

汇编语言简易教程(3):编码表示
汇编语言简易教程(3):编码表示
'表示'指的是计算机如何在内存中表示/存储. 计算机使用二进制 ( 1/0 )进行存储, 但是由于空间的限制, 任何表示方式只能表达一定范围, 一定精度的数据.
本章简要总结了整数、浮点和 ASCII 表示方案。
假设读者已经普遍熟悉二进制、十进制和十六进制编号系统。
应该注意的是,如果没有指定,则数字以 10 为基数。
此外,前面带有 0x 的数字是十六进制值。例如,19 = 1910 = 1316 = 0x13
整数
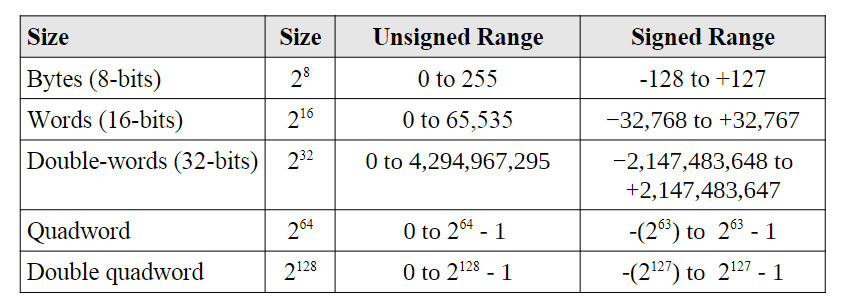
无符号整数
可以直接从0开始表示到(2N - 1)的范围
有符号整数
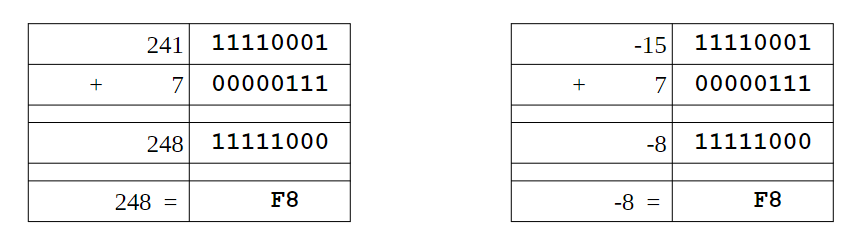
补码
仅针对负数
- 按位取反
- 得到的值 +1
package main import "unsafe" func int64ToUnit64(i int64) uint64 { return *(*uint64)(unsafe.Pointer(&i)) } func uint64ToInt64(u uint64) int64 { return *(*int64)(unsafe.Pointer(&u)) } func main() { for i := int64(-10); i < 10; i++ { // print bit representation of int64 // 64 bits // 1 bit for sign // 63 bits for value v := int64ToUnit64(i) s := "" for j := 63; j >= 0; j-- { if v&(1<<j) > 0 { s += "1" } else { s += "0" } } println(i, s) } }补码的设计使得加法和减法可以使用相同的电路进行计算,并且可以将符号位和其他位统一处理,简化了计算机内部的硬件设计。
表示区别
需要注意区别类型!!!
浮点数
IEEE 32-bit
计算公式
$N=(−1)S×1.F×2^{E−127}$
实际上是二级制的科学计数法.
转换过程
- 计算二级制表示
- 确定起止位, 确定小数点要移动几位
举例
- 确定符号位
- 将数字用二进制表示(注意小数部分只能拟合)
- 确定第一个1的位置
- 确定
F和E, 需要注意E要+ 127IEEE 64-bit
表达方式和IEEE 32-bit几乎一致, 但是有更好的精度和范围
NaN
not a number
当一个值被解释为浮点值并且不符合定义的标准(无论是 32 位还是 64 位)时,它就不能用作浮点值。
如果将整数表示形式视为浮点表示形式,或者浮点算术运算(加、减、乘或除)导致值太大或太小而无法表示,则可能会发生这种情况。
不正确的格式或无法表示的数字被称为 NaN,它是 not anumber 的缩写。
字符以及字符串
字符表示
在计算机中,字符是对应于符号(例如字母表中的字母)的信息单元。
字符的示例包括字母、数字、常见标点符号(例如“.”或“!”)和空格。
一般概念还包括控制字符,它们并不对应于特定语言中的符号,而是对应于用于处理文本的其他信息。控制字符的示例包括回车符或制表符
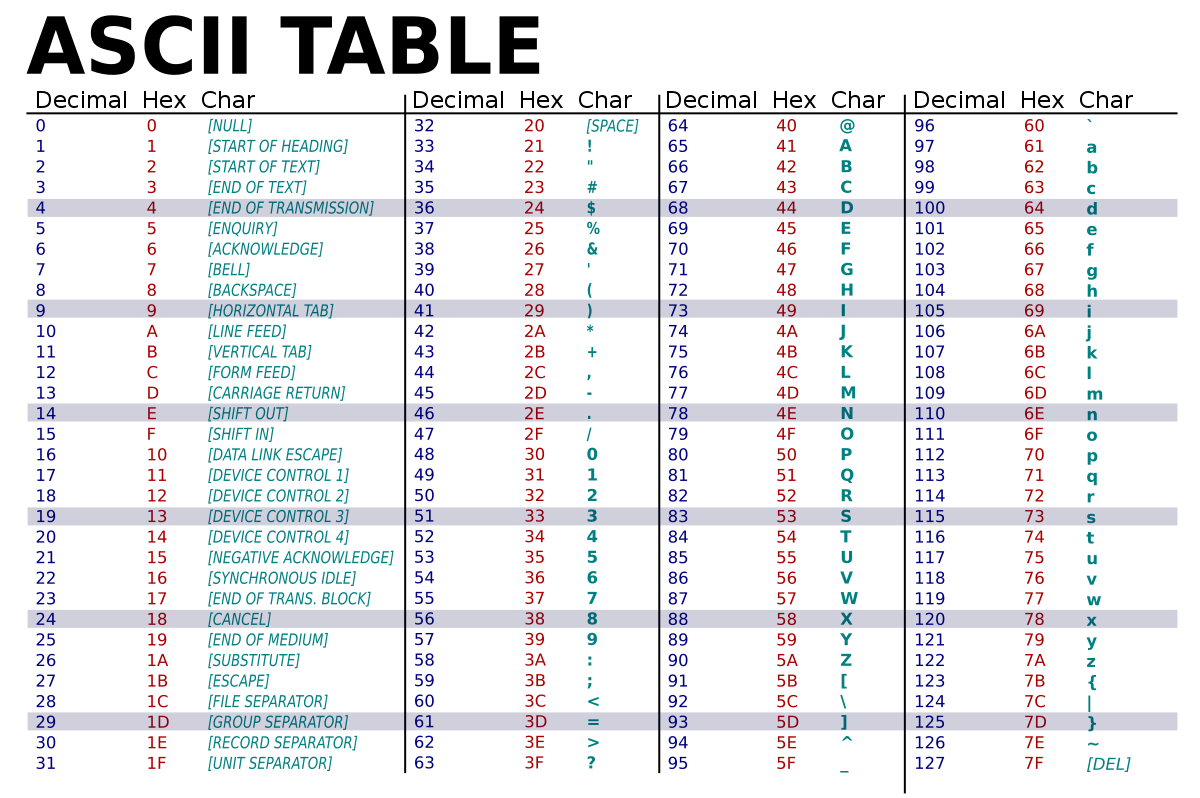
ASCII (American Standard Code for InformationInterchange)
Unicode
应该注意的是,Unicode 是当前标准,包括对不同语言的支持。
Unicode 标准提供了一系列不同的编码方案(UTF-8、UTF-16、UTF-32 等),以便为每个字符提供唯一的编号,无论什么平台、设备、应用程序或语言。
在最常见的编码方案 UTF-8 中,ASCII 英文文本在 UTF-8 中看起来与在 ASCII 中完全相同。 根据需要,其他字符将使用其他字节
UTF-8编码格式
UTF-8使用一到四个字节为每个字符编码,编码长度取决于字符的Unicode码点:
- 1字节:用于表示标准ASCII字符,范围从
0x00到0x7F。这意味着ASCII文本也是合法的UTF-8文本。- 2字节:用于表示拉丁字母补充、希腊字母、西里尔字母、亚美尼亚字母、希伯来字母、阿拉伯字母等字符。
- 3字节:用于表示基本多文种平面(BMP)内的字符,这包括了大多数常用的字符。
- 4字节:用于表示那些辅助平面的字符,包括一些较少用的符号和表情符号。
UTF-8编码的具体规则
- 对于单字节的字符,第一个字节以
0开头,后面7位代表字符(与ASCII码相同)。- 对于多字节的字符,第一个字节以连续的
n个1开头,后面跟一个0,表示这个字符占用n字节。随后的字节都以10开头。剩余的位用于编码字符。举例
- ASCII字符
A(码点0x41)的UTF-8编码是0100 0001。- 欧元符号
€(码点0x20AC)的UTF-8编码是1110 0010 1000 0010 1010 1100(3字节)。- 某些表情符号,如,其码点可能超过
0xFFFF,因此需要4字节来编码。字符串
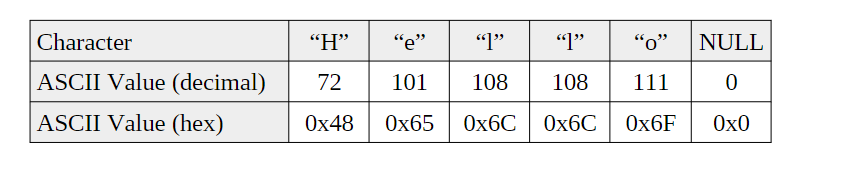
string是一系列 ASCII 字符,通常以 NULL 结尾。 NULL 是不可打印的 ASCII 控制字符。 由于它不可打印,因此可以用来标记字符串的末尾
通常来说字符串就是连续的字符表示.






 浙公网安备 33010602011771号
浙公网安备 33010602011771号