sklearn之转换器和估计器
sklearn之转换器和估计器
转换器
想一下之前做的特征工程的步骤?
- 实例化(实例化的是一个转换器类(Transformer)——特征工程的父类)
- 调用
fit_transform(对于文档建立分类词频矩阵,不能同时调用)
我们把特征工程的接口称之为转换器,其中转换器调用有这么几种形式(以标准化为例进行说明)
- fit_transform
- fit —— 计算 每一列的平均值、标准差
- transform —— 公式的带入进行最终转换
估计器(sklearn机器学习算法的实现)
在sklearn中,估计器(estimator)是一个重要的角色,是一类实现了算法的API
- 用于分类的估计器:
sklearn.neighborsk-近邻算法sklearn.nalve_bayes贝叶斯slearn.linear_model.LogisticRegression逻辑回归sklearn.tree决策树与随机森林
- 用于回归的估计器:
sklearn.linear_model.LinearRegression线性回归sklearn.linear_model.Ridge岭回归
- 用于无监督学习的估计器
sklearn.cluster.KMeans聚类
估计器工作流程
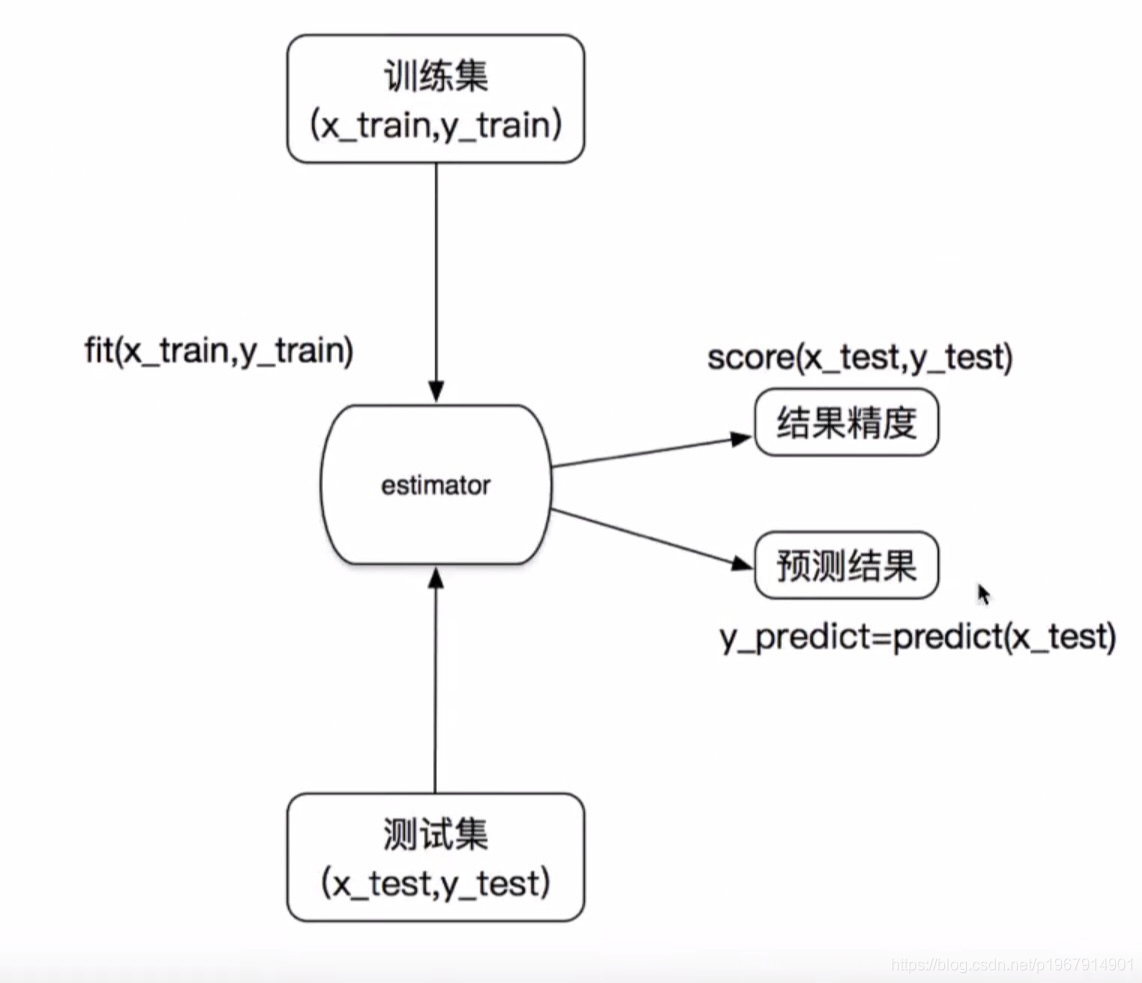
- 实例化一个
estimator estimator,fit(x_train,y_train)计算- 调用完毕,模型生成
- 模型评估:
- 直接比对真实值和预测值
y_predict= estimator.predict(x_test)y_test== y_predict
- 计算准确率
accuracy = estimator.score(x_test, y_test)
- 直接比对真实值和预测值

 浙公网安备 33010602011771号
浙公网安备 33010602011771号