决策树
认识决策树
决策树思想的来源非常朴素,程序设计中的条件分支结构就是if-else结构,最早的决策树就是利用这类结构分割数据的一种分类学习方法
怎么理解这句话?通过一个对话例子
比如:你母亲要给你介绍男朋友,是这么来对话的:
- 女儿:多大年纪了?
- 母亲:26。
- 女儿:长的帅不帅?
- 母亲:挺帅的。
- 女儿:收入高不?
- 母亲:不算很高,中等情况。
- 女儿:是公务员不?
- 母亲:是,在税务局上班呢。
- 女儿:那好,我去见见。
想一想这个女生为什么把年龄放在最上面判断!!!!!!!!!!!!!!
**决策树的思想:**如何高效的进行决策?——特征的先后顺序
那么如何确定特效的先后顺序呢?
决策树分类原理详解
原理
信息煽、信息增益等
需要用到信息论的知识!!!
信息论基础
- 信息
- 消除随机不确定性的的东西
- 例如:小明的年龄
- ”我今年18岁“ —— 信息
- ”我明年19岁“ —— 不是信息
- 信息的衡量 —— 信息量 —— 信息熵
信息適的定义
- H的专业术语称之为信息炯,单位为比特(bit)。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-asCysUwX-1608431730837)(C:\Users\ASUS\AppData\Roaming\Typora\typora-user-images\image-20201219232312280.png)]
决策树的划分依据之— —— 信息增益
- 定义与公式
特征A对训练数据集D的信息增益g(D,A),定义为集合D的信息煽H(D)与特征A给定条件下D的信息条件煽H(D|A)之差
公式为:g(D,A) = H(D) - H(D|A)
信息熵计算:
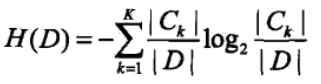
条件熵的计算:
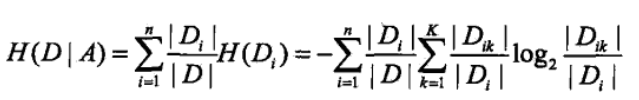
注:
- Ck 表示某个样本类别的样本数
- 信息增益表示得知特征X的信息而息的不确定性减少的程度使得类Y的信息熵减少程度
当然决策树的原理不止信息增益这一种,还有其他方法。但是原理都类似,我们就不去举例计算。
- ID3
- 信息增益 最大的准则
- C4.5
- 信息增益比 最大的准则
- CART
- 分类树:基尼系数 最小的准则在
sklearn中可以选择划分的默认原则 - 优势:划分更加细致(从后面例子的树显示来理解)
决策树API
class sklearn.tree.DecisionTreeClassifier(criterion='gini', max_depth=None,random_state=None)- 决策树分类器
criterion:决策树的划分依据,默认是gini系数,也可以选择信息增益的熵entropy。max_depth:树的深度大小,不设置的话数据量过大,使得决策树划分太细,泛化能力差,可能训练数据效果好,测试数据就不好了random_state:随机数种子
决策树预测鸢尾花数据集
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
if __name__ == '__main__':
# 获取数据
iris = load_iris()
# 划分数据集
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=4)
# 决策树 算法预估器
estimator = DecisionTreeClassifier(criterion='entropy')
estimator.fit(x_train, y_train)
# 模型评估
# 方法一:直接对比真实值和预测值
y_predict = estimator.predict(x_test)
print('y_predict:\n', y_predict)
print('直接对比真实值和预测值:\n', y_test == y_predict)
# 方法二:计算准确率
score = estimator.score(x_test, y_test)
print('准确率:\n', score)
决策树可视化
保存树的结构到dot文件
sklearn.tree.export_graphviz()该函数能够导出DOT格式tree.export_graphviz(estimator,out_file='tree.dot',feature_names=[])
dot 文件当中内容如下:
digraph Tree {
node [shape=box] ;
0 [label="petal width (cm) <= 0.8\nentropy = 1.576\nsamples = 112\nvalue = [32, 42, 38]"] ;
1 [label="entropy = 0.0\nsamples = 32\nvalue = [32, 0, 0]"] ;
0 -> 1 [labeldistance=2.5, labelangle=45, headlabel="True"] ;
2 [label="petal width (cm) <= 1.75\nentropy = 0.998\nsamples = 80\nvalue = [0, 42, 38]"] ;
0 -> 2 [labeldistance=2.5, labelangle=-45, headlabel="False"] ;
3 [label="petal length (cm) <= 4.95\nentropy = 0.433\nsamples = 45\nvalue = [0, 41, 4]"] ;
2 -> 3 ;
4 [label="petal width (cm) <= 1.65\nentropy = 0.165\nsamples = 41\nvalue = [0, 40, 1]"] ;
3 -> 4 ;
5 [label="entropy = 0.0\nsamples = 40\nvalue = [0, 40, 0]"] ;
4 -> 5 ;
6 [label="entropy = 0.0\nsamples = 1\nvalue = [0, 0, 1]"] ;
4 -> 6 ;
7 [label="petal width (cm) <= 1.65\nentropy = 0.811\nsamples = 4\nvalue = [0, 1, 3]"] ;
3 -> 7 ;
8 [label="entropy = 0.0\nsamples = 3\nvalue = [0, 0, 3]"] ;
7 -> 8 ;
9 [label="entropy = 0.0\nsamples = 1\nvalue = [0, 1, 0]"] ;
7 -> 9 ;
10 [label="petal length (cm) <= 4.85\nentropy = 0.187\nsamples = 35\nvalue = [0, 1, 34]"] ;
2 -> 10 ;
11 [label="sepal length (cm) <= 5.95\nentropy = 0.918\nsamples = 3\nvalue = [0, 1, 2]"] ;
10 -> 11 ;
12 [label="entropy = 0.0\nsamples = 1\nvalue = [0, 1, 0]"] ;
11 -> 12 ;
13 [label="entropy = 0.0\nsamples = 2\nvalue = [0, 0, 2]"] ;
11 -> 13 ;
14 [label="entropy = 0.0\nsamples = 32\nvalue = [0, 0, 32]"] ;
10 -> 14 ;
}
网站显示结构
http://webgraphviz.com/
决策树总结
- 优点:
- 简单的理解和解释,树木可视化。
- 缺点:
- 决策树学习者可以创建不能很好地推广数据的过于复杂的树,这被称为过拟合
- 改进:
- 减枝
cart算法(决策树API当中已经实现,随机森林参数调优有相关介绍)。 - 随机森林
- 减枝
注:企业重要决策,由于决策树很好的分析能力,在决策过程应用较多, 可以选择特征

 浙公网安备 33010602011771号
浙公网安备 33010602011771号