

atomic.LoadInt64
atomic.LoadInt64
源码
在经历了之前查看AddInt64的经历后, 我们可以确定LoadInt64的代码位置
TEXT runtime∕internal∕atomic·Loadint64(SB), NOSPLIT, $0-16
JMP runtime∕internal∕atomic·Load64(SB)
我们看到, 其实是直接调用runtime∕internal∕atomic·Load64这个函数, 我们再去看看它的实现吧.
TEXT sync∕atomic·LoadInt64(SB), NOSPLIT|NOFRAME, $0-16
GO_ARGS
MOVQ $__tsan_go_atomic64_load(SB), AX
CALL racecallatomic<>(SB)
RET
这里的实现还是非常简单的, 将__tsan_go_atomic64_load移动至AX寄存器, 调用该函数, 并返回.
这里的__tsan_go_atomic64_load还是对我们隐藏了细节, 我们还是编译后来看看源码吧
汇编分析
源码
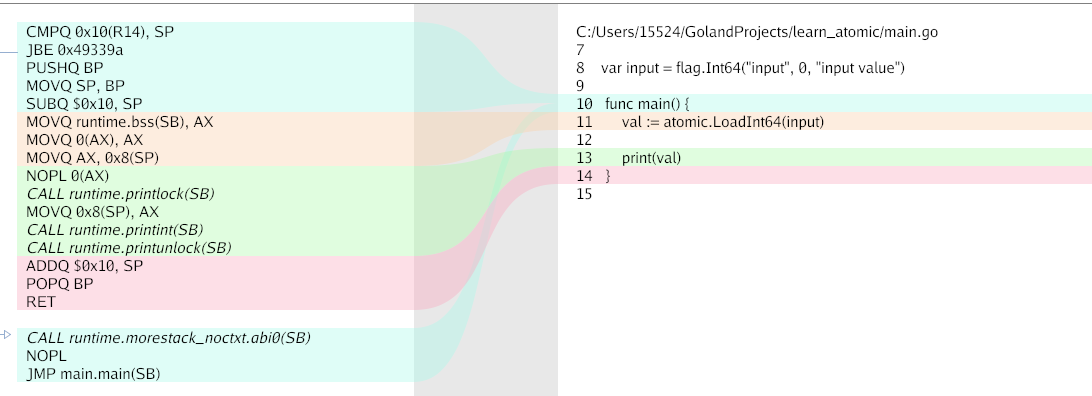
分析
黄色部分是
LoadInt64的实际代码
- 将地址移动到
AX寄存器中 - 解引用
(AX) -> AX, 需要注意的是: 在汇编语言中 如果在寄存器或者地址外有一个(), 意味着这是间接寻址模式 (MOVQ (%RCX), %RDX) - 将
AX寄存器中的值直接返回+8(SP), 即返回值
思考

分析刚刚的源码我们可以知道, LoadInt64做的事情, 实际上就是寻址.
那么我们当然也可以通过go的语法来实现取址 再 寻址
两者是没有什么区别的
这也揭示了一件事情: 在当前的计算机体系下, 并发更多的是由于写引起的, 读在大多数情况下是不存在并发冲突的.
注意
为什么直接取值就可以了?
原因很很简单, 只需要获取当前的最新值就可以了, 在Store和Add时, 都保证了一定会保证原子性.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号