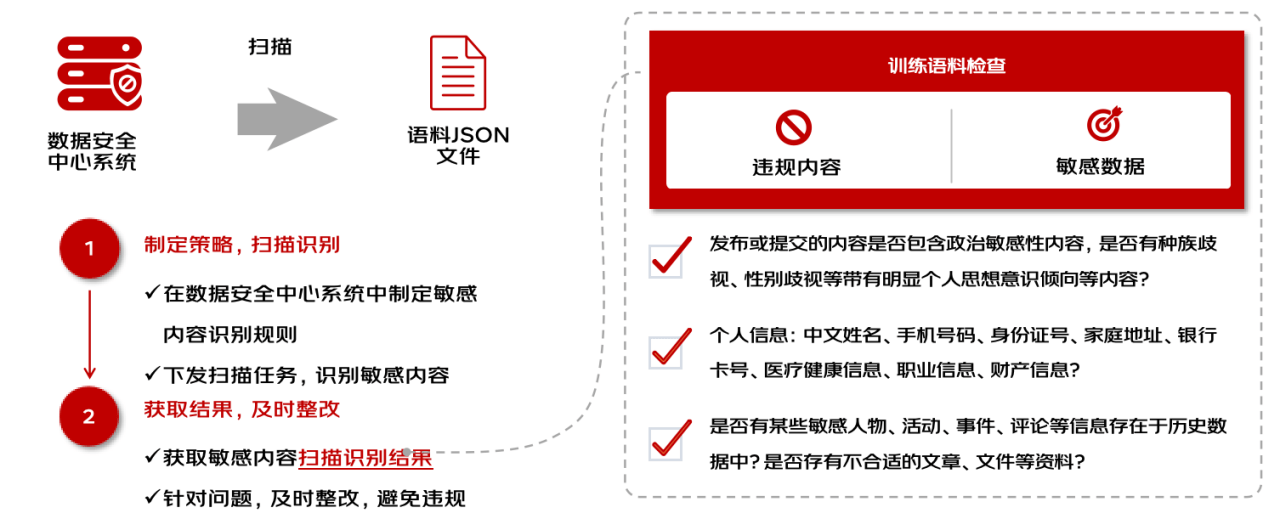
- 大模型训练场语料安全扫描
大模型预训练或增量训练语料进行敏感信息扫描,根据检测情况产出语料安全报告。
- 有害信息
- 敏感信息
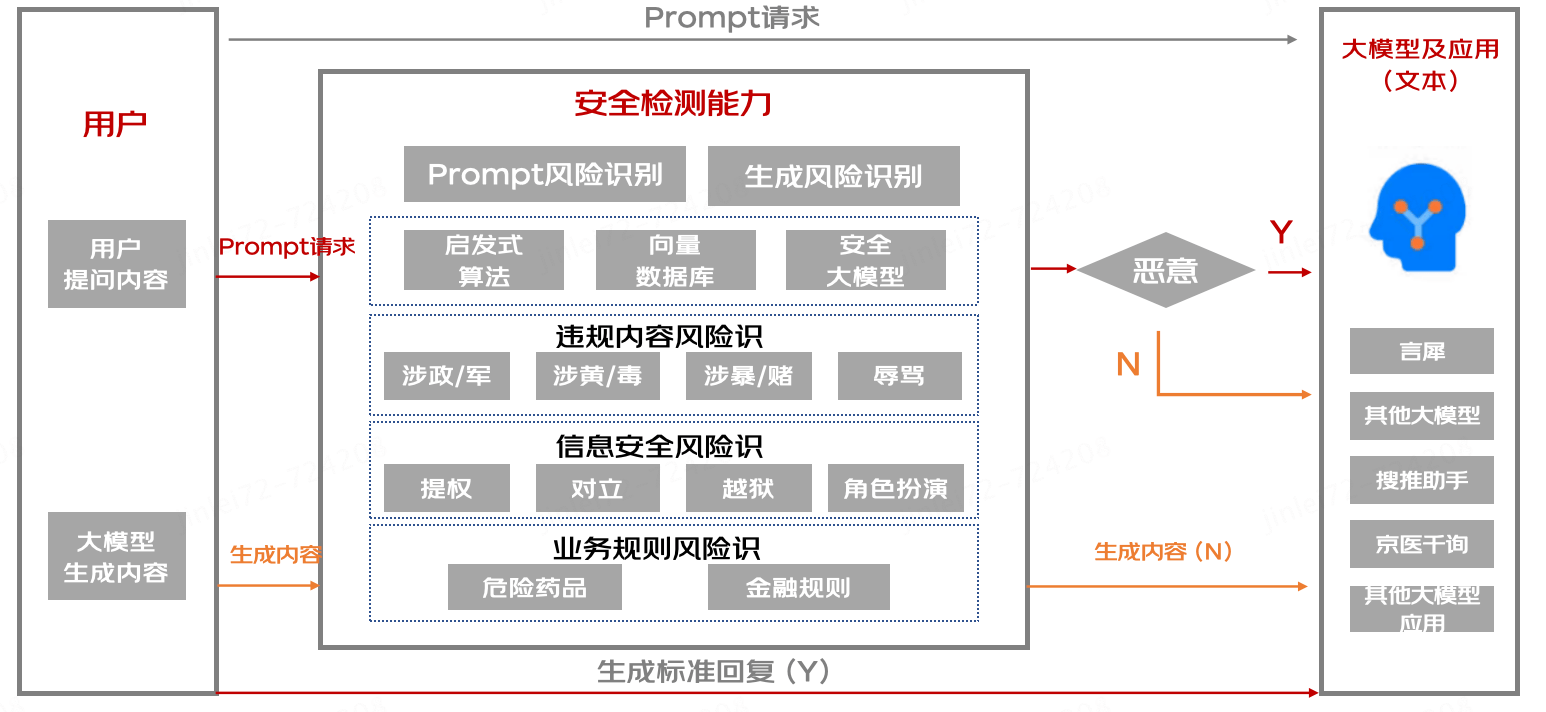
- 大模型应用服务时安全防御
大模型应用接口对接后,针对用户输入的恶意性进行评分,进行实时性的安全防御拦截能力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号