Git使用心得体会
在上高软课之前,我的git水平一直都停留在add,commit以及push这些基础操作上,也没有进行过一个系统的学习。
万幸上了孟宁老师的高软课,让我对git的认识又进了一步,也解决了一直困扰我的难题。
本博客基于孟宁老师的文章进行编写:https://mp.weixin.qq.com/s/Km5KuXPETvG0wCGHrvj9Vg 。
场景一:Git 本地版本库的基本用法
在刚接触到git的时候我就有这样一个疑问了,就是在我进行commit操作的时候,git是如何存储数据的呢。我之前认为git就是存储文件每一个版本完整的内容罢了。但是上了高软课,我又认为保存的是文件差异。上网搜索了一下,比较一致的说法是:git保存的是文件快照,至于快照是个什么东西,我看了网上的一些说法还是觉得很蒙。所以为了满足我的好奇心,我特地在进行场景一操作时观察了一下.git文件夹的变化。
首先在一个空文件夹下初始化一个本地版本库:

init成功后,我的demo文件夹下多出了一个.git文件夹,我重点关注的是.git 下面的objects文件夹,因为这个文件夹下是存储对象的。目前objects文件夹下有两个空的文件夹,分别是info和pack.
接下来在工作区下创建一个hello.txt,随便写点东西,使用git add命令将它保存到暂存区。

看一下objects 文件夹,在里面多了一个名叫7c的文件夹,info和pack文件夹还是空的。7c文件夹里面有一个以38位字符为名的文件。这题我会,因为所有用来表示项目历史信息的文件,都是是通过一个40个字符的“对象名”来索引的 ,这个“对象名”是对“对象”内容做SHA1哈希计算得来的 。
show一下这个对象:

既然是对内容做哈希,那么我再创建一个不同的文件(内容相同,文件名不同)再执行git add命令会怎样呢。
做完这一系列的操作后,我惊奇地发现,objects文件夹下面什么都没有添加!!!好的,我悟了,git跟踪的是内容,而不是文件。
接着进行commit操作:

这个时候object下 又创建了两个文件夹,这波我能猜到,绝对是创建了一个tree和一个commit对象。
显示tree对象的信息,它存了一个blob文件。

显示commit对象信息,它包含了刚才那个tree对象以及一些其他信息。
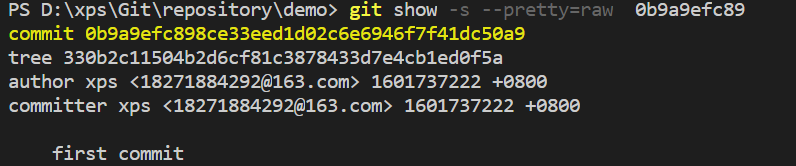
为了验证git存的是差异还是文件整个内容,我又做了如下操作:
对hello.txt 做了两次修改及add,object文件夹又多了两个文件。
进行一次commit,查看这个commit对象。
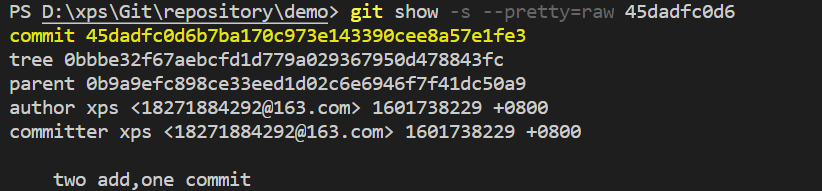
这个commit对象比上次多了一个parent, 指向的正是上一次commit的commit对象。这就可以解释为什么git可以快速回退到文件上一版本了。
显示一下commit对象中的tree对象信息

show一下blob 8cc5896:

这个时候问题出现了,blob存的是当前文件版本的全部内容啊,那我期待的文件差异到底在哪里体现呢。
翻了一下git community book,其中有这样一段话:
Git 往磁盘保存对象有两种格式:默认使用的格式叫松散对象 (loose object) 格式。
松散对象是一种比较简单格式. 它就是磁盘上的一个存储压缩数据的文件. 每一个对象都被写入一个单独文件中。
另外一种对象存储方式是使用打包文件(packfile). 由于Git把每个文件的每个版本都作为一个单独的对象, 它的效率可能会十分的低. 设想一下在一个数千行的文件中改动一行, Git会把修改后的文件整个存储下来, 很浪费空间.
Git使用打包文件(packfile)去节省空间. 在这个格式中, Git只会保存第二个文件中改变了的部分, 然后用一个指针指向相似的那个文件(译注: 即第一个文件).
Git会为每一个打包文件创建一个较小的索引文件. 索引文件中包含了对象在打包文件中的偏移, 以使于通过SHA值来快速找到特定的对象.
到这里的时候,我已经了解了事情的真相,但我还是想要看看打包文件是怎样的。就又在另一个文件夹下搞了个版本库,对文件做了几次修改。
手动打包:
打开objects文件夹,发现除了info和pack文件夹,其他的全没了。点开pack文件夹,里面有一个打包文件和一个idx文件。上网查了一下,这个idx文件可以显示:
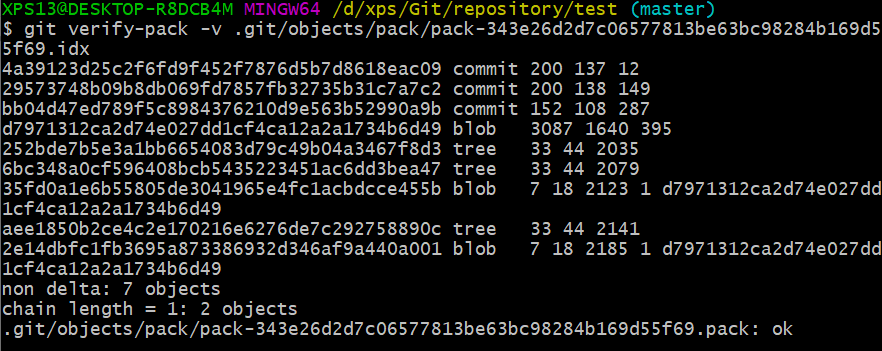
看到这些blob文件的大小,以及有些blob引用了别的blob,应该是保存差异无疑了。
我觉得孟宁老师文章中的一段话简直完美地说明了git存储commit对象,进行版本控制的原理:
line diff是形成增量补丁的技术方法,即一个文件按行对比(line diff)将差异的部分制作成一个增量补丁。
commit是存储到仓库里的一个版本,是整个项目范围内的一个或多个文件的增量补丁合并起来,形成项目的增量补丁,是一次提交记录。
接着进行场景一剩下的操作:
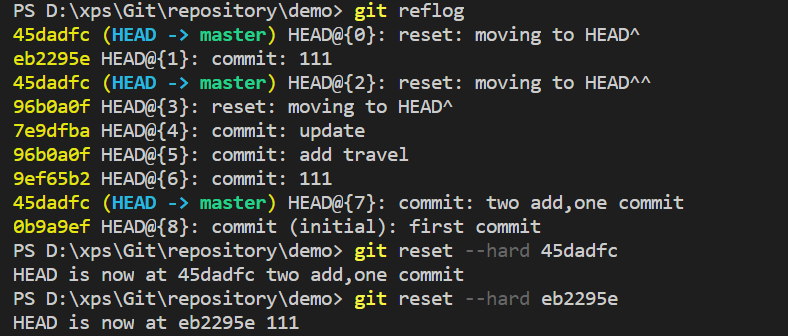
版本回退,退到上一版本:

又回到最新版本:
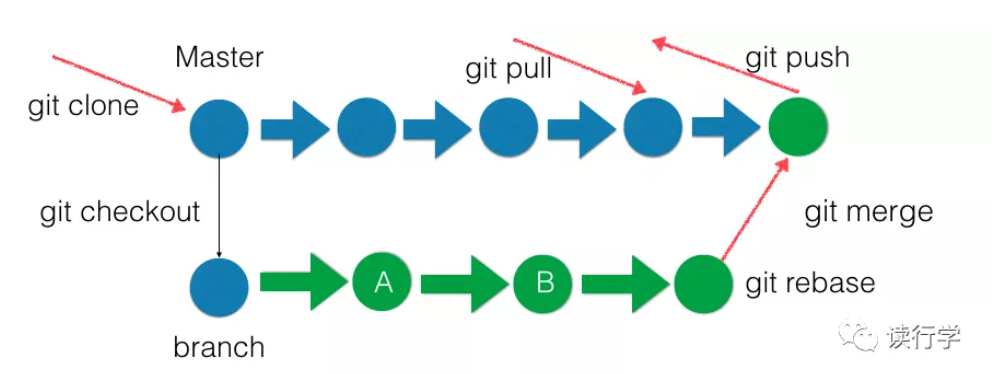
场景二:Git 远程版本库的基本用法
首先是克隆远程版本库到本地:

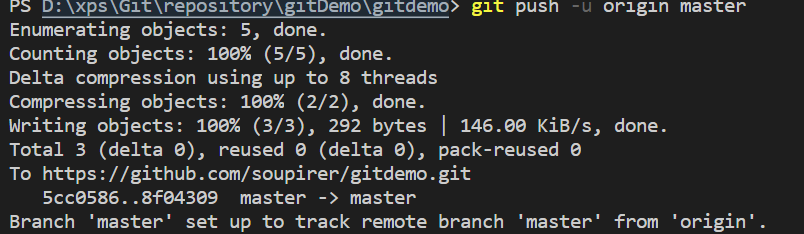
修改文件并commit后,push到远程版本库,成功。
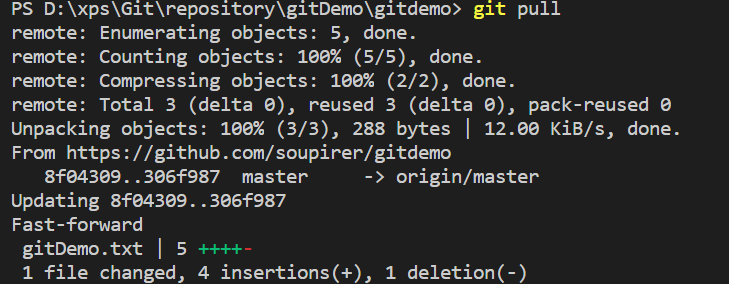
在远程版本库中修改文件,然后再pull到本地:
场景三:团队项目中的分叉合并
接着场景二的项目。
首先创建一个分支update1

在update1 分支上修改文件并提交,然后在远程master分支下修改文件,再在本地切换master分支尝试分支合并
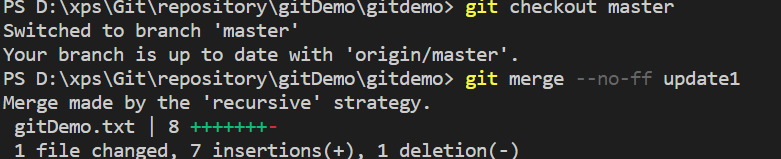
先不管,push一波
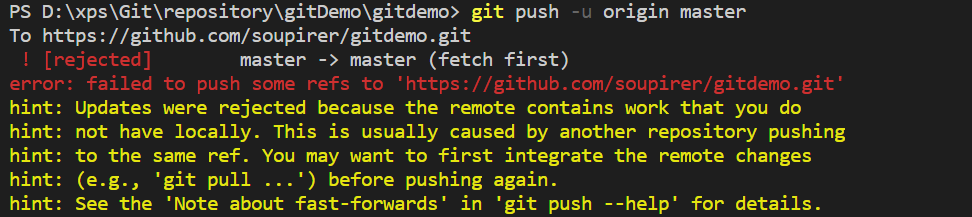
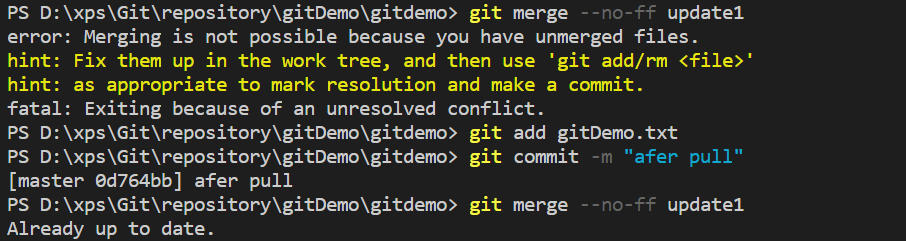
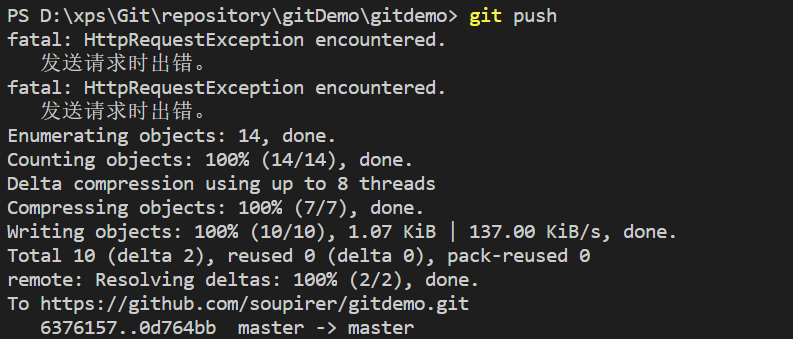
直接报错,并且提供解决方案:git pull。那就按流程行事:
打开github的网络图:
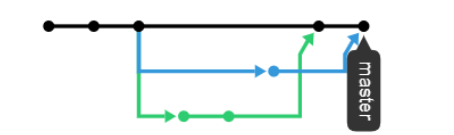
场景四:Git Rebase
为了完成练习题,即实现如下 commit 网络结点示意图,要求 A 和 B 在本地存在过,但并不出现在远程网络图中。
我创建了一个新的远程版本库,搞个文件上去。然后克隆到本地。在远程版本库的master分支下修改并commit文件两次。
在本地版本库创建一个分支,在新分支上修改并commit文件两次。下图是commit log信息:
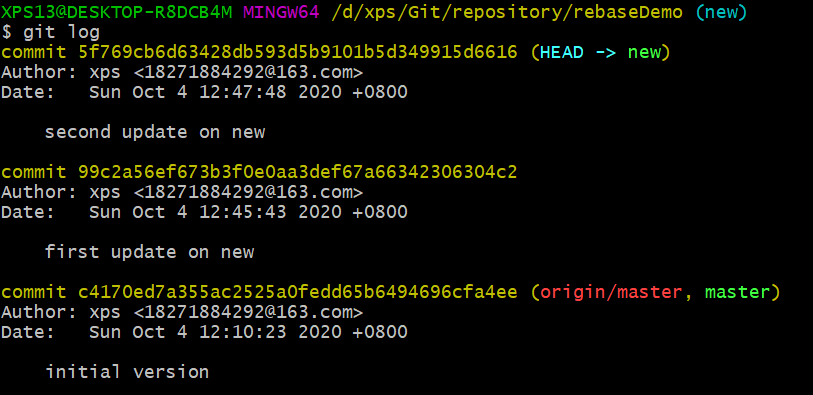
按题目的意思,应该是要这两次commit记录合并成一次。
接下来就进行rebase操作,执行以下指令:
git rebase -i HEAD^^
然后编辑文本:


查看 commit日志:
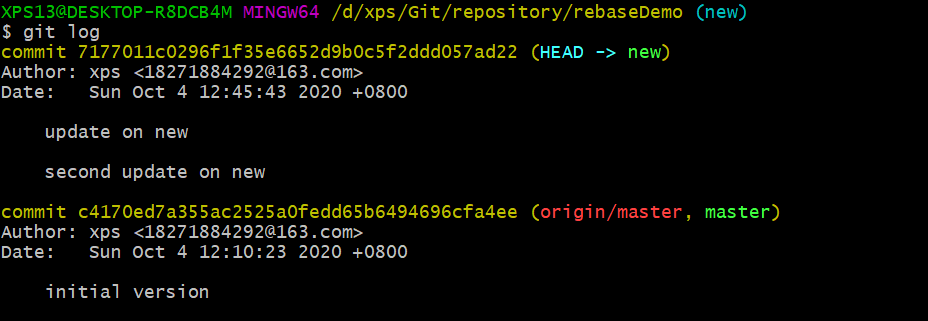
接着回到master分支,重复场景三合并分支的操作。
GitHub上的网络图如下:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号