
数据采集与融合技术_实验一
码云地址:https://gitee.com/a2625113421/data-acquisition-practice-i
-
作业①:
1)、大学软工排名信息的爬取
– 要求:用urllib和re库方法定向爬取给定网址https://www.shanghairanking.cn/rankings/bcsr/2020/0812的数据。
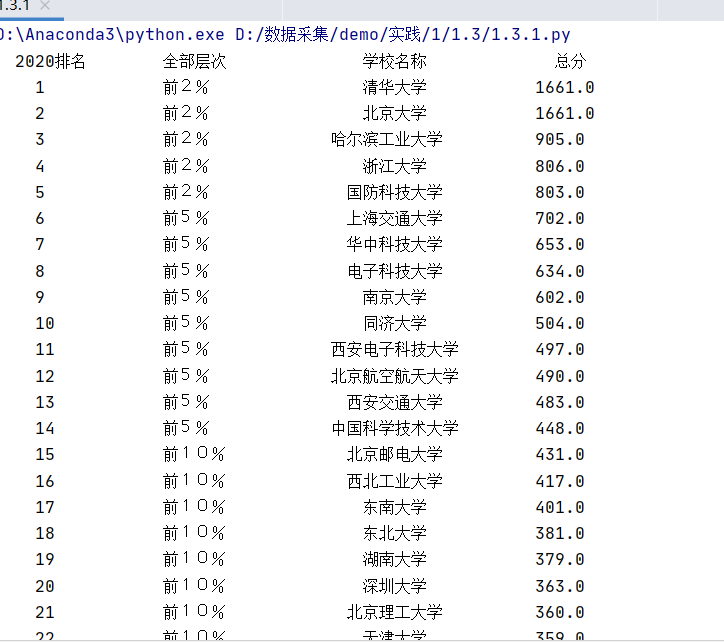
– 输出信息:
| 2020排名 | 全部层次 | 学校名称 | 总分 |
|---|---|---|---|
| 1 | 前2% | 清华大学 | 1661.0 |
过程:
1.向页面发送请求,获取源代码:
def get_html(url):
try:
headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
req = urllib.request.Request(url, headers=headers)
data = urllib.request.urlopen(req)
data = data.read()
data = data.decode()
return data
except Exception as err:
print(err)
2.利用正则表达式匹配数据并存入相应列表:
def fill_univ_list(ulist,html):
while True:
reg = r'(<div class="ranking" data-v-68e330ae>\s+)(\d+)'
rank = re.search(reg,html)
reg = r'(<td data-v-68e330ae>\s+)([\u4e00-\u9fa5]\d+%)'
level = re.search(reg,html)
reg = r'(data-v-b80b4d60>)([\u4e00-\u9fa5]+)'
name = re.search(reg,html)
reg = r'(<td data-v-68e330ae>\s+)(\d+.\d)'
ponits = re.search(reg, html)
if rank != None:
ulist.append([rank.group(2),level.group(2),name.group(2),ponits.group(2)])
html = html[name.end():]
else:
break
3.输出
def print_ulist(ulist):
tplt = "{0:^10}\t{1:{4}^10}\t{2:{4}^10}\t{3:^10}"
print(tplt.format("2020排名", "全部层次", "学校名称","总分", chr(12288)))
for u in ulist:
u[1] = strB2Q(u[1])
print(tplt.format(u[0], u[1], u[2], u[3], chr(12288)))
4.结果
2)、心得体会
此次作业只允许使用urllib和re库定向爬取网址,所以通过这次实验我进一步学习和巩固Re知识,运用正则表达式也更加得心应手了
-
作业②
1)、 城市实时空气质量信息的爬取
– 要求:用requests和Beautiful Soup库方法设计爬取https://datacenter.mee.gov.cn/aqiweb2/AQI实时报。
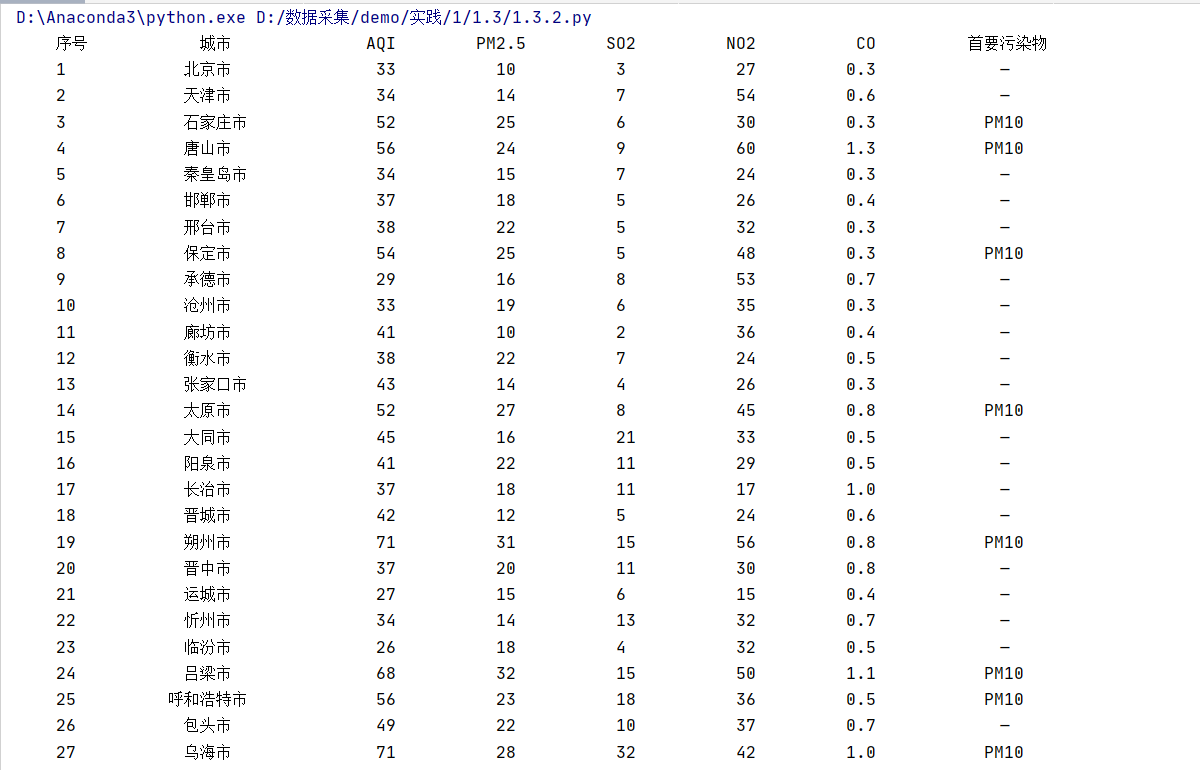
– 输出信息:
| 序号 | 城市 | AQI | PM2.5 | SO2 | NO2 | CO | 首要污染物 |
|---|---|---|---|---|---|---|---|
| 1 | 北京市 | 55 | 6 | 5 | 1.0 | 225 | —— |
过程:
1.向页面发送请求,获取源代码:
def get_html(url):
try:
headers = {"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
r = requests.get(url, timeout = 30, headers=headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
except:
return "产生异常"
return r.text
2.用BS4匹配相应td标签
def myFilter(tag):
return (tag.name=="tbody" and tag.has_attr("id") and tag["id"]=="legend_01_table")
def get_AQI(html):
AQI_list = []
soup = BeautifulSoup(html, "lxml")
for tr in soup.find(myFilter).children:
if isinstance(tr, bs4.element.Tag):
for td in tr.find_all("td"):
AQI_list.append(td.text.strip())
return AQI_list
3.输出
def print_AIQ(AQI_list):
tplt = tplt = "{0:^10}\t{1:{8}^10}\t{2:^10}\t{3:^10}\t{4:^10}\t{5:^10}\t{6:^10}\t{7:{8}^10}"
print(tplt.format("序号", "城市", "AQI", "PM2.5", "SO2", "NO2", "CO", "首要污染物", chr(12288)))
for i in range(int(len(AQI_list)/9)):
print(tplt.format(i, AQI_list[i*9], AQI_list[i*9+1], AQI_list[i*9+2], AQI_list[i*9+4],
AQI_list[i*9+5], AQI_list[i*9+6], AQI_list[i*9+8], chr(12288)))
4.结果
2)、心得体会
本题主要是对Requests和BeautifulSoup的再复习,与之前的做过练习很相似,内容更多了。采用将爬取到的信息统统添入列表,最后按照对应位置读取需要的数据。
-
作业③
1)、福大新闻网图片的爬取
– 要求:使用urllib和requests和re爬取一个给定网页https://news.fzu.edu.cn/爬取该网站下的所有图片
– 输出信息:将自选网页内的所有jpg文件保存在一个文件夹中
过程:
1.向页面发送请求,获取网页源代码:
def get_html_request(url):
try:
headers = {"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
r = requests.get(url, timeout = 30, headers=headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
except:
return "产生异常"
return r.text
def get_html_urllib(url):
try:
headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
req = urllib.request.Request(url, headers=headers)
data = urllib.request.urlopen(req)
data = data.read()
data = data.decode()
return data
except Exception as err:
print(err)
2.利用正则表达式匹配图片下载链接:
def download_jps(html):
reg = '<img src="/([a-zA-z]+[^\s"]*)'
imagelist = re.compile(reg).findall(html)
i = 1
for image in imagelist:
imageurl = "http://news.fzu.edu.cn/" + image
response = requests.get(imageurl)
img = response.content
with open("./picture/第" + str(i) +"张图片.jpg", "wb" ) as f:
f.write(img)
i += 1
print("下载完成")
3.结果:

2)、心得体会
此题要求使用urllib和requests和re库爬取一个给定网址的图片信息。通过这次作业使我对urllib和requests库有更清晰的认识,进一步体会二者区别,同时也是又一次对正则表达式的练习。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号