python实现单词的简单爬取
因为不需要登录之类的操作,可以说,这是对爬虫初学者来说最简单最基础的一个案例了,由于之后要用到这里就简单学习记录一下。
确定URL
爬取目标:金山词霸的四六级词汇
http://word.iciba.com/
我们可以很容易看到四个选项,六级就不列出来了。

- http://word.iciba.com/?action=courses&classid=11
- http://word.iciba.com/?action=courses&classid=122
- http://word.iciba.com/?action=courses&classid=12
- http://word.iciba.com/?action=courses&classid=123
网址很容易拿到,且规律这么明显,所以说很容易。
我们每次爬取单词的时候仅需对这四个词库随机选取即可。
我们选择四级必备词汇词库第一课点进去之后我们发现后面的url会加上一个参数,参数值为课的节数。这样我们根据这个规律来完成拼接一种词库界面的一节课的url。我们根据class以及其course的最大值来随机构造url。
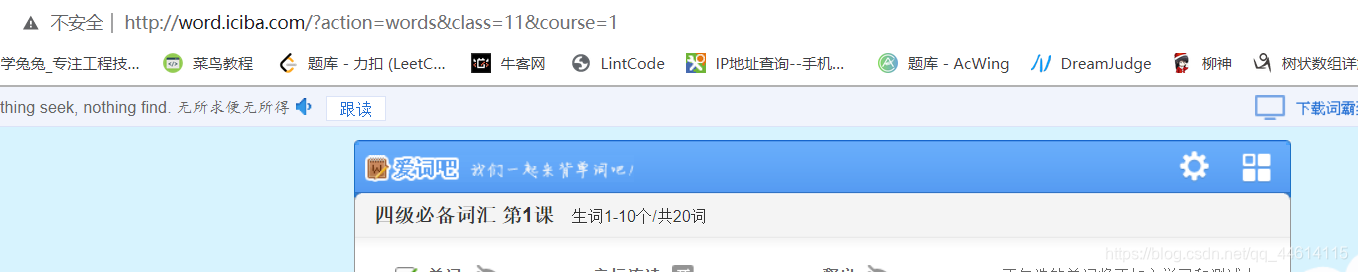
choice = random.choice([(11, 226), (12, 105), (122, 35), (123, 25)])
url = "http://word.iciba.com/?action=words&class=" + str(choice[0]) + "&course=" + str(random.randint(1, choice[1]))
找到单词标签位置
我们找到单词所在的标签,确定每个单词所在的标签
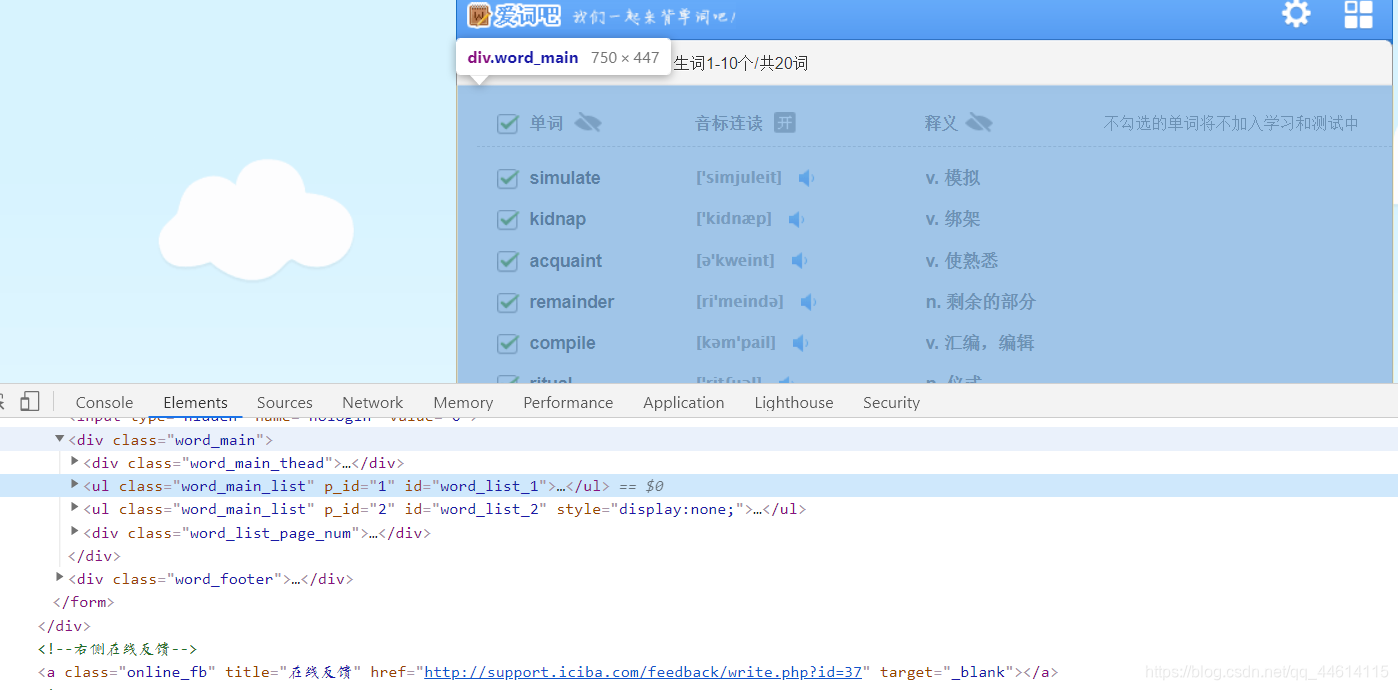
这里我们可以只用xpath来获取,可以使用xpath helper插件(chrome)。我们右击元素选择copy ,copy xpath,这样我们就获取了这个元素的xpath位置
//*[@id=“word_list_1”]/li[2]/div[1]
我们可以通过改变标签的下标来改变不同的单词。获取里面的文字后面需要加上text()

这里我们就获得了第一个单词

如果我们把xpath里面的下标去掉会发生什么呢
div下标去掉

li下标也去掉
显示有二十个结果,那肯定是是个单词和释义啦!

但是我们发现,每一课其实是有分页的,即两个list,上面语法只能获得10个单词,我们需要改变一下语法才行。
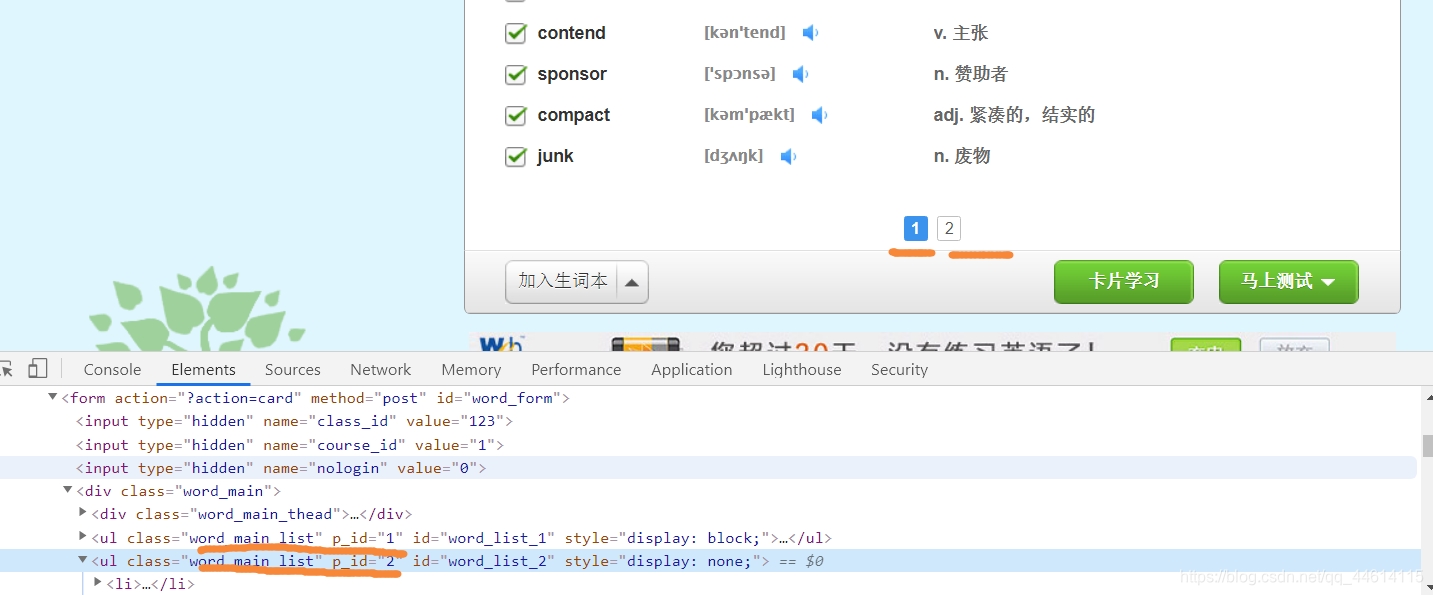
我们发现两组单词都有一个共同的class word_main_list 我们从这里入手,最终得到获得所有单词的xpath语法,这里需要一点xpath语法基础。
获取英语单词
//*[@class=“word_main_list”]/li/div[@class=“word_main_list_w”]/span//text()
获取单词释义
//*[@class=“word_main_list”]/li/div[@class=“word_main_list_s”]/span//text()
爬取加处理
接下来的任务就很简单了,直接给出代码
from lxml import etree
import requests
import random
words = []
meaning = []
choice = random.choice([(11, 226), (12, 105), (122, 35), (123, 25)])
url = "http://word.iciba.com/?action=words&class=" + str(choice[0]) + "&course=" + str(
random.randint(1, choice[1]))
r = requests.get(url)
r.encoding = r.apparent_encoding
if r.status_code == 200:
text = r.text
doc = etree.HTML(text)
words = doc.xpath('//*[@class="word_main_list"]/li/div[@class="word_main_list_w"]/span//text()')
meaning = doc.xpath('//*[@class="word_main_list"]/li/div[@class="word_main_list_s"]/span//text()')
li = []
for i in range(len(words)):
dic = {'words': words[i], 'meaning': meaning[i]}
li.append(dic)
print(li)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号